
- 1HASH 哈希算法之MD5 算法_c++ md5哈希值计算
- 2微服务解决方案 -- OSS对象存储服务 (外传一)_对象存储系统的微服务化
- 3FPGA基于VCU的H265视频压缩,HDMI2.0输入,支持4K60帧,提供工程源码+开发板+技术支持_fpga h265视频编码
- 4【第20期】实践深度学习?先接住这三板斧再说
- 5【已解决】RuntimeError: CUDA out of memory. Tried to allocate 50.00 MiB (GPU 0; 4.00 GiB total capacity;_torch.cuda.outofmemoryerror: cuda out of memory. t
- 6Day28:ElasticSearch入门、Spring整合ES、开发社区搜索功能
- 7DPlayer-node安装docker报错:localunixsocket is it running?_usermod: group 'docker' does not exist
- 8机器学习中的准确率、精确率、召回率、F1值、ROC/AUC整理笔记_f1值 准确率 精确率那个重要
- 9SpringCloud学习
- 10QPushButton&&QT窗口设置_qt pushbutton 不打卡对话框设置
MySQL的缓冲池(buffer pool)及 LRU算法_buffer pool 污染
赞
踩
1.什么是缓冲池(buffer pool)
buffer pool 是数据库的一个内存组件,里面缓存了磁盘上的真实数据,Java系统对数据库的增删改操作,主要是这个内存数据结构中的缓存数据执行的。
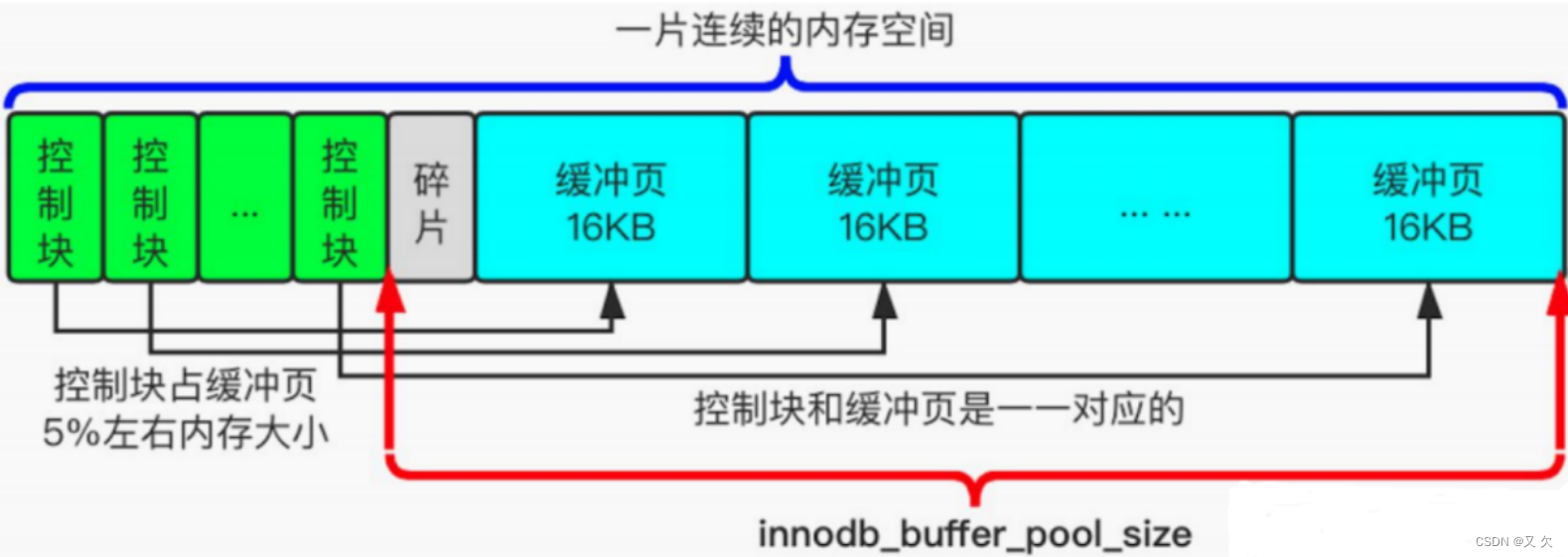
控制块
- 存的是 数据页所属的表 空间号,数据页编号,数据页地址等信息
- 是放在缓存页的前面
- 控制块占缓冲页百分之5左右的内存大小
缓存页
1.buffer pool中存放的数据页我们叫缓存页,和磁盘上的数据页是一一对应的,都是16KB
2.缓存页的数据,是从磁盘上加载到buffer pool当中的
2. 缓冲池有什么作用
MySQL的InnoDB能使用内存会尽量的使用内存。这样是为了加速数据访问,把查询数据放在MySQL作为一个存储系统,使用缓冲池(buffer pool)机制,以避免每次查询数据都进行磁盘IO。
它的默认大小是128M。在实际的生产环境中可以通过参数innodb_buffer_pool_size对 buffer pool进行调整,一般建议设置成可用物理内存的 60%~80%。
那么在一条update语句中,缓冲池是什么作用呢?’
执行SQL语句
update user set name=’李四‘ where id=3
- 1
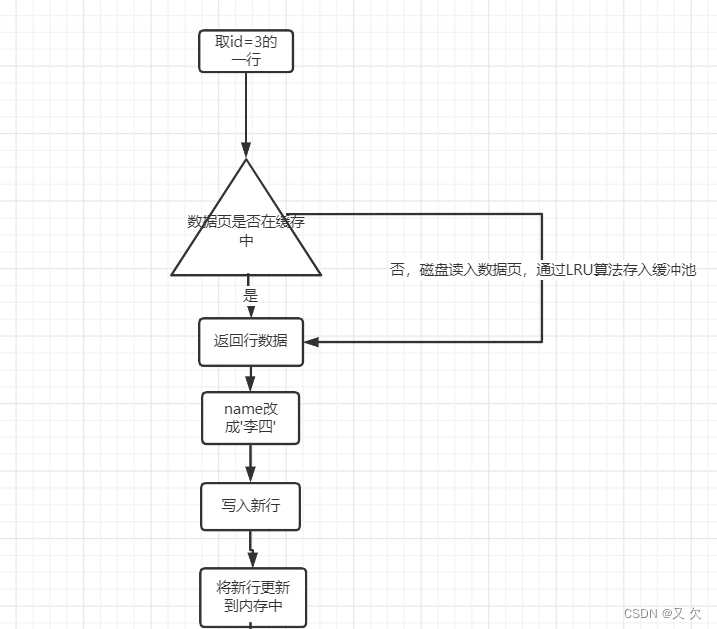
这条SQL语句执行流程是这样的:
- 在主键id这颗树上上找到id=3这一行数据
- 判断这一行数据页是否在内存(缓冲池)中
- 如果在缓冲池中,直接返回数据。不在缓冲池中,就从磁盘读入数据页。并通过LRU算法存入缓冲池
- 在数据页找到这一行数据,并把name改成李四
- 将此行数据更新到内存中。
- 进行两阶段提交。
在这条SQL语句中,我们可以知道MySQL它是会先从内存中读取我们的数据页,如果内存中没有数据页,我们就会在去读磁盘。
怎么知道数据页是否被缓存?
因为buffer pool内部存储它是一个hash结构。优化器会通过这张表所对应的表空间+页号计算为key,然后通过value对应的缓冲页的控制块。这样就可以通过表空间+页号找到控制块,然后通过控制块找到缓冲页了
而我们缓冲池(buffer pool)它是有固定大小的,虽然我们一页是数据是16KB。但是数据页多了,难免会把缓冲池(buffer pool)撑满,这个时候缓冲池(buffer pool)是怎么进行淘汰的呢?这个就是我们接下来要讲的MySQL的LRU算法。
3. 什么是LRU算法
LRU是Least Recently Used的缩写,即最近最少使用,选择最近最久未使用的页面予以淘汰。在InnoDB 管理 Buffer Pool 的 LRU 算法,它巧妙的使用了链表,把刚访问的数据放在链表头部,链表尾部的就是最近未被访问过的数据,予以淘汰。

链表头部是 P1,表示 P1 是最近刚刚被访问过的数据页;PN表示的是链表的尾部;先假设内存里只能放下这么多数据页;

这时候有一个读请求访问 P4,因此变成状态 2,P4 被移到最前面;
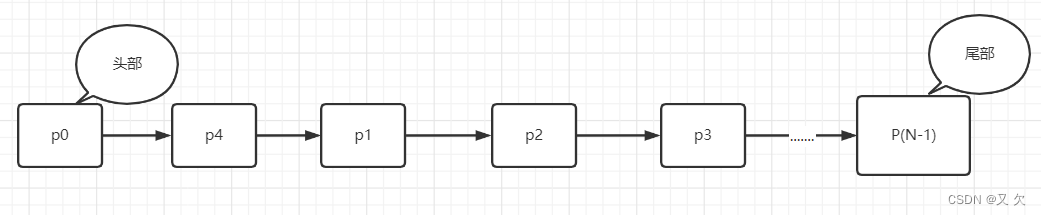
这次访问的数据页是p0,它不存在于链表中的,所以需要在 Buffer Pool 中新申请一个数据页 P0,加到链表头部。但是由于内存已经满了,不能申请新的内存。于是,会清空链表末尾 PN 这个数据页的内存。在存入 P0 的内容,然后放到链表头部。
这个算法有什么问题???
从算法的角度来看,这似乎没什么问题。但我们需要考虑到使用场景,为什么需要使用LRU 呢,为什么需要淘汰呢?
现在假如我们业务访问一个内存特别大、数据很多的表,这个表的内容也不是热点数据(假如是日志,或者历史数据),我们平时访问也很少。并且进行全表扫描
那么,按照这个算法扫描的话,就会把当前的 Buffer Pool 里的数据全部淘汰掉,存入扫描过程中访问到的数据页的内容。也就是说 Buffer Pool 里面主要放的是这个(日志、历史数据)表的数据。
对于一个正在做业务服务的库,这可不妙。你会看到,Buffer Pool 的内存命中率急剧下降,磁盘压力增加,SQL 语句响应变慢。
4. MySQL的LRU算法
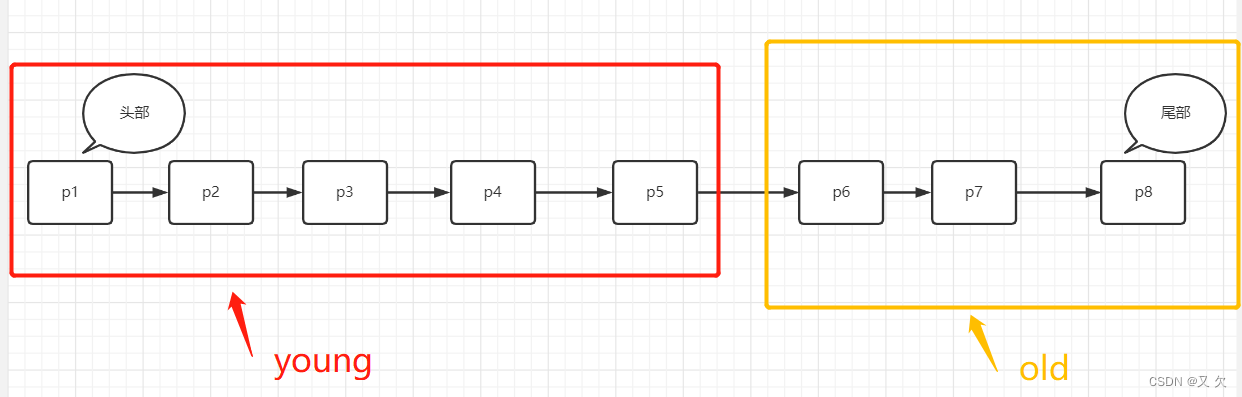
在 InnoDB 实现上,按照 5:3 的比例把整个 LRU 链表分成了 young 区域和 old 区域。图中p6就是 old 区域的第一个位置,是整个链表的 5/8 处。也就是说,靠近链表头部的 5/8 是 young 区域,靠近链表尾部的 3/8 是 old 区域。
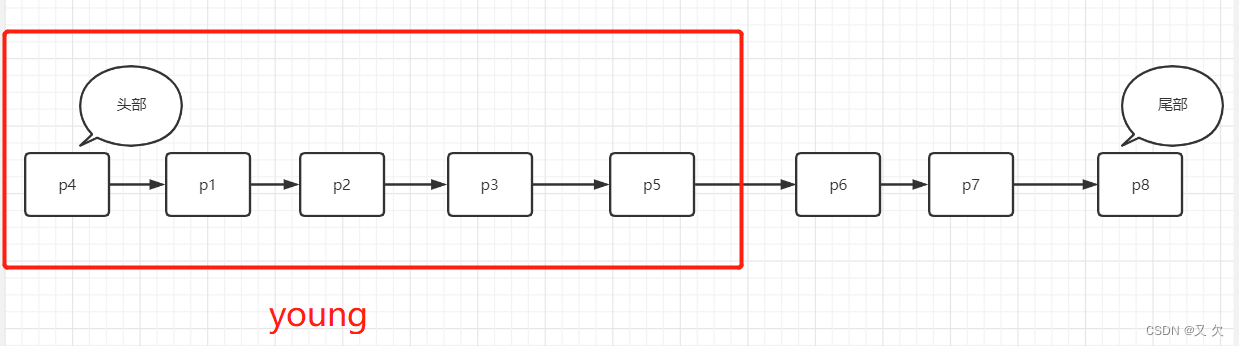
当我们在young区域访问数据时,假如要访问数据页 P4,由于 P4 在 young 区域,因此和优化前的 LRU 算法一样,将其移到链表头部。
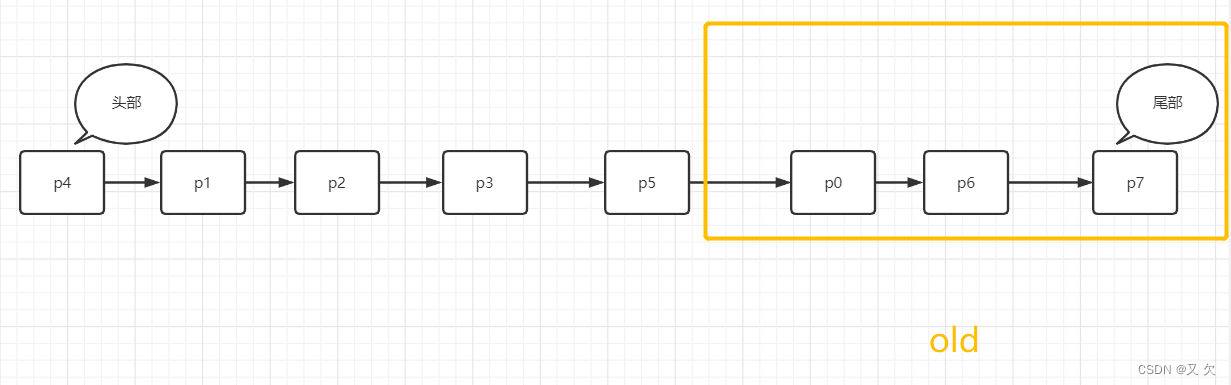
之后要访问一个新的不存在于当前链表的数据页,这时候依然是淘汰掉数据页 P8尾部数据,但是新插入的数据页 P0,是放在old区域的头部。
处于 old 区域的数据页,每次被访问的时候都要做下面这个判断:
1.若这个数据页在 LRU 链表中存在的时间超过了 1 秒,就把它移动到链表头部;
2.如果这个数据页在 LRU 链表中存在的时间短于 1 秒,位置保持不变。1 秒这个时间,是由参数 innodb_old_blocks_time 控制的。其默认值是 1000,单位毫秒。
这个策略,就是为了处理类似全表扫描的操作量身定制的。还是以刚刚例子。现在假如我们业务访问一个内存特别大、数据很多的表,这个表的内容也不是热点数据(假如是日志,或者历史数据),我们平时访问也很少。并且进行全表扫描
1.扫描过程中,需要新插入的数据页,都被放到 old 区域 ;
2.一个数据页里面有多条记录,这个数据页会被多次访问到,但由于是顺序扫描,这个数据页第一次被访问和最后一次被访问的时间间隔不会超过 1 秒,因此还是会被保留在 old 区域;
3.再继续扫描后续的数据,之前的这个数据页之后也不会再被访问到,于是始终没有机会移到链表头部(也就是 young 区域),很快就会被淘汰出去。
5.被淘汰的页怎么处理?
什么是脏页
当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为“脏页”。
什么是干净页
内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为“干净页”
MySQL什么时候会刷脏页
(1)redo log满了
因为我们redo log日志是有固定空间的,如果它满了的话,就会进行刷脏页 (flush 脏页)。MySQL会先把内存数据更新到磁盘上,并把redo log进行清空。这种情况是 InnoDB所有更新会为0,因为出现这种情况的时候,整个系统就不能再接受更新了,所有的更新都必须堵住。
(2)内存满了
因为我们MySQL的缓冲池是有固定内存大小的,当我们缓冲池满了的时候,这时候也会进行刷脏页。而这时在内存中的数据会有三种类型数据页
第一种是,还没有使用的; 第二种是,使用了并且是干净页;第三种是,使用了并且是脏页。
而当要读入的数据页没有在内存的时候,就必须到缓冲池中申请一个数据页。这时候只能把最久不使用的数据页从内存中淘汰掉:如果要淘汰的是一个干净页,就直接释放出来复用;但如果是脏页呢,就必须将脏页先刷到磁盘,变成干净页后才能复用。
(3)mysql空闲的时候
这个时候就是我们MySQL比较空闲,没有请求的时候。这个时候redo log会flush 脏页,会把内存中的脏页更新到我们的磁盘里。
(4)mysql正常关闭的时候
因为我们MySQL正常关闭,肯定是要把内存脏页更新到磁盘中的。
会影响性能的刷脏页操作
1.比如我们一个查询要淘汰的脏页个数太多,如果MySQL刷脏页速度很慢,则会导致查询的响应时间明显变长;
2.redo log 写满了,导致这个系统更新为0;
6.刷脏页控制策略
1.设置系统刷脏页的速度和能力
show global variables like ‘innodb_io_capacity’; 查看当前系统刷脏页的能力
set global innodb_io_capacity=200; 进行设置刷脏页速度
2.设置脏页比例
如果我们系统一直全力去刷盘的话,那其他业务必定会受到影响。所以我们需求设置脏页比例,去执行刷盘。脏页比例默认75%,一定不要让其接近75%**
查看当前脏页比例
参数innodb_max_dirty_pages_pct是脏页比例上限,默认值是75%
select VARIABLE_VALUE into @a from performance_schema.global_status where VARIABLE_NAME = ‘Innodb_buffer_pool_pages_dirty’; select VARIABLE_VALUE into @b from performance_schema.global_status where VARIABLE_NAME = ‘Innodb_buffer_pool_pages_total’; select @a/@b;
3. 刷脏页速度 nnodb_io_capacity定义的能力乘以R%(redolog)来控制刷脏页的速度
InnoDB每次写入的日志都有一个序号,当前写入的序号跟checkpoint对应的序号之间的差值,InnoDB会将这两个值经过一定的计算得出一个数,这个结果数就是用来控制刷脏页的速度。
4. innodb_flush_neighbors=0(不开启脏页相邻淘汰) (对于机械硬盘顺序读写会有提升,ssd无提升。iops普通机械硬盘只有几百,ssd有上千,可以不开启)
在MySQL 8.0中,innodb_flush_neighbors参数的默认值已经是0了。


