
- 1线程状态:深入理解多任务并发编程中的精髓
- 2[Android studio] 第10节 ProgressBar控件_android progressbar
- 32024华为软件测试笔试面试真题,抓紧收藏不然就看不到了_华为软件测试工程师面试题
- 4【Java基础教程】(三十四)常用类库篇 · 第四讲:Runtime类——API知识汇总分享,深入解析Runtime运行时环境访问支持类~_java runtime
- 5hadoop:hafs:上传文件、删除文件、改变文件权限等常用命令
- 6H264视频编码成MP4文件_h264如何存储为mp4文件
- 7「转」plt.legend()简明使用教程
- 8动手学深度学习(二十七)——微调(fine turning)
- 9SQLServer删除表和截断表_sqlserver如果表存在就删除
- 10成为产品经理需要考哪些证书?全在这
[阅读笔记23][JAM]JOINTLY TRAINING LARGE AUTOREGRESSIVE MULTIMODAL MODELS
赞
踩

这篇论文是24年1月发表的,然后是基于的RA-CM3和CM3Leon这两篇论文。它所提出的JAM结构系统地融合了现有的文本模型和图像生成模型。

主要有两点贡献,第一点是提出了融合两个模型的方法,第二点是为混合模型精心设计的指令微调策略。
下图是一个示例,再给出问题回答时可以生成若干张相关的图片,便于提问者对答案的理解。

图文自回归模型来自于CM3leon,已经在2.4T的token上预训练过了,上下文长度为4096。大语言模型使用相同的结构,在1.4T的token上以2048上下文长度预训练过了。然后又用30B的token以4096上下文长度训练。图像的tokenizer来自VQ-VAE,接收的输入图像分辨率为256*256,将一张图像表示为1024个token,然后词表大小是8192。

这篇论文整体工作主要分两阶段,第一阶段就是将两个自回归模型进行融合,第二阶段是图像和文本交错的指令微调。
融合时有三种方案可以选择,首先是比较简单粗暴的方法,由于两个模型结构上是相同的,所以可以对应参数直接取均值。之前的BTX在融合多个专家模型时也使用了类似的策略。这种方案叫做JAM-Uniform。

第二种方案是JAM-Width,也就是将两个模型从宽度上拼接起来。这样词向量维度就需要翻倍,原来是4096,现在是8192,然后enbedding的投影矩阵直接拼接起来。对于注意力层,它这里列举的可能是多头注意力中多个头拼接起来以后再投影时使用的投影矩阵,因为就那个矩阵是方阵。像其他的参数,比如前馈层等等也按照相同的策略拼接起来。最后模型参数变成了26B。

第三种方案是借助交叉注意力实现模型融合。使用共享的输入输出投影层,并且最后添加了一个线性层,将两个模型最终输出拼接起来输入进线性层,然后线性层的输出维度是单个模型输出的维度,实现了降维。

这篇论文的第二个贡献点就是图文交错的指令微调,与以往的仅使用图像文本对来微调不同,这种微调方式得到的模型可以实现输出交错的图像和文本,图像与文本强相关,可以增强文本的可理解性。
具体在微调的时候有两种设置,也就是微调时是否引入Shutterstock这一预训练使用的图像文本数据,根据后续消融实验,发现引入以后图像生成质量更高。
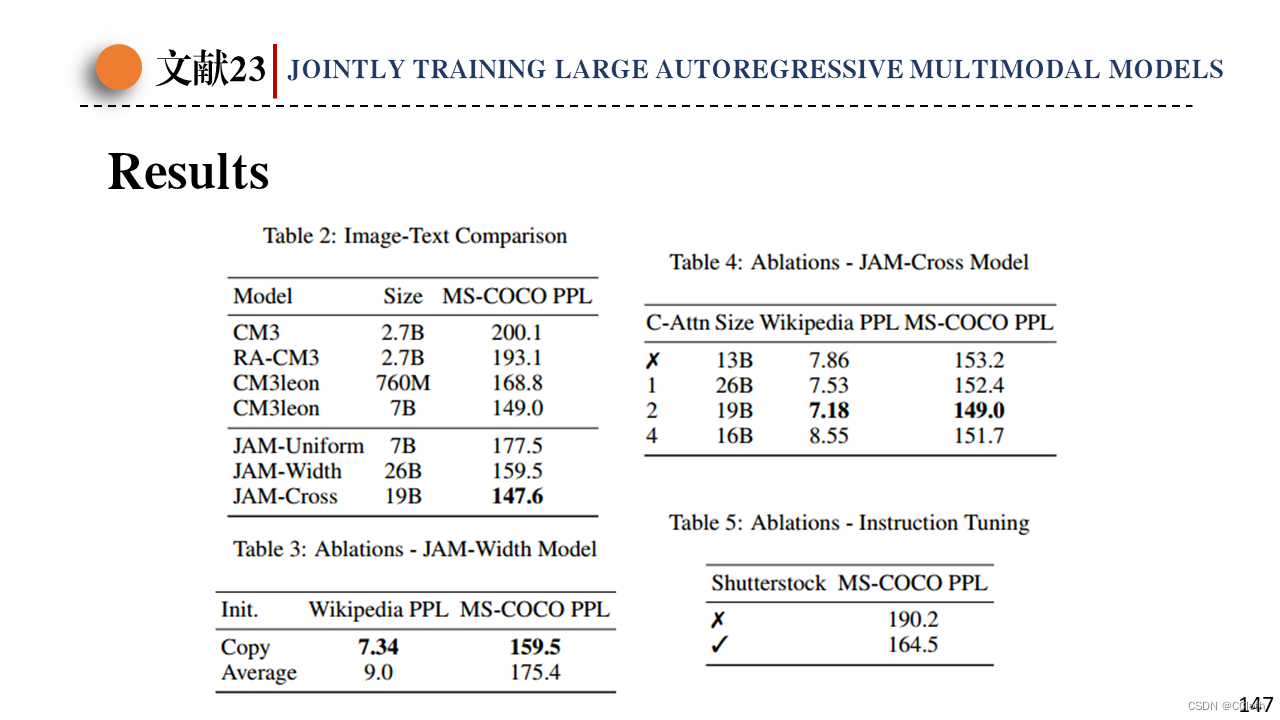
最后展示一下模型的结果,左上是CM3衍生出来的模型之间的性能对比,使用困惑度指标进行比较,可以看到Cross结构效果最好。右上是JAM-Cross结构中插入交叉注意力层的频率,可以看到频率太高也不好。左下是JAM-Width中注意力映射矩阵拼接后参数初始化问题,直接用原来的参数copy过来会更好一点。右下是指令微调阶段是否引入Shutterstock这一预训练使用的图像文本数据,根据实验结果,引入以后效果更好。

这是一个定性对比,与当前最相关的GILL模型进行对比,GILL也可以生成文本和图像的交错输出,但是生成的文本比较简略。

