
- 1Flink 部署——概览_flink客户端
- 2医咖会免费STATA教程学习笔记——日志文件_stata smcl文件
- 3UE5.1 利用WEBUI插件完成UE与JS的交互 (UE5.1嵌入WEB)_ue webui
- 4毕业设计-基于大数据的房地产数据分析与预测-python_基于数据挖掘的房价预测分析
- 5MATLAB机器学习、深度学习_matlab app 机器学习和深度学习
- 6CDH集群配置过程中若干个坑加配置教程_grant all on oozie.* to 'oozie'@'%' identified by
- 7你做的 9 件事表明你不是专业的 Python 开发人员
- 8【Java面试题】八、String str = “hello“ 和 String str = new String(“hello“) 一样吗?_string s="hello"; 与string s=new string("hello");有何
- 9探索最前沿SLAM技术: YiChenCityU/Recent_SLAM_Research
- 10打破知识壁垒,电子类比赛的百科全书_电赛是一年一次吗
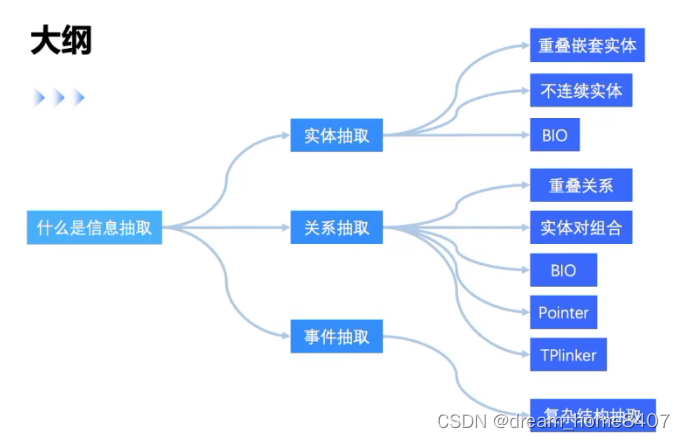
【NLP实体抽取,事件抽取,序列标注】_自然语言事件抽取标注工具
赞
踩
实体抽取式nlp中广泛使用
实体抽取是自动从非结构化数据或者半结构化数据中抽取结构化信息的任务。


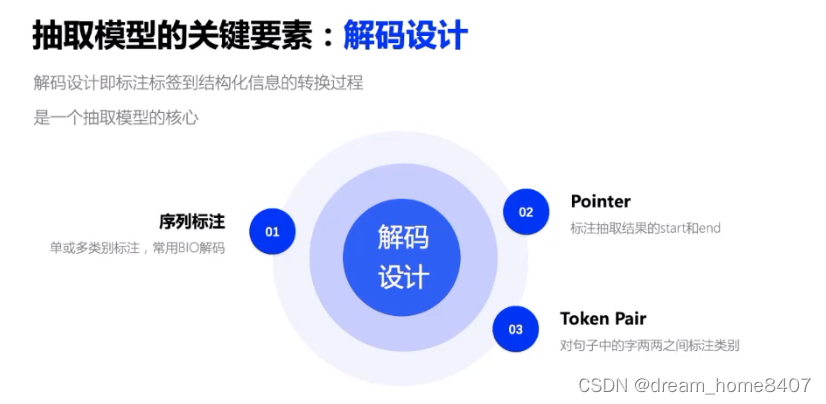
信息抽取的关键要素,解码设计
1.BIO解码,序列标注,单个或者多类别标注,
2.pointer解码,标注抽取结果的start和end
3.token pair,对句子中的两两之间标注类别
实体抽取
从一段文本中抽取出文本实体,并识别出预定义类别
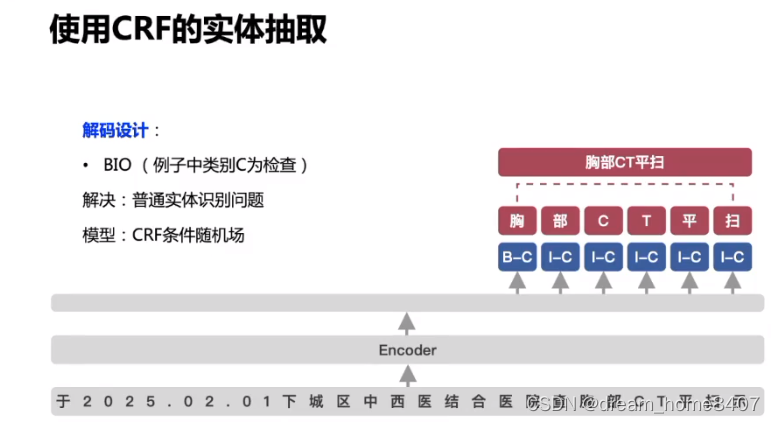
BIO B是实体开始 c是实体类别,I是实体中间位置,o是表示其他部分
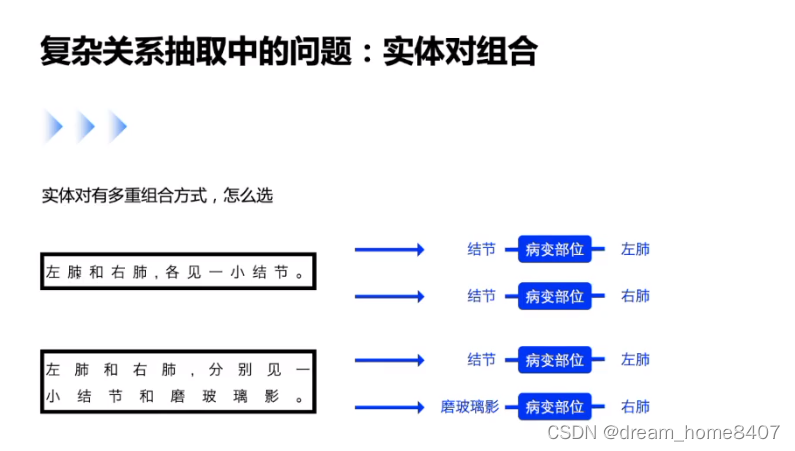
实际中的问题
一段文字包含两种实体,怎么标注

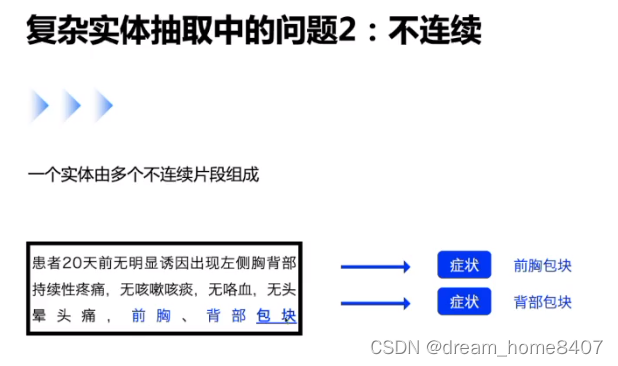
这些问题需要使用复杂的模块来解决

关系抽取
从文本中抽取出一对实体和预定义的关系类型,得到包含语言信息的实体关系三元组

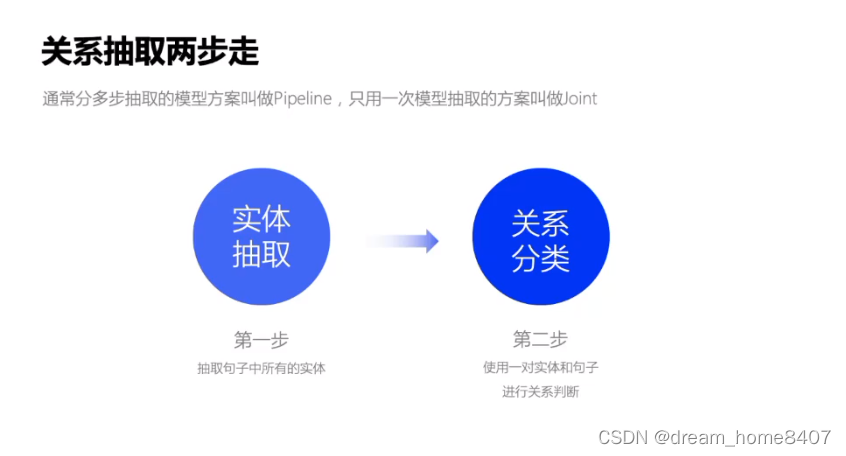
使用序列标注解决关系抽取
思路是通过增加标注信息来解决问题,增加的是关系标注信息
模型使用sigmoid独立分类,大于阈值属于这个类别,
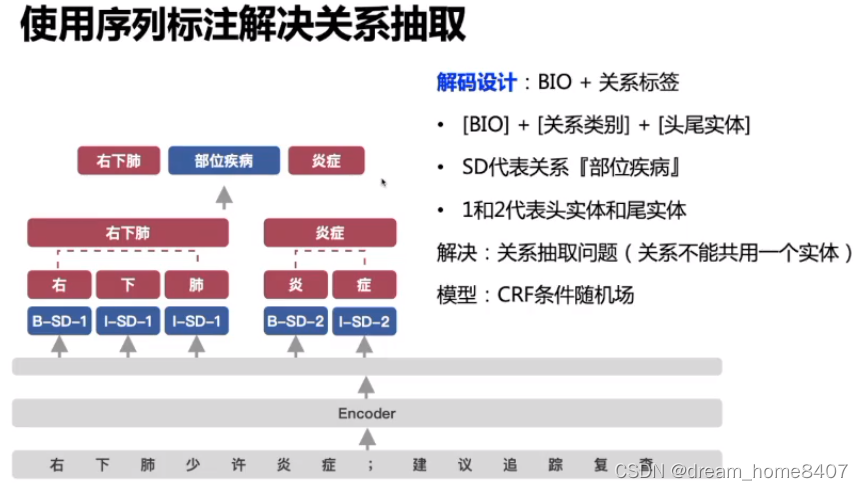
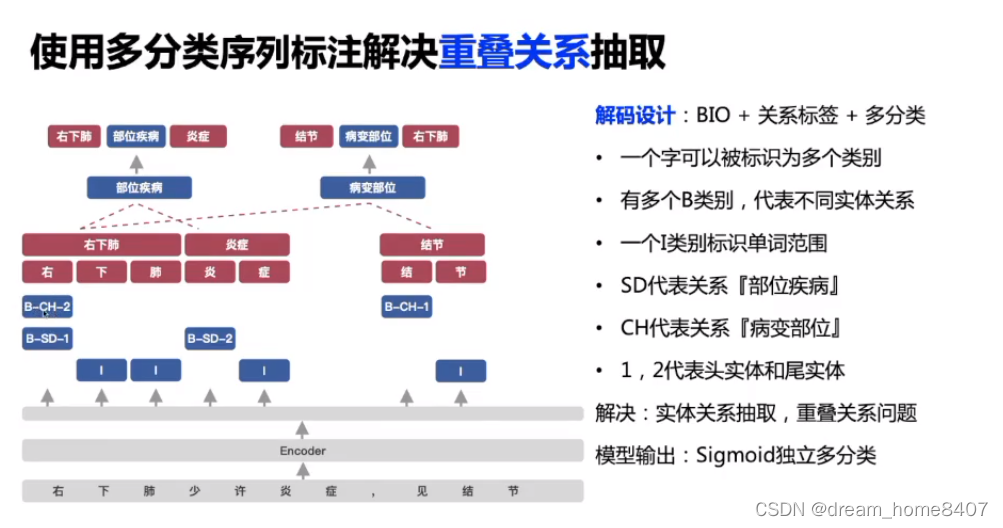
两个实体在训练中怎么连在一起,头实体和尾实体怎么组合,需要模型给出结果
模型先预测头实体,根据头实体预测尾实体
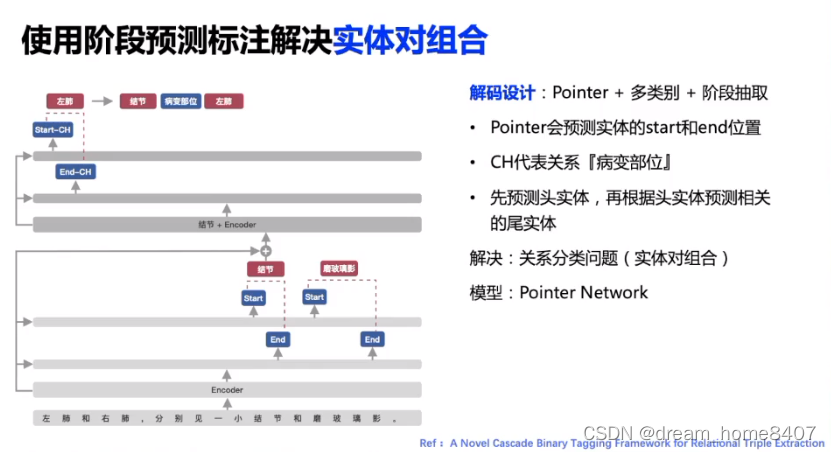
每一个字和句子中的其他字做分类

事件抽取
事件抽取:从文本中抽取事先定义的事件触发词和事件要素,组合为响应的结构化信息
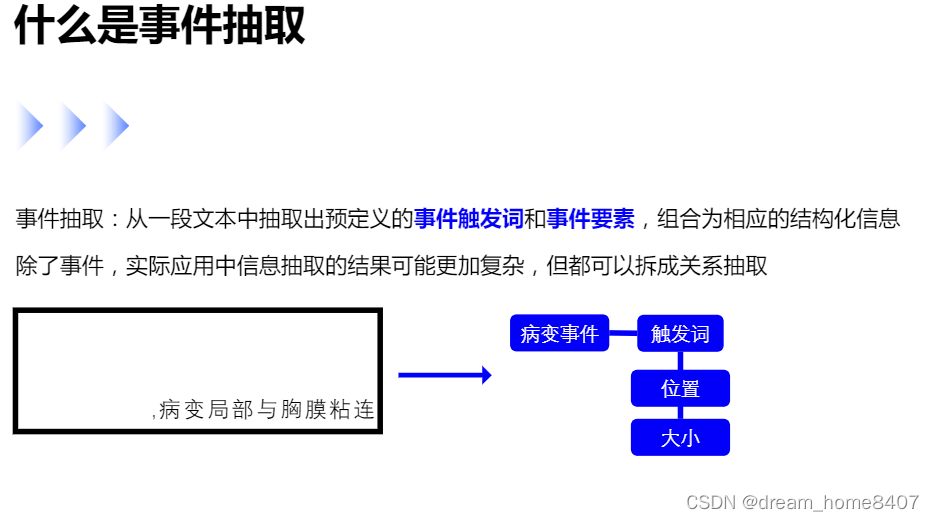
实体抽取怎么标注文本
杨幂主演秀春刀,饰演北斋
1.定义关系,主演,和饰演
序列标注
我们可以用序列标注模型来解决信息抽取任务,下面具体介绍一下序列标注模型。
在序列标注任务中,一般会定义一个标签集合,来表示所以可能取到的预测结果。例如,针对需要被抽取的“姓名、电话、省、市、区、详细地址”等实体,标签集合可以定义为:
label = {P-B, P-I, T-B, T-I, A1-B, A1-I, A2-B, A2-I, A3-B, A3-I, A4-B, A4-I, O}
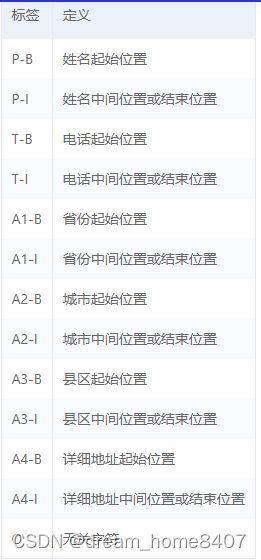
注意每个标签的结果只有 B、I、O 三种,这种标签的定义方式叫做 BIO 体系,也有稍麻烦一点的 BIESO 体系,其中 B 表示一个标签类别的开头,比如 P-B 指的是姓名的开头;相应的,I 表示一个标签的延续。
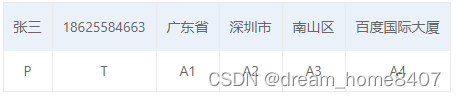
对于句子“张三18625584663广东省深圳市南山区百度国际大厦”,每个汉字及对应标签为:

注意到“张“,”三”在这里表示成了“P-B” 和 “P-I”,“P-B”和“P-I”合并成“P” 这个标签。这样重新组合后可以得到以下信息抽取结果:
总结:
1.根据业务需求定义标签
2.转为bio的标注方式
3.找序列标注开源工具,在git上
训练模型
先读入数据,将数据格式转换成预训练模型输入的数据格式
tag.dict存入的数据类别
将明文转化为tokenid送入模型
模型输入分别是 向量,位置,类别

