
- 1C++之A*算法的简单实现_c++ a*算法
- 2出海企业首选的免费开源财务管理系统解决方案
- 3C语言写二叉树_创建一颗二叉树的代码
- 4SpringBoot学习之Redis下载安装启动【Mac版本】(三十七)_mac redis下载
- 5C++中使用sort对常见容器排序_c++ vector sort
- 6深入分布式缓存:从原理到实践
- 7IDEA直接拉取git上项目、push新项目到git上&导入拉取的maven项目_idea 拉取公司项目工程
- 8学习Python的好处是什么?真的有用吗?_学python有什么好处
- 9实验报告5-Spring MVC实现页面
- 10Flutter应用——生命周期管理 Lifecycle Management_flutter 如何管理activity的生命周期
为什么-关于因果关系的新科学 | 导言_为什么关于因果关系的新科学
赞
踩
参考链接: 小样本学习与智能前沿
Reference[原文]: Joselynzhao.top & 夏木青 | 为什么-关于因果关系的新科学 | 导言
[美]朱迪亚·珀尔
[美]达纳·麦肯齐 著
推荐序
以平实的话语介绍了因果推断的理论建构
对渴望了解因果推断的人们来说,它既是因果关系科学的入门书,又是关于这门学问从萌发到蓬勃发展的一部简史,其中不乏对当前的人工智能发展现状的反思和对未来人工智能发展方向的探索。
the book of why
the book of change
这样一本重量级的科普读物,即便是对于一
位专门从事人工智能或机器学习方面的研究的学者而言,如果其以前从未接触过因果推断,那么在初次阅
读时他也未必能完全掌握书中的内容,因此这本书对于没有专业背景的普通读者的阅读难度可想而知。
对
于没有概率统计基础的读者来说,笔者的阅读建议是略过数学细节,着重抓住内容大意;而对于有一定概
率统计基础的读者来说,笔者认为在阅读时一定不能放过正文中的数学精髓,这本书中的数学公式不多不
少,刚好自圆其说。
古人云:“博学之,审问之,慎思之,明辨之,笃行之。”此话正合此书精神,与读者共勉。
前言
那些依赖于因
果信息、长期被认为是形而上的或无法解决的实际问题,现在也可以借助初等数学加以解决了。简言之,
因果论已经完成了数学化。”
完成一个三位一体的使命:
- 首先,用非数学的语言阐述因果革命的知识内涵,说明它将怎样影响我们的生活和未来。
- 其次,分享在解决重要的因果问题时,我们的科学家前辈走过的英勇征
程,无论成败,这些故事都值得讲述。 - 最后,回溯因果革命在人工智能领域的发源地,目的是向你介绍如何开发出用我们的母语——因果语言进行交流的机器人.
新一代机器人应该能够向我们解释事情为何发生,为何机器人以它们选择的某种方
式做出反应,以及大自然为何以这样而非那样的方式运作。一个更加雄心勃勃的目标是,它们也应该能够
让我们进一步认识人类自身:我们的思维为什么以这样的方式运行,以及理性思考原因和结果、信任和遗
憾、目的和责任究竟意味着什么。
导言: 思维胜于数据
每一门蒸蒸日上的科学都是在其符号系统的基础上繁荣发展起来的。
——奥古斯都·德·摩根(1864)
以数学形式表达因果关系的能力让我们得以开
发出许多强大的、条理化的方法,将我们的知识与数据结合起来,解决实际问题.
阻碍因果
推断这一科学诞生的最大障碍,是我们用以提出因果问题的词汇和我们用以交流科学理论的传统词汇之间
的鸿沟。
我们可以用数学公式表示关系, 却很难说清楚里面的因果.
气压计读数B可以用来表示实际的大气压P。我们可以轻而易举地用方程式来表示这种关系,
B=kP,其中k是某个比例常数。
字母k、B或P三者中的任意一个在数学上都没有凌驾于其他两个之上的特权。那么,我们怎样才能表
达这个确凿无疑的事实,即是大气压导致了气压计读数的变化,而不是反过来?
倘若连这一事实都无法表
达,我们又怎能奢望去表达其他许多无法用数学公式来表达的因果推断,例如公鸡打鸣不会导致太阳升
起?
用公式去表达事实.
众所周知,按动开关按钮会
导致一盏灯的打开或关闭,夏日午后的闷热空气会促使当地冰激凌店的销售额增加。那么,为什么科学家
们没有像用公式表达光学、力学或几何学的基本法则那样,用公式去捕捉这些显而易见的事实?
随着人类求知欲的不断增
强,以及社会现实开始要求人们讨论在复杂的法律、商业、医疗等领域的决策情境中出现的因果问题,我
们终于发现我们缺少一门成熟的科学所应提供的用于回答这些问题的工具和原理。
公鸡打鸣与日出高度相关,但它显然不是日出
的原因。
统计学盲目迷恋这种常识性的观察结论。它告诉我们,相关关系不等于因果关系,但并没
有告诉我们因果关系是什么。
统计学不允许学生们
说X是Y的原因 [2] ,只允许他们说X与Y“相关”或“存在关联”
数据远非万能。数据可以告诉你服药的病人比不服药的
病人康复得更快,却不能告诉你原因何在。也许,那些服药的人选择吃这种药只是因为他们支付得起,即
使不服用这种药,他们照样能恢复得这么快。
因果关系演算法由两种语言组成:
其一为因果图(causal diagrams),用以表达我们已知的事物,
其二为类似代数的符号语言,用以表达我们想知道的事物。
因果图是由简单的点和箭头组成的图, 它们能被用
于概括现有的某些科学知识。点代表了目标量,我们称之为“变量”,箭头代表这些变量之间已知或疑似存
在的因果关系,即哪个变量“听从于”哪个变量。这些因果图非常容易绘制、理解和使用.
与图表式的“知识语言”并存的还有一种符号式的“问题语言
如果我们感兴趣的是药物(D)对病人生存期(L)的影响,那么我们的问题可以用符号写成:P(L|do(D))
如果一个身体状况具有足够代表性的病人服用了这种药,那么他在L年内存活的概率§是多少?
在许多情况下,我们可能还希望对P(L│do(D))和
P(L|do(not-D))进行比较,后者描述的是拒绝接受相应处理(服药)的病人,也称“对照组”病人的情
况。其中,do算子表明了我们正在进行主动干预而非被动观察,这一概念是经典统计学不可能涉及的。
我们必须调用一个干预算子do(D)来确保观察到的病人存活期L的变化能完全归因于药物本
身,而没有混杂其他影响寿命长短的因素。如果我们不进行干预,而是让病人自己决定是否服用该药物,
那么其他因素就可能会影响病人的决定,而服药和未服药的两组病人的存活期差异也将无法再被仅仅归因于药物。
随机地指示
一些病人服用药物或不服用药物,而不考虑先决条件如何,则可以去除两组病人之间原有的差异,提供有
效的比较结果。
在数学上,我们把自愿服药的病人的生存期L的观测频率记作P(L|D)
表示生存期L的概率§是以观察到病人服用药物D为条件的
注意P(L|D)与
P(L|do(D))完全不同。观察到(seeing)和进行干预(doing)有本质的区别,
缺少P(L|do(D)),而完全由P(L|D)统治的世界将是十分荒诞的。
在这个世界中,病人不去就诊就能减少人们患重病的概率,城市解
雇消防员就能减少火灾的发生
因果革命最重要的成果之一就是解释了如何在不实际实施干预的情况下预测干预的效果。
当我们感兴趣的科学问题涉及反思性的思考时,我们通常会诉诸另一种类型的表达形式,这种表达形
式是因果推断科学独有的,我们称之为反事实”(counterfactual)
例如,假设乔在服用了药物D一个月后
死亡,那么我们现在关注的问题就是这种药物是否导致了他的死亡。为了回答这个问题,我们需要想象这
样一种情况:假如乔在即将服药时改变了主意,他现在会活着吗?
经典统计学只关注总结数据,因此它甚至无法提供一种语言让我们提出上面那个问题。
因果推断则不仅提供了一种表达符号,更重要的是,它还提供了一种解决方案。
反事实推理涉及假设分析(what-ifs),这可能会使一些读者质疑其科学性。经验观察永远无
法证实或反驳这些问题的答案。
反事实并非异想天开之物,而是反映了现实世界运行模式的特有结构。
我对语言的强调也源于一个坚定的信念,即语言会塑造我们的思想。你无法回答一个你提不出来的问题,
你也无法提出一个你的语言不能描述的问题。
20世纪80年代末,我意识到智能机器
缺乏对因果关系的理解,这也许是妨碍它们发展出相当于人类水平的智能的最大障碍。
现实的蓝图
而现在,我提议引入另一个术语——“因果模型”。
图0.1展示了一个“因果推断引
擎”的蓝图,此引擎将帮助未来的人工智能进行因果推理。更重要的是,它不仅仅是一张关于未来的蓝
图,也是一份指南,用于指导我们发现在当今的科学应用中,因果模型是如何发挥作用的,以及它们与数
据之间的相互作用是怎样的。
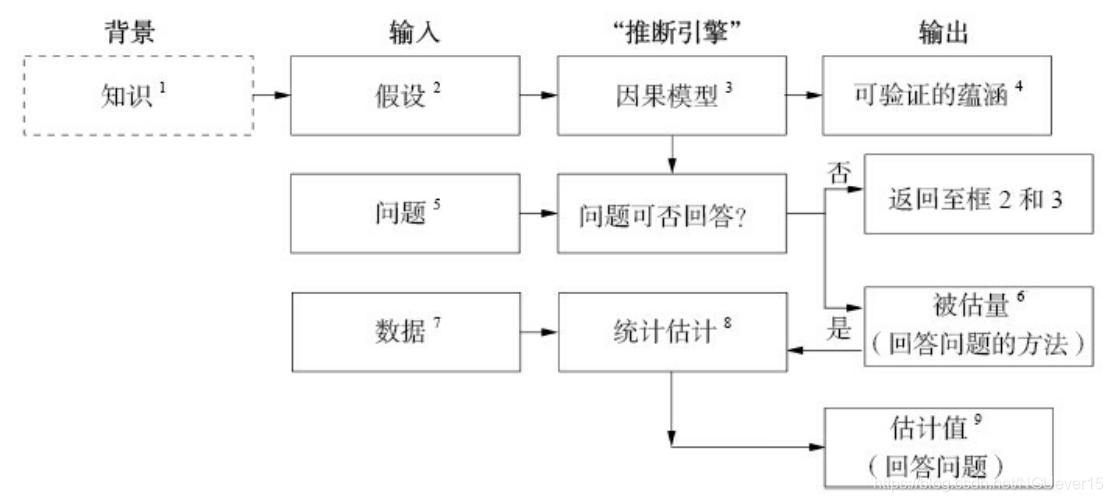
图0.1 “因果推断引擎”能够将数据与因果知识相结合生成目标问题的答案。虚线框不是引擎的组成部分,但它是构建引擎
的必要基础。箭头也可以从方框4和方框9指向方框1, 但在这里为简化图示进行了省略。
因果推断引擎是一种问题处理机器,它接收三种不同的输入——假设、问题和数据,并能够产生三种
输出。第一种输出是“是/否”判断,用于判定在现有的因果模型下,假设我们拥有完美的、无限的数据,那
么给定的问题在理论上是否有解。如果答案为“是”,则接下来推断引擎会生成一个被估量。这是一个数学
公式,可以被理解为一种能从任何假设数据中生成答案的方法,只要这些数据是可获取的。最后,在推断
引擎接收到数据输入后,它将用上述方法生成一个问题答案的实际估计值,并给出对该估计值的不确定性
大小的统计估计。这种不确定性反映了样本数据集的代表性以及可能存在的测量误差或数据缺失。
以“药物D对病人生存期L的影响是什么”这个问题为例进行具体分析。
-
“知识”指的是推理主体(reasoning agent)过去的经验,包括过去的观察、以往的行为、接受
过的教育和文化习俗等所有被认为与目标问题有关的内容。“知识”周围的虚线框表示它仍隐藏在推理主
体的思想中,尚未在模型中得到正式表达。 -
科学研究总是要求我们给出简化的假设,这些假设也就是研究者在现有知识的基础上认为有必要明
确表述出来的陈述。 -
因果模型有多种表现形式,包括因果图、结构方程、逻辑语句等。
-
以因果模型的路径来表示的变量之间的听从模式通常会导向数据中某种显而易见的模式或相关关
系。这些模式可被用于测试模型,因此也被称为“可验证的蕴涵”(testable implications) [3] -
向推理引擎提交的问题就是我们希望获得解答的科学问题,这一问题必须用因果词汇来表述。
例如,我们现在感兴趣的问题是:P(L|do(D))是什么?因果革命的主要成就之一就是确保了这一语言在
科学上容易理解,同时在数学上精确严谨。 -
被估量“estimand”来自拉丁语,意思是“需要估计的东西”。它是我们从数据中估算出来的统计量。一旦这个量被估算出来,我们便可以用它来合理地表示问题的答案。虽然被估量的表现形式是一个概
率公式,如P(L|D,Z)×P(Z),但实际上它是一种方法,可以让我们根据我们所掌握的数据类型回答
因果问题(前提是推断引擎证实了这种数据类型就是我们需要的)。
在当前的因果模型下,无论我们收集到
多少数据,有些问题可能仍然无法得到解答。
例如,如果我们的模型显示D和L都依赖于第三变量Z(比如
疾病的发展阶段),并且,如果我们没有任何方法可以测量Z的值,那么问题P(L|do(D))就无法得到
解答。在这种情况下,收集数据完全就是浪费时间。相反,我们需要做的是回过头完善模型,具体方式则
是输入新的科学知识,使我们可以估计Z的值,或者简化假设(注意,此处存在犯错的风险),例如假设Z对D的影响是可以忽略不计的。
-
数据可以被视作填充被估量的原料。数据本身不具备表述因果关系的能力。数据告诉我们的只是数量信息,如P(L|D)或P(L|D,Z)的值。基于模型假设,该表达式在逻辑上等价于我们所要回答的因果问题,比说
P(L|do(D))。 -
我们也无法避免根据样本测量的概率无法代
表整个总体的相应概率的可能性。幸运的是,依靠机器学习领域所提供的先进技术,统计学科为我们提供
了很多方法来应对这种不确定性,这些方法包括最大似然估计、倾向评分、置信区间、显著性检验等。 -
最后,如果我们的模型是正确的且数据是充分的,那么我们就获得了这个待解决的因果问题的答
案,比如“药物D使糖尿病患者Z的生存期L增加了30%,误差±20%。”啊哈!现在,这一答案将被添加到
我们的科学知识(方框 1)中。而如果这一答案与我们的预期不符,则很可能说明我们需要对因果模型做
一些改进(方框3)
据假设确定了因果模型,提出了我们想要解决的科学问题,推导出被估量。
如果拥有一个因果模型,我们就可以在大部分情况下从未经干预处理的数据中预测干
预的结果了。
当我们试图回答反事实问题,比如“假如我们采取了相反的行动会发生什么”时,因果模型的重要性就
更加引人注目了。
如果我们想让机器人回答“为什么”这样的问题, 或者只是试图让它们理解
此类问题的意义,那么我们就必须用因果模型武装它们,并教它们学会如何回答反事实问题,做法就像图
0.1所展示的那样。
因果模型所具备而数据挖掘和深度学习所缺乏的另一个优势就是适应性。
注意在图0.1中,被估量是在我们真正检查数据的特性之前仅仅根据因果模型计算出来的,这就使得因果推断引擎适应性极强,因为无
论变量之间的数值关系如何,被估量都能适用于与定性模型适配的数据。
全书内容概要
- 第一章将观察、干预和反事实这三个台阶组合成因果关系之梯(ladder of causation),这是本
书的核心隐喻。
它将向你揭示利用因果图(我们主要的建模工具)进行推理的基本原理,同时引导你一步
步成为一名精通因果推理的专家。
如果能用一句话来概括本书的内容,那就是“你比你的数据更聪明”。数据不了解因果,而人类了解。
我希望因果推断这门新科学能让我们更好地理解我们是如何做到这件事的,因为除了自我模拟,我们没有
更好的方法来了解人类自身了。与此同时,在计算机时代,这种新的理解也有望被应用于增强人类自身的
因果直觉,从而让我们更好地读懂数据,无论是大数据还是小数据。


