
- 1记burp suite安装全过程_burpsuite安装
- 2【专用】C# ArrayList的用法总结
- 3STM32深入系列02——BootLoader分析与实现_stm32 bootloader
- 4人工智能与机器学习——开启智能时代的里程碑_关于人工智能和机器学习
- 5WSUS补丁服务器搭建和使用(超详细+域策略设置)
- 6vue实现头像上传_vue实现头像上传圆圈
- 734.scrapy解决爬虫翻页问题_scrapy无法翻页的常见原因
- 8GitHub初学——上传、修改本地项目文件到GitHub_github desktop上传修改后的个人文件
- 9北京地区软考证书如何领取?
- 10第三章:Mac OS X内核故事之苹果和开源界的那点事儿:_苹果公共源代码许可证
干货 | YOLOv7目标检测论文解读与推理演示_yolov7论文
赞
踩
导读
本文主要介绍简化的YOLOv7论文解读和推理测试以及YOLOv7与 YOLO系列的其他目标检测器的比较。(公众号:OpenCV与AI深度学习)

背景介绍
YOLOv7是YOLO系列中最先进的新型目标检测器。根据论文所述,它是迄今为止最快、最准确的实时目标检测器,最好的模型获得了56.8%的平均精度(AP),这是所有已知目标检测器中最高的,各种模型的速度范围在 5~160 FPS。
本文主要介绍简化的YOLOv7论文解读和推理测试以及YOLOv7与 YOLO系列的其他目标检测器的比较。
YOLOv7通过将性能提升一个档次建立了重要的基准。从YOLOv4开始在极短的时间内,我们看到YOLO家族的新成员接踵而至。每个版本都引入了一些新的东西来提高性能。早些时候,我们已经详细讨论了以前的 YOLO 版本。在下面查看YOLO 系列介绍:https://learnopencv.com/category/yolo/
YOLO的一般架构
YOLO架构基于FCNN(全卷积神经网络),然而,基于Transformer的版本最近也被添加到了YOLO 系列中。我们将在另一篇文章中讨论基于 Transformer 的检测器。现在,让我们关注基于FCNN的 YOLO 目标检测器。
YOLO 框架具有三个主要组件:
-
-
-
Backbone
-
Head
-
Neck
-
-
Backbone主要提取图像的基本特征,并通过Neck将它们馈送到Head。Neck收集由Backbone提取的特征图并创建特征金字塔。最后,头部由具有最终检测的输出层组成。下表显示了YOLOv3、YOLOv4和YOLOv5 的总体架构。
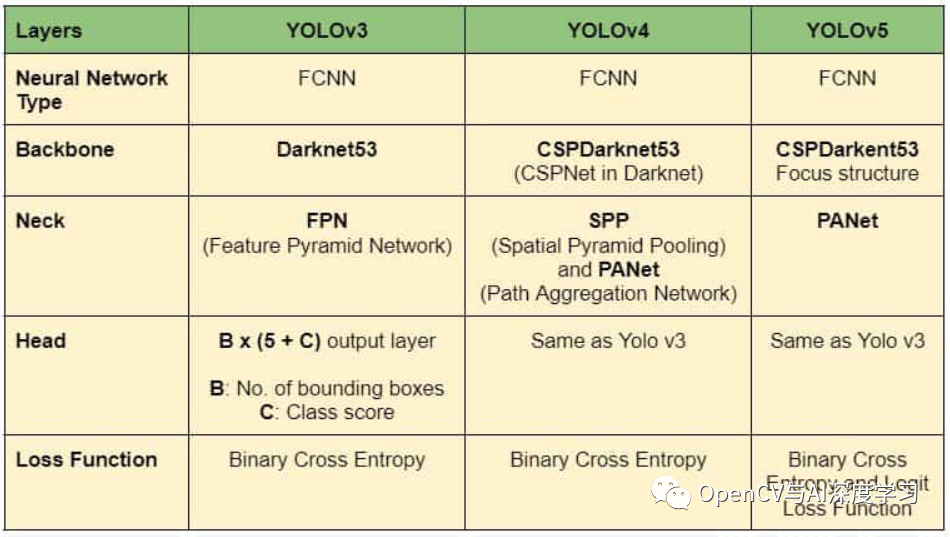
YOLOv7有什么新功能?
YOLOv7通过引入多项架构改革提高了速度和准确性。与Scaled YOLOv4类似,YOLOv7主干不使用 ImageNet预训练的主干。相反,模型完全使用 COCO 数据集进行训练。由于YOLOv7是由Scaled YOLOv4 的同一作者编写的,因此可以预料到这种相似性。YOLOv7 论文中引入了以下主要变化,我们将一一进行介绍:
-
-
-
架构改革
-
-
E-ELAN(扩展高效层聚合网络)
-
基于串联模型的模型缩放
-
-
可训练的 BoF(赠品袋)
-
-
计划重新参数化卷积
-
粗为辅助,细为Lead Loss
-
-
-
YOLOv7架构
该架构源自 YOLOv4、Scaled YOLOv4 和 YOLO-R。以这些模型为基础,进行了进一步的实验以开发新的和改进的 YOLOv7。
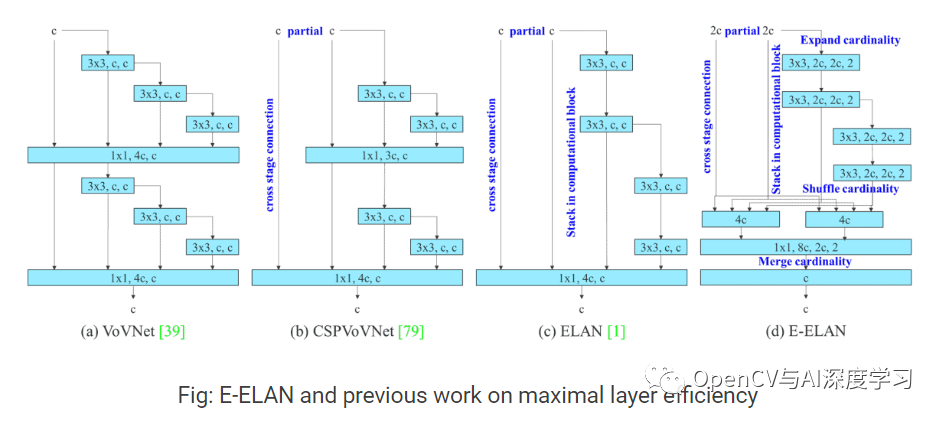
【1】YOLOv7论文中的E-ELAN(Extended Efficient Layer Aggregation Network)
E-ELAN是 YOLOv7主干中的计算块。它从先前对网络效率的研究中汲取灵感。它是通过分析以下影响速度和准确性的因素而设计的。
-
-
-
内存访问成本
-
输入输出通道比
-
元素明智的操作
-
激活
-
渐变路径
-
-
提出的E-ELAN使用expand、shuffle、merge cardinality来实现在不破坏原有梯度路径的情况下不断增强网络学习能力的能力。
简单来说,E-ELAN 架构使框架能够更好地学习。它基于 ELAN 计算块。在撰写本文时,ELAN 论文尚未发表。我们将通过添加 ELAN 的详细信息来更新帖子(https://github.com/WongKinYiu/yolov7/issues/17#issuecomment-1179831969)
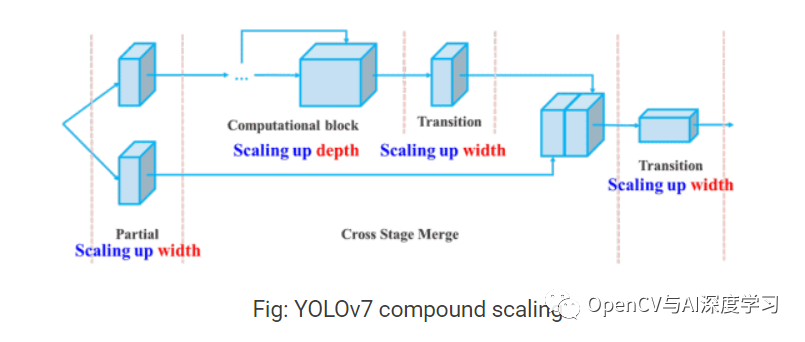
【2】YOLOv7中的复合模型缩放
不同的应用需要不同的模型。虽然有些人需要高度准确的模型,但有些人优先考虑速度。执行模型缩放以适应这些要求并使其适合各种计算设备。
在缩放模型大小时,会考虑以下参数:
-
-
-
分辨率(输入图像的大小)
-
宽度(通道数)
-
深度(网络层数)
-
阶段(特征金字塔的数量)
-
-
NAS(Network Architecture Search)是一种常用的模型缩放方法。研究人员使用它来迭代参数以找到最佳比例因子。但是,像 NAS 这样的方法会进行参数特定的缩放。在这种情况下,比例因子是独立的。
YOLOv7论文的作者表明,它可以通过复合模型缩放方法进一步优化。在这里,对于基于连接的模型,宽度和深度是连贯地缩放的。
YOLOv7可训练的Bag of FreeBies
BoF或Bag of Freebies 是在不增加训练成本的情况下提高模型性能的方法。YOLOv7引入了以下 BoF 方法。
【1】计划重参数化卷积
重新参数化是训练后用于改进模型的一种技术。它增加了训练时间,但提高了推理结果。有两种类型的重新参数化用于最终确定模型,模型级和模块级集成。
模型级别的重新参数化可以通过以下两种方式完成。
-
-
使用不同的训练数据但相同的设置,训练多个模型。然后平均它们的权重以获得最终模型。
-
取不同时期模型权重的平均值。
-
最近,模块级别的重新参数化在研究中获得了很大的关注。在这种方法中,模型训练过程被分成多个模块。输出被集成以获得最终模型。YOLOv7 论文中的作者展示了执行模块级集成的最佳方法(如下所示)。
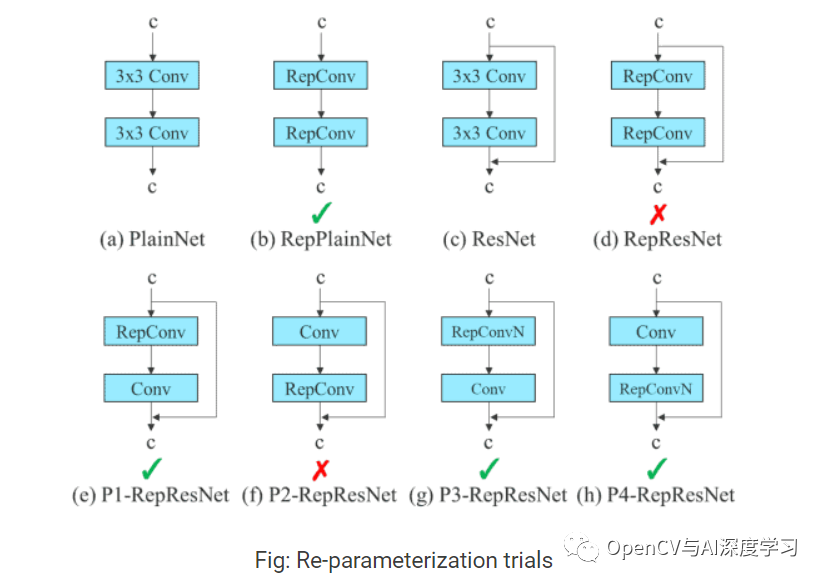
在上图中,E-ELAN 计算块的 3×3 卷积层被替换为 RepConv 层。我们通过切换或替换 RepConv、3×3 Conv 和 Identity 连接的位置来进行实验。上面显示的残余旁路箭头是一个身份连接。它只不过是一个 1×1 的卷积层。我们可以看到有效的配置和无效的配置。在RepVGG 论文中查看有关 RepConv 的更多信息。
包括 RepConv,YOLOv7 还对 Conv-BN(Convolution Batch Normalization)、OREPA(Online Convolutional Re-parameterization)和 YOLO-R 进行了重新参数化,以获得最佳结果。
【2】Coarse for Auxiliary and Fine for Lead loss
正如你现在已经知道的那样,YOLO 架构包括主干、颈部和头部。头部包含预测的输出。YOLOv7 不以单头为限。它有多个头可以做任何想做的事情。是不是很有趣?
然而,这并不是第一次引入多头框架。深度监督是 DL 模型使用的一种技术,它使用多个头。在 YOLOv7 中,负责最终输出的 head 称为Lead Head。而中间层用来辅助训练的头叫做辅助头。
在辅助损失的帮助下,辅助头的权重被更新。它允许深度监督并且模型学习得更好。这些概念与Lead Head和Label Assigner 密切相关。
标签分配器是一种将网络预测结果与基本事实一起考虑然后分配软标签的机制。需要注意的是,标签分配器不会生成硬标签,而是生成软标签和粗标签。
Lead Head Guided Label Assigner 封装了以下三个概念。
-
-
-
Lead Head
-
Auxiliary Head
-
Soft Label Assigner
-
-
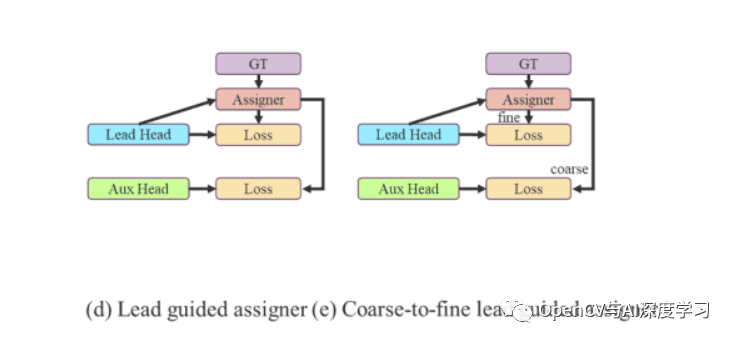
YOLOv7 网络中的 Lead Head 预测最终结果。基于这些最终结果生成软标签。重要的部分是基于生成的相同软标签计算前导头和辅助头的损失。最终,两个头部都使用软标签进行训练。如上图左图所示。
有人可能会问,“为什么要使用软标签?”。作者在论文中说得很好:
“之所以这样做,是因为lead head具有比较强的学习能力,所以由它生成的软标签应该更能代表源数据和目标之间的分布和相关性。……通过让较浅的辅助头直接学习领头人学习过的信息,领头人将更能专注于学习尚未学习的残留信息。”
现在,进入从粗到细的标签,如上图右图所示。实际上,在上述过程中,生成了两组不同的软标签。
-
-
-
精细标签用于训练训练 lead head
-
粗略标签用于训练辅助头部
-
-
精细标签与直接生成的软标签相同。然而,为了生成粗略的标签,更多的网格被视为正目标。这是通过放宽正样本分配过程的约束来完成的。
YOLOv7的实验和结果
所有 YOLOv7 模型在 5 FPS 到 160 FPS 范围内的速度和精度都超过了之前的目标检测器。下图很好地说明了 YOLOv7 模型与其他模型相比的平均精度 (AP) 和速度。
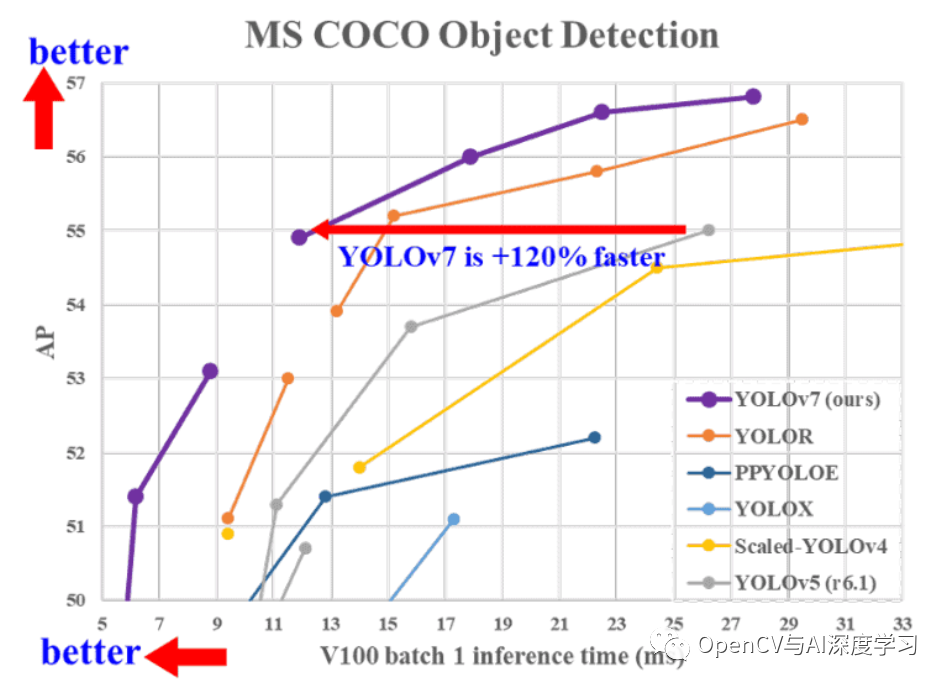
从上图可以看出,从 YOLOv7 开始,无论是速度还是准确率,其他模型都无法与 YOLOv7 竞争。
注意:我们进一步讨论的结果来自YOLOv7 论文,其中所有推理实验都是在 Tesla V100 GPU 上完成的。所有 AP 结果都是在 COCO 验证或测试集上完成的。
【1】mAP 比较:YOLOv7 与其他模型
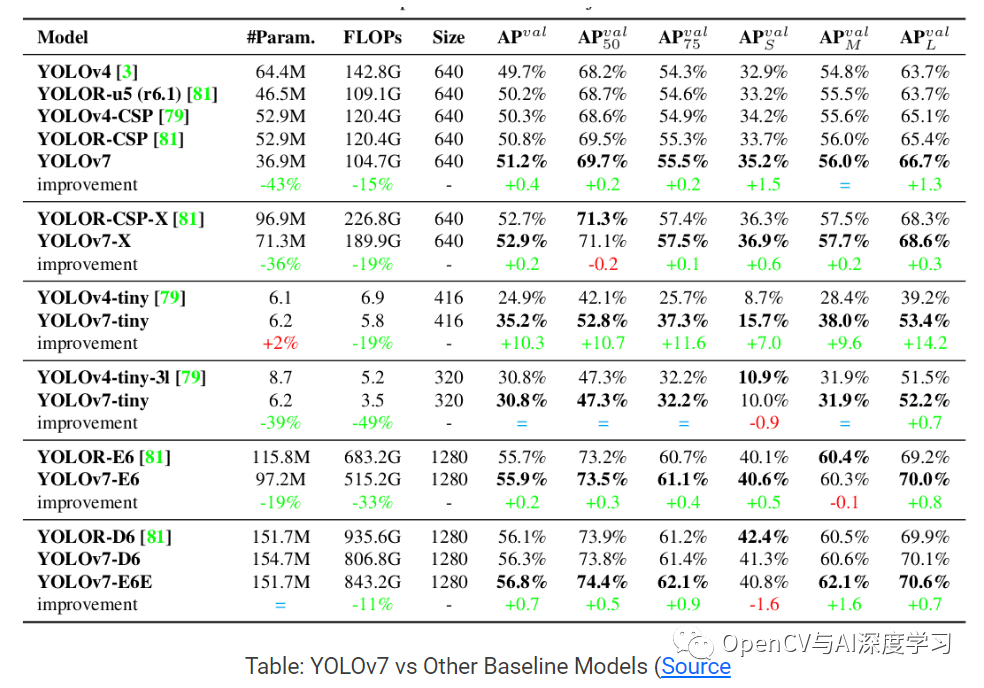
上述结果大多根据一组特定模型的一系列参数组合在一起。
-
-
-
从 YOLOv7-Tiny 模型开始,它是家族中最小的模型,参数刚刚超过 600 万。它的验证 AP 为 35.2%,击败了具有相似参数的 YOLOv4-Tiny 模型。
-
-
-
-
-
具有近 3700 万个参数的 YOLOv7 正常模型提供了 51.2% 的 AP,再次击败了具有更多参数的 YOLOv4 和 YOLOR 的变体。
-
-
-
-
-
YOLO7 系列中较大的型号,YOLOv7-X、YOLOv7-E6、YOLOv7-D6 和 YOLOv7-E6E。所有这些都击败了各自的 YOLOR 模型,它们的参数数量相似或更少,AP 分别为 52.9%、55.9%、56.3% 和 56.8%。
-
-
现在,YOLOv7超越的不仅仅是YOLOv4和YOLOR模型。将验证 AP 与具有相同范围内参数的YOLOv5和 YOLOv7 模型进行比较,很明显 YOLOv7 也击败了所有 YOLOv5 模型。
【2】FPS 比较:YOLOv7 与其他模型
YOLOv7 论文中的表 2提供了 YOLOv7 与其他模型的 FPS 的全面比较,以及尽可能在 COCO 测试集上的 AP 比较。
已经确定 YOLOv7 在 5 FPS 到 160 FPS 的范围内具有最高的 FPS 和 mAP。所有 FPS 比较均在 Tesla V100 GPU 上完成。
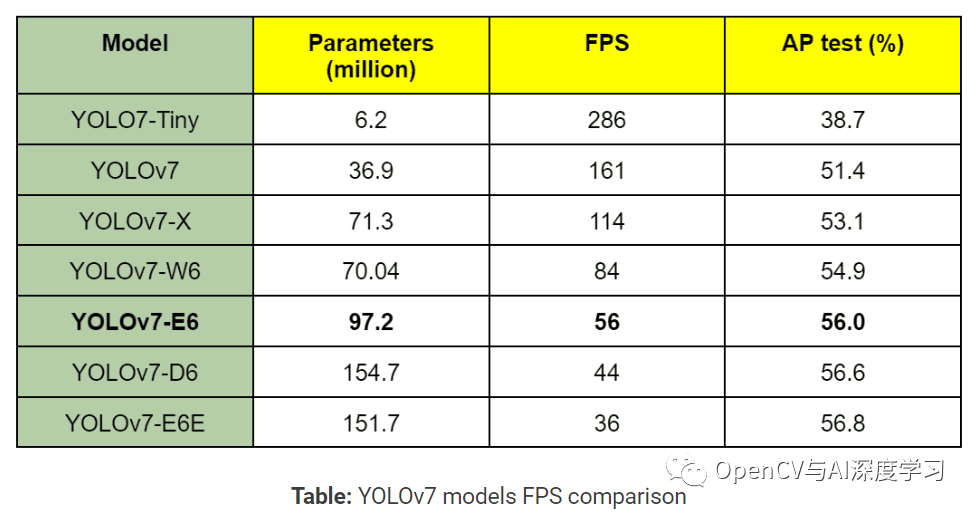
YOLOv7-E6 模型(上面突出显示)在 V100 GPU 上以 56 FPS 运行,测试 AP 为 56%。这超过了基于变压器的SWIN_L Cascade-Mask R-CNN模型(9.2 FPS,53.9% AP)和基于卷积的ConvNeXt-XL(8.6 FPS,55.2% AP)。这很重要,因为其他两种型号即使在 A100 GPU 上也提供更少的 FPS,与 V100 GPU 相比,A100 GPU 更强大。
值得注意的是,没有一个 YOLOv7 模型适用于移动设备/移动 CPU(如作者在论文中所述)。
YOLOv7-Tiny、YOLOv7 和 YOLOv7-W6 分别用于边缘 GPU、普通(消费者)GPU 和云 GPU。这意味着 YOLOv7-E6 和 YOLOv7-D6 以及 YOLOv7-E6E 也仅适用于高端云 GPU。尽管如此,所有 YOLOv7 模型在 Tesla V100 GPU 上的运行速度都超过了 30 FPS,超过了实时 FPS。
上述实验结果表明,YOLOv7 模型在速度和准确度上确实优于目标检测器。
YOLOv7目标检测推理
现在,让我们进入博文中令人兴奋的部分,即使用 YOLOv7 对视频进行推理。我们将使用 YOLOv7 和 YOLOv7-Tiny 模型运行推理。除此之外,我们还将将结果与 YOLOv5 和 YOLOv4 模型的结果进行比较。
注意:此处显示的所有推理结果均在具有6 GB GTX 1060(笔记本 GPU)、第 8 代 i7 CPU 和 16 GB RAM 的机器上运行。
如果您打算在自己的视频上运行对象检测推理实验,则必须使用以下命令克隆 YOLOv7 GitHub 存储库。
git clone https://github.com/WongKinYiu/yolov7.git然后,您可以使用 detect.py 脚本对您选择的视频进行推理。您还需要从此处下载yolov7-tiny.pt和yolov7.pt预训练模型。
在这里,我们将对描述以下三种不同场景的三个视频进行推理。
-
-
-
第一个视频是测试 YOLOv7 物体检测模型在小而远的物体上的表现。
-
第二个视频有很多人描绘了一个拥挤的场景。
-
第三个视频是许多 YOLO 模型(v4、v5 和 v7)在检测对象时犯了同样的一般错误的视频。
-
-
此处的 YOLOv7 结果针对所有三个视频的Tiny和Normal模型一起显示。这将帮助我们以简单的方式比较每个结果的结果。
让我们看看使用 YOLOv7-Tiny(顶部)和 YOLOv7(底部)模型对第一个视频的检测推理结果。以下命令分别用于使用 Tiny 和 Normal 模型运行推理。
python detect.py --source ../inference_data/video_1.mp4 --weights yolov7-tiny.pt --name video_tiny_1 --view-imgpython detect.py --source ../inference_data/video_1.mp4 --weights yolov7.pt --name video_1 --view-img

我们可以立即看到 YOLOv7-Tiny 模型的局限性。它无法检测到非常遥远和小的汽车、摩托车和人。YOLOv7 模型能够更好地检测这些物体。但这不是故事的全部。虽然 YOLO7-Tiny 的表现不是那么好,但它比 YOLOv7 快得多。虽然 YOLOv7 提供大约 19 FPS 的速度,但 YOLOv7-Tiny 能够以大约 42 FPS 的速度运行它,这远高于实时速度。
现在,让我们看看描述拥挤场景的第二个视频的结果。我们使用与上面相同的命令,但根据视频路径和名称更改 –source 和 –name 标志的值。


与 YOLOv7-Tiny 模型相比,YOLOv7 模型能够以更少的波动和更高的信心检测到人。不仅如此,YOLOv7-Tiny 还错过了一些红绿灯和远处的人。
现在让我们对最终视频进行推理,该视频显示了所有 YOLOv7 模型中的一些一般故障案例。

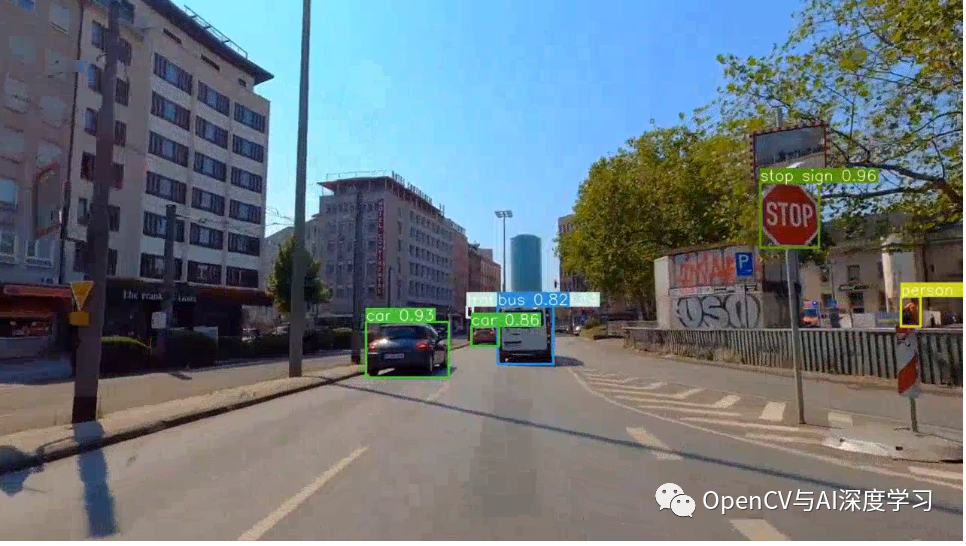
我们可以看到两个模型中的一些普遍错误:
-
-
-
检测其他路标作为停车标志。
-
将禁止的道路符号错误地检测为人。
-
-
正如我们稍后将看到的,上述两个错误在 YOLOv4 和 YOLOv5 中很常见。
尽管 YOLO7-Tiny 比 YOLOv7 模型犯的错误更多,但它的速度要快得多。平均而言,YOLOv7-Tiny 的运行速度超过 40 FPS,而 YOLOv7 模型的运行速度略高于 20 FPS。
YOLOv4、YOLOv5-Large、YOLOv7模型比较
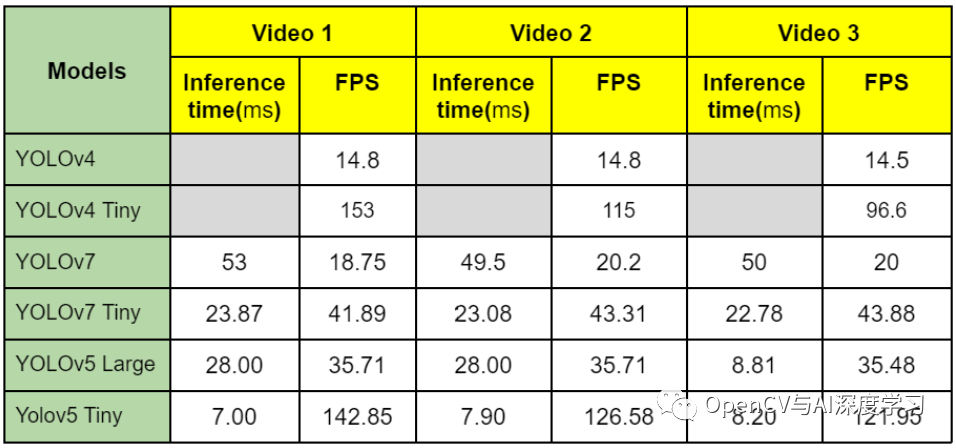
以下三个视频展示了其中一个视频上 YOLOv4、YOLOv5-Large 和 YOLOv7 模型(从上到下)的比较。这将使我们对每个模型在各种场景中的表现有一个适当的定性概念。



下表显示了三个视频中三个模型的不同变体的 FPS 和运行时间。
YOLOv7简单总结
至此,我们结束了对 YOLOv7 的介绍,本文内容简单总结如下:
-
-
YOLO 的一般架构由 Backbone、Neck 和 Head 组成。
-
YOLOv7 的架构改革。
-
E-ELAN
-
YOLOv7 中的复合模型缩放
-
-
YOLOv7 中可训练的免费赠品包。
-
YOLOv7 中的重新参数化
-
粗为辅助,细为Lead Loss
-
-
如何使用 YOLOv7 GitHub 存储库运行目标检测推理。
-
YOLOv7 在速度和准确度上超过了所有实时目标检测器。
-
FPS:5 – 165
-
mAP:51.4% – 56.8%
-
YOLOv7 减少了 40% 的参数和 50% 的计算,但提高了性能。
-
参考链接:
1. https://learnopencv.com/yolov7-object-detection-paper-explanation-and-inference/
2. YOLOv7论文:https://arxiv.org/pdf/2207.02696.pdf
3. YOLOv7 GitHub:https://github.com/WongKinYiu/yolov7

