
- 1【C++】哈希
- 21.2.3 初次释出Linux 0.02_linux0.02
- 3Canal+RabbitMQ实现MySQL数据同步至ClickHouse_canal 配合哪个消息队列好
- 4双向链表的插入操作_pta双链表插入操作。 #include
using namespace std - 5fatal: unable to access ‘http://xxxx‘: Empty reply from server
- 6Ps 滤镜:自定
- 7Android Studio 4.2之后 不显示 gradle task list 问题_do not build gradle task list during gradle sync
- 82021年中国大学生程序设计竞赛女生专场-ADGIK
- 9SQL server数据库手动建库建表建约束,代码建库建表,数据库备份
- 10迷你无人车 Gazebo 仿真_steer_bot_hardware_gazebo
论文阅读:Pre-trained Models for Natural Language Processing: A Survey 综述:自然语言处理的预训练模型_pre-trained models for natural lan- guage processi
赞
踩
Pre-trained Models for Natural Language Processing: A Survey
综述:自然语言处理的预训练模型
目录
摘要
最近,预训练模型(PTMs)的出现将自然语言处理(NLP)带入了一个新时代。在此调查中,我们提供了针对NLP的PTMs的全面概述。我们首先简要介绍语言表示学习及其研究进展。然后,我们基于分类从四个角度对现有PTMs进行系统分类。接下来,我们描述如何使PTMs的知识适应下游任务。最后,我们概述了PTMs未来研究的一些潜在方向。该调查旨在作为实践指南,帮助您理解,使用和开发适用于各种NLP任务的PTMs。
关键词
深度学习,神经网络,自然语言处理,预训练模型,分布式表示,词嵌入,自监督学习,语言建模
1引言
随着深度学习的发展,各种神经网络已广泛用于解决自然语言处理(NLP)任务,例如卷积神经网络(CNNs)[79、85、48],递归神经网络(RNNs)[167、106] ],基于图的神经网络(GNN)[153、168、118]和注意力机制[7、178]。这些神经模型的优点之一是它们减轻特征工程问题的能力。非神经NLP方法通常严重依赖离散的手工特征,而神经方法通常使用低维和密集向量(又称为分布式表示)来隐式表示语言的句法或语义特征。这些表示是在特定的NLP任务中学习的。因此,神经方法使人们易于开发各种NLP系统。
尽管用于NLP任务的神经模型取得了成功,但与“计算机视觉”(CV)领域相比,性能改进的重要性可能较低。主要原因是大多数受监督的NLP任务的当前数据集很小(机器翻译除外)。深度神经网络通常具有大量参数,这使它们过度适合于这些小的训练数据,并且在实践中不能很好地推广。因此,许多NLP任务的早期神经模型相对较浅,通常仅包含1-3个神经层。
最近,大量的工作表明,大型语料库上的预训练模型(PTMs)可以学习通用语言表示形式,这对下游NLP任务很有帮助,并且可以避免从头开始训练新模型。随着计算能力的发展,深层模型(即Transformer [178])的出现以及培训技能的不断增强,PTMs的体系结构已从浅层发展到深层。第一代PTMs旨在学习良好的单词嵌入。由于下游任务不再需要这些模型本身,因此对于计算效率而言它们通常很浅,例如Skip-Gram [123]和GloV e [127]。尽管这些经过预训练的嵌入可以捕获单词的语义,但它们不受上下文限制,无法捕获上下文中的高级概念,例如多义歧义消除,句法结构,语义角色,回指。第二代PTMs专注于学习上下文词嵌入,例如CoV e [120],ELMo [129],OpenAI GPT [136]和BERT [35]。仍然需要这些学习的编码器来表示下游任务在上下文中的单词。此外,还提出了各种预训练任务来学习PTMs,以用于不同的目的。
这项调查的贡献可归纳如下:
1.全面审查。我们对NLP的PTMs进行了全面的回顾,包括背景知识,模型架构,预训练任务,各种扩展,改编方法和应用。
2.新的分类法。我们提出了用于NLP的PTMs分类法,该分类法从四个不同的角度对现有PTMs进行了分类:1)表示类型,2)模型体系结构; 3)预训练任务的类型; 4)特定类型场景的扩展。
3.丰富的资源。我们收集有关PTMs的大量资源,包括PTMs的开源实现,可视化工具,语料库和论文清单。
4.未来方向。我们讨论并分析现有PTMs的局限性。另外,我们建议可能的未来研究方向。
其余的调查安排如下。第2节概述了PTMs的背景概念和常用符号。第3节简要概述了PTMs,并阐明了PTMs的分类。第4节提供了PTMs的扩展。第5节讨论如何将PTMs的知识转移到下游任务。第6节提供了有关PTMs的相关资源。第7节介绍了跨各种NLP任务的应用程序集合。第8节讨论了当前的挑战并提出了未来的方向。第9节总结了论文。
2 背景
2.1语言表示学习
如Bengio等人所建议。 [13],一个好的表示应该表达不是特定任务的通用先验,但是对于学习机器解决AI任务可能很有用。在语言方面,一个好的表示法应该捕获隐藏在文本数据中的隐含语言规则和常识知识,例如词汇含义,句法结构,语义角色,甚至是语用学。
分布式表示的核心思想是通过低维实值向量来描述一段文本的含义。向量的每个维度都没有相应的意义,而整体代表了一个具体的概念。图1说明了NLP的通用神经体系结构。词嵌入有两种:非上下文嵌入和上下文嵌入。它们之间的区别在于,单词的嵌入是否根据出现的上下文而动态变化。
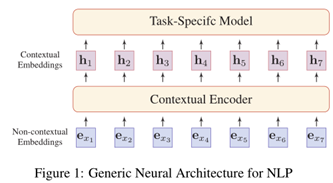
非上下文嵌入表示语言的第一步是将离散的语言符号映射到分布式嵌入空间中。形式上,对于词汇表V中的每个单词(或子单词)x,我们将其映射到具有查找表E∈RDe×| V |的向量ex∈RDe,其中Deis是指示令牌嵌入维数的超参数。这些嵌入和其他模型参数一起在任务数据上训练。
这种嵌入有两个主要限制。第一个问题是嵌入是静态的。单词的嵌入与上下文无关,始终是相同的。因此,这些非上下文嵌入无法建模多义词。第二个问题是语外问题。为了解决这个问题,字符级单词表示或子单词表示被广泛用于许多NLP任务中,例如CharCNNs [86],FastText [14]和Byte-Pair Encoding(BPE)[148]。
上下文嵌入为了解决多义性和单词的上下文相关性质的问题,我们需要区分不同上下文中单词的语义。给定一个文本x1,x2,···,xT,其中每个标记xt∈V是一个单词或子单词,则xt的上下文表示取决于整个文本。
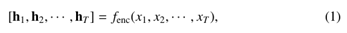
其中fenc(·)是神经编码器(在2.2节中进行了介绍),由于其中包含的上下文信息,因此称为令牌的上下文嵌入或动态嵌入。
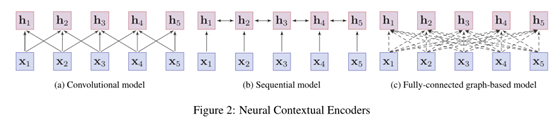
2.2神经上下文编码器
大多数神经上下文编码器可分为三类:卷积模型,顺序模型和基于图的模型。图2说明了这些模型的体系结构。
(1)卷积模型。卷积模型将单词嵌入到输入句子中,并通过卷积运算汇总来自邻居的局部信息来捕获单词的含义[85]。卷积模型通常易于训练,并且可以捕获本地上下文信息。
(2)顺序模型 顺序模型通常按顺序捕获单词的上下文表示,例如LSTM [63]和GRU [23]。实际上,双向LSTM或GRU用于从单词的两侧收集信息,但是其性能通常受长期依赖问题的影响。
(3)基于图的模型 与上述模型不同,基于图的模型将单词作为节点,并通过单词之间的预定义语言结构(例如语法结构[153、168]或语义关系)学习上下文表示。 [118]。
尽管语言感知图结构可以提供有用的归纳偏差,但是如何构建良好的图结构也是一个具有挑战性的问题。此外,该结构在很大程度上取决于专家知识或外部NLP工具,例如依赖项解析器。
实际上,一种更直接的方法是使用完全连接的图对每两个单词的关系进行建模,然后让模型自己学习结构。通常,连接权重是通过自我关注机制动态计算的,该机制会隐式指示单词之间的联系。
这种想法的成功实现是Transformer [178],它采用了完全连接的自我关注架构以及其他有用的设计,例如位置嵌入,层归一化和残差连接。
分析 卷积模型和顺序模型都学习具有局部偏差的单词的上下文表示,并且很难捕获单词之间的远程交互。相反,Transformer可以直接对序列中每两个单词之间的依赖关系进行建模,这更强大并且更适合于对语言进行建模。
但是,由于其笨重的结构和较少的模型偏差,因此Transformer通常需要较大的训练语料,并且容易在小型或中等规模的数据集上过拟合[136,52]。
2.3为什么要进行预训练?
随着深度学习的发展,模型参数的数量迅速增加。需要更大的数据集来完全训练模型参数并防止过度拟合。但是,由于注释成本极其昂贵,因此对于大多数NLP任务而言,构建大规模的标记数据集是一项巨大的挑战,尤其是对于语法和语义相关的任务。
相反,大规模的未标记语料库相对容易构建。为了利用巨大的未标记文本数据,我们可以首先从它们中学习良好的表示形式,然后将这些表示形式用于其他任务。最近的研究表明,借助从大型无注释语料库中的PTMs提取的表示形式,可以在许多NLP任务上显着提高性能。
预训练的优势可以归纳如下:
1.在庞大的文本语料库上进行预训练可以学习通用的语言表示形式并帮助完成下游任务。
2.预训练提供了更好的模型初始化,通常可以带来更好的泛化性能并加快目标任务的收敛速度。
3.可以将预训练视为一种正则化,以避免对小数据过度拟合[42]。
2.4用于NLP的PTMs的简要历史
预训练一直是学习深度神经网络参数的有效策略,然后对下游任务进行微调。早在2006年,深度学习的突破就出现了贪婪的逐层无监督预训练,然后是有监督的微调[61]。在简历中实际上,我们已经在庞大的ImageNet语料库上对模型进行了预训练,然后针对不同的任务在较小的数据上进一步进行微调。这比随机初始化要好得多,因为该模型可以学习一般的图像特征,然后可以将其用于各种视觉任务。
在NLP中,从浅层词嵌入到深层神经模型,大型语料库上的PTMs也被证明对下游NLP任务有益。
2.4.1第一代PTMs:经过预训练的词嵌入
将单词表示为密集的向量已有很长的历史[59]。在神经网络语言模型(NNLM)的开创性工作中引入了“现代”词嵌入[12]。 Collobert等。 [26]表明,将预训练的词嵌入到未标记的数据上可以显着改善许多NLP任务。为了解决计算复杂性,他们使用成对排名任务而不是语言建模来学习单词嵌入。他们的工作是从未标记的数据中获得对其他任务有用的通用词嵌入的首次尝试。 Mikolov等。 [123]表明没有必要使用深度神经网络来构建良好的单词嵌入。他们提出了两种浅层架构:连续词袋(CBOW)和Skip-Gram(SG)模型。尽管它们很简单,但是他们仍然可以学习高质量的词嵌入,以捕获词之间潜在的句法和语义相似性。 Word2vec是这些模型最流行的实现之一,它使NLP中的不同任务可以访问经过预训练的单词嵌入。此外,GloV e [127]也是一种广泛使用的模型,用于获取预训练词嵌入,该词嵌入是通过从大型语料库中进行的全局词-词共现统计来计算的。
尽管已显示出预训练的单词嵌入在NLP任务中有效,但它们与上下文无关,并且大多由浅层模型训练。当用于下游任务时,整个模型的其余部分仍需要从头开始学习。
在同一时期,许多研究人员还尝试学习段落,句子或文档的嵌入,例如段落向量[94],跳过思想向量[87],Context2V ec [121]。这些句子嵌入模型与其现代的继承者不同,它们尝试将输入的句子编码为固定维的矢量表示形式,而不是每个标记的上下文表示形式。
2.4.2第二代PTMs:预训练的上下文编码器
由于大多数NLP任务都超出单词级别,因此很自然地将神经编码器预训练为句子级别或更高级别。神经编码器的输出向量也称为上下文词嵌入,因为它们根据其上下文表示单词语义。
McCann等。 [120]从带有机器翻译(MT)的注意序列到序列模型中预先训练了一个深LSTM编码器。预训练编码器输出的上下文向量(CoV e)可以提高各种常见NLP任务的性能。彼得斯等。 [129]具有双向语言模型(BiLM)的预训练2层LSTM编码器,由前向LM和后向LM组成。预训练的BiLM ELMo(语言模型的嵌入)输出的上下文表示显示出对各种NLP任务都带来了很大的改进。 Akbik等。 [1]通过字符级LM预训练的上下文字符串嵌入来捕获单词含义。
但是,这些PTMs通常用作特征提取器来生成上下文词嵌入,这些词嵌入到主模型中以用于下游任务。它们的参数是固定的,并且仍从头开始训练主要模型的其余参数。
Ramachandran等。 [140]发现Seq2Seq模型可以通过无监督的预训练得到显着改善。编码器和解码器的权重都使用两种语言模型的预训练权重进行初始化,然后使用标记的数据进行微调。 ULMFiT(通用语言模型微调)[66]尝试微调用于文本分类(TC)的预训练LM,并在六个广泛使用的TC数据集上取得了最新技术成果。 ULMFiT包括三个阶段:1)对通用域数据进行LM预训练; 2)对目标数据进行LM微调; 3)对目标任务进行微调。 ULMFiT还研究了一些有效的微调策略,包括判别式微调,倾斜的三角形学习率和逐渐解冻。自ULMFiT以来,微调已成为使PTMs适应下游任务的主流方法。
最近,非常深入的PTMs在学习通用语言表示中表现出了强大的能力:例如,OpenAI GPT(生成式预训练)[136]和BERT(来自变压器的双向编码器表示)[35]。除了LM外,还提出了越来越多的自我监督任务(请参阅第3.1节),以使PTMs从大型文本语料库中获取更多知识。
3 PTMs概述
PTMs之间的主要区别是上下文编码器的用法,预训练任务和目的。我们在第2.2节中简要介绍了上下文编码器的体系结构。在本节中,我们重点介绍预训练任务,并给出PTMs的分类法。
3.1预训练任务
预训练任务对于学习语言的通用表示形式至关重要。通常,这些预训练任务应具有挑战性,并具有大量的培训数据。在本节中,我们将培训前的任务概括为三类:监督学习,无监督学习和自我监督学习。
1.监督学习(SL)是要学习一种功能,该功能基于包含输入输出对的训练数据将输入映射到输出。
2.无监督学习(UL)是从未标记的数据中找到一些固有知识,例如聚类,密度,潜在表示。
3.自我监督学习(SSL)是监督学习和非监督学习的结合1)。 SSL的学习范例与监督学习完全相同,但是训练数据的标签是自动生成的。 SSL的关键思想是以某种形式预测来自其他部分的输入的任何部分。例如,屏蔽语言模型(MLM)是一种自我监督的任务,它试图在给定其余单词的情况下预测句子中的屏蔽单词。
在CV中,许多PTMs在大型监督训练集(如ImageNet)上进行训练。但是,在NLP中,大多数受监督任务的数据集不足以训练一个好的PTMs。唯一的例外是机器翻译(MT)。大规模的MT数据集WMT 2017由超过700万个句子对组成。此外,MT是NLP中最具挑战性的任务之一,在MT上进行预训练的编码器可以使各种下游NLP任务受益。作为成功的PTMs,CoV e [120]是针对MT任务进行预训练的编码器,可改进各种常见的NLP任务:情感分析(SST,IMDb),问题分类(TREC),蕴涵度(SNLI)和问题接听(SQuAD)。
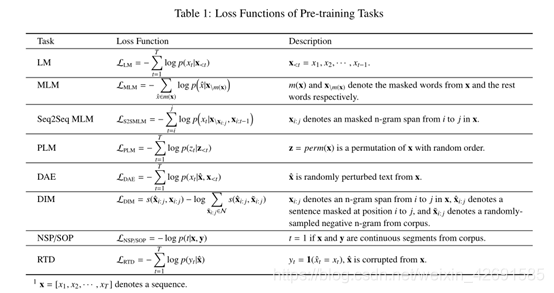
在本节中,我们将介绍一些现有PTMs中广泛使用的预训练任务。我们可以将这些任务视为自我监督学习。表1还总结了它们的损失函数。
3.1.1语言建模(LM)
NLP中最常见的无监督任务是概率语言建模(LM),这是一个经典的概率密度估计问题。尽管LM是一个笼统的概念,但在实践中,LM通常特别是指自回归LM或单向LM。
给定文本序列x1:T = [x1,x2,…,xT],其联合概率p(x1:T)可以分解为

其中,x0是表示序列开始的特殊标记。
条件概率p(xt | x0:t-1)可以通过给定语言上下文x0:t-1的词汇表上的概率分布来建模。上下文x0:t-1由神经编码器fenc(·)建模,条件概率为
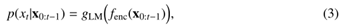
其中,gLM(·)是预测层。
给定一个庞大的语料库,我们可以使用最大似然估计(MLE)训练整个网络。
单向LM的一个缺点是每个令牌的表示仅编码向左上下文令牌及其本身。但是,更好的文本上下文表示应从两个方向对上下文信息进行编码。一种改进的解决方案是双向LM(BiLM),它由两个单向LM组成:向前的从左到右的LM和向后的从右到左的LM。对于BiLM,Baevski等人。 [6]提出了一个两塔模型,前塔操作从左到右的LM,后塔操作从右到左的LM。
3.1.2屏蔽语言建模(MLM)
掩码语言建模(MLM)最早是由Taylor [172]在文献中提出的,他将其称为Cloze任务。 Devlin等。 [35]将该任务改编为一种新颖的预训练任务,以克服标准单向LM的缺点。松散地说,MLM首先从输入语句中屏蔽掉一些令牌,然后训练模型顶部用其余令牌来预测被屏蔽的令牌。但是,这种预训练方法将在预训练阶段和微调阶段之间产生不匹配,因为在微调阶段不会出现掩码令牌。为了解决这个问题,Devlin等人从经验上讲。 [35]在80%的时间内使用特殊的[MASK]令牌,在10%的时间内使用随机令牌,在10%的时间内使用原始令牌进行屏蔽。
序列到序列MLM(Seq2Seq MLM) 传销通常作为分类问题解决。我们将屏蔽的序列馈送到神经编码器,该编码器的输出矢量进一步馈入softmax分类器,以预测屏蔽的令牌。或者,我们可以为MLM使用编码器-解码器(也称为序列到序列)体系结构,在该体系结构中,编码器被提供了屏蔽序列,而解码器以自回归的方式顺序生成屏蔽令牌。我们指的是
这种MLM作为序列到序列MLM(Seq2Seq MLM),在MASS [154]和T5 [138]中使用。 Seq2Seq MLM可以使Seq2Seq样式的下游任务受益,例如问题回答,摘要和机器翻译。
增强型屏蔽语言建模(E-MLM) 同时,有许多研究提出不同的MLM增强版本以进一步改进BERT。 RoBERTa [111]代替了静态屏蔽,通过动态屏蔽改进了BERT。
UniLM [38,8]在三种类型的语言建模任务上扩展了掩码预测的任务:单向,双向和序列到序列的预测。 XLM [27]在称为翻译语言建模(TLM)的平行双语句子对的串联上执行MLM。 SpanBERT [76]用随机连续词掩蔽和跨度边界目标(SBO)代替了MLM,以将结构信息集成到预训练中,这要求系统根据跨度边界来预测掩蔽的跨度。此外,StructBERT [187]引入了跨度顺序恢复任务以进一步整合语言结构。
丰富传销的另一种方法是整合外部知识(请参阅第4.1节)。
3.1.3置换语言建模(PLM)
尽管在预训练中广泛使用MLM任务,Yang等人。 [202]声称,当模型应用于下游任务时,MLM的预训练中使用的某些特殊标记(如[MASK])将不存在,从而导致预训练和微调之间存在差距。为了克服这个问题,置换语言建模(PLM)[202]是取代MLM的预训练目标。简而言之,PLM是一种对输入序列进行随机排列的语言建模任务。从所有可能的排列中随机抽取排列。然后,将置换序列中的某些标记选择为目标,然后训练模型以预测这些目标,具体取决于其余标记和目标的自然位置。请注意,此排列不会影响序列的自然位置,只会定义标记预测的顺序。实际上,由于收敛速度较慢,仅预测了置换序列中的最后几个标记。并针对目标感知表示引入了特殊的两流自我注意。
3.1.4去噪自动编码器(DAE)
去噪自动编码器(DAE)采用部分损坏的输入,旨在恢复原始的未失真输入。特定语言,序列到序列模型(例如标准Transformer)用于重构原始文本。有几种破坏文本的方法[98]:
(1)令牌屏蔽:从输入中随机采样令牌,并将其替换为[MASK]元素。
(2)令牌删除:从输入中随机删除令牌。与令牌屏蔽不同,该模型需要确定缺失输入的位置。
(3)文本填充:与SpanBERT一样,许多文本跨度也被采样并替换为单个[MASK]标记。每个跨度长度均来自泊松分布(λ= 3)。该模型需要预测跨度中缺少多少个令牌。
(4)句子置换:根据句号将文档分为多个句子,并以随机顺序对这些句子进行改组。
(5)文件轮换:随机地均匀选择一个令牌并旋转文件,以使其从该令牌开始。该模型需要标识文档的实际开始位置。
3.1.5对比学习(CTL)
对比学习[147]假设观察到的一些文本对在语义上比随机采样的文本更相似。学习文本对(x,y)的得分函数s(x,y)以最小化目标函数:
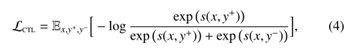
其中(x,y +)是相似的对,而y-可能与x不同。 y +和y-通常称为正样本和负样本。分数函数s(x,y)通常由可学习的神经编码器以两种方式计算:s(x,y)= fT enc(x)fenc(y)或s(x,y)= fenc(x y y )。
CTL背后的想法是“通过比较学习”。与LM相比,CTL通常具有较少的计算复杂性,因此是PTMs的理想替代训练标准。
Collobert等。 [26]提出了成对排序任务,以区分真假短语。该模型需要预测合法短语的得分要比通过用随机单词替换其中心单词而获得的不正确短语更高的分数。 Mnih和Kavukcuoglu [125]使用噪声对比估计(NCE)[54]有效地训练了单词嵌入,后者训练了一个二元分类器来区分真实样本和假样本。 NCE的思想也用于著名的word2vec嵌入[123]。
我们在以下段落中简要描述了一些最近提出的CTL任务。
深度InfoMax(DIM) Deep InfoMax(DIM)[62]最初是针对图像而提出的,它通过最大化图像表示和图像局部区域之间的互信息来提高表示的质量。
Kong等。 [88]将DIM应用于语言表示学习。序列x的全局表示被定义为上下文编码器fenc(x)输出的第一个标记的隐藏状态(假定是句子符号的特殊开始)。 DIM的目的是为fenc(xi:j)Tfenc(ˆ xi:j)分配比fenc(〜xi:j)Tfenc(ˆ xi:j)高的分数,其中xi:j表示n-gram2)span从x的i到j,xi:j表示在i到j位置掩盖的句子,而xi:j表示从语料库中随机抽取的负n-gram。
替换令牌检测(RTD)
替换令牌检测(RTD)与NCE相同,但在给定其周围上下文的情况下,它会预测是否替换了令牌。
带有负采样的CBOW(CBOW-NS)[123]可以看作是RTD的简单版本,其中通过简单的建议分布从词汇表中随机抽取负采样。
ELECTRA [24]通过利用生成器替换序列的某些标记来改进RTD。发电机G和鉴别器D遵循两个步骤进行训练:(1)仅训练具有MLM任务的发电机n1步; (2)用发生器的重量初始化鉴别器的重量。然后用判别任务训练判别器n2步,保持G冻结。在此,判别任务指示是否有理由用G替换输入令牌。在预训练后将生成器抛出,并且仅对鉴别器进行下游任务微调。
RTD还是解决不匹配问题的替代解决方案。在预训练期间,网络会看到[MASK],但在下游任务中进行微调时却看不到。
同样,WKLM [195]在实体级别而不是令牌级别替换单词。具体而言,WKLM用相同类型的其他实体的名称替换实体提及,并训练模型以区分该实体是否已被替换。
下一句预测(NSP) 标点符号是文本数据的自然分隔符。因此,利用它们来构建预训练方法是合理的。下一句预测(NSP)[35]就是一个很好的例子。顾名思义,NSP训练模型以区分两个输入句子是否是训练语料的连续片段。具体而言,当为每个预训练示例选择句子对时,有50%的时间,第二个句子是第一个句子的实际下一个句子,而有50%的时间,它是语料库中的随机句子。通过这样做,能够教导模型理解两个输入句子之间的关系,从而使对该信息敏感的下游任务受益,例如问题回答和自然语言推理。
但是,后续工作[76,202,111,91]质疑了NSP任务的必要性。杨等。 [202]发现NSP任务的影响是不可靠的,而Joshi等。 [76]发现没有NSP损失的单句训练优于具有NSP损失的句子对训练。此外,刘等。 [111]对NSP任务进行了进一步分析,结果表明,在训练单个文档中的文本块时,消除NSP损失匹配项或略微提高了下游任务的性能。
句子顺序预测(SOP)为了更好地模拟句子连贯性,ALBERT [91]用句子顺序预测(SOP)损失代替了NSP损失。如兰等人的推测。 [91],NSP将主题预测和相关性预测合并为一个任务。因此,允许模型仅依靠较容易的任务即主题预测来进行预测。与NSP不同,SOP使用同一文档中的两个连续片段作为肯定示例,而使用相同的两个连续片段但顺序互换了它们作为否定示例。结果,ALBERT在各种下游任务上始终优于BERT。
StructBERT [187]和BERTje [32]也将SOP作为他们的自我监督学习任务。
3.1.6其他
除上述任务外,还有许多其他辅助的预训练任务,它们旨在吸收事实知识(请参阅第4.1节),改进跨语言任务(请参阅第4.2节),多模式应用程序(请参阅第4.3节)或其他特定的任务(请参阅第4.4节)。
3.2 PTMs的分类
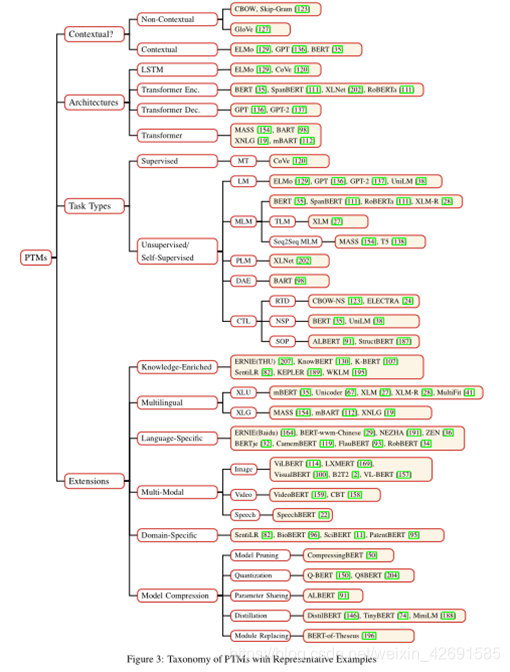
为了阐明NLP的现有PTMs的关系,我们建立了PTMs的分类法,从四个不同的角度对现有PTMs进行了分类:
1.表示类型:根据用于下游任务的表示,我们可以将PTMs分为非上下文和上下文楷模。
2.体系结构:PTMs使用的骨干网,包括LSTM,Transformer编码器,Transformer解码器和完整的Transformer体系结构。 “变压器”是指标准的编码器-解码器体系结构。 “ Transformer编码器”和“ Transformer解码器”分别表示标准Transformer体系结构的编码器和解码器部分。它们的区别在于,解码器部分使用带有三角矩阵的蒙版自我注意来防止令牌进入其未来(正确)位置。
3.预训练任务类型:PTMs使用的预训练任务的类型。我们已经在第3.1节中讨论了它们。
4.扩展:针对各种场景而设计的PTMs,包括知识丰富的PTMs,多语言或语言特定的PTMs,多模型PTMs,特定领域的PTMs和压缩的PTMs。我们将在第4节中特别介绍这些扩展。
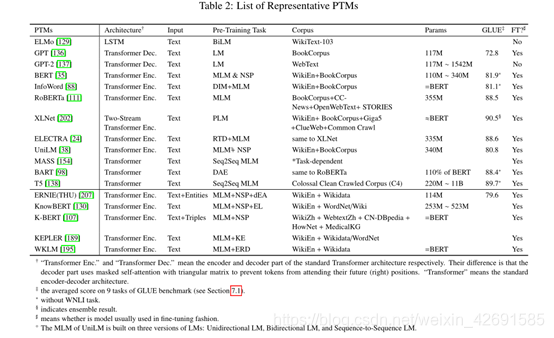
图3显示了分类法以及一些相应的代表性PTMs。此外,表2更详细地区分了一些代表性的PTMs。
3.3模型分析
由于PTMs的巨大成功,重要的是要了解PTMs捕获了哪些知识,以及如何从PTMs中获取知识。大量文献分析了存储在预训练的非上下文和上下文嵌入中的语言知识和世界知识。
3.3.1非上下文嵌入
首先探究静态词嵌入,以获取各种知识。 Mikolov等。 [124]发现神经网络语言模型学习的单词表示能够捕获语言的语言规律性,并且单词之间的关系可以通过特定关系的矢量偏移来表征。进一步的类比实验[123]证明,跳过语法模型产生的词向量可以捕获句法和语义词关系,例如vec(“中国”)-vec(“北京”)≈vec(“日本”)-vec( “东京”)。此外,他们发现单词向量的组成特性,例如,vec(“德国”)+ vec(“资本”)接近vec(“柏林”)。受这些工作的启发,Rubinstein等人。 [145]发现,分布词表示法擅长预测生物分类属性(例如,狗是动物),但无法学习定语属性(例如,天鹅是白色的)。同样,Gupta等。 [53]表明word2vec嵌入隐式编码实体的引用属性。分布式单词向量与简单的监督模型一起可以学习以合理的准确度预测实体的数字和二进制属性。
3.3.2上下文嵌入
大量研究在上下文嵌入中探究并引入了不同类型的知识。通常,知识有两种类型:语言知识和世界知识。
语言知识 设计了各种各样的探查任务来调查PTMs中的语言知识。 Tenney等。 [174],刘等。 [105]发现BERT在许多句法任务上表现出色,例如词性标记和成分标记。但是,与简单的语法任务相比,BERT在语义和细粒度的语法任务方面还不够出色。
此外,Tenney等。 [173]分析了BERT层在不同任务中的作用,发现BERT以与NLP管道中相似的顺序解决任务。此外,主语-动词一致性[49]和语义角色[43]的知识也被证实存在于BERT中。此外,休伊特和曼宁[58],贾瓦哈尔等。 [71],Kim等。 [84]提出了几种从BERT提取依赖树和选民树的方法,证明了BERT编码语法结构的能力。 Reif等。 [142]探索了BERT中内部表示的几何,并找到了一些证据:1)语言特征似乎在分离的语义和句法子空间中表示; 2)注意矩阵包含语法表示; 3)BERT很好地区分了词义。
世界知识 除语言知识外,PTMs还可以存储训练数据中显示的世界知识。探索世界知识的一种直接方法是使用“填空”的完形填空语句查询BERT,例如“ Dante出生于[MASK]”。 Petroni等。 [132]通过从几个知识源手动创建单令牌的完形填空语句(查询)来构造LAMA(语言模型分析)任务。他们的实验表明,BERT包含与传统信息提取方法竞争的世界知识。由于LAMA中查询生成过程的简单性,Jiang等人。 [73]认为,LAMA只是衡量语言模型知道的下限,并提出了更高级的方法来生成更有效的查询。尽管有LAMA令人惊讶的发现,但随后的工作也对其提出质疑[135,81]。同样,一些研究从BERT得出了下游任务的关系知识[15]和常识知识[31]。
4 PTMs的扩展
4.1知识丰富的PTMs
PTMs通常从通用大型文本语料库中学习通用语言表示,但是缺少特定领域的知识。将外部知识库中的领域知识整合到PTMs中被证明是有效的。外部知识的范围从语言[92、82、130、185],语义[97],常识[51],事实[207、130、107、195、189]到特定领域的知识[57]。
一方面,可以在预训练期间注入外部知识。早期的研究[190,210,194,198]集中于共同学习知识图嵌入和词嵌入。自BERT以来,便设计了一些辅助的预训练任务,以将外部知识整合到深层的PTMs中。 LIBERT [92](语言知悉的BERT)通过附加的语言约束任务整合了语言知识。 Ke等。 [82]集成了每个单词的情感极性,以将MLM扩展到标签感知MLM(LA-MLM)。结果,他们提出的模型SentiLR在一些句子和方面级别的情感分类任务上实现了最新的性能。 Levine等。 [97]提出SenseBERT,经过预训练,不仅可以预测屏蔽的令牌,还可以预测WordNet中的令牌。 ERNIE(THU)[207]将在知识图上预先训练的实体嵌入与文本中的相应实体提及进行集成,以增强文本表示。同样,KnowBERT [130]与实体链接模型一起训练BERT,以端到端的方式合并实体表示。 Wang等。 [189]提出了KEPLER,它共同优化了知识嵌入和语言建模目标。这些工作通过实体嵌入来注入知识图的结构信息。相反,K-BERT [107]将从KG提取的相关三元组显式注入句子中,以获得BERT的扩展树形输入。此外,熊等。 [195]采用实体替换识别来鼓励模型更多地了解事实知识。但是,这些方法中的大多数在注入知识时都会更新PTMs的参数,而在注入多种知识时可能会遭受灾难性的遗忘。为了解决这个问题,K-Adapter [185]通过针对不同的预训练任务独立地训练不同的适配器来注入多种知识,从而可以不断地注入知识。
另一方面,人们可以将外部知识整合到预训练的模型中,而无需从头开始对其进行再训练。例如,K-BERT [107]允许在对下游任务进行微调时注入事实知识。关等。 [51]运用常识知识库,ConceptNet和A TOMIC来增强GPT-2的故事生成能力。扬等。 [200]提出了一种知识-文本融合模型来获取相关的语言和事实知识,以进行机器阅读理解。
此外,洛根四世等。 [113]和Hayashi等。 [56]将语言模型分别扩展为知识图语言模型(KGLM)和潜在关系语言模型(LRLM),这两种模型都允许以知识图为条件的预测。这些新颖的以KG为条件的语言模型显示了进行预训练的潜力。
4.2多语言和特定语言的PTMs
4.2.1多语言PTMs
学习跨语言共享的多语言文本表示形式在许多跨语言的NLP任务中起着重要的作用。
跨语言理解(XLU) 早期的大多数工作都集中在学习多语言单词嵌入[44、117、152],该语言表示在单个语义空间中来自多种语言的文本。但是,这些方法通常需要语言之间的(弱)对齐。
多语言BERT3)(mBERT)已由MLM进行了预训练,并使用了来自104种主要语言的Wikipedia文本上的共享词汇和权重。每个培训样本都是单语言文档,没有专门设计的跨语言目标,也没有任何跨语言数据。即使这样,mBERT仍然可以很好地执行跨语言的泛化[134]。 K等。 [78]表明语言之间的词汇重叠在跨语言成功中起的作用微不足道。
XLM [27]通过合并跨语言任务翻译语言建模(TLM)改进了mBERT,该任务在并行双语句子对的串联上执行MLM。 Unicoder [67]进一步提出了三种新的跨语言预训练任务,包括跨语言单词恢复,跨语言释义分类和跨语言掩蔽语言模型(XMLM)。
XLM-RoBERTa(XLM-R)[28]是一种按比例缩放的多语言编码器,已通过大量增加的训练数据(2.5TB干净的CommonCrawl数据)以100种不同的语言进行了预训练。 XLM-RoBERTa的预训练任务仅是单语言的MLM。 XLM-R在包括XNLI,MLQA和NER在内的多个跨语言基准测试中获得了最新的成果。
跨语言生成(XLG) 多语言生成是一种任务,用于从输入语言生成具有不同语言的文本,例如机器翻译和跨语言抽象摘要。
与用于多语言分类的PTMs不同,用于多语言生成的PTMs通常需要共同预训练编码器和解码器,而不是仅仅关注编码器。
MASS [154]在多种语言上使用单语Seq2Seq MLM预先训练了Seq2Seq模型,并为无人监督的NMT取得了重大改进。 XNLG [19]为跨语言自然语言生成执行两阶段的预训练。第一阶段通过单语言MLM和跨语言MLM(XMLM)任务对编码器进行预训练。第二阶段通过使用单语言DAE和跨语言自动编码(XAE)任务对解码器进行预训练,同时保持编码器固定。实验表明XNLG在跨语言问题生成和跨语言抽象摘要方面的优势。 mBART [112]是BART [98]的多语言扩展,它在25种语言的大规模单语言语料库上与Seq2Seq去噪自动编码器(DAE)任务一起对编码器和解码器进行预训练。实验表明,mBART可以在各种机器翻译(MT)任务中显着提高性能。
4.2.2特定语言的PTMs
尽管多语言PTMs在多种语言上表现良好,但最近的工作表明,使用单一语言训练的PTMs明显优于多语言结果[119、93、180]。
对于没有明确单词边界的中文,建模较大的粒度[29,36,191]和多粒度[164,165]词表示法已显示出巨大的成功。 Kuratov和Arkhipov [90]使用迁移学习技术使多语言PTMs适应俄语的单语言PTMs。另外,已经发布了针对不同语言的一些单语言PTMs,例如法语的CamemBERT [119]和FlauBERT [93],芬兰语的FinBERT [180],荷兰语的BERTje [32]和RobBERT [34],AraBERT [4]。阿拉伯语。
4.3多模式PTMs
观察到PTMs在许多NLP任务中的成功,一些研究集中在获得PTMs的交叉模式版本上。这些模型中的绝大多数是为通用的视觉和语言特征编码而设计的。这些模型在大量的跨模式数据语料库上进行了预训练,例如带有口语的视频或带字幕的图像,并结合了扩展的预训练任务以充分利用多模式功能。通常,诸如基于视觉的MLM,蒙版的视觉特征建模和视觉语言匹配之类的任务广泛用于多模式预训练中,例如VideoBERT [159],VisualBERT [100],ViLBERT [114]。
4.3.1视频文本PTMs
VideoBERT [159]和CBT [158]是联合的视频和文本模型。为了获得用于预训练的视觉和语言标记序列,分别通过基于CNNs的编码器和现成的语音识别技术对视频进行预处理。单个Transformer编码器在处理后的数据上进行训练,以学习视频字幕等下游任务的视觉语言表示。此外,UniViLM [116]提出引入生成任务以进一步预训练在下游任务中使用的解码器。
4.3.2图像文本PTMs
除了用于视频语言预训练的方法之外,还有几篇著作介绍了在图像-文本对上的PTMs,旨在适应诸如视觉问题解答(VQA)和视觉常识推理(VCR)之类的下游任务。几个提出的模型采用两个单独的编码器分别用于图像和文本表示,例如ViLBERT [114]和LXMERT [169]。而其他方法,例如VisualBERT [100],B2T2 [2],VLBERT [157],Unicoder-VL [99]和UNITER [17]则提出了单流统一变压器。尽管这些模型架构不同,但是在这些方法中引入了类似的预训练任务,例如MLM和图像文本匹配。为了更好地利用视觉元素,在应用预训练的Transformers进行编码之前,可以通过应用RoI或边界框检索技术将图像转换为区域序列。
4.3.3音频文本PTMs
而且,有几种方法已经探索了在语音文本对上使用PTMs的机会,例如SpeechBERT [22]。这项工作尝试通过使用单个Transformer编码器对音频和文本进行编码来构建端到端语音问题回答(SQA)模型,该模型在语音和文本语料库上经过MLM预先训练,并在Question Answering上进行了微调。
4.4特定领域和特定任务的PTMs
大多数公开可用的PTMs都接受了通用域语料库(例如Wikipedia)的培训,这使它们的应用限于特定域或任务。最近,一些研究提出了在专业语料库上训练的PTMs,例如BioBERT [96]用于生物医学文本,SciBERT [11]用于科学文本,ClinicalBERT [68,3]用于临床文本。
除了对特定领域的PTMs进行预训练之外,一些工作还尝试使可用的预训练模型适应目标应用,例如生物医学实体标准化[72],专利分类[95],进度说明分类和关键字提取[170]。
还提出了一些面向任务的预训练任务,例如用于SentiLR的情感标签感知MLM [82]用于情感分析,用于文本摘要的Gap句子生成(GSG)[205]和用于流离失所检测的嘈杂单词检测[186]。 ]。
4.5模型压缩
由于PTMs通常至少包含数亿个参数,因此很难将PTMs部署在实际应用程序中的在线服务和资源受限的设备上。模型压缩[16]是减小模型大小并提高计算效率的潜在方法。
有五种压缩PTMs的方法[45]:(1)模型修剪,删除不重要的参数,(2)权重量化[39],使用较少的比特表示参数,(3)在相似模型单元之间共享参数,(4)知识提炼[60],它训练了一个较小的学生模型,该模型从原始模型的中间输出中学习型号和(5)模块更换,从而用更紧凑的替代品替换了原始PTMs的模块。
表3比较了一些代表性的压缩PTMs。
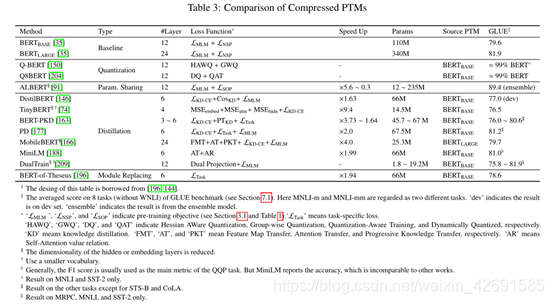
4.5.1模型修剪
模型修剪是指删除神经网络的一部分(例如权重,神经元,层,通道,注意头等),从而达到减小模型大小并加快推理时间的效果。
戈登等。 [50]探讨了修剪的时间(例如,在预训练期间进行修剪,在下游进行微调之后)和修剪方式。 Li和Eisner [101]使用变体信息瓶颈对ELMo单词令牌嵌入进行了压缩。 Michel等。 [122]和V oita等。 [181]试图修剪变压器块中的整个自我注意头。
4.5.2量化
量化是指将较高精度的参数压缩为较低精度。沉等人的著作。 [150]和Zafrir等。 [204]仅关注此领域。注意,量化通常需要兼容的硬件。
4.5.3参数共享
减少参数数量的另一种众所周知的方法是参数共享,它广泛用于CNNs,RNNs和Transformer [33]。 ALBERT [91]使用跨层参数共享和因式分解参数化来减少PTMs的参数。
4.5.4知识提炼
知识蒸馏(KD)[60]是一种压缩技术,其中训练了一个称为学生模型的小模型,以重现一个称为教师模型的大模型的行为。在这里,教师模型可以是许多模型的集合,并且通常经过良好的训练。与模型压缩不同,蒸馏技术通过一些优化目标从固定的教师模型中学习小型学生模型,而压缩技术旨在搜索稀疏的体系结构。
通常,蒸馏机制可以分为三种类型:(1)从软目标概率进行蒸馏,(2)从其他知识进行蒸馏,以及(3)蒸馏至其他结构:
(1)从软目标概率进行蒸馏。 Bucilua等。 [16]表明,使学生接近教师模型可以将知识从教师传授给学生。一种常见的方法是近似教师模型的对数。 DistilBERT [146]通过对教师的软目标概率的蒸馏损失训练了学生模型,如下所示:

其中,分别由教师模型和学生估计的概率。
从软目标概率中提取出来的数据也可以用于特定任务的模型中,例如信息检索[115]和序列标记[175]。
(2)从其他知识中提炼。从软目标概率中提取出来的内容将教师模型视为黑匣子,仅关注其输出。此外,分解教师模型并提取更多知识可以为学生模型带来改进。
TinyBERT [74]使用嵌入输出,隐藏状态和自我注意分布执行层到层蒸馏。 MobileBERT [166]还使用软目标概率,隐藏状态和自我注意分布执行层到层蒸馏。 MiniLM [188]从教师模型中提炼出自我注意力分布和自我注意力价值关系。
此外,其他模型还通过许多方法来提取知识。 Sun等。 [163]介绍了一种“耐心的”教师生机制,Liu等。 [108]利用KD改进了预训练的多任务深度神经网络。
(3)蒸馏至其他结构。通常,除了较小的图层大小和较小的隐藏大小以外,学生模型的结构与教师模型相同。但是,不仅减少参数,而且简化从Transformer到RNNs [171]或CNNs [20]的模型结构都可以降低计算复杂度。
4.5.5更换模块
模块更换是减小模型尺寸的一种有趣且简单的方法,它用更紧凑的替代品替代了原始PTMs的大型模块。徐等。 [196]提出了以著名的思想实验“ by修斯之船”为动机的These修斯压缩,该实验逐渐用较少参数的模块替换了源模型中的模块。与KD不同,These修斯压缩仅需要一项特定任务的丢失功能。压缩模型The-theseus的速度提高了1.94倍,同时保留了源模型的98%以上的性能。
5 使PTMs适应下游任务
尽管PTMs可以从大型语料库中获取通用语言知识,但是如何有效地将其知识适应下游任务仍然是关键问题。
5.1转移学习
转移学习[126]旨在使知识从源任务(或领域)适应目标任务(或领域)。图4给出了转移学习的示意图。
NLP中有很多类型的迁移学习,例如领域适应,跨语言学习,多任务学习。使PTMs适应下游任务是顺序转移学习任务,其中任务是顺序学习的,目标任务已标记数据。
5.2如何转让
要将PTMs的知识转移到下游NLP任务,我们需要考虑以下问题:
5.2.1选择适当的预训练任务,模型体系结构和语料库
不同的PTMs通常会对同一下游任务产生不同的影响,因为这些PTMs受到了各种预训练任务,模型体系结构和语料库的训练。
(1)目前,语言模型是最流行的预训练任务,可以更有效地解决各种NLP问题[137]。但是,不同的预训练任务有其自身的偏见,并且对不同的任务会产生不同的效果。例如,NSP任务[35]使PTMs了解两个句子之间的关系。因此,PTMs可以使诸如问答(QA)和自然语言推论(NLI)之类的下游任务受益。
(2)PTMs的体系结构对于下游任务也很重要。例如,尽管BERT可以帮助大多数自然语言理解任务,但很难生成语言。
(3)下游任务的数据分布应近似于PTMs。当前,有大量现成的PTMs,它们可以方便地用于各种特定域或特定语言的下游任务。
因此,给定目标任务,选择经过适当的预训练任务,体系结构和语料库训练的PTMs始终是一个好的解决方案。
5.2.2选择适当的层
给定一个预先训练的深度模型,不同的层应该捕获不同种类的信息,例如POS标记,解析,长期依赖性,语义角色,共指。对于基于RNNs的模型,Belinkov等。 [10]和Melamud等。文献[121]表明,从多层LSTM编码器的不同层中学习到的表示,可以使不同的任务受益(例如,预测POS标签和理解词义)。对于基于变压器的PTMs,Tenney等人。 [173]发现BERT代表了传统NLP流水线的步骤:基本语法信息出现在网络中的较早位置,而高层语义信息则出现在较高层中。
令H(l)(1 6 l 6 L)表示具有L层的预训练模型的第l层表示,而g(·)表示目标任务的特定任务的模型。
有三种选择表示的方法:
a)仅嵌入。一种方法是仅选择预训练的静态嵌入,而模型的其余部分仍需要从头开始进行训练以完成新的目标任务。
他们无法捕获可能更有用的高级信息。词嵌入仅在捕获词的语义上有用,但是我们还需要了解词义之类的高级概念。
b)顶层。最简单有效的方法是将顶层的表示形式输入到特定任务的模型g(H(L))中。
c)所有层。一种更灵活的方法是自动选择软版本中的最佳图层,例如ELMo [129]:

其中α是第l层的softmax归一化权重,而γ是标量,用于缩放通过预训练模型输出的矢量。混合表示被输入到特定任务的模型g(rt)中。
5.2.3调整还是不调整?
当前,有两种常见的模型传递方式:特征提取(冻结了预训练的参数)和微调(未冻结和微调的预训练参数)。
在特征提取方式中,预训练模型被认为是现成的特征提取器。此外,重要的是要公开内部层,因为它们通常会编码最易传递的表示形式[131]。
尽管这两种方式都可以极大地使大多数NLP任务受益,但是特征提取方式却需要更复杂的特定任务的体系结构。因此,对于许多不同的下游任务而言,微调方法通常比特征提取方法更为通用和方便。
表4给出了适应性PTMs的一些常见组合。

5.3细粒度调整策略
随着PTMs深度的增加,它们捕获的表示形式使下游任务变得更加容易。因此,整个模型的特定任务的层很简单。自ULMFit和BERT以来,微调已成为PTMs的主要适应方法。但是,微调的过程通常很脆弱:即使使用相同的超参数值,不同的随机种子也可能导致结果大不相同[37]。
除了标准的微调之外,还有一些有用的微调策略。
两阶段微调 另一种解决方案是两阶段转移,它引入了预训练和微调之间的中间阶段。在第一阶段,将PTMs转换为通过中间任务或语料库进行微调的模型。在第二阶段,将转移的模型微调到目标任务。 Sun等。 [161]表明,对相关领域语料库的“进一步预训练”可以进一步提高BERT的能力,并在八个经过广泛研究的文本分类数据集上实现了最新的性能。 Phang等。 [133]和Garg等。 [47]介绍了与目标任务相关的中间监督任务,它为BERT,GPT和ELMo带来了很大的改进。 Li等。 [103]也为故事结局预测使用了两阶段转移。提出的TransBERT(可传输BERT)不仅可以传输来自大规模未标记数据的一般语言知识,还可以传输来自各种语义相关的受监管任务的特定种类的知识。
多任务微调 刘等。 [109]在多任务学习框架下对BERT进行了微调,这表明多任务学习和预训练是互补的技术。
使用额外的适配模块进行微调 微调的主要缺点是其参数效率低:每个下游任务都有自己的微调参数。因此,更好的解决方案是在固定原始参数的同时将一些可微调的适配模块注入PTMs。
Stickland和Murray [156]配备了一个共享的BERT模型,其中包括一些小的额外的特定任务的适应模块,预计注意力层(PAL)。与共享的BERTPAL与GLUE基准上的微调模型分别匹配,参数减少了大约7倍。同样,Houlsby等。 [65]通过添加适配器模块修改了预训练BERT的体系结构。适配器模块产生了紧凑且可扩展的模型;它们为每个任务仅添加了几个可训练的参数,并且可以在不重新访问先前任务的情况下添加新任务。原始网络的参数保持固定,从而实现高度的参数共享。
其他 逐渐取消冻结[66]而不是同时对所有层进行微调,也是一种有效的方法,该方法从顶层开始逐渐冻结PTMs的各层。 Chronopoulou等。 [21]提出了一种更简单的解冻方法,即顺序解冻,该方法首先仅微调随机初始化的任务特定层,然后解冻PTMs的隐藏层,最后解冻嵌入层。
受到广泛使用的集成模型成功的推动,Xu等人。 [199]通过两种有效的机制改进了BERT的微调:自集成和自蒸馏。
通常,以上工作表明,可以通过更好的微调策略进一步激发PTMs的效用。
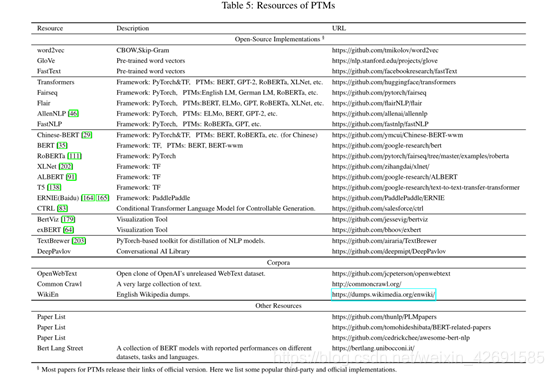
6 PTMs的资源
在线有许多PTMs相关资源。表5提供了一些受欢迎的存储库,包括第三方实现,论文列表,可视化工具以及PTMs的其他相关资源。
7应用
在本节中,我们总结了PTMs在一些经典的NLP任务中的一些应用。
7.1一般评估基准
对于NLP社区来说,存在一个基本问题,即如何以可比较的指标评估PTMs。因此,必须进行大规模基准测试。
通用语言理解评估(GLUE)基准[184]包含九种自然语言理解任务,包括单句分类任务(CoLA和SST-2),成对文本分类任务(MNLI,RTE,WNLI,QQP和MRPC),文本相似性任务(STSB)和相关排名任务(QNLI)。 GLUE基准是为评估模型的鲁棒性和泛化而精心设计的。 GLUE不提供测试集的标签,而是设置评估服务器。
然而,由于近年来的进步大大削弱了GLUE基准的动态余量,因此提出了一个新的基准,称为SuperGLUE [183]。与GLUE相比,SuperGLUE具有更具挑战性的任务和更多样化的任务格式(例如,共同指称解决方案和问题解答)。
相应的排行榜4)5)中列出了最新的PTMs。
7.2问答
问题解答(QA)或较窄的概念机器阅读理解(MRC)是NLP社区中的重要应用程序。从简单到困难,QA任务共有三种类型:单轮提取QA(SQuAD)[139],多轮生成QA(CoQA)[141]和多跳QA(HotpotQA)[201]。
BERT创造性地将提取的QA任务转换为可预测答案的开始范围和结束范围的范围预测任务[35]。之后,PTMs作为用于预测跨度的编码器已成为竞争基准。对于提取质量检查,Zhang等人。 [208]提出了一种追溯阅读器架构,并使用PTMs(例如ALBERT)初始化编码器。对于多轮生成质量检查,Ju等人。 [77]提出了“ PTMs +职业培训+理性标签+知识蒸馏”模型。对于多跳质量检查,Tu等人。 [176]提出了一种可解释的“选择,回答和解释”(SAE)系统,其中PTMs充当选择模块中的编码器。
通常,建议的QA模型中的编码器参数是通过PTMs初始化的,其他参数是随机初始化的。最先进的模型在相应的排行榜中列出。6)7)8)
7.3情感分析
BERT只需在SST-2上进行微调就可以胜过以前的最新模型,SST-2是广泛用于情感分析(SA)的数据集[35]。 Bataa和Wu [9]将BERT与迁移学习技术结合使用,并在日本SA中实现了最新技术。
尽管他们在简单的情感分类中取得了成功,但直接将BERT应用于基于方面的情感分析(ABSA)(这是一种细粒度的SA任务),显示的意义却不大无法改善[160]。为了更好地利用BERT的强大功能,Sun等人。 [160]通过将ABSA从单个句子分类任务转换为句子对分类任务来构造辅助句子。徐等。 [197]提出了后训练,以使BERT从其源域和任务适应ABSA域和任务。此外,Rietzler等。 [143]通过分析具有ABSA性能的跨域事后训练的行为,扩展了[197]的工作。 Karimi等。 [80]表明,经过对抗训练,可以进一步提高训练后的BERT的性能。宋等。 [155]添加了一个额外的池化模块,可以将其实现为LSTM或关注机制,以利用BERT中间层来实现ABSA。此外,李等。 [102]共同学习了面向端到端ABSA的方面检测和情感分类。 SentiLR [82]从SentiWordNet获取词性标签和先验情感极性,并采用Label-Aware MLM来利用引入的语言知识来捕获句子级情感标签和单词级情感转换之间的关系。 SentiLR在几个句子和方面级别的情感分类任务上都达到了最先进的性能。
对于情感转移,吴等。 [193]提出了基于BERT的“遮罩和填充”。在掩盖步骤中,模型通过掩盖情感标记将情感与内容区分开。在填充步骤中,它使用BERT以及目标情感嵌入来填充掩盖的位置。
7.4命名实体识别
命名实体识别(NER)是信息提取中的一项基本任务,并且在许多NLP下游任务中起着重要作用。在深度学习中,大多数NER方法都在序列标记框架中。句子中的实体信息将转换为标签序列,一个标签对应一个单词。该模型用于预测每个单词的标签。由于ELMo和BERT在NLP中显示出了强大的功能,因此关于NER的预训练模型还有很多工作要做。
Akbik等。 [1]使用预训练的字符级语言模型为NER生成单词级嵌入。 TagLM [128]和ELMo [129]使用预先训练的语言模型的最后一层输出以及每一层输出的加权和作为一部分词嵌入。刘等。 [104]使用分层修剪和密集连接来加快ELMo对NER的推断。 Devlin等。 [35]使用第一个BPE的BERT表示来预测每个单词的标签而无需使用CRF。 Pires等。 [134]通过多语言BERT实现了零发动NER。蔡等。 [175]利用知识提炼在单个CPU上为NER运行一个小型BERT。此外,BERT还用于特定领域的NER,例如生物医学[55,96]等。
7.5机器翻译
机器翻译(MT)是NLP社区中的一项重要任务,吸引了许多研究人员。几乎所有的神经机器翻译(NMT)模型都共享编码器-解码器框架,该框架首先通过编码器将输入令牌编码为隐藏表示,然后以目标语言从解码器解码输出令牌。 Ramachandran等。 [140]发现通过用两种语言模型的预训练权重初始化编码器和解码器,可以显着改善编码器-解码器模型。 Edunov等。 [40]使用ELMo在NMT模型中设置单词嵌入层。这项工作通过使用预训练的语言模型进行源词嵌入初始化,显示了英语-土耳其语和英语-德语NMT模型的性能改进。
鉴于BERT在其他NLP任务上的出色表现,很自然地研究如何将BERT整合到NMT模型中。 Conneau和Lample [27]尝试通过多语言预训练的BERT模型初始化整个编码器和解码器,并表明可以在无监督MT和英国-罗马尼亚监督MT上实现显着改进。同样,Clinchant等。 [25]设计了一系列不同的实验,以检验在NMT模型的编码器部分使用BERT的最佳策略。他们通过使用BERT作为编码器的初始化实现了一些改进。他们还发现,这些模型可以在域外数据集上获得更好的性能。 Imamura和Sumita [69]提出了用于NMT的两个阶段的BERT微调方法。在第一阶段,通过预训练的BERT模型初始化编码器,并且它们仅在训练集上训练解码器。在第二阶段,整个NMT模型在训练集上共同进行了微调。通过实验,他们证明了该方法可以超越一级微调方法,后者可以直接微调整个模型。除此之外,Zhu等。 [212]建议使用预训练的BERT作为额外的内存来简化NMT模型。具体而言,它们首先通过预训练的BERT对输入令牌进行编码,然后将最后一层的输出用作额外的内存。然后,NMT模型可以通过编码器和解码器每一层中的额外注意模块访问内存。他们在有监督,无监督和无监督的MT方面显示出明显的改进。
不仅仅对编码器进行预训练,MASS(掩蔽序列到序列预训练)[154]还利用Seq2Seq MLM共同对编码器和解码器进行了预训练。在实验中,这种方法可以超越Conneau和Lample [27]在无监督MT和英-罗马尼亚监督MT上提出的BERT样式的预训练。与MASS不同,mBART [112]是BART [98]的多语言扩展,它在25种语言的大规模单语语料库上与Seq2Seq去噪自动编码器(DAE)任务一起对编码器和解码器进行预训练。实验表明,mBART可以在句子级别和文档级别上显着改善有监督和无监督的机器翻译。
7.6总结
概述旨在产生保留较长文本大部分含义的较短文本,近年来引起了NLP社区的关注。自从PTMs的广泛使用以来,这项任务已得到显着改善。 Zhong等。 [211]引入了可转让的知识(例如BERT)进行汇总,并超越了先前的模型。张等。 [206]尝试预训练可以预测句子而不是单词的文档级模型,然后将其应用于下游任务,例如摘要。更详细地讲,Zhang等。 [205]设计了一个用于预训练的间隙句生成(GSG)任务,其目标涉及从输入中生成类似摘要的文本。此外,Liu和Lapata [110]提出了BERTSUM。 BERTSUM包括一个新颖的文档级编码器,以及一个用于提取摘要和抽象摘要的通用框架。在编码器框架中,BERTSUM通过插入多个[CLS]令牌来学习句子表示,从而扩展了BERT。为了进行提取摘要,BERTSUM堆叠了多个Intersentence Transformer层。为了进行抽象总结,BERTSUM提出了一种使用新的微调时间表的两阶段微调方法。
7.7对抗攻击与防御
深度神经模型容易受到对抗性示例的攻击,这些示例会误导模型以产生特定的错误预测,并产生来自原始输入的不可察觉的扰动。在CV中,对抗性攻击和防御已被广泛研究。然而,由于语言的离散性,对于文本来说仍然是挑战。为文本生成对抗性样本需要具备以下素质:(1)人类判断力难以察觉,但会误导神经模型; (2)语法流利,语义上与原始输入一致。 Jin等。 [75]成功攻击了微调的BERT关于文本分类和文本蕴含的对抗性例子。华莱士等。 [182]定义了通用对抗触发器,当与任何输入连接时,该触发器可以促使模型产生特定目的的预测。某些触发器甚至可能导致GPT-2模型生成种族主义文字。 Sun等。 [162]表明BERT在拼写错误方面不够强健。
8 未来方向
尽管PTMs已证明可以胜任各种NLP任务,但是由于语言的复杂性,仍然存在挑战。在本节中,我们建议PTMs的五个未来方向。
(1)PTMs的上限 目前,PTMs尚未达到上限。当前更多的PTMs可以通过更多的培训步骤和更大的语料库得到进一步改善。
通过增加模型的深度,可以进一步提高NLP的技术水平,例如Megatron-LM [151](83亿个参数,72个具有3072个隐藏头的Transformer层和32个关注头)和Turing-NLG9) (170亿个参数,78个Transformer层(隐藏大小为4256)和28个关注头)。
通用PTMs一直是我们追求学习语言固有的普遍知识(甚至世界知识)的追求。但是,此类PTMs通常需要更深的体系结构,更大的语料库和挑战性的预训练任务,这进一步导致更高的训练成本。但是,训练庞大的模型也是一个挑战性的问题,它需要更复杂,更有效的训练技术,例如分布式训练,混合精度,梯度累积等。因此,更实用的方向是设计更有效的模型架构,自我监督的预-使用现有的硬件和软件来培训任务,优化器和培训技能。 ELECTRA [24]是朝着这个方向的一个很好的解决方案。
(2)PTMs的体系结构 变压器已被证明是一种有效的预训练架构。但是,变压器的主要局限性在于其计算复杂度,它是输入长度的平方。受GPU内存的限制,当前大多数PTMs不能处理长度超过512个令牌的序列。打破此限制需要改进Transformer的体系结构,例如Transformer-XL [30]。因此,为PTMs寻找更有效的模型架构对于捕获更广泛的上下文信息很重要。
深度架构的设计具有挑战性,我们可能会从一些自动方法中寻求帮助,例如神经架构搜索(NAS)[213]。
(3)面向任务的预训练和模型压缩 在实践中,不同的下游任务需要PTMs的不同功能。 PTMs与下游任务之间的差异通常在于两个方面:模型架构和数据分发。更大的差异可能会导致PTMs的收益微不足道。例如,文本生成通常需要特定的任务来预训练编码器和解码器,而文本匹配则需要为句子对设计的预训练任务。
此外,尽管较大的PTMs通常可以带来更好的性能,但实际问题是如何在特殊情况下利用这些巨大的PTMs,例如低容量设备和低延迟应用程序。因此,我们可以为下游任务精心设计特定的模型体系结构和预训练任务,或者从现有的PTMs中提取部分特定任务的知识。
代替从头训练面向任务的PTMs,我们可以使用模型压缩等技术将它们与现有的通用PTMs一起教(见4.5节)。尽管在CV中对CNNs的模型压缩进行了广泛的研究[18],但对NLP的PTMs压缩却才刚刚开始。变压器的完全连接结构也使模型压缩更具挑战性。
(4)超越微调的知识转移
当前,微调是将PTMs的知识转移到下游任务的主要方法,但缺点是其参数效率低下:每个下游任务都有自己的微调参数。一种改进的解决方案是修复PTMs的原始参数,并为特定任务添加小型的微调适配模块[156,65]。因此,我们可以使用共享的PTMs服务多个下游任务。确实,使用PTMs作为外部知识[132],从PTMs挖掘知识可以更加灵活,例如特征提取,知识提取[203],数据增强[192、89]。期望有更有效的方法。
(5)PTMs的可解释性和可靠性 尽管PTMs达到了令人印象深刻的性能,但其深层的非线性体系结构使决策过程变得高度透明。
最近,可解释的人工智能(XAI)[5]已成为通用AI界的热点。与用于图像的CNNs不同,由于类似于Transformer的架构和语言的复杂性,解释PTMs更加困难。为了分析PTMs中包含的语言和世界知识,已经进行了广泛的努力(请参阅第3.3节),这有助于我们以一定程度的透明性理解这些PMT。但是,模型分析方面的许多工作取决于关注机制以及关注的有效性。可解释性仍然是有争议的[70,149]。
此外,PTMs还容易受到对抗性攻击(请参见7.7节)。随着PTMs在生产系统中的广泛使用,PTMs的可靠性也成为一个令人关注的问题。对PTMs的对抗攻击的研究可通过充分暴露其漏洞来帮助我们了解其功能。 PTMs的对抗性防御也很有前途,它可以提高PTMs的健壮性并使它们对对抗攻击具有免疫力。
总体而言,作为许多NLP应用程序中的关键组件,PTMs的可解释性和可靠性仍有许多方面需要进一步探讨,这有助于我们了解PTMs的工作原理,并为更好地使用和进一步改进提供指南。
9 结论
在本次调查中,我们对NLP的PTMs进行了全面概述,包括背景知识,模型架构,预训练任务,各种扩展,适应方法,相关资源和应用程序。基于当前的PTMs,我们从四个不同的角度提出了PTMs的新分类法。我们还建议了PTMs的几种可能的未来研究方向。

