
- 1在npm install 时报错 unable to connect to github.com_npm i下载github失败
- 2AI绘画第一步:Stable Diffusion 本地安装&汉化教程_windows ai绘画 stable diffusion, dwindows ai绘画 stabl
- 3NLP | 自然语言处理 - 语言模型(Language Modeling)_自然语言模型按照主语句子分割的模型
- 4微服务:Eureka
- 5Android -- 购物车_android 购物车
- 6postgresql-聚合函数string_agg、array_agg的妙用_parcition by合array_agg
- 7重磅!MongoDB官方文档现已支持中文!抢先浏览!
- 8php中文转码mb_convert_encoding()函数的使用_php mb_convert_encoding
- 9ELK收集MySQL SlowLog(Filebeat .KO. Logstash )【实操系列】_filebeat slowlog
- 10将springboot项目生成可依赖的jar,并引入到项目中_springboot引入第三方jar包
DRL--算法合集
赞
踩
一、注意点(难点)
-
DRL的训练标签是什么?
想让智能体学习一段时间后,然后仿照考试一样,对智能体进行测试;以此反复训练网络参数。 -
强化学习中的无模型和有模型
-
具有完整环境模型的智能体可以预测每个动作的结果以及相应的奖励,因此可以在不进行试验的情况下优化其策略。这种类型的智能体被称为“有模型”智能体。
-
另一方面,没有对环境建模的智能体被称为“无模型”智能体。这些智能体必须通过与环境交互来学习,然后基于其经验进行行动决策。它们只能在实验过程中通过试错来学习,并且需要更多的时间和经验才能达到与有模型智能体相同的性能水平。
-
Sarsa算法就是一个无模型的在线学习算法。
-
-
Q值
- 强化学习中的Q值是指在某个状态下采取某个动作的价值,也就是说,它代表了智能体选择这个动作后,一直到最终状态奖励总和的期望。Q值可以用来指导智能体做出最优的决策,以获得最大的累积奖励。
- 预测Q值是指神经网络的输出,也就是当前状态-动作对的Q值的估计。目标Q值是指根据贝尔曼方程计算出的期望的Q值,也就是当前状态-动作对的真实的Q值。
-
策略学习和价值学习
- 策略学习是直接学习一个策略函数,输入一个状态,输出一个动作或者一个动作的概率分布。策略学习的优点是可以处理连续的动作空间,也可以实现随机性的策略。策略学习的缺点是收敛速度较慢,容易陷入局部最优。
- 价值学习是间接学习一个价值函数,输入一个状态或者一个状态-动作对,输出一个价值或者一个Q值。价值学习的优点是收敛速度较快,可以利用贝尔曼方程进行迭代更新。价值学习的缺点是难以处理连续的动作空间,也难以实现随机性的策略。
一般来说,策略学习和价值学习都需要与环境进行交互,获取奖励信号来更新参数。但是也有一些算法可以同时使用策略和价值来做决策,比如演员-评论家算法(Actor-Critic),其中演员(Actor)是一个策略函数,评论家(Critic)是一个价值函数,演员根据评论家的评价来更新策略,评论家根据环境的奖励来更新价值。
-
策略梯度(reinforce和AC算法)

- REINFORCE 用实际观测的回报近似 Q π , actor-critic 方法用神经网络近似 Q π 。
-
关于rt、Rt大小写的区别
-
episode和评估次数的关系
- 评估的次数是指你用一个固定的策略在一个环境中运行多少次,而episode是指你在一个环境中从开始状态到结束状态的一次过程。
- 如果你每次评估只运行一个episode,那么评估的次数就等于episode的数量。但是如果你每次评估运行多个episode,或者你的环境没有明确的结束状态,那么评估的次数就不等于episode的数量。
-
状态价值V和动作价值Q
- 状态价值是指在某个状态下,遵循某个策略能够获得的期望回报。它反映了到达这个状态后的潜在收益。
- 动作价值是指在某个状态下,执行某个动作后,遵循某个策略能够获得的期望回报。它反映了选择这个动作后的潜在收益。
- 状态价值和动作价值都是对未来回报的预测,但状态价值需要考虑所有可能的动作选择,而动作价值只需要考虑一个特定的动作选择。

-
AC算法中的更新
-

-
Q-learning是一种离线算法,它使用贪心策略来选择下一个状态的最大价值动作,但实际执行时可能不采用该动作12。SARSA是一种在线算法,它使用 ε − g r e e d y \varepsilon-greedy ε−greedy 策略来选择下一个状态的实际动作,并执行该动作12。
-

-
Q-learning是离线算法,因为它在更新Q值时,使用的是下一个状态的最大价值动作,而不是实际执行的动作12。也就是说,Q-learning在学习过程中使用的策略和实际执行的策略可能不一致,这样可以避免局部最优解23。
-
SARSA是在线算法,因为它在更新Q值时,使用的是下一个状态的实际动作,也就是说,SARSA在学习过程中使用的策略和实际执行的策略是一致的12。这样可以保证SARSA能够适应环境的变化,并且对错误或惩罚更敏感24。
-
Q-learning和SARSA的更新公式不同,Q-learning使用下一个状态的最大价值动作来更新当前状态的价值函数,即 Q ( s , a ) = Q ( s , a ) + α ∗ ( r + γ ∗ m a x ( Q ( s ’ , a ’ ) ) − Q ( s , a ) ) Q (s,a) = Q (s,a) + α* (r+γ* {max} (Q (s’,a’))-Q (s,a)) Q(s,a)=Q(s,a)+α∗(r+γ∗max(Q(s’,a’))−Q(s,a))。SARSA使用下一个状态的实际动作来更新当前状态的价值函数,即 Q ( s , a ) = Q ( s , a ) + α ∗ ( r + γ ∗ Q ( s ’ , a ’ ) − Q ( s , a ) ) Q (s,a) = Q (s,a) + α* (r+γ*Q (s’,a’)-Q (s,a)) Q(s,a)=Q(s,a)+α∗(r+γ∗Q(s’,a’)−Q(s,a)) \123。
-
Q-learning和SARSA的行为特征不同,Q-learning是一种激进的算法,它只考虑最终获得最大奖励的可能性,不在乎中途遇到的陷阱或惩罚124。SARSA是一种保守的算法,它对错误或死亡十分敏感,会尽量避开可能导致负面结果的动作124。
-
-
由于某些算法(如 A2C、PPO)默认采取 stochastic 策略,因此在测试即调用 .predict() 时应该设置 deterministic=True,这会有更好的效果?
-
这句话的意思是,在强化学习中,有两种不同的策略类型:确定性策略和随机性策略。确定性策略是指对于每个状态,只输出一个确定的动作。随机性策略是指对于每个状态,输出一个动作的概率分布,然后从中采样动作。
-
一些强化学习算法(如A2C、PPO)默认采用随机性策略,这样可以增加探索性和鲁棒性。34
-
但是,在测试的时候,如果想要得到最优的动作,就应该设置 deterministic=True,这样就可以直接输出最大概率的动作,而不是随机采样。34
-
这样做的原因是,在训练的时候,随机性策略可以帮助学习到更多的状态和动作,但是在测试的时候,确定性策略可以保证输出最好的动作。
-

二、算法的比较和区别
-
Q-learning:Q-learning是一种基于值函数的强化学习算法,可以用于离散状态和动作空间的问题,收敛速度较快,但对于连续状态和动作空间的问题效果可能不太好。
-
Deep Q Network (DQN):DQN是一种基于深度神经网络的Q-learning算法,可以用于处理连续状态和离散动作空间的问题。DQN具有较好的泛化能力和稳定性,但训练过程比较复杂。
-
TD 目标的计算分解成选择和求值两步,缓解了最大化造成的高估。过度估计问题是指DQN在选择最大化动作价值函数的动作时,往往高估了一些情况下的行为价值,导致学习偏差和不稳定。
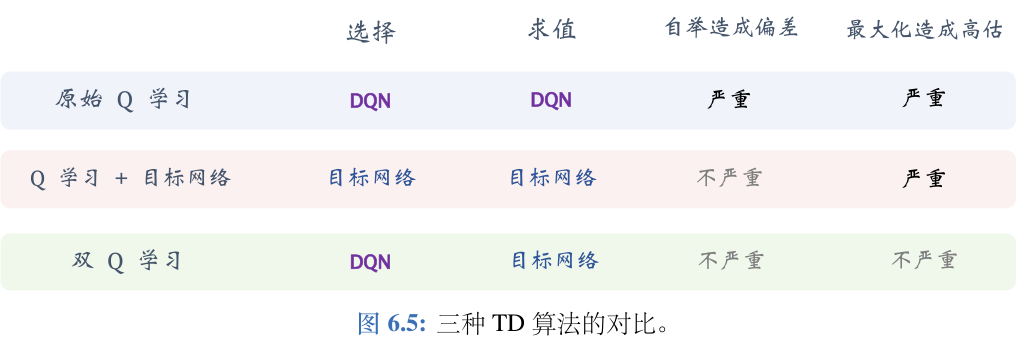
- DQN直接用Target Q网络中t+1时刻可选Q的最大值用来更新
- 而DDQN用的是根据Q网络t+1时刻的最大Q来选择对应的action,然后用这个action来对应决定Target Q网络中的Q值
- 这样更新的Q值就会小于等于DQN更新的Q值,改善overestimate的问题。
- DDQN的解决方法是将动作选择和动作评估分开,用Q网络选择最优动作,用目标网络评估该动作的价值。这样,就可以减少过度估计的影响,提高学习性能32。
-
τ:

-
Policy Gradient:Policy Gradient是一种基于策略优化的强化学习算法,可以用于离散和连续状态空间、离散和连续动作空间的问题。Policy Gradient可以直接优化策略函数,但训练过程比较不稳定。
-
Actor-Critic:Actor-Critic是一种将值函数和策略函数结合起来的强化学习算法,可以用于离散和连续状态空间、离散和连续动作空间的问题。Actor-Critic可以同时优化策略和值函数,但训练过程也比较复杂。
-
Proximal Policy Optimization (PPO):PPO是一种基于策略优化的强化学习算法,可以用于离散和连续状态空间、离散和连续动作空间的问题。PPO具有较好的稳定性和收敛速度,但训练效率较低。
-
同策略:SARSA、REINFORCE、A2C 都属于同策略。它们要求经验必须是当前的目标策略收集到的,而不能使用过时的经验。经验回放不适用于同策略
-
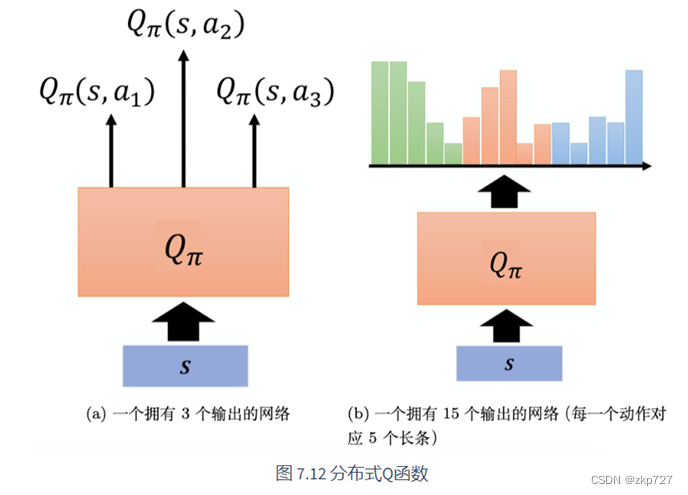
Distributional DQN:(原文链接:参考链接)
- 为什么会有:在传统DQN中,网络输出的是动作价值Q的估计,但是其实还是忽略了很多信息。假如两个动作能够获得的价值期望相同都是20,第一个动作有90%的情况是10,10%的情况下是110,第二个动作的50%的情况下是25,50%的情况下是15,那么虽然期望一样,但是要想减少风险,就应该选择后一种动作,只输出期望值看不到背后隐含的风险。
- 为什么分布式深度Q网络不会高估奖励,反而会低估奖励呢?因为分布式深度Q网络输出的是一个分布的范围,输出的范围不可能是无限的,我们一定会设一个限制, 比如最大输出范围就是从 −10 ~ 10。假设得到的奖励超过 10,比如 100 怎么办?我们就当作没看到这件事,所以奖励很极端的值、很大的值是会被丢弃的,用分布式深度Q网络的时候,我们不会高估奖励,反而会低估奖励。
- Distributional DQN:特点是不仅学习动作值函数Q(s, a),也就是在状态s下采取动作a的期望回报,而且学习动作值分布Z(s, a),也就是在状态s下采取动作a的回报的概率分布。
- Distributional DQN使用了一个神经网络来输出一个离散的分布,也就是在一组预定义的支撑点上给出每个支撑点对应的概率。这个神经网络可以看作是一个分类器,它的输入是状态s和动作a,输出是一个向量,表示每个类别(支撑点)的概率。为了训练这个神经网络,Distributional DQN使用了一个损失函数,它是基于KL散度的,用来衡量两个分布之间的差异。
-
PPO和A3C区别
- A3C是一种异步的actor-critic算法,它使用多个并行的智能体来探索不同的环境,并将它们的梯度更新到一个共享的全局网络。A3C可以有效地利用多核CPU,但是也可能遇到样本相关性和更新不稳定的问题。
- PPO是一种近端策略优化算法,它使用一个单一的智能体来收集经验,并用一个裁剪的目标函数来更新策略。PPO可以避免策略更新过大或过小,从而保证策略的改进。PPO也可以使用多个智能体来并行收集数据,但是需要同步更新参数。
- PPO算法是一种近端策略优化算法,它也使用了actor-critic框架,但是引入了一个裁剪的目标函数来限制策略的更新幅度。PPO算法可以避免策略更新过大或过小,从而保证策略的改进。PPO算法的优点是更稳定和高效,也更容易调参,缺点是可能需要更多的epoch和batch size。
- 一般来说,PPO比A3C更稳定和高效,也更容易调参。
- PPO算法是一种on-policy的算法,也就是说它的目标策略和行为策略是相同的,它只能用当前策略产生的数据来更新。但是PPO算法通过重要性采样和近端策略优化的方法,使得它可以多次使用同一批数据进行更新,而不会导致策略分布发生剧烈变化 。这样就可以减少采样的次数,提高数据的利用率,也可以避免on-policy算法的高方差和低效率的问题 。
-
epoch
- 强化学习中的epoch通常是指智能体在环境中执行了一定数量的步骤或者完成了一定数量的任务。
- 例如,如果智能体在一个迷宫环境中寻找出口,那么一个epoch可以是指智能体从起点到达出口或者失败的一次尝试,也可以是指智能体在环境中走了多少步。
-
软更新系数
- 软更新系数是一种在强化学习中更新目标网络参数的方法,它利用当前网络参数与目标网络参数的凸组合来更新网络,即目标网络的参数 θ i − \theta_i^ {-} θi− 会用当前网络参数 θ i \theta_i θi 按照如下公式更新1:
θ i + 1 − ← ( 1 − ϵ ) θ i − + ϵ θ i = θ i − + ϵ ( θ i − θ i − ) \begin {align*} \theta_ {i+1}^ {-} &\leftarrow (1-\epsilon)\theta_i^ {-} + \epsilon \theta_i\\ &= \theta_i^ {-} + \epsilon (\theta_i - \theta_i^ {-}) \end {align*} θi+1−←(1−ϵ)θi−+ϵθi=θi−+ϵ(θi−θi−)
其中 0< ϵ \epsilon ϵ << 1 是软更新系数,它控制了目标网络参数变化的速度。软更新系数越小,目标网络参数变化越缓慢,算法越稳定,但收敛速度也越慢。软更新系数越大,目标网络参数变化越快,算法越不稳定,但收敛速度也越快。一个合适的软更新系数能让算法既稳定又快速地收敛。
软更新系数一般用于连续动作空间的强化学习算法,如DDPG 2、TD3 3、SAC [4]等。它们与离散动作空间的强化学习算法不同,后者通常使用硬更新 (Hard Update) 的方法,即每隔固定的 C 步用Q网络参数 \theta_i 同步更新一次目标网络参数 θ i − \theta_i^- θi− 。硬更新和软更新之间有一个关系,即当目标网络更新间隔 C 和软间隔更新系数 ϵ \epsilon ϵ 满足 ϵ C = 1 \epsilon C=1 ϵC=1 时,两种更新方式下的性能是相当的1
-
load_state_dict和parameters().copy区别
- load_state_dict是torch.nn.Module类的一个方法,它的作用是从一个字典中加载模型的参数和缓冲区,如果strict参数为True,那么字典中的键必须和模型的state_dict()方法返回的键完全匹配12。
- parameters().copy是torch.nn.Parameter类的一个方法,它的作用是返回一个新的Parameter对象,它包含了原来Parameter对象的数据的副本3。这个方法通常用于复制模型中的某个参数,而不是整个模型
-
torch.mean(F.mse_loss())和nn.MSELoss()区别
- torch.mean(F.mse_loss()) 和 nn.MSELoss() 的功能是相同的,只是使用方式不同。
- 一般来说,nn.MSELoss() 更适合用在神经网络的训练中,因为它可以和其他的优化器或者学习率调度器配合使用,而 torch.mean(F.mse_loss()) 更适合用在测试或者评估中,因为它更简单直接。
-
关于策略梯度:
AC算法中,代码实现策略梯度计算的一般步骤如下12:
1. 定义actor网络和critic网络,分别用于输出策略和值函数。
2. 采样一条轨迹,记录每个状态、动作和奖励。
3. 对每个时刻,计算累积奖励或者使用critic网络的输出作为目标值。
4. 对每个时刻,计算actor网络的输出对应的对数概率,乘以目标值,得到策略梯度。
5. 对每个时刻,计算critic网络的输出与目标值之间的均方误差,得到值函数梯度。
6. 使用优化器更新actor网络和critic网络的参数。
二、算法解析注释
1.改进的贪婪算法
- 改进之前始终不变的探索欲望,探索欲望随着玩的次数逐渐降低,可以设置成次数的倒数。
- 上置信界算法UCB:多探索玩的少的机器。通过设置UCB的值,UCB是一个向量,随着玩的次数增多,逐渐变小
2.Dyna Q算法
总结就是:离线反刍,温故而知新(离线学习)
-
它通过利用环境模型来加速Q-learning算法的收敛,同时也可以对环境进行预测,从而改善策略。
-
Dyna Q算法的基本思想是,在Q-learning算法的基础上,增加了一个环境模型,用来模拟环境的动态变化。当智能体与环境交互时,除了更新Q值之外,还会更新环境模型。环境模型可以记录智能体的经验,包括每个状态的奖励和下一个状态的转移概率,智能体在更新Q值时会利用这些信息来加速收敛。
-
在Dyna Q算法中,每次更新Q值时,会随机选择一个之前经历过的状态,并根据环境模型预测其下一步的状态和奖励。这样可以在Q-learning算法的基础上,增加更多的训练数据,进一步提高智能体的决策能力。另外,在环境模型中预测的状态和奖励也会用来更新Q值,以此来改进智能体的策略。
-
总的来说,Dyna Q算法是一种结合了模型学习和模型利用的增强学习算法,可以有效地提高强化学习算法的收敛速度和性能。但是,在实际应用中,由于需要维护环境模型,所以Dyna Q算法的计算复杂度相对较高。
3.DQN中的延迟更新next_model
- 因为在训练时,是用经验模型评估动作模型的目标。如果目标总是在变,训练就会变得困难、不稳定,所以需要暂时让目标确定下来
- 关于detach()(A2C算法)
- 回报是根据下一个状态的价值(next_value)和奖励(rewards)计算出来的,而下一个状态的价值是由评论家网络(critic network)输出的,所以回报和评论家网络的参数有依赖关系。
- 如果不加detach,那么在反向传播(backpropagation)的时候,回报会对评论家网络的参数产生梯度,这会影响评论家网络的更新。
- 但是我们只想用回报来评估当前状态的价值,而不想用它来更新评论家网络,所以要加上detach,断开它与计算图(computation graph)的连接。
4.对期望的蒙特卡洛近似

5、强化学习中确定性策略和随机策略的区别
- 确定性策略是指对于每个状态,都有一个确定的动作选择,不涉及任何随机性12。例如,如果你在一个迷宫中,你的确定性策略可能是:如果有左转,就左转;如果没有左转,就直走;如果遇到死胡同,就回头。
- 随机策略是指对于每个状态,都有一个动作的概率分布,根据概率来选择动作12。例如,如果你在一个迷宫中,你的随机策略可能是:如果有左转,以0.8的概率左转,以0.2的概率直走;如果没有左转,以0.6的概率直走,以0.4的概率右转;如果遇到死胡同,以0.9的概率回头,以0.1的概率停留。
确定性策略和随机策略各有优缺点。确定性策略的优点是简单、高效、易于实现;缺点是可能陷入局部最优、缺乏探索能力、不适用于部分可观测或随机的环境3。随机策略的优点是可以增强探索能力、适应不确定性、避免过早收敛或震荡;缺点是可能增加方差、降低效率、难以优化
6、A3C
1)异步、并发、多线程
- 异步(asynchronous)是指一个操作不会阻塞程序的执行,而是在后台进行,当操作完成时,会通知程序或者执行一个回调函数。异步操作可以在单线程或者多线程的环境中进行,它可以提高程序的响应性和效率。
- 并发(concurrent)是指多个操作可以在同一时间段内交替执行,但不一定同时执行。并发可以在单核或者多核的处理器上实现,它可以提高程序的吞吐量和利用率。
- 多线程(multithreading)是指程序可以创建多个线程来执行不同的任务,每个线程有自己的执行流和上下文。多线程可以实现并发,也可以实现并行,取决于处理器的核数和调度算法。多线程可以提高程序的性能和并发能力。
- 并行(parallel)是指多个操作可以在同一时刻同时执行。并行需要多核或者分布式的处理器来实现,它可以提高程序的速度和规模。
- 总之:异步是指不阻塞程序的执行,而是在后台进行;并发是指多个操作交替执行,但不一定同时执行;多线程是指程序创建多个线程来执行不同的任务;并行是指多个操作同时执行。
- 多线程是指程序创建多个线程来执行不同的任务,而并行是指多个操作同时执行。多线程可以实现并行,但并行不一定需要多线程。
2)算法原理
A3C 采用异步梯度更新的方式,不同的 worker 获取独立的经验后(一个 batch),独立的去更新 Global Network,当主网络参数被更新了以后,就用最新的参数去重置所有的 worker,然后在开始下一轮循环。
3)具体更新过程–参考链接
- 其中一个 worker i 跑完了它当前的循环(完成一个episode),于是它就用这个 tajectory的经验计算 actor loss 和 critic loss,计算梯度并上传给 global network,而 lobal network 进行梯度下降后得到新的参数,再传回给那个 woker i ,这时主网络和 worker i 的参数同时得到更新;
- 而与此同时,其它的woker 还在跑它们自己的循环,完全不受影响,当 worker i 开始新循环以后,它跟其它 worker 使用的都是不同的 policy。
- 直到某个 worker 跑完了自己的循环,再次重复以上过程。
7、DDPG
8、PPO
9、关于目标网络
(1)AC算法中的目标网络
- 目标网络和评论家网络的关系是一种固定网络技术,它是为了解决值函数更新时的不稳定性问题。
- 目标网络和评论家网络有相同的结构,但是目标网络的参数是延迟更新的,也就是说,它不会每次都和评论家网络同步,而是每隔一段时间才会复制评论家网络的参数。这样可以让目标值更稳定,避免因为参数的快速变化而导致值函数震荡或者发散。
- 目标网络只用来计算目标值,不用来更新参数,所以它的梯度不需要反向传播到评论家网络。
- 1
- 2
- 3
(2)什么时候需要目标网络,什么时候不用
-
目标网络主要用于基于 Q-learning 的算法,如 DQN 和 DDPG,它们使用值函数网络来估计 Q 值,并根据 Q 值来选择动作。目标网络的作用是生成目标 Q 值,用于计算值函数网络的损失函数和梯度更新。
-
目标网络不是必须的,但是使用目标网络可以使训练过程更稳定,因为它可以减少目标 Q 值和值函数网络输出之间的差异,从而减少训练过程中的震荡和不稳定。
-
如果不使用目标网络,那么目标 Q 值和值函数网络输出都会随着同一套参数变化,这可能导致训练陷入循环或者发散。
-
如果使用基于策略梯度的算法,如 REINFORCE 或者 PPO,那么就不需要目标网络,因为它们直接学习一个策略网络来输出动作的概率分布,并根据优势函数或者回报估计来更新策略网络。
(3)PPO有价值网络critic,可以用目标网络吗?
-
PPO 有一个价值网络,用来估计状态值,并用于计算优势函数或者回报估计。理论上,PPO 也可以使用目标网络来生成目标状态值,从而稳定价值网络的训练。但是,PPO 是一个 on-policy 的算法,它只使用当前策略产生的经验来更新网络,而不使用历史策略产生的经验。这意味着 PPO 需要在每次更新策略后丢弃之前收集的经验,因为它们不再适用于新的策略。这样做的好处是 PPO 可以保证策略和值函数之间的一致性,也就是说,值函数可以很好地估计当前策略的性能。
-
如果 PPO 使用目标网络,那么目标网络的参数会滞后于价值网络的参数,这可能导致目标状态值和价值网络输出之间的不一致性,也就是说,目标状态值可能不能很好地估计当前策略的性能。这样做的代价是 PPO 可能降低学习效率,因为它不能及时反映环境和策略的变化。
-
因此,PPO 通常不使用目标网络,而是直接使用价值网络来生成目标状态值。这样做的好处是 PPO 可以提高学习效率,因为它可以及时反映环境和策略的变化。
10、SAC
知乎文章
SAC算法是一种基于policy iteration来解决控制问题的,off-policy数据可能影响的是policy evaluation的部分,因为该部分需要逼近
Q
π
Q^\pi
Qπ和
V
π
V^\pi
Vπ。SAC算法解决的问题是离散动作空间和连续动作空间的强化学习问题,是off-policy的强化学习算法.
SAC算法中,如果actor网络输出的动作越能够使一个综合指标(既包含动作价值q,又包含熵h)变大,那么就越好。如果Q critic网络输出的动作价值q越准确(根据贝尔曼方程可知,q是否准确依赖于v是否准确),那么就越好。如果V critic网络输出的状态价值v越准确,那么就越好。
(2)算法优势
- SAC可以增加策略的探索性,让策略更广泛地搜索状态空间,同时放弃明显无效的行动,这样可以加速学习过程,也可以避免陷入局部最优。
- SAC可以捕捉策略的多模性,让策略在多个近似最优的行动之间分配概率,这样可以提高策略的鲁棒性和适应性。
- SAC可以利用离策略的数据进行更新,让策略更高效地利用已经收集的数据,也可以减少采样的开销。
- SAC可以稳定地训练一个随机的行为-评论网络,让策略更容易收敛和泛化。
11、TD3算法
什么是TD3算法?(附代码及代码分析) - 张斯俊的文章 - 知乎
12、优先级采样和重要性采样
-
优先级采样是一种根据数据的重要性来分配采样概率的方法,它可以用来减少数据的冗余和偏差,提高数据的多样性和代表性。优先级采样通常需要定义一个优先级函数,用来衡量每个数据的重要性,比如TD误差、奖励大小、状态稀疏度等。优先级采样可以用来改进经验回放机制,让强化学习算法更快地从关键的经验中学习。例如,( Schaul et al., 2016) 提出了一种基于优先级采样的深度Q网络算法1。
-
重要性采样是一种根据数据的偏差来调整学习更新的方法,它可以用来减少数据的偏差和方差,提高数据的有效性和稳定性。重要性采样通常需要计算一个重要性权重,用来衡量每个数据在目标分布和行为分布之间的偏差,比如策略概率比值、值函数梯度比值等。重要性采样可以用来改进
策略评估和策略改进机制,让强化学习算法更准确地从不同的策略中学习。例如,( Precup et al., 2000) 提出了一种基于重要性采样的离线策略评估算法2。 -
重要性采样和优先级经验回放的区别和联系是这样的:
- 重要性采样是一种统计学的方法,用于从一个分布中抽样,但是根据另一个分布来计算期望值。它可以用于处理抽样分布和目标分布不匹配的情况,例如在强化学习中,当策略改变时,经验回放中的样本可能不再符合当前策略的分布12。
- 优先级经验回放是一种基于重要性采样的经验回放方法,它根据每个经验样本的时间差分误差(TD-error)来给它们分配不同的优先级,从而使得更重要的样本更有可能被抽取。它可以提高深度强化学习算法的学习效率和稳定性3 。
- 重要性采样和优先级经验回放的联系是,优先级经验回放使用了重要性采样的思想,即根据一个非均匀的分布来抽取样本,但是根据一个均匀的分布来计算梯度更新。为了消除偏差,优先级经验回放使用了重要性采样权重(IS-weight),即抽取概率的倒数,来修正梯度更新3 。
13、强化学习的归一化
归一化是一种常用的数据预处理方法,可以消除数据的量纲,让输入神经网络的数值符合标准正态分布,从而让神经网络的训练更加舒服123。
在强化学习中,归一化可以应用于状态信息、动作信息和奖励信息,但是有不同的方式和效果123。
-
状态信息:可以对输入神经网络的状态信息进行归一化,使其均值为0,方差为1。这样可以避免输入一个绝对值很大的数字,导致神经网络的参数需要经过很多步的更新才能适应12。
-
动作信息:在动作空间是连续的情况下,可以将动作空间限制在一个范围内,例如-1到1。这样可以让动作信息的均值和方差接近0和1,也有利于神经网络的训练12。
-
确保稳定性:标准化动作可以帮助提高算法的稳定性。在强化学习中,智能体可能需要选择具有不同取值范围的动作。如果不对动作进行标准化,不同动作的取值范围差异很大,可能会导致训练不稳定,难以收敛。
-
提高收敛速度:标准化动作可以加快训练的收敛速度。通过将动作值映射到固定的范围(例如[-1, 1]或[0, 1]),可以使智能体更容易学习和调整动作策略,减少训练时间。
-
泛化能力:标准化动作可以提高智能体的泛化能力。通过将动作范围限制在一定的范围内,智能体可以更好地适应不同环境和任务的动作要求。这种泛化能力使得训练好的智能体可以更好地应对未知环境和动作空间的变化。
-
-
兼容性:标准化动作可以使得智能体的策略更易于与其他模型或系统进行集成。例如,在与物理环境交互的控制任务中,动作的标准化可以使得智能体输出的动作值与物理系统的控制输入匹配,从而更容易实现实际控制。
-
奖励信息:不应该对奖励信息进行归一化,因为这样会破坏奖励信号的意义123。但是可以对奖励信息进行放缩,即乘以一个常数因子,来调整奖励信息的大小123。这样可以避免奖励信息的方差过大导致算法无法收敛,或者奖励信息过小导致算法收敛变慢12。
如果你想了解更多细节:
-
【代码实现】强化学习调参经验集成 - 知乎**3**
三、贴一个代码流程pipline连接
(1)
大部分DRL算法,指的是 Off-policy的 DDPG、TD3、SAC 等,以及 On-policy 的 A3C、PPO 等 及其变体。大部分算法的区别只在于:计算Q值、探索环境罢了。如果是DQN类的,那么只需要把 actor 看成是 arg max (Q1, …, Qn),critic看成是Q Network 即可。
(2)算法选择
四、报错集合
RuntimeError: Found dtype Double but expected Float
你使用了torch.from_numpy方法来将numpy数组转换为torch张量,但是这个方法默认会保留原来的数据类型,而numpy数组的默认数据类型是双精度浮点数。你可以在torch.from_numpy方法后面加上.float()方法来将张量转换为单精度浮点数,

