
- 1MongoDB性能最佳实践:硬件和操作系统配置_mongodb性能最佳实践:硬件和操作系统配置
- 2Python实现机器学习(下)— 数据预处理、模型训练和模型评估_python 建立模型和模型训练
- 3PLC工业网关,实现PLC联网
- 4keil5创建寄存器编程模板_怎么在keil里设定寄存器
- 5半天学会深度学习故障识别!从入门到发文!CNN,BiLSTM,GRU,LSTM,TCN和CNN-LSTM,CNN-GRU全家桶!_[链接]半天学会深度学习预测,从入门到发文!cnn,bilstm,gru,lstm,tcn和cnn-
- 6高可用 Prometheus:问题集锦_prometheus高可用方案
- 7Matlab无基础快速上手1(遗传算法框架)
- 8git修改远程仓库的分支名称_git修改远程仓库名称
- 9若依新建模块后接口404_ruoyi新增模块,系統接口404
- 10什么是数字化?为什么需要数字化?
ARTrack论文阅读分享(单目标跟踪)
赞
踩
PS:好久没写csdn了,比较懒,临近过年了提前祝各位读者新年快乐。 (新年玩嗨了,都忘续写了,惭愧惭愧),新年已过,祝各位龙年吉祥。
偶然碰到了这篇论文,觉得是一种很新颖的架构,所以拿过来分享下。
(上一个觉得很新颖的架构是SeqTrack,但又觉得只是把输入和输出变一变又太普通了,所以没有写相关论文精读笔记,如有需要可以留言)
今天分享的论文是ARTrack:Autoregressive Visual Tracking (自回归视觉跟踪),字越少,论文越“狠”。
GitHub网址:https://github.com/MIV-XJTU/ARTrack
单目标跟踪的相关背景就不详细展开。
文章最主要的创新点
将跟踪视为坐标序列解释任务,通过学习一个简单的端到端模型对轨迹序列变化进行建模,以保持对目标的跨帧跟踪
以往传统的SOT的想法:通常将跟踪视为每帧模板匹配问题,进而忽略了视频帧之间的时序依赖性。
前言/概述
ARTrack将跟踪视为一项坐标序列解释任务,逐步估计物体轨迹,其中当前估计是由先前的状态引起的,进而影响子序列。
这种时间自回归方法对轨迹的顺序演化进行建模,以保持跨帧跟踪对象,使其优于现有的仅考虑每帧定位精度的基于模板匹配的跟踪器。ARTrack简单直接,省去了后处理。
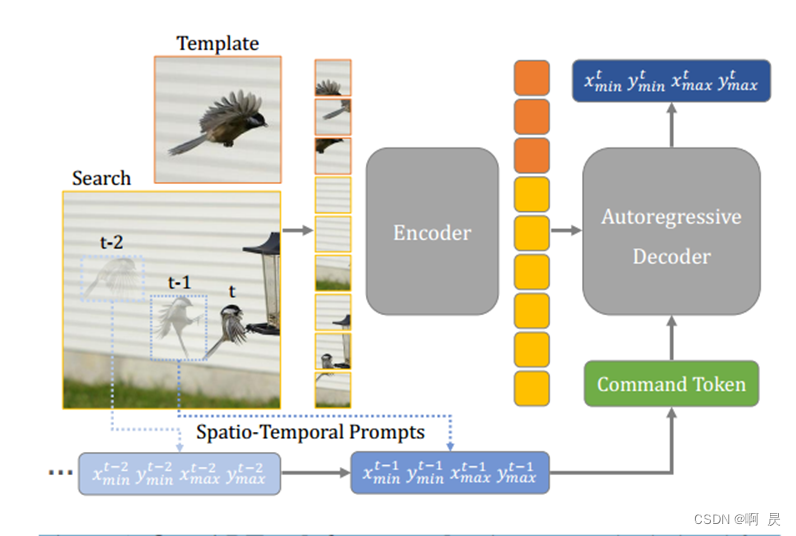
图片分析:
-
template和search(t时刻) 与之前的操作步骤是一样的,变为patch embedding送入编码器,提取特征,特征交互。
-
search图片中多个虚影表示先前的状态,t时刻表示当前状态。先前的状态经过一些处理作为command token 进入到自回归的解码器,影响当前状态(t随时间增加以此往复)。
-
输出方面,和seqTrack一致, 直接回归目标框的两个点(左上右下)。
传统跟踪中的问题(未考虑帧关系)
- 传统的跟踪方法做的是每帧的模板匹配,从而忽略了帧之间的连续性。
- 某些算法中涉及的模板更新和后处理技术过于复杂,可能需要单独的训练(e.g. mixformer中的模板更新)和推理,这会损害简单的端到端框架。
- 和1问题差不多,目标跟踪强调在整个序列中保持定位精度,而传统的跟踪方法旨在每帧中优先考虑即时定位精度,导致训练和推理之间的客观不匹配。(作者认为我们更应该看重整个跟踪的流程、序列。而不是过于关注每帧的定位。全局最优≠每时刻最优)
本文的改进
把视觉跟踪作为一个连续的坐标解释任务,以条件概率的形式表述:
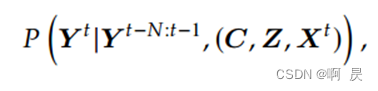
在t时,通过前N个时刻, command token , Z ,X_t 来预测t时刻结果的概率。
作者简称这个公式为AR(N)
C:图片里的command token
Z: template 模板Z也可以在每个时间步长使用更新机制[13,56]进行更新,或者简单地作为初始机制[40,64]
X_t : t时刻的search
Y_t t时刻预测的结果
特别 的 AR(0) = 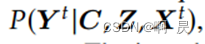
此时不以先前的状态为条件
最重要的三大组成
Sequence Construction from Object Trajectory
Tokenization(标志化)
t时刻的预测包含4个值 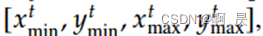 。 tokenization的思想是,将这些值缩放到 [1,n_bins]范围内的整数(这里有点参照量化的思想,通过压缩的方法,减少计算量, 比如图片大小 256*256,要把结果压缩到[1,16] 就是把所有的像素位置压缩了16倍, 可想此时的的精确度会挺低的,因为原来(256)预测(0–15) 都对应[1,16]中的1。)。
。 tokenization的思想是,将这些值缩放到 [1,n_bins]范围内的整数(这里有点参照量化的思想,通过压缩的方法,减少计算量, 比如图片大小 256*256,要把结果压缩到[1,16] 就是把所有的像素位置压缩了16倍, 可想此时的的精确度会挺低的,因为原来(256)预测(0–15) 都对应[1,16]中的1。)。
Trajectory coordinate mapping(轨迹坐标映射)
主要讲了坐标映射的关系----------大多数跟踪器裁剪搜索区域以降低计算成本,导致了坐标的映射关系变得略微复杂,最终预测的位置是相对于裁剪的搜索区域的坐标,而非原图坐标。在本文的方法中,作者将前面的框坐标缓存在全局坐标系中声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

