
- 1Hadoop常用的操作命令_movefromlocal
- 2波士顿房价预测案例(python scikit-learn)---多元线性回归(多角度实验分析)
- 3模糊C均值聚类简述
- 4kendo ui grid选中行事件,获取combobox选择的值_kendo grid 行内下拉框选中后不回显选中的值
- 5如何做好nodejs服务在服务器上的安全防护?_nodejs helmet
- 6Python 基础语法_chmod +x detect.py
- 7从点点点到年薪30W的心理历程--测试君请进,绝对让你不虚此行!_测试点点点工资
- 8YOLOv8 代码逐行解析(一) 项目目录构造分析_yolov8工程目录_yolov8模型应用于java项目
- 9es和redis都可以存储数据,那么开发中凯怎么选择
- 10制作一个搜题公众号_数据库制作搜题
【AIGC】探索大语言模型中的词元化技术机器应用实例_大模型 词元划分
赞
踩
科技前沿:探索大语言模型中的词元化技术及其应用实例
随着人工智能技术的迅猛发展,自然语言处理领域也取得了长足的进步。其中,大语言模型的崛起为文本处理带来了革命性的变化。而在这背后,词元化技术扮演着至关重要的角色。本文将深入探讨词元化技术的原理、应用实例以及其在当前科技热点中的体现,并通过实例和代码展示其在实际项目中的应用效果。
一、词元化技术的原理与重要性
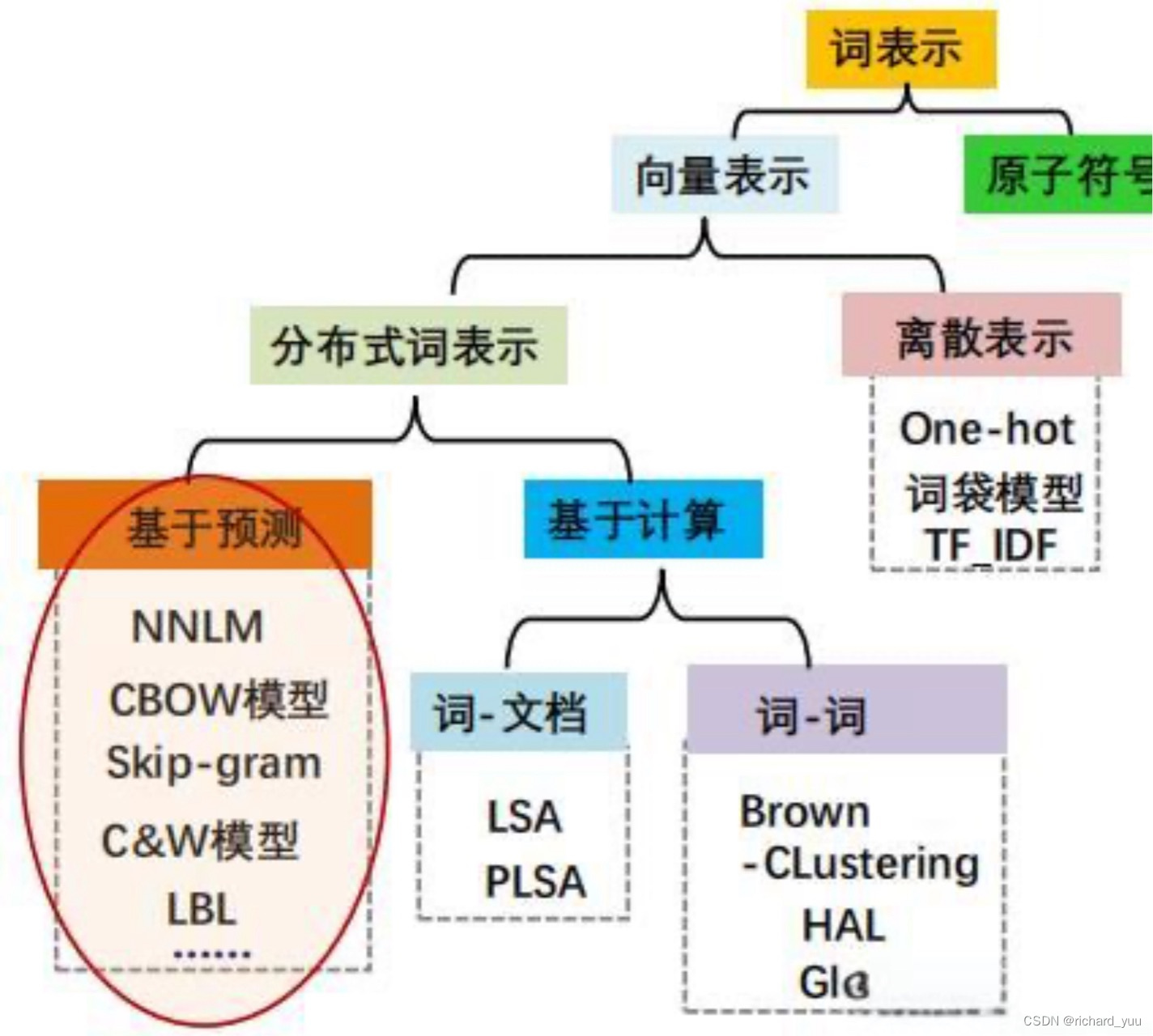
词元化(Tokenization)作为大语言模型预训练数据准备的关键步骤,其目标是将原始文本分割成模型可识别和建模的词元序列。这一过程不仅关系到模型能否准确理解文本内容,还直接影响到模型的训练效率和性能。通过词元化,原始文本被转化为模型能够理解的数字序列,为后续的词嵌入、模型训练等步骤奠定基础。
在实际应用中,词元化的粒度选择至关重要。Word级别的分词能够保留完整的单词语义,但面临长尾效应和稀有词问题;Char级别的分词虽然解决了OOV问题,但可能缺乏明确的语义信息,且计算成本较高;而Subword级别的分词则试图在两者之间找到平衡,通过合并字符或字符组合形成新的词汇单元,既保留了语义信息,又减少了OOV问题的发生。
二、词元化技术的应用实例与代码展示
以英文文本处理为例,我们可以使用开源的分词器工具如SentencePiece进行词元化处理。SentencePiece支持BPE、WordPiece和Unigram等多种分词方法,能够灵活应对不同语言和数据集的特点。
以下是一个使用SentencePiece进行词元化的简单示例:
python import sentencepiece as spm # 加载预训练的模型 sp = spm.SentencePieceProcessor() sp.Load('model.spm') # 对文本进行词元化 text = "This is a sample text for tokenization." tokens = sp.EncodeAsPieces(text) print(tokens) 输出结果为: [' This', ' is', ' a', ' sample', ' text', ' for', ' tokenization', '.']

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
在上述代码中,我们首先加载了一个预训练的SentencePiece模型,然后使用该模型对输入的文本进行词元化处理。输出的结果是一个词元序列,每个词元都对应原始文本中的一个或多个字符或字符组合。
除了英文,词元化技术同样适用于中文等其他语言。对于中文文本,我们可以采用基于字符或字节级别的分词方法,如BBPE(字节级别的BPE)。BBPE通过将字节作为合并操作的基本符号,能够更有效地处理中文文本中的生僻字和特殊符号。
三、词元化技术在科技热点中的应用
随着自然语言处理技术的广泛应用,词元化技术也在各个科技领域中发挥着重要作用。以智能问答系统为例,通过词元化技术将用户的问题转化为模型可理解的词元序列,系统能够更准确地理解用户意图,从而给出更加精准的答案。
此外,在机器翻译、情感分析、文本分类等任务中,词元化技术也扮演着不可或缺的角色。它能够帮助模型更好地捕捉文本中的语义信息,提高任务的完成质量和效率。
四、总结与展望
词元化技术作为大语言模型预训练数据准备的关键步骤,对于提升模型的性能和效率具有重要意义。通过选择合适的分词粒度和分词器类型,我们可以根据具体任务和数据集的特点进行灵活调整,以达到最佳的处理效果。
未来,随着自然语言处理技术的不断发展,词元化技术也将不断优化和创新。我们可以期待更加高效、准确的分词方法的出现,为文本处理领域带来更多的可能性。同时,词元化技术也将与其他先进技术相结合,如深度学习、强化学习等,共同推动自然语言处理领域的发展。

