
- 1SE-Net:Squeeze-and-Excitation Networks论文详解_se注意力机制论文
- 2技术开发知识库_开发过程专家知识库
- 3二叉树遍历方法——前、中、后序遍历(图解)_二叉树遍历前序中序后序
- 4为什么前端工程师的工资越来越高了?_前端为什么比后端工资高
- 5自动化平台测试开发方案(详解自动化平台开发)_自动化测试开发
- 6寻找数组中的最小值和最大值——编程之美2.10_dw法的取值中最大值和最小值
- 7Unity中关于SendMessage方法_安卓 unitysendmessage
- 8【AIGC】探索大语言模型中的词元化技术机器应用实例_大模型 词元划分
- 9win11如何安装及使用ncat(nc命令)_windows ncat
- 10数字信号处理|Matlab设计巴特沃斯低通滤波器(冲激响应不变法和双线性变换法)
ZooKeeper 的架构是怎样的?_zookeeper架构
赞
踩
前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见大数据技术体系
正文
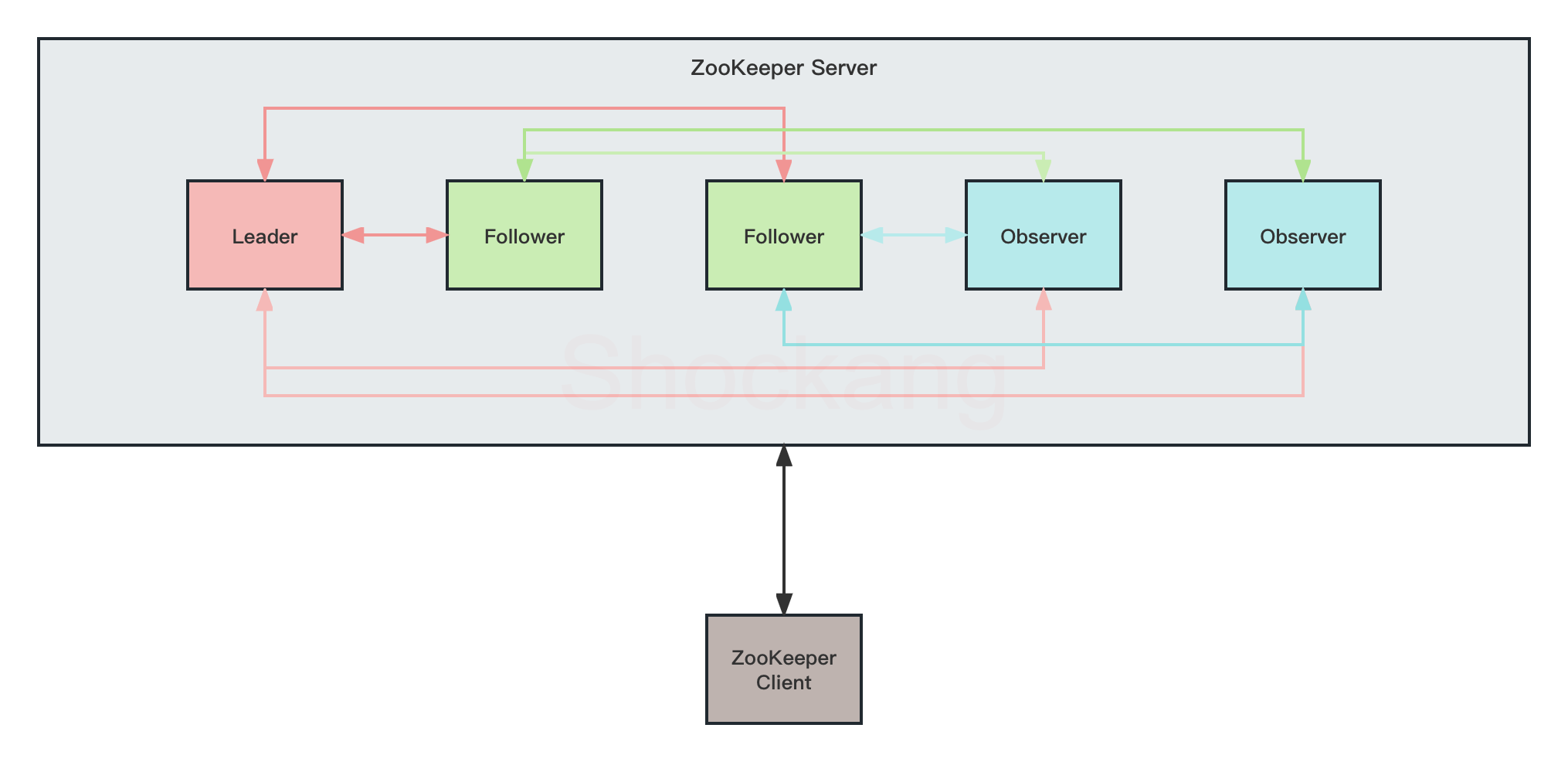
ZooKeeper 的架构图主要包含以下几个部分:
- ZooKeeper Client:是 ZooKeeper 的客户端,可以连接到任意一个 ZooKeeper Server 上(除非 leaderServes 参数被显式设置,leader 不允许接受客户端连接)。客户端使用并维护一个 TCP 连接,通过这个连接发送请求、接收响应、获取观察的事件以及发送心跳。如果这个 TCP 连接中断,客户端将自动尝试连接到另外的 ZooKeeper Server。
- ZooKeeper Server:是 ZooKeeper 的服务端,可以组成一个集群来提供高可用的分布式协调服务。
ZooKeeper Server 有三种角色:Leader、Follower 和 Observer
-
Leader:是整个 ZooKeeper 集群工作机制中的核心。Leader 作为整个 ZooKeeper 集群的主节点,负责响应所有对 ZooKeeper 状态变更的请求。主要工作有:事务请求的唯一调度和处理,保障集群处理事务的顺序性。集群内各服务器的调度者。Leader 选举是 ZooKeeper 最重要的技术之一,也是保障分布式数据一致性的关键所在。
-
Follower:是 ZooKeeper 集群状态的跟随者。他的逻辑就比较简单。除了响应本服务器上的读请求外,follower 还要处理 leader 的提议,并在 leader 提交该提议时在本地也进行提交。另外需要注意的是,leader 和 follower 构成 ZooKeeper 集群的法定人数,也就是说,只有他们才参与新 leader 的选举、响应 leader 的提议。
-
Observer:服务器充当一个观察者的角色。如果 ZooKeeper 集群的读取负载很高,或者客户端多到跨机房,可以设置一些 observer 服务器,以提高读取的吞吐量。
Observer 和 Follower 比较相似,只有一些小区别:首先 observer 不属于法定人数,即不参加选举也不响应提议,也不参与写操作的“过半写成功”策略;其次是 observer 不需要将事务持久化到磁盘,一旦 observer 被重启,需要从 leader 重新同步整个名字空间。
ZooKeeper 集群中节点(Leader+Follower)个数通常是奇数,方便投票选举。ZooKeeper 中的选举机制请参考我的这篇博客——《一篇文章搞懂 ZooKeeper 的选举机制》
通信
Leader 和 Follower 之间的通信
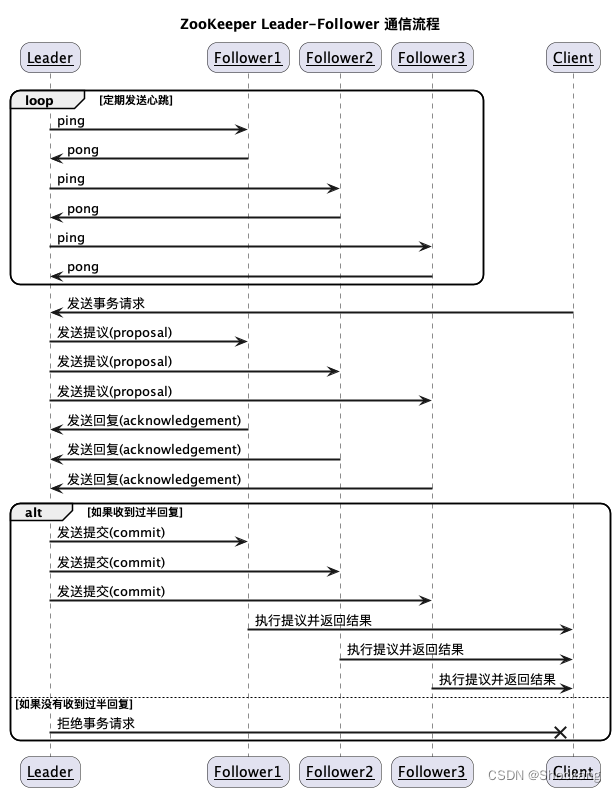
- Leader 发送提议(proposal)给 Follower,提议包含了要执行的事务请求和事务编号。
- Follower 收到提议后,如果同意,就发送回复(acknowledgement)给 Leader。
- Leader 收到过半 Follower 的回复后,就发送提交(commit)给所有 Follower,表示该提议可以执行了。
- Follower 收到提交后,就在本地执行该提议,并向客户端返回结果。
- Leader 和 Follower 还会定期发送心跳(ping)给对方,以维持连接和检测故障。
Leader 和 Observer 之间的通信
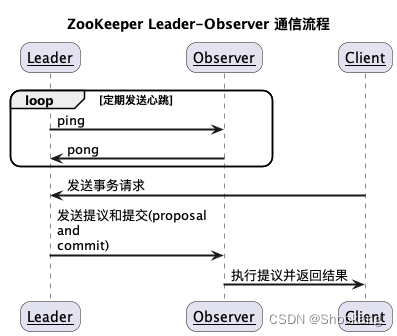
- Leader 发送提议和提交给 Observer,Observer 只需要等待提交就可以执行事务,不需要发送回复给 Leader。
- Observer 收到提交后,就在本地执行该提议,并向客户端返回结果。
- Leader 和 Observer 还会定期发送心跳给对方,以维持连接和检测故障。
Follower 和 Observer 之间的通信
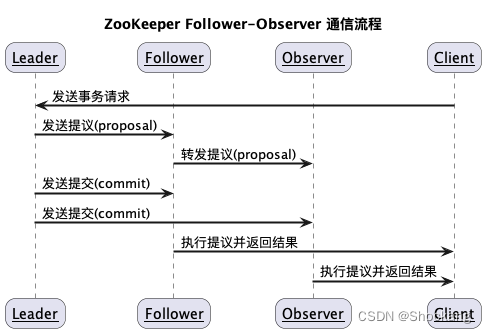
- Follower 可以将自己收到的提议转发给 Observer,以减轻 Leader 的负担。
- Observer 收到提议后,仍然需要等待 Leader 的提交才能执行事务。
Follower 和 Follower 之间有通信吗?
- Follower 和 Follower 之间没有通信,他们只和 Leader 通信。
- 这是为了简化 ZooKeeper 的协议和实现,避免复杂的多对多通信。
- Follower 和 Follower 之间的数据一致性是通过 Leader 的提议和提交来保证的。
Observer 和 Observer 之间有通信吗?
- Observer 和 Observer 之间没有通信,他们只和 Leader 或 Follower 通信。
- 这是为了简化 ZooKeeper 的协议和实现,避免复杂的多对多通信。
- Observer 和 Observer 之间的数据一致性是通过 Leader 或 Follower 的提议和提交来保证的。

