
- 1RDD的创建方式(Python)_创建一个包含1到10的整数的rdd
- 2阿里云全球技术服务部_测开岗实习生一面(7/15)_阿里云全球技术服务部怎么样
- 3Android开发:文本控件详解——EditText(一)基本属性
- 4css制作0.5px的线条_css画0.3px的线
- 5Vue进阶之Vue项目实战(一)
- 6ESP8266作为arduino D1 wifi模块应用时引脚序号说明(与UNO对比异同)2.5.0版本开发板库_uno和d1开发板区别
- 7vslam论文8:EPLF-VINS: Real-Time Monocular Visual-InertialSLAM With Efficient Point-Line Flow Features
- 8Windows下使用linux_windows怎么用linux
- 9【感受C++的魅力】:用C++演奏歌曲《起风了》——含完整源码_c++演奏起风了
- 10【大数据 OLAP ClickHouse 引擎】ClickHouse 系统架构和存储引擎实现原理 : 为什么 ClickHouse 这么快? Why is ClickHouse so fast?_fastapi clickhouse
MapTR文章研读
赞
踩
MapTR为在线矢量化地图构建提供有效的端到端的网络结构。作者提出一种统一的基于排列的建模方法,即将地图元素的等效排列作为点集进行建模,避免地图元素模糊定义并且可以简化学习。在网络结构上,作者采用一种分层的query embedding方法来灵活的编码结构性地图信息并且使用分层的二分匹配方法学习地图元素信息。
MapTR在nuScenes数据集上比现存的矢量化地图构建方法性能更好,MapTR-nano在RTX3090上推理速度为25.1FPS,比现存的实时的基于视觉方法快了8倍,与此同时,其mAP比其他方法高了3.3;MapTR-tiny比现有的多模态方法mAP高了13.5,并且速度更快。在质量评估结果中展示MapTR在复杂多样的驾驶场景下可以稳定的进行地图构建。
代码见:hustvl/MapTR: [ICLR’23 Spotlight] MapTR: Structured Modeling and Learning for Online Vectorized HD Map Construction (github.com)
1. 基于排列的建模方法
MapTR主要以一种结构性的行为去建模和学习高精地图。高精地图是静态地图元素的集合,包括人行横道、车道线、路沿等等。对于结构性建模来讲,MapTR将地图元素简要概括成封闭形状(包括人性横道)和开放形状(包括车道线)。通过沿着形状边沿序列采样形成点集,封闭形状被描述成多边形(polygon),开放形状被描述成线段(polyline)。
在介绍之前,先看下图:

在上图(a)中在车道线的两边有着相反的标识,那该车道线的方向就是不确定的,车道线的某个方向的终点也可视为起始点。在图1(b)中人行横道的顺序可以是逆时针也可是顺时针,改变点集排列顺序不影响多边形的几何形状。从图1可以看到,如果将点集强制规定成某一特定排列方式会导致模棱两可的定义。
故在本文中,每一个地图元素都有如下定义:
(
V
,
Γ
)
{(V,\Gamma)}
(V,Γ),
V
=
{
v
j
}
j
=
0
N
v
−
1
{V=\{v_j\}_{j=0}^{N_v-1}}
V={vj}j=0Nv−1表示地图元素点的集合,在元素轮廓等距离采样获得点集V,其中
N
v
{N_v}
Nv表示点的数目。
Γ
{\Gamma}
Γ表示点集V的排列,枚举了所有可能的排列方法。
对于线段来说,有两种排列方法:

对于多边形来说,有
2
∗
N
v
{2*N_v}
2∗Nv中等效排列方法:

从下图中也可以看到,对于线段和多边形来说,同一个点集有着不同的排列方式。

2. MapTR结构
MapTR采用encoder-decoder结构,具体网络结构见下图:

backbone
MapTR在encoder结构中首先通过resnet提取各路图片特征
Map Encoder
然后使用基于2D-to-BEV的GKT方法将各路特征转换到bev特征。
Map Decoder
作者采用分层的query embedding方法来编码每一个地图元素。定义实例级别的queries为 { q i ( i n s ) } i = 0 N − 1 {\{q_i^{(ins)}}\}_{i=0}^{N-1} {qi(ins)}i=0N−1 ,和一个点级别的queries为 { q j ( p t ) } j = 0 N v − 1 {\{q_j^{(pt)}}\}_{j=0}^{N_v-1} {qj(pt)}j=0Nv−1 ,点级别的queries是对所有地图元素共享的。对于第i个地图元素实例中的第j个点的queries定义如下:

map decoder部分包含多个级联的decoder层用来更新分层的queries。在每一个decoder层,采用MHSA(Multi-Head Self-Attention)交互queries信息。采用Deformable Attention将分层queries和bev特征融合。 会预测点pij在bev平面上二维的点坐标(xij,yij),然后采样点pij对应的bev特征用来更新queries。
Head
预测头包含分类分支和点回归分支。其中分类分支预测实例类别分数,点的回归分支预测点集。
3. 分层匹配方法
MapTR参考DETR结构,设定有N个地图元素,其中N值大于在场景中实际地图元素数目。 Y ^ = { y ^ i } i = 0 N − 1 {\hat Y=\{\hat y_i\}_{i=0}^{N-1}} Y^={y^i}i=0N−1为 N {N} N个地图元素的预测结果集合, Y = { y i } i = 0 N − 1 {Y=\{ y_i\}_{i=0}^{N-1}} Y={yi}i=0N−1为真实标签的地图元素集合,其中 y i = ( c i , V i , Γ i ) {y_i=(c_i,V_i,\Gamma_i)} yi=(ci,Vi,Γi),不满 N {N} N个地图元素的,用空值补满。为了结构性地图的建模和学习,MapTR引进分层匹配方法包括实例级别(instance-level)匹配和点级(point-level)匹配方法。
Instance-level匹配方法:
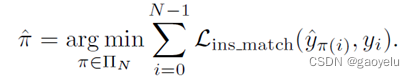

其中,公式第一项为类别匹配损失函数,采用Focal Loss。第二项为位置匹配损失,文中为了计算
L
p
o
s
i
t
i
o
n
{L_{position}}
Lposition比较了两种计算方法,Chamfer distance和point2point,其中point2point方法和下面讲的point-level匹配方法类似,将所有点对计算Manhattan距离后累加之和作为损失计算最佳。下表是两种方法的比较。

计算得到损失矩阵,使用匈牙利匹配来找到最优匹配。
point-level匹配方法:
在实例级别匹配后,每一个预测得到的地图元素都和一个真实地图元素对应,为了进一步确定预测的地图元素点集的排列方式,作者利用point2point方法(即计算点对的曼哈顿距离)实现下列损失最小:

即将预测得到的元素点集和与之对应的真实元素点集的所有排列分别计算点对的曼哈对距离和,取距离最小的一种排列方法作为预测点集的排列方法。
4. 损失函数

包括类别损失、点对损失和边界方向损失三部分。
其中类别损失定义:

点对损失定义如下

边界方向损失定义如下:

Point2point损失仅对对线段和多边形的节点进行限制,没有对点之间的边进行约束。为了准确地表示地图元素,作者提出将匹配的预测边和GT边的余弦相似度作为loss。
5. 实验结果



