
nlp对语料进行分类
Over the years, we have seen Twitter evolve from just a social media to also a business and news platform. While this growth is excellent, it has also caused an increase in the spread of fake news which can have serious effects around the world.
多年来,我们已经看到Twitter从社交媒体发展成为商业和新闻平台。 尽管这种增长非常出色,但也导致假新闻传播的增加,这可能在世界范围内产生严重影响。
This project aims to address the problem of fake news using real disasters. We will use a dataset of tweets and their corresponding labels to train a model that can predict if a tweet reports fake news about disasters or not.
该项目旨在利用真实灾难解决假新闻问题。 我们将使用推文及其对应标签的数据集来训练一个模型,该模型可以预测推文是否报告有关灾难的虚假新闻。
数据 (Data)
The data was obtained from Kaggle and consists of training data and test data in two separate CSV files. There are 7,613 entries in the training dataset and 3,263 entries in the test dataset.
数据是从Kaggle获得的,由两个单独的CSV文件中的训练数据和测试数据组成。 训练数据集中有7,613个条目,测试数据集中有3,263个条目。
The training dataset contains [id, location, keyword, text and target] columns. The id column has a unique id for each tweet, location and keyword columns contain the location the tweet was sent from and a particular keyword in the tweet respectively; however, not every row has a value in these two columns. The text column contains the main text with URLs if there was a link in the tweet and the target column is for the label of each tweet. All columns are of string datatype apart from the target column which is an integer. The test dataset contains the same columns except the target column.
训练数据集包含[ id,位置,关键字,文本和目标 ]列。 id列对每个推文都有唯一的id, location和keyword列分别包含发送推文的位置和推文中的特定关键字; 但是,并非每一行在这两列中都有一个值。 如果推文中有链接,并且目标列用于每个推文的标签,则文本列将包含带有URL的主要文本。 除目标列(整数)之外,所有列均为字符串数据类型。 除目标列外,测试数据集包含相同的列。
总览 (Overview)
I trained a Gaussian Naive Bayes, Logistic regression and Gradient boosting classifier for this task. The text column was used as the feature because it is a better representation of a tweet while the target column was used as the label.
我为此任务训练了高斯朴素贝叶斯,逻辑回归和梯度提升分类器。 文本列被用作功能,因为当目标列被用作标签时,它可以更好地表示鸣叫。
探索性数据分析 (Exploratory Data Analysis)
For Exploratory Data Analysis (EDA), below is a visualisation of the top ten keywords with the most fake disaster tweets.
对于探索性数据分析(EDA),以下是具有最伪造的灾难推文的前十个关键字的可视化。
import pandas as pdtrain_df = pd.read_csv('train.csv')# Get list of keywords with their count of fake disaster tweets, sort the list in descending orderkeywords= [(i, len(train_df[(train_df['keyword']==i) & (train_df['target']==0)])) for i in train_df['keyword'].unique()]keywords.sort(key = lambda x: x[1], reverse=True)# Plot bar graph of keywords with the most fake disaster tweetsx, y = (zip(*keywords))x = [str(i) for i in (x)][:10]y = [int(i) for i in (y)][:10]清洁和预处理 (Cleaning and Preprocessing)
Regex was used to clean each tweet removing every URL links and other characters apart from alphanumeric characters. The text was left in alphanumeric form because some tweets contained figures which are important. Then the text was preprocessed using Gensim and NLTK, resulting in a tweet being a list of word strings. Preprocessing carried out was lemmatization to reduce words to basic form so they can be analysed as one word irrespective of previous inflections; stemming which gets rids of prefixes and suffixes to reduce words to their root form even if the resulting stem is not a valid word in that language; and tokenization to convert sentences into individual words, known as tokens.
正则表达式用于清除每条推文,除去每个URL链接和除字母数字字符之外的其他字符。 文本以字母数字形式保留,因为某些推文中包含重要的数字。 然后使用Gensim和NLTK对文本进行预处理,从而产生一条推文,即一串单词字符串。 进行的预处理是词义化处理,将单词还原为基本形式,因此可以将它们作为一个单词进行分析,而与以前的词尾变化无关。 去除前缀和后缀的词干,即使单词词干不是该语言中的有效词,也可以将词简化为词根形式; 和标记化将句子转换为单个词,称为标记。
import regex as reimport gensimfrom gensim.utils import simple_preprocessfrom gensim.parsing.preprocessing import STOPWORDSfrom nltk.stem.porter import PorterStemmerfrom nltk.stem import WordNetLemmatizer, SnowballStemmer# Function to preprocess data with Gensimdef preprocess_gensim(text): # Remove non-alphanumeric characters from data text = [re.sub(r'[^a-zA-Z0-9]', ' ', text) for text in text] # Lemmatize, stem and tokenize words in the dataset, removing stopwords text = [(PorterStemmer().stem(WordNetLemmatizer().lemmatize(w, pos='v')) )for w in text] result = [[token for token in gensim.utils.simple_preprocess(sentence) if not token in gensim.parsing.preprocessing.STOPWORDS and len(token) > 3] for sentence in text] return resultWhen comparing NLTK library to Gensim library for stopwords, I discovered the Gensim stopwords collection was more comprehensive than NLTK’s so I decided to go ahead with Gensim stopwords package.
在比较NLTK库和Gensim库中的停用词时,我发现Gensim停用词集合比NLTK的更全面,因此我决定继续使用Gensim停用词包。
import nltkfrom nltk.corpus import stopwordsimport gensimfrom gensim.parsing.preprocessing import STOPWORDS# download list of stopwords (only once; need not run it again)nltk.download("stopwords")nltk.download('punkt')stop_words = set(stopwords.words('english'))The stemming algorithm used was PorterStemmer. PorterStemmer and SnowballStemmer give similar results but Porter stemmer is an older algorithm. Its main concern is removing the common endings to words so that they can be resolved to a common form. Typically, it’s not really advised to use the PorterStemmer for any production/complex application; instead, it has its place in research as a nice, basic stemming algorithm that can guarantee reproducibility. It also said to be gentle when compared to others. However, there is about a 5% difference in the way that Snowball stems versus Porter.¹
使用的词干算法是PorterStemmer。 PorterStemmer和SnowballStemmer给出相似的结果,但Porter stemmer是较旧的算法。 它主要关心的是删除单词的公共结尾,以便可以将它们解析为公共形式。 通常,不建议将PorterStemmer用于任何生产/复杂应用程序。 取而代之的是,它在研究中占有一席之地,它是一种可以保证可重复性的不错的基本词干算法。 与其他人相比,它也很温柔。 但是,Snowball的阻止方式与Porter的区别大约为5%。¹
造型 (Modelling)
After each tweet has been preprocessed, we transform them into a Bag-of-Words (BoW) vector. A BoW model is a representation of text that describes the occurrence of words within a document. It is a way of getting features from text without keeping information about the order of words in the document. A BoW is a vector of numbers which each number representing a word in the sentence. X_train and X_test are the tweets while y_train and y_test are the labels of the respective tweets in the training and test data. train_test_split module splits arrays or matrices into random train and test subsets in the ratio (3:1 unless otherwise specified).
在对每条推文进行预处理之后,我们将其转换为单词袋(BoW)向量。 BoW模型是文本的表示形式,描述文档中单词的出现。 这是一种从文本中获取特征而又不保留有关文档中单词顺序信息的方法。 BoW是数字的向量,每个数字代表句子中的单词。 X_train和X_test是推文,而y_train和y_test是训练和测试数据中相应推文的标签。 train_test_split模块将数组或矩阵按比例(除非另有说明,为3:1)分成随机的训练序列和测试子集。
from sklearn.model_selection import train_test_split#Split data into train and test dataX_train, X_test, y_train, y_test = train_test_split(train_df['text'].to_list(), train_df['target'].to_list(), random_state=0)# Carry out preprocessing on text datawords_train, words_test = preprocess_gensim(X_train), preprocess_gensim(X_test)The vocabulary is a set of all words in the training set and is what the supervised learning algorithm is trained based on. Test data is transformed so that the learned model can be applied for prediction in the future.
词汇表是训练集中所有单词的集合,是监督学习算法所训练的基础。 测试数据经过转换,以便将来可以将学习的模型应用于预测。
from sklearn.feature_extraction.text import CountVectorizer# Extract Bag-of-Words (BoW)vectorizer = CountVectorizer(preprocessor=lambda x: x, tokenizer=lambda x: x)features_train = vectorizer.fit_transform(words_train).toarray()features_test = vectorizer.transform(words_test).toarray()# Create a vocabulary from the datasetvocabulary = vectorizer.vocabulary_Next step is to normalise the BoW feature vectors. This gives each vector a unit length and stop longer tweets (documents) from dominating those with fewer word counts; but, still retaining the unique mixture of feature components.
下一步是标准化BoW特征向量。 这为每个向量赋予了单位长度,并阻止了更长的tweet(文档)在那些字数较少的文档中占主导地位; 但是,仍然保留了功能部件的独特组合。
import sklearn.preprocessing as pr# Normalize BoW features in training and test setfeatures_train = pr.normalize(features_train, axis=0)features_test = pr.normalize(features_test, axis=0)Algorithms
演算法
Gaussian Naive Bayes Classifier: The first choice was the Gaussian Naive Bayes Classifier. Tree-based algorithms often work quite well on Bag-of-Words as their highly discontinuous and sparse nature is nicely matched by the structure of trees. Ideally, due to better result in both binary and multi-class problems and independence rule, Naive Bayes algorithm has a higher success rate as compared to other algorithms. It assumes that features follow a normal distribution and it is very fast to train. The Gaussian Naive Bayes’ model had a high accuracy score on the train data but did not really perform well on test data. This is known as overfitting which occurs when a model performs very well on training data but struggles to accurately predict test data. It is caused by a model picking up unnecessary noise from the training dataset, learning it and trying to apply them on the test data. Overfitting can be prevented by using cross-validation to fit multiple models on the training data and then comparing their respective performances on unseen data.
高斯朴素贝叶斯分类器 :首选是高斯朴素贝叶斯分类器。 基于树的算法通常在词袋中效果很好,因为它们的高度不连续和稀疏性质与树的结构很好地匹配。 理想情况下,由于在二元和多类问题以及独立性规则方面都有更好的结果,因此与其他算法相比,朴素贝叶斯算法具有较高的成功率。 它假定特征遵循正态分布,并且训练速度非常快。 高斯朴素贝叶斯模型在火车数据上具有较高的准确度得分,但在测试数据上的表现并不理想。 这被称为过度拟合,当模型在训练数据上表现非常好但难以准确预测测试数据时,就会发生这种情况。 这是由于模型从训练数据集中拾取了不必要的噪声,进行了学习并将其应用于测试数据而引起的。 可以通过使用交叉验证将多个模型拟合到训练数据上,然后在看不见的数据上比较它们各自的性能来防止过度拟合。
Logistic Regression: Given that the first model did not give a very impressive accuracy score on the test data, I decided to try out by training a logistic regression model. Logistic regression is a discriminative model, as opposed to Naive Bayes that is a generative classifier. In discriminative models, you have “less assumptions” because it learns the posterior probability p(x|y) “directly”. Although Naive Bayes converges quicker, it typically has a higher error than logistic regression. On small datasets, you might want to try out naive Bayes, but as your training set size grows, you likely get better results with logistic regression. The solver is a parameter of the Logistic regression model that dictates which algorithm is used to solve the problem. I went ahead with the default solver, ‘lbfgs’ . It uses multinomial loss algorithm in the optimisation, works best on not-so-large datasets and saves a lot of memory. The maximum number of iterations taken for the solver to converge was set at 1000. After training the logistic regression model, the accuracy score of the model on test data improved.
Logistic回归 :考虑到第一个模型在测试数据上没有给出非常可观的准确性得分,我决定通过训练Logistic回归模型进行尝试。 逻辑回归是一种判别模型,而朴素贝叶斯是生成分类器。 在判别模型中,您拥有“较少的假设”,因为它“直接”学习后验概率p(x | y)。 尽管朴素贝叶斯算法收敛速度更快,但其误差通常比逻辑回归更高。 在小型数据集上,您可能想尝试朴素的贝叶斯,但是随着训练集大小的增加,使用逻辑回归可以得到更好的结果。 求解器是Logistic回归模型的参数,该参数指示使用哪种算法来解决问题。 我继续使用默认的求解器' lbfgs'。 它在优化中使用多项式损失算法,在不太大的数据集上效果最佳,并节省了大量内存。 求解器收敛的最大迭代次数设置为1000。训练完逻辑回归模型后,模型在测试数据上的准确性得分得到了提高。
Gradient Boosting Algorithm: Gradient boosting builds an additive model in a forward stage-wise fashion; it allows for the optimization of arbitrary differentiable loss functions. Boosting is a sequential technique which works on the principle of ensemble. It combines a set of weak learners and delivers improved prediction accuracy. Unfortunately, this model performed averagely on both train and test data and due to the limited resources, I decided not to pursue it further.
梯度提升算法 :梯度提升以正向阶段的方式建立加性模型。 它允许优化任意微分损失函数。 增强是一种基于合奏原理的顺序技术。 它结合了一组弱点 学习者,并提高预测准确性。 不幸的是,由于该模型在训练和测试数据上平均表现出色,并且由于资源有限,我决定不再进一步研究它。
超参数调整 (Hyperparameters Tuning)
Hyperparameter tuning is the act of searching for the right set of hyperparameters to achieve high precision and accuracy for a model. A hyperparameter is any parameter whose value, if changed, can affect the learning process and performance of the model on the data. The aim is to find a balance between underfitting and overfitting. There are various tuning techniques such as Grid search, Random search, etc. Grid search was the model selection technique used in this project to tune hyperparameters. It loops through predefined hyperparameters and fits the model on the train data. From this, you can select the best parameters for that model. You can also cross-validate each set of hyperparameters multiple times. One drawback of the Grid search is that time complexity explodes with more dimensions and hyperparameters to tune. It suffers from the curse of dimensionality, i.e., the efficiency of the algorithm decreases rapidly as the number of hyperparameters being tuned and the range of values of hyperparameters increase.⁶ It is common to use this technique when the parameters are not more than 4.
超参数调整 搜索正确的超参数集以实现模型的高精度和准确性的行为。 超参数是其值(如果更改)会影响学习过程和数据模型性能的任何参数。 目的是在过度拟合与过度拟合之间找到平衡。 有各种调整技术,例如Grid搜索,Random搜索等。GridSearch是此项目中用于调整超参数的模型选择技术。 它遍历预定义的超参数并使模型适合列车数据。 从中,您可以为该模型选择最佳参数。 您还可以多次交叉验证每组超参数。 网格搜索的一个缺点是时间复杂度会随着更多维度和超参数的调整而爆炸。 它遭受了维数的诅咒,即,算法的效率随着要调整的超参数数量的增加和超参数值的范围的增加而Swift下降。⁶通常在参数不超过4时使用此技术。
Tuning Gaussian Naive Bayes with var_smoothing: Var_smoothing is a parameter that can be tuned to improve the performance of a Naive Bayes estimator. Its default value is 1e-9 and is of type, float. It is the portion of the largest variance of all features that is added to variances for calculation stability.³ Because Naive Bayes assumes the data follows a normal distribution, it essentially assigns more weights to samples closer to the distribution mean. The variable, var_smoothing, artificially adds a user-defined value to the distribution’s variance (whose default value is derived from the training data set). This essentially widens (or “smooths”) the curve and accounts for more samples that are further away from the distribution mean and helps avoid overfitting. The var_smoothing chosen were 10 samples of evenly spaced numbers between 0 to -9 on a log scale. However, the tuned model’s best score was still not very impressive so I decided to tune the Logistic regression estimator.
使用var_smoothing调整高斯朴素贝叶斯 :Var_smoothing是可以调整以改善朴素贝叶斯估计器性能的参数。 其默认值为1e-9,类型为float。 这是所有要素中最大方差的一部分,该部分被添加到方差中以提高计算的稳定性。³因为朴素贝叶斯(Naive Bayes)假设数据服从正态分布,所以从本质上讲,它为更接近于分布平均值的样本分配了更多的权重。 变量var_smoothing会人为地将用户定义的值添加到分布的方差中(其默认值是从训练数据集中得出的)。 这实质上会加宽(或“平滑”)曲线,并说明更多样本,这些样本距离分布平均值较远,并有助于避免过度拟合。 选择的var_smoothing是对数刻度上0到-9之间均匀间隔的10个数字的样本。 但是,调整后的模型的最佳分数仍然不怎么令人印象深刻,因此我决定调整Logistic回归估计量。
from sklearn.model_selection import GridSearchCVfrom sklearn.model_selection import RepeatedStratifiedKFoldparams_NB = {'var_smoothing': np.logspace(0,-9, num=10)}cv_method = RepeatedStratifiedKFold(n_splits=2, n_repeats=3, random_state=0)gs_NB = GridSearchCV(estimator=nb, param_grid=params_NB, cv=cv_method, verbose=1, scoring='accuracy')gs_NB.fit(features_train, y_train);Tuning Logistic regression with Inverse regularization parameter(C): C is a control variable that retains strength modification of regularization by being inversely positioned to the Lambda regulator. Smaller values specify stronger regularization. “Regularization is any modification we make to a learning algorithm that is intended to reduce its generalization error but not its training error.”⁴ This prevents the algorithm from overfitting the training dataset.
使用反正则化参数(C)调整Logistic回归 :C是一个控制变量,它通过与Lambda调节器相反地定位,保留了正则化的强度修改。 较小的值表示更强的正则化。 “正则化是我们对学习算法所做的任何修改,旨在减少其泛化误差,而不是其训练误差。”⁴这样可以防止算法过度拟合训练数据集。
This tuned estimator performed better than the others on test data.
经过调整的估算器在测试数据上的表现优于其他估算器。
from scipy.stats import uniformfrom sklearn.linear_model import LogisticRegressionlogistic = LogisticRegression(solver='saga', tol=1e-2, max_iter=1000, random_state=0)hyperparameters = dict(C=uniform(loc=0, scale=4), penalty=['l2', 'l1'])param_grid = {'C': [100, 10, 1.0, 0.1, 0.01]}k = RepeatedStratifiedKFold(n_splits=2, n_repeats=3, random_state=0)grid = GridSearchCV(logistic, param_grid=param_grid, cv=k, n_jobs=4, verbose=1)grid.fit(features_train, y_train)评价 (Evaluation)
Using the Scikit-learn classification report, I compared metrics across the three main estimators (Gaussian naive Bayes, Logistic Regression and tuned Logistic Regression). Accuracy score and AUROC were also compared. The computed Area Under the Receiver Operating Characteristic Curve (AUROC) shows the performance of a classification model at all classification thresholds from prediction scores.The Naive Bayes estimator had the highest sensitivity while the tuned Logistic regression has the highest specificity.
使用Scikit-learn分类报告,我比较了三个主要估计量(高斯朴素贝叶斯,Logistic回归和调整Logistic回归)的度量。 还比较了准确性得分和AUROC。 计算得出的接收器工作特征曲线下面积(AUROC)显示了根据预测得分在所有分类阈值下分类模型的性能。朴素贝叶斯估计量的灵敏度最高,而调整后的Logistic回归的特异性最高。
from sklearn.metrics import roc_curveypreds=[y_pred1, y_pred2, y_pred3]result_table = pd.DataFrame(columns=['fpr','tpr'])for pred in ypreds: fpr, tpr, _ = roc_curve(y_test, pred) auc = roc_auc_score(y_test, pred) result_table = result_table.append({'fpr':fpr, 'tpr':tpr, 'auc': auc}, ignore_index=True)models = ['Gaussian', 'Logreg', 'Tuned logreg']result_table['models'] = modelsresult_table.set_index("models", inplace = True)fig = plt.figure(figsize=(8,6))for i in result_table.index: plt.plot(result_table.loc[i]['fpr'], result_table.loc[i]['tpr'], label="{}, AUC={:.3f}".format(i, result_table.loc[i]['auc']))plt.plot([0,1], [0,1], color='orange', linestyle='--')plt.xticks(np.arange(0.0, 1.1, step=0.1))plt.xlabel("False Positive Rate", fontsize=15)plt.yticks(np.arange(0.0, 1.1, step=0.1))plt.ylabel("True Positive Rate", fontsize=15)plt.title('ROC Curve Analysis', fontweight='bold', fontsize=15)plt.legend(prop={'size':13}, loc='lower right')plt.show()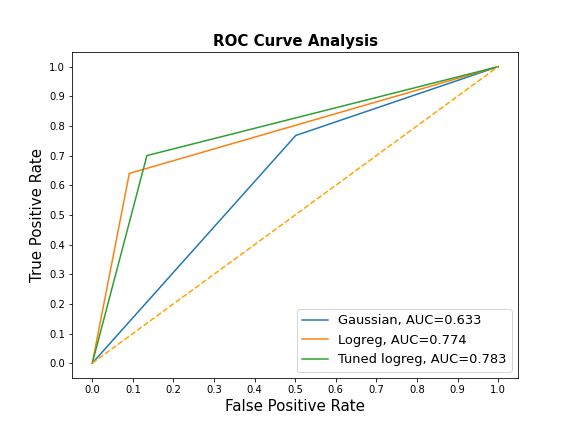
结论 (Conclusion)
The tuned Logistic regression model had the highest average precision, recall, accuracy, AUROC score and f1-score so it was selected as the best performing model in this project. However, it is noted that the accuracy score of the model on test data could be improved. This could be by trying out a deep learning algorithm, like Recurrent Neural Network (RNN) to see its performance on the data.
调整后的Logistic回归模型具有最高的平均精度,召回率,准确性,AUROC得分和f1-分数,因此被选为该项目中性能最好的模型。 但是,请注意,可以提高模型在测试数据上的准确性得分。 这可以通过尝试深度学习算法(例如递归神经网络(RNN))来查看其在数据上的性能。
For the full notebook for this article, check out my GitHub repo below: https://github.com/AniekanInyang/tweet-classification
对于本文的完整笔记本,请在下面查看我的GitHub存储库: https : //github.com/AniekanInyang/tweet-classification
Link to Part 2 of the series where I used Recurrent Neural Network (RNN) to solve the problem: https://medium.com/@_aniekan_/how-to-use-nlp-to-classify-tweets-part-ii-98841a2f5fbd
链接到我使用递归神经网络(RNN)解决问题的系列文章的第2部分: https : //medium.com/@__aniekan_/how-to-use-nlp-to-classify-tweets-part-ii- 98841a2f5fbd
Feel free to reach out on LinkedIn, Twitter or send an email: contactaniekan at gmail dot com if you want to chat about this or any NLP research project.
如果您想就此或任何NLP研究项目进行聊天,请随时通过LinkedIn , Twitter或发送电子邮件:gmail dot com与contactaniekan联系。
Stay safe.

