
- 10基础学习PyFlink——使用PyFlink的Sink将结果输出到Mysql_pyflink写数据到mysql
- 2linux 查看io 进程,如何查看具体进程的IO情况?
- 3HashMap为什么使用红黑树而不用普通的AVL树_map为什么用红黑树不用avl树
- 4对于verlog仿真的时候,数据打拍delay的问题_verilog仿真中为什么有时候打拍,它没有延时一个时钟周期?
- 5word2vec的原理和难点介绍(skip-gram,负采样、层次softmax)_word2vec 负采样
- 6测试开发面试题(自用,遇到哪个记录哪个,持续更新~)_你的职业测试发展是什么,你自认为你做测试的优势是什么
- 7遨博协作机器人ROS开发 - 机械臂复杂轨迹规划_机械臂摆焊轨迹
- 8Sql server 连接 Oracle数据库_sqlserver链接oracle数据库
- 9【100%通过率】华为OD机试真题 C 实现【星际篮球争霸赛】【2023 Q1 | 100分】
- 10NLP精选10个实现项目推荐-涉及预训练Bert、知识图谱、智能问答、机器翻译、对话等...
Apache Kafka - 构建数据管道 Kafka Connect
赞
踩

概述
Kafka Connect 是一个工具,它可以帮助我们将数据从一个地方传输到另一个地方。比如说,你有一个网站,你想要将用户的数据传输到另一个地方进行分析,那么你可以使用 Kafka Connect 来完成这个任务。
Kafka Connect 的使用非常简单。它有两个主要的概念:source 和 sink。Source 是从数据源读取数据的组件,sink 是将数据写入目标系统的组件。使用 Kafka Connect,你只需要配置好 source 和 sink 的相关信息,就可以让数据自动地从一个地方传输到另一个地方。
主要概念
当使用Kafka Connect来协调数据流时,以下是一些重要的概念:
Connector
- Connector是一种高级抽象,用于协调数据流。它描述了如何从数据源中读取数据,并将其传输到Kafka集群中的特定主题或如何从Kafka集群中的特定主题读取数据,并将其写入数据存储或其他目标系统中。
Kafka Connect 中的连接器定义了数据应该复制到哪里和从哪里复制。 连接器实例是一个逻辑作业,负责管理 Kafka 和另一个系统之间的数据复制。 连接器实现或使用的所有类都在连接器插件中定义。 连接器实例和连接器插件都可以称为“连接器”。

Kafka Connect可以很容易地将数据从多个数据源流到Kafka,并将数据从Kafka流到多个目标。Kafka Connect有上百种不同的连接器。其中最流行的有:
这些连接器的更详细信息如下:
RDBMS连接器:用于从关系型数据库(如Oracle、SQL Server、DB2、Postgres和MySQL)中读取数据,并将其写入Kafka集群中的指定主题,或从Kafka集群中的指定主题读取数据,并将其写入关系型数据库中。
Cloud Object stores连接器:用于从云对象存储(如Amazon S3、Azure Blob Storage和Google Cloud Storage)中读取数据,并将其写入Kafka集群中的指定主题,或从Kafka集群中的指定主题读取数据,并将其写入云对象存储中。
Message queues连接器:用于从消息队列(如ActiveMQ、IBM MQ和RabbitMQ)中读取数据,并将其写入Kafka集群中的指定主题,或从Kafka集群中的指定主题读取数据,并将其写入消息队列中。
NoSQL and document stores连接器:用于从NoSQL数据库(如Elasticsearch、MongoDB和Cassandra)中读取数据,并将其写入Kafka集群中的指定主题,或从Kafka集群中的指定主题读取数据,并将其写入NoSQL数据库中。
Cloud data warehouses连接器:用于从云数据仓库(如Snowflake、Google BigQuery和Amazon Redshift)中读取数据,并将其写入Kafka集群中的指定主题,或从Kafka集群中的指定主题读取数据,并将其写入云数据仓库中。
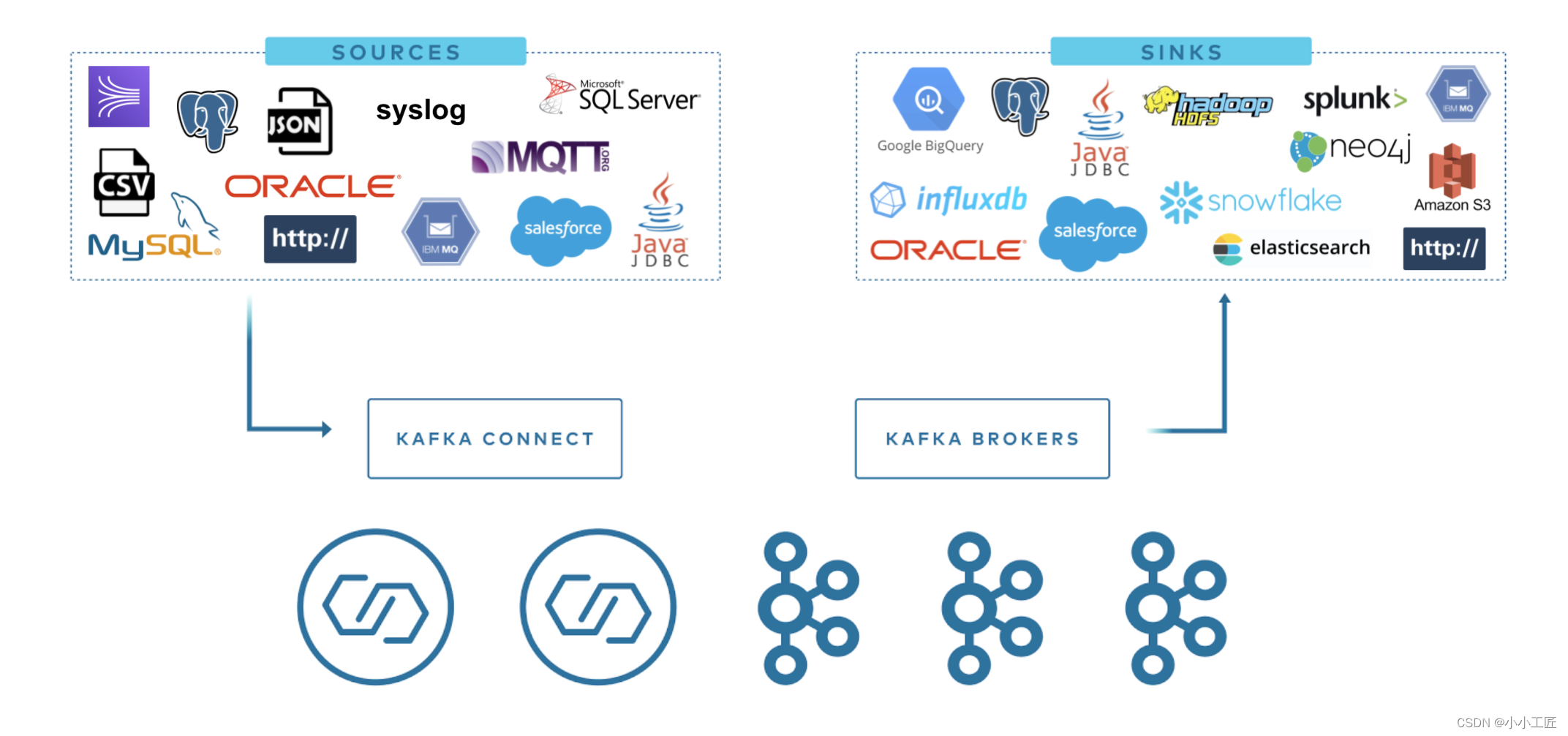
除了上述流行的连接器之外,Kafka Connect还支持许多其他数据源和目标,包括:
- Hadoop文件系统 (HDFS)
- Amazon Kinesis
- FTP/SFTP
- Salesforce
- JMS
- Apache HBase
- Apache Cassandra
- InfluxDB
- Apache Druid
这些连接器可以使Kafka Connect成为一个灵活的、可扩展的数据管道,可以轻松地将数据从各种来源流入Kafka,并将数据流出到各种目标。
Tasks
任务是Kafka Connect数据模型中的主要组件,用于协调实际的数据复制过程。每个连接器实例都会协调一组任务,这些任务负责将数据从源端复制到目标端。
Kafka Connect通过允许连接器将单个作业分解为多个任务来提供对并行性和可扩展性的内置支持。这些任务是无状态的,不会在本地存储任何状态信息。相反,任务状态存储在Kafka中的两个特殊主题config.storage.topic和status.storage.topic中,并由关联的连接器管理。
通过将任务状态存储在Kafka中,Kafka Connect可以实现弹性、可扩展的数据管道。这意味着可以随时启动、停止或重新启动任务,而不会丢失状态信息。此外,由于任务状态存储在Kafka中,因此可以轻松地在不同的Kafka Connect实例之间共享状态信息,从而实现高可用性和容错性。
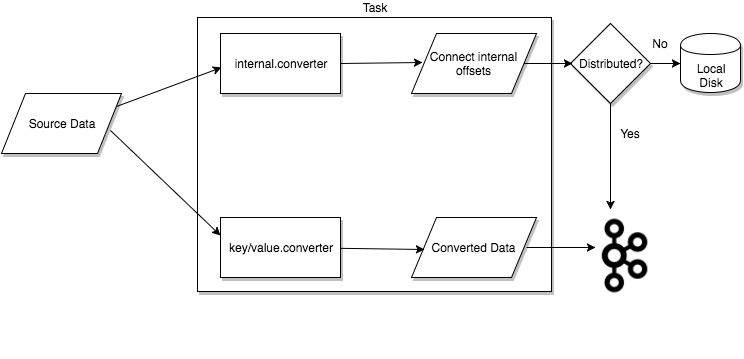
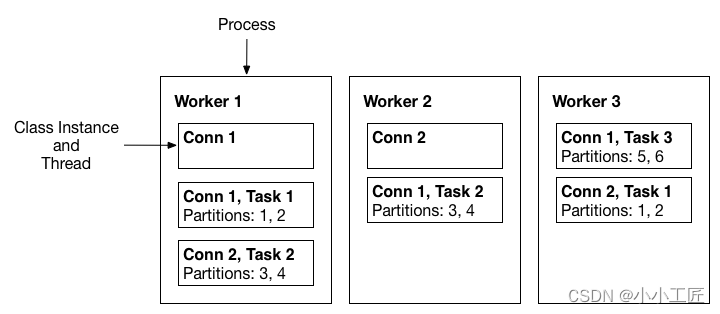
Workes
- Workers是执行连接器和任务的运行进程。它们从Kafka集群中的特定主题读取任务配置,并将其分配给连接器实例的任务。
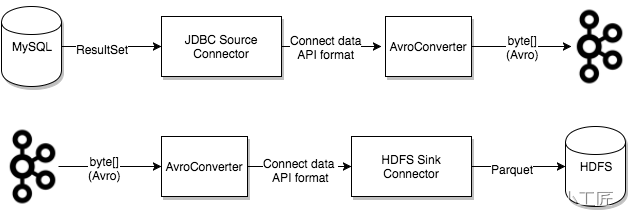
Converters
Converters是Kafka Connect中一种用于在发送或接收数据的系统之间转换数据的机制。它们将数据从一种格式转换为另一种格式,以便在不同的系统之间进行传输。
在Kafka Connect中,数据通常以字节数组的形式进行传输。Converters负责将Java对象序列化为字节数组,并将字节数组反序列化为Java对象。这样,就可以在不同的系统之间传输数据,而无需担心数据格式的兼容性问题。
Kafka Connect提供了多种内置的转换器,例如JSON Converter、Avro Converter和Protobuf Converter等。这些转换器支持多种数据格式,并且可以轻松地配置和使用。
此外,Kafka Connect还支持自定义转换器,用户可以编写自己的转换器来满足特定的需求。自定义转换器通常需要实现org.apache.kafka.connect.storage.Converter接口,并提供序列化和反序列化方法的实现。
总之,Converters是Kafka Connect中一种非常有用的机制,它可以帮助在不同的系统之间传输数据,并实现数据格式的转换。
Transforms
Transforms是Kafka Connect中一种用于改变消息的机制,它可以在连接器产生或发送到连接器的每条消息上应用简单的逻辑。Transforms通常用于数据清洗、数据转换和数据增强等场景。
通过Transforms,可以对每条消息应用一系列转换操作,例如删除字段、重命名字段、添加时间戳或更改数据类型。Transforms通常由一组转换器组成,每个转换器负责执行一种特定的转换操作。
Kafka Connect提供了多种内置的转换器,例如ExtractField、TimestampConverter和ValueToKey等。此外,还可以编写自定义转换器来满足特定的需求。
总之,Transforms是Kafka Connect中一种非常有用的机制,它可以帮助改变消息的结构和内容,从而实现数据清洗、转换和增强等功能。
Dead Letter Queue
Dead Letter Queue是Kafka Connect处理连接器错误的一种机制。当连接器无法处理某个消息时,它可以将该消息发送到Dead Letter Queue中,以供稍后检查和处理。
Dead Letter Queue通常是一个特殊的主题,用于存储连接器无法处理的消息。这些消息可能无法被反序列化、转换或写入目标系统,或者它们可能包含无效的数据。无论是哪种情况,将这些消息发送到Dead Letter Queue中可以帮助确保数据流的可靠性和一致性。
通过Dead Letter Queue,可以轻松地监视连接器出现的错误,并对其进行适当的处理。例如,可以手动检查Dead Letter Queue中的消息,并尝试解决问题,或者可以编写脚本或应用程序来自动检查并处理这些消息。
总之,Dead Letter Queue是Kafka Connect处理连接器错误的一种重要机制,它可以帮助确保数据流的可靠性和一致性,并简化错误处理过程。
主要使用场景
Kafka 通常在数据管道中有两种主要使用场景:
- Kafka 作为数据管道的一个端点,起源端或目的端。例如,从 Kafka 导出数据到 S3,或者从 MongoDB 导入数据到 Kafka。

- Kafka 作为数据管道中两个端点之间的中间件。例如,从 xx 流导入数据到 Kafka,再从 Kafka 导出到 Elasticsearch。
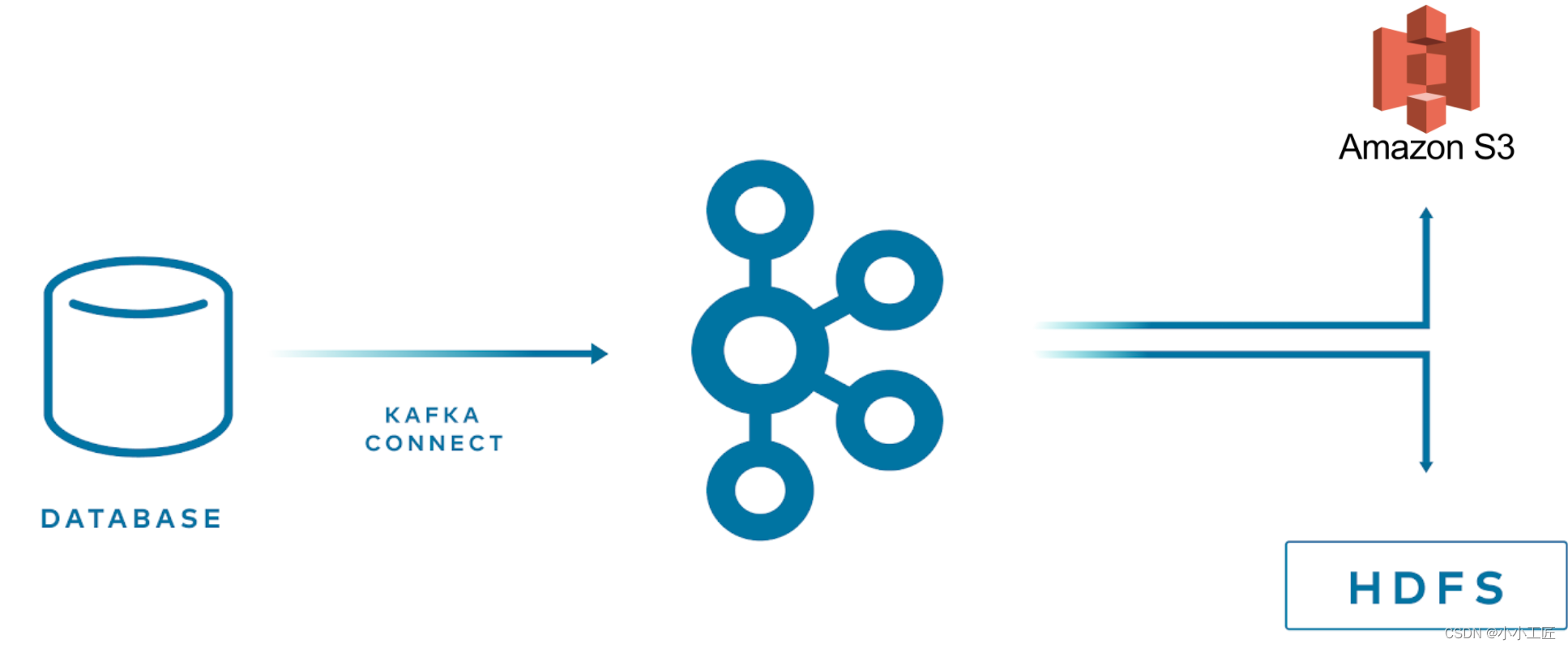
主要价值
Kafka 为数据管道带来的主要价值在于:
-
它可以作为一个大型的缓冲区,有效地解耦数据生产者和消费者。
-
它在安全性和效率方面非常可靠,是构建数据管道的最佳选择。
Kafka Connect API vs Producer 和 Consumer API
Kafka Connect API 正是为了解决数据集成中的常见问题而设计的。
相比直接使用 Producer 和 Consumer API,Kafka Connect API 的一些优点是:
- 简化了开发。不需要手动编写生产者和消费者逻辑。
- 具有容错性。Connect 会自动重启失败的任务,并继续同步数据而不会丢失。
- 常见数据源和目的地已经内置。比如 mysql、postgres、elasticsearch 等连接器已经开发完成,很容易就可以使用。
- 一致的配置和管理界面。通过 REST API 可以轻松配置、启动、停止 connector 任务。
除 Kafka Connect API 之外,Kafka 也可以和其他系统集成,实现数据集成。例如:
- 和 Spark Streaming 集成,用于实时数据分析和机器学习。
- 和 Flink 结合,实现 Exactly-Once 语义的流式处理。
- 和 Storm 联合,构建实时计算工具。
- 和 Hadoop 相结合,用于实时和批量计算。
构建数据管道时需要考虑的主要问题
- 及时性:支持不同的及时性需求,能够进行迁移。Kafka 起buffer作用,生产者和消费者解耦,支持实时和批处理。
- 可靠性:避免单点故障,能够快速恢复。Kafka 支持至少一次传递,结合外部系统可以实现仅一次传递。
- 高吞吐量和动态吞吐量:支持高并发和突发流量。Kafka 高吞吐,生产者和消费者解耦,可以动态调整。
- 数据格式:支持各种格式,连接器可以转换格式。Kafka 和 Connect API 与格式无关,使用可插拔的转换器。
- 转换:ETL vs ELT。ETL 可以节省空间和时间,但会限制下游系统。ELT 保留原始数据,更灵活。
- 安全性:数据加密,认证和授权,审计日志。Kafka 支持这些安全特性。
- 故障处理:处理异常数据,重试并修复。因为 Kafka 长期保留数据,可以重新处理历史数据。
- 耦合性和灵活性:
- 避免针对每个应用创建单独的数据管道,增加维护成本。
- 保留元数据和允许schema变更,避免生产者和消费者紧密耦合。
- 尽量少处理数据,留给下游系统更大灵活性。过度处理会限制下游系统。
总之,构建一个好的数据管道,需要考虑到时间、安全、格式转换、故障处理等方方面面,同时还需要尽量 loosely coupled,给使用数据的下游系统最大灵活性。
Kafka 作为一个流处理平台,能够很好地解决这些问题,起到解耦生产者和消费者的buffer作用。同时 Kafka Connect 为数据的输入输出提供了通用接口,简化了集成工作。
使用 Kafka 构建的数据管道,可以同时服务于实时和批处理的场景,具有高可用、高吞吐、高扩展性等特征。
ETL VS ELT
数据整合方式的不同
两种不同的数据整合方式
- ETL:Extract-Transform-Load,即提取-转换-加载。在这种方式下,数据从源系统提取出来后,会先进行转换和处理,然后再加载到目标系统。
- ELT:Extract-Load-Transform,即提取-加载-转换。在这种方式下,数据从源系统提取出来后,首先加载到目标系统,然后再在目标系统内进行转换和处理。
- ETL 和 ELT 的主要区别在于数据转换的时机和位置不同: ETL 在加载之前转换数据,ELT 是在加载之后转换数据。 ETL 的转换发生在源系统和目标系统之间,ELT 的转换发生在目标系统内。
ETL 和 ELT 各有优缺点:
ETL 优点:
- 可以在加载过程中对数据进行过滤、聚合和采样,减少存储和计算成本。
- 可以在加载数据到目标系统之前确保数据格式和质量。
ETL 缺点: - 转换逻辑混杂在数据管道中,难以维护和调试。
- 下游系统只能访问转换后的数据,灵活性差。
ELT 优点: - 为下游系统提供原始数据,更灵活。下游系统可以根据需求自行处理和转换数据。
- 转换逻辑在下游系统内,更易于调试和维护。
- 源数据较易回溯和重处理。
ELT 缺点:
- 需要目标系统具有强大的数据处理能力。
- 需要更大的存储空间来存储原始数据。
- 转换过程可能会对目标系统造成较大负载。
总体来说,如果下游系统需要高度灵活地处理数据,并有较强的数据处理能力,ELT 往往更为合适。否则,ETL 可以在加载数据前进行预处理,减轻下游系统负载,这种方式会更高效。很多情况下,也会采用 ETL 和 ELT 混合的方式



