
- 1齿轮故障诊断数据集分享(包括轴承和齿轮)_齿轮故障数据集
- 2深入解析基于DWA的路径规划算法MATLAB_dwa路径规划算法
- 3acm退役感言(一个又菜又懒的退役选手的记录)_ccpc外卡名额怎么申请
- 4git中如何获取远程仓库的最新代码?_git远程仓库中的新分支最新内容
- 5【深度学习】从huggingface上加载数据集到本地并保存为csv文件_huggingface 数据集 csv
- 6无人机技术服务应用_无人机的服务
- 7Web安全—文件上传(解析)漏洞_文件上传漏洞
- 8Qt+OpenGL-part3
- 9[从0开始AIGC][Transformer相关]:算法的时间和空间复杂度
- 10Java基于微信小程序的在线投稿小程序(V2.0),附源码
Kafka入门介绍+集群部署+简单使用_kafka0基础搭配集群
赞
踩
简介
官网:https://kafka.apache.org/
中文文档:https://kafka1x.apachecn.org/intro.html
Kafka是一个开源的分布式流处理平台
主要有三个关键功能
- 发布订阅事件流(可以用作消息队列)
- 分布式持久化存储事件流(可以用作数据处理系统)
- 可以在事件发生时处理或回顾性的处理
整体架构图如下:

核心概念
Broker(服务节点/实例)
一个Broker 可以看作一个独立的Kafka服务节点。
多个Broker组成一个Kafka集群。
Producer(生产者)
消息的生产者,将数据发送到Topic中。
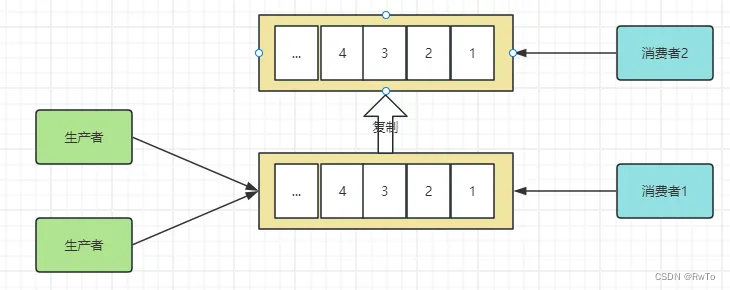
Topic(主题)
Topic是Kafka实现发布订阅的核心。类比其他MQ,可以把Topic看作 交换机和队列 的组合。
相同类型的消息发到同一个Topic。
生产者将消息发送给 Topic,Topic接收消息并持久化。
Topic 内部持久化存储了所有消息。所以Kafka也常被当做一个存储系统。
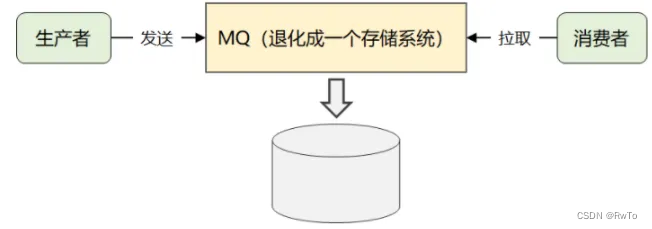
思考一个问题:Kafka为什么持久化存储所有消息?
Kafka作为消息队列,一般要提供给多个消费者消费,即广播。
而传统MQ,在消费者消费完一个消息后,会将消息删除。传统MQ想实现广播,需要复制一份给新的消费者消费。
这个复制的过程无疑加大了性能开销,这与Kafka高性能处理海量数据的设计理念相违背。所以Kafka在设计时,在Topic下持久化存储所有消息。将消费选择权交给消费者,由消费者提供offset偏移量 来实 现同一消息不同消费者进行消费,进而实现广播。

Partition(分区)
partition 是 消息实际存储的位置,属于Topic的一部分。
生产者向Topic丢数据,最终会落到Partition中。
消费者消费Topic中的数据,也是消费的Partition中的数据。
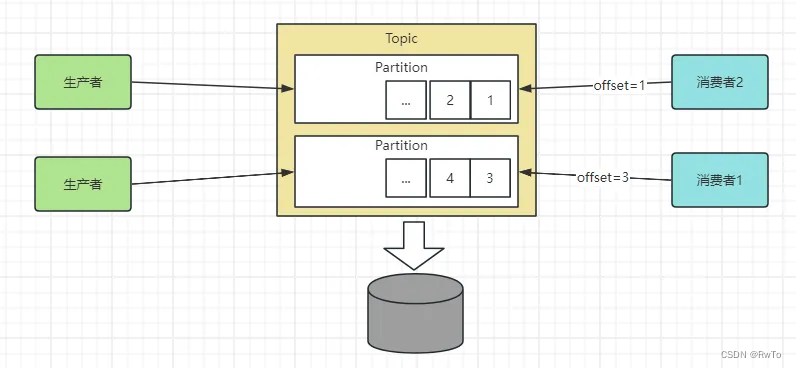
Kafka是为大数据而生,需要经常处理海量数据。单机的存储容量和读写性能肯定不能满足需求。需要对数据进行分片存储,Partition就是Kafka分片的数据子集。
也就是说,Partition是Kafka分布式的核心组件。
并且 Partition 是Kafka高性能,高可用,高并发的关键所在。
Consumer(消费者)和Consumer Group(消费者组)
消费者:即消费消息的。
Kakfa设计了消费者组的概念。
同一个消费者组中的消费者共同消费一个Topic中的消息
同时做了如下限制:
一个分区只可以被消费组中的一个消费者所消费
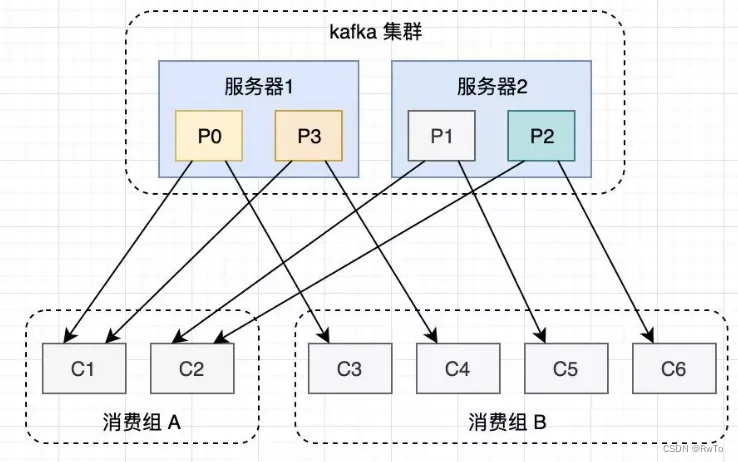
消费者组的特性:
- 一个消费组中的一个消费者可以消费多个分区
- 一个消费组中的不同消费者消费的分区一定不会重复
- 一个消费组中的所有消费者共同完成整个Topic中所有Partition的消费
思考一下,消费者组这种设计的好处是什么?
- 分摊消费压力,多个消费者并行无冲突的消费一组消息
- 消费模式更灵活,不同组合可以实现不同消费
例如:所有消费者一个组,实现单播
一个消费者一个组,实现广播- 高可用,提高容错率,多个消费者一个组,有一个消费者挂了,自己的分区会分配给其他消费者。
安装部署
下载安装
https://kafka.apache.org/downloads
官网下载并传到服务器进行解压安装
tar -zxvf kafka_2.13-3.1.2.tgz
- 1
安装完成后,查看目录结构

config目录

bin目录
分别使用ZK和Kafka的启动命令,即完成了Kafka单机模式的启动。(Kafka默认端口9092)
集群部署
接下来介绍下集群模式如何部署:
下面使用单机进行伪集群搭建,多台机器搭建方式类似。
# 创建一个集群配置目录
mkdir -p cluster/config
# 将zk 和 Broker的配置文件复制过去,三台Broker搭建集群,所以部署三份
cp config/zookeeper.properties cluster/config/
cp config/server.properties cluster/config/server-0.properties
cp config/server.properties cluster/config/server-1.properties
cp config/server.properties cluster/config/server-2.properties
- 1
- 2
- 3
- 4
- 5
- 6
- 7
修改 zookeeper配置
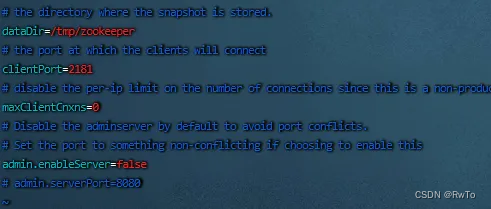
修改 三个Broker 配置
注意:broker.id 必须保证每个serve不同
如果是单机搭建的伪集群,注意listeners 端口也要不同,
同时还要修改log.dirs 日志目录,保证日志目录也不相同,
因为Broker在启动时会检查日志目录下的meta.properties中的broker.id,相同日志目录会导致冲突

启动
进入bin目录下启动zk和broker
启动Zookeeper
./zookeeper-server-start.sh ../cluster/config/zookeeper.properties
# 后台启动
nohup ./zookeeper-server-start.sh ../cluster/config/zookeeper.properties > /dev/null 2>&1 &
- 1
- 2
- 3
启动broker集群
./kafka-server-start.sh ../cluster/config/server-0.properties
./kafka-server-start.sh ../cluster/config/server-1.properties
./kafka-server-start.sh ../cluster/config/server-2.properties
# 后台启动
nohup ./kafka-server-start.sh ../cluster/config/server-0.properties > /dev/null 2>&1 &
nohup ./kafka-server-start.sh ../cluster/config/server-1.properties > /dev/null 2>&1 &
nohup ./kafka-server-start.sh ../cluster/config/server-2.properties > /dev/null 2>&1 &
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
简单使用
进入bin目录下
bin下面的kafka相关命令,都可以使用 --help 查看帮助文档,介绍的很全面
例如:./kafka-topics.sh --help
下面是我根据帮助文档做的简单使用
创建Topic主题
# 直接使用./kafka-topics.sh命令 会给出help文档
./kafka-topics.sh
# 创建一个名为 topci_test 的主题,Partition为3个,副本为2个
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic topic-test --partitions 3 --replication-factor 2
# 查看topic列表
./kafka-topics.sh --bootstrap-server localhost:9092 --list
# 查看 topic-test 的详细信息
./kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic topic-test
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

ISR:副本同步正常的BrokerId
Replicas:副本所在的BrokerId
Leader:leader所在的BrokerId
Partition:partition的编号
发送消息
./kafka-console-producer.sh --bootstrap-server localhost:9092,localhost:9093,localhost:9094 --topic topic-test
- 1

消费消息
消费者发送的offset在 0.9版本之前 存放在zookeeper,因为zookeeper 不适合大量频繁的读写,0.9版本之后,放在kafka默认的Topic(__consumer_offsets)里保存
低于0.9的老版本可能需指定Zookeeper地址
我这里使用3.1.2,所以不需要指定 zookeeper
# 如果需要从头消费 可以加上--from-beginning 或者 指定 --offset进行消费,默认是消费最新的
./kafka-console-consumer.sh --bootstrap-server localhost:9092,localhost:9093,localhost:9094 --topic topic-test
- 1
- 2


