
- 1ComfyUI 详细入门基础教程之(一):安装与常用插件
- 2python数据爬取案例--地产数据及交通数据_交通数据抓取
- 3【Livox】安装Livox-ros-driver2_livox_ros_driver2
- 4IDEA中没有Web Application的解决办法_idea没有web application
- 5Laravel + PHP +Composer + Git,Laravel项目运行完整步骤_运行git上的laravel项目
- 6web3.js 常用的操作方法_web3.js教程
- 7HBase Shell命令
- 8sql加减乘除运算_小白学sql(一)
- 9linux防火墙命令汇总_linux查看防火墙状态命令
- 10Spring Boot 经典面试题(六)
使用BERT做中文文本相似度计算与文本分类_bert中文文本相似度计算与文本分类
赞
踩
转载请注明出处,原文地址:
https://terrifyzhao.github.io/2018/11/29/使用BERT做中文文本相似度计算.html
简介
最近Google推出了NLP大杀器BERT,BERT(Transformer双向编码器表示)是Google AI语言研究人员最近发表的一篇论文。它通过在各种NLP任务中呈现最先进的结果,包括问答系统、自然语言推理等,引起了机器学习社区的轰动。
本文不会去讲解BERT的原理,如果您还不清楚什么是BERT建议先参阅Google的论文或者其他博文,本文主要目的在于教会大家怎么使用BERT的预训练模型。
在开始使用之前,我先简单介绍一下到底什么是BERT,大家也可以去BERT的github上进行详细的了解,或者直接参阅我的版本github。在CV问题中,目前已经有了很多成熟的模型供大家使用,我们只需要修改结尾的FC层或根据实际场景添加softmax层,也就是我们常说的迁移学习。那在NLP领域是否有这样泛化能力很强的模型呢,答案是肯定的,BERT是一个已经事先采用大量数据进行过训练的模型,泛化能力极强,使用时只需要针对特定领域进行微调即可使用。对于NLP的正常流程来说,我们需要做一些预处理,例如分词、W2V等,BERT包含所有的预训练过程,只需要提供文本数据即可,接下来我们会基于NLP常用的文本相似度计算问题来介绍如何使用BERT。
下载预训练模型
谷歌提供了以下几个版本的BERT模型,每个模型的参数都做了简单的说明,中文的预训练模型在11月3日的时候提供了,这里我们只需要用到中文的版本,点击下载

下载下来的文件包括以下内容
- TensorFlow 用来保存预训练模型的三个 checkpoint 文件(bert_model.ckpt.xxx)
- 字典文件,用于做ID的映射 (vocab.txt)
- 配置文件,该文件的参数是fine-tuning时模型用到的,可自行调整 (bert_config.json)
编写代码
模型准备好后就可以编写代码了,我们先把BERT的github代码clone下来,之后我们的代码编写会基于run_classifier.py文件,我们看下代码的结构
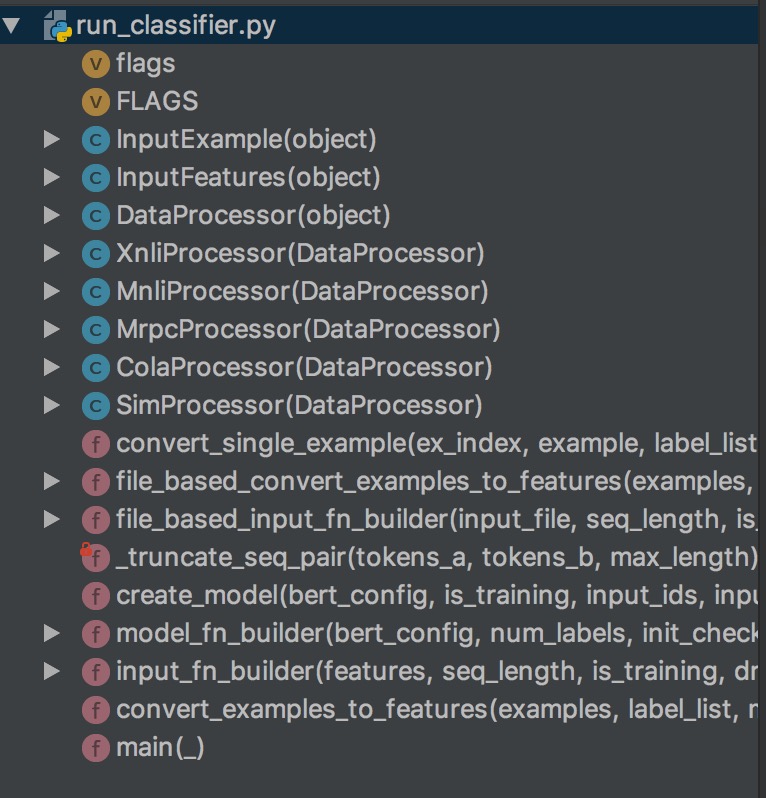
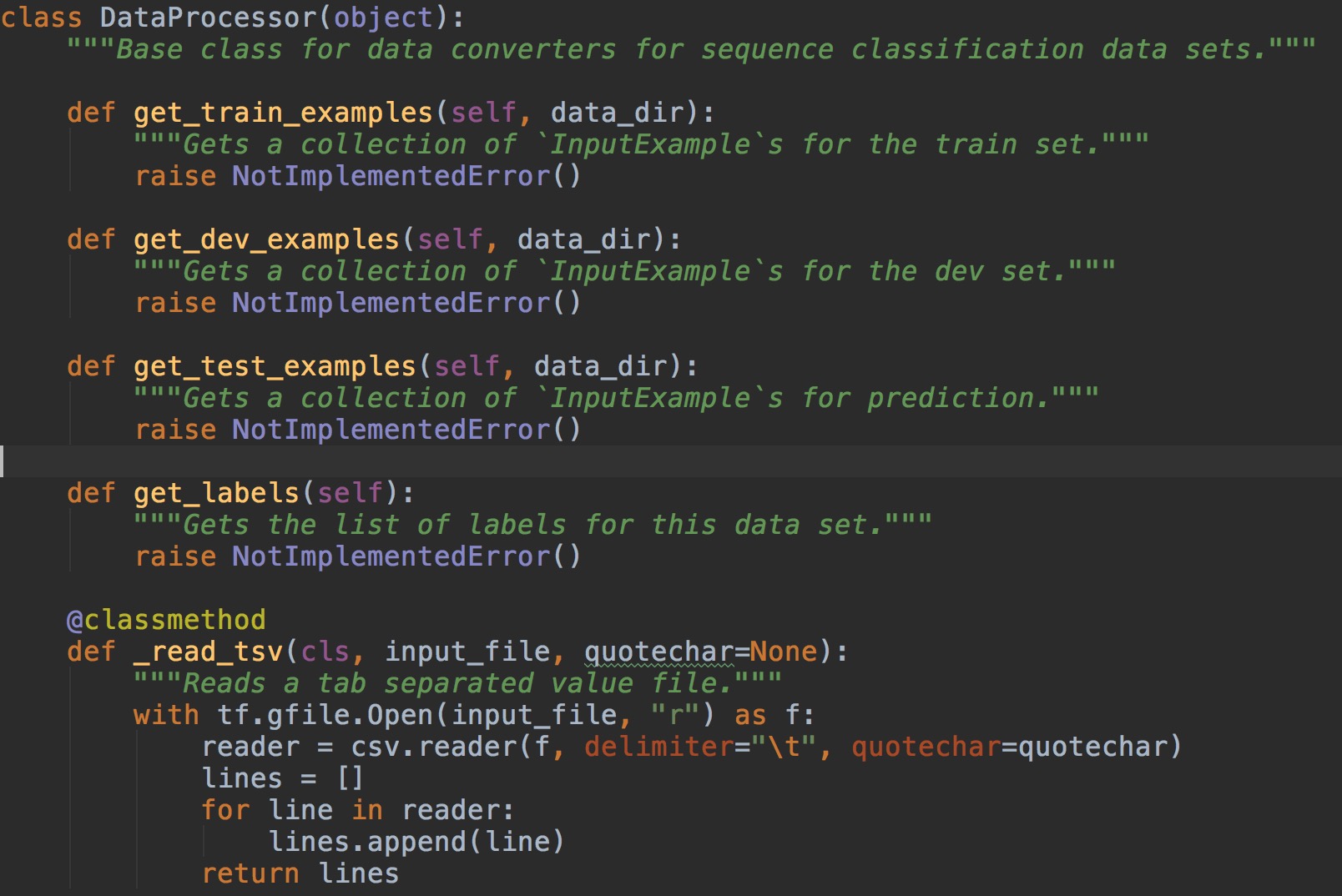
可以看到有好几个xxxProcessor的类,这些类都有同一个父类DataProcessor,其中DataProcessor提供了4个抽象方法,如图
顾名思义,Processor就是用来获取对应的训练集、验证集、测试集的数据与label的数据,并把这些数据喂给BERT的,而我们要做的就是自定义新的Processor并重写这4个方法,也就是说我们只需要提供我们自己场景对应的数据。这里我自定义了一个名叫SimProcessor的类,我们简单看一下
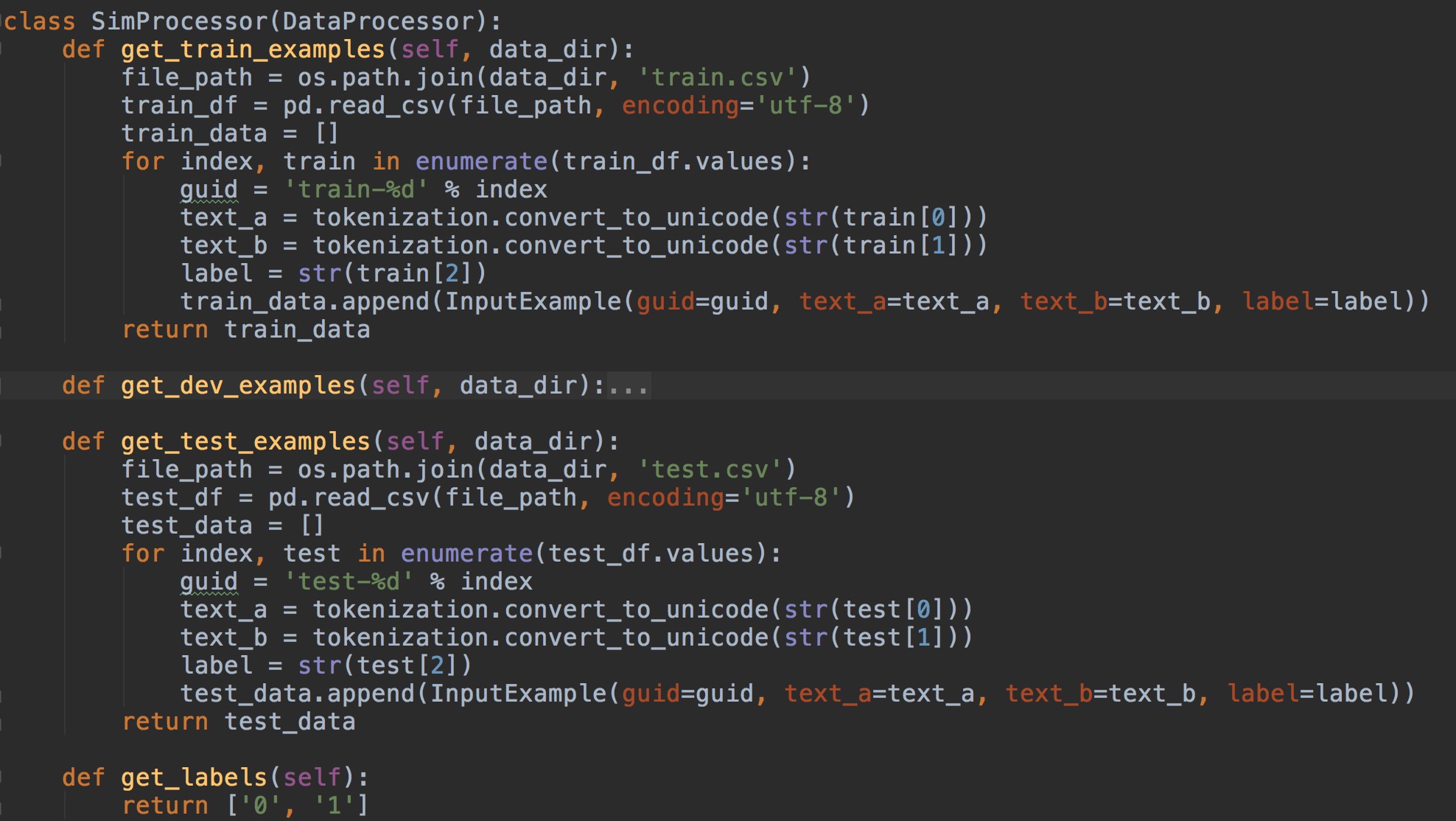
读取的数据需要封装成一个InputExample的对象并添加到list中,注意这里有一个guid的参数,这个参数是必填的,是用来区分每一条数据的。是否进行训练集、验证集、测试集的计算,在执行代码时会有参数控制,我们下文会讲,所以这里的抽象方法也并不是需要全部都重写,但是为了体验一个完整的流程, 建议大家还是简单写一下。
get_labels方法返回的是一个数组,因为相似度问题可以理解为分类问题,所以返回的标签只有0和1,注意,这里我返回的是参数是字符串,所以在重写获取数据的方法时InputExample中的label也要传字符串的数据,可以看到上图中我对label做了一个str()的处理。
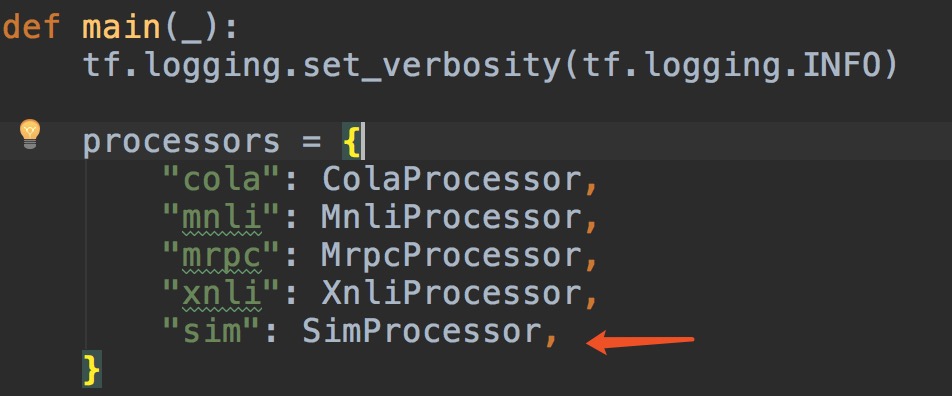
接下来还需要给Processor加一个名字,让我们的在运行时告诉代码我们要执行哪一个Processor,如图我自定义的叫做sim
训练模型
ok,到这里我们已经把Processor编写好了,接下来就是运行代码了,我们来看下run_classifier.py的执行过程。
可以看到,在执行run_classifier.py时需要先输入这5个必填参数,这里我们对参数做一个简单的说明
| 参数 | 说明 |
|---|---|
| data_dir | 训练数据的地址 |
| task_name | processor的名字 |
| vocab_file | 字典地址,用默认提供的就可以了,当然也可以自定义 |
| bert_config_file | 配置文件 |
| output_dir | 模型的输出地址 |
当然还有一些其他的参数,这里给出官方提供的运行参数
export BERT_BASE_DIR=/Users/joe/Desktop/chinese_L-12_H-768_A-12 export MY_DATASET=/Users/joe/Desktop/bert_data python run_classifier.py \ --data_dir=$MY_DATASET \ --task_name=sim \ --vocab_file=$BERT_BASE_DIR/vocab.txt \ --bert_config_file=$BERT_BASE_DIR/bert_config.json \ --output_dir=/tmp/sim_model/ \ --do_train=true \ --do_eval=true \ --init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \ --max_seq_length=128 \ --train_batch_size=32 \ --learning_rate=5e-5\ --num_train_epochs=2.0

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
这里再补充下以下三个可选参数说明
| 参数 | 说明 |
|---|---|
| do_train | 是否做fine-tuning,默认为false,如果为true必须重写获取训练集的方法 |
| do_eval | 是否运行验证集,默认为false,如果为true必须重写获取验证集的方法 |
| dopredict | 是否做预测,默认为false,如果为true必须重写获取测试集的方法 |
预测
执行以上的代码即可训练我们自己的模型了,如果需要使用模型来进行预测,可执行以下命令
python run_classifier.py \
--task_name=sim \
--do_predict=true \
--data_dir=$MY_DATASET \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=/tmp/sim_model \
--max_seq_length=128 \
--output_dir=/tmp/output/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
当然,我们需要在data_dir下有测试数据,测试完成后会在output_dir路径下生成一个test_results.tsv文件,该文件包含了测试用例和相似度probabilities
总结
除了相似度计算,以上的代码完全能够用来做文本二分类,你也可以根据自己的需求来修改Processor,更多的细节大家可以参阅github源码。

