
- 1使用Docker快速部署Flink分布式集群_flink docker
- 2音视频开发领域常用的9大开源项目,你值得关注_音视频开发一般在什么平台
- 3【LaTeX】小白学习笔记补充——参考文献BibTeX格式使用
- 4【C++干货基地】面向对象核心概念 const成员函数 | 初始化列表 | explicit关键字 | 取地址重载
- 5技术面试,如何谈薪资?_如何跟技术leader聊薪资
- 6全球大数据产业发展现状与应用趋势
- 7使用 Amazon Bedrock Studio 构建生成式 AI 应用程序(预览版)
- 8PP-YOLO_ppyolo
- 9【LeetCode】给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。_js给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。 示例 1:
- 10Kotlin 集合操作符(元素操作符、顺序操作符、映射操作符、生产操作符、统计操作符、自定义操作符)_kotlin contains
基于java的网络爬虫框架(实现京东数据的爬取,并将插入数据库)_java github爬虫京东项目demo
赞
踩
本文为原创博客,仅供技术学习使用。未经允许,禁止将其复制下来上传到百度文库等平台。
目录
网络爬虫框架
写网络爬虫,一个要有一个逻辑顺序。本文主要讲解我自己经常使用的一个顺序,并且本人经常使用这个框架来写一些简单的爬虫,复杂的爬虫,也是在这个基础上添加其他程序。
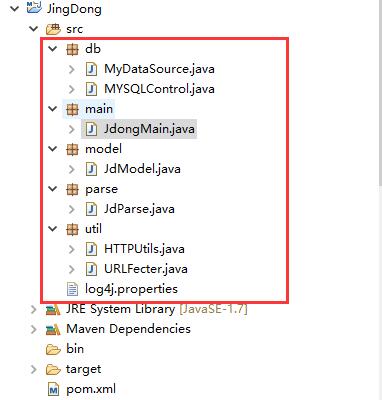
首先,我的工程都是使用maven建的,不会使用maven的,请看之前写的网络爬虫基础。使用Spring MVC框架编写过网站的同学,可以看出框架的重要性与逻辑性。在我的网络爬虫框架中,包含的package有db、main、model、parse、util五个文件。
db:主要放的是数据库操作文件,包含MyDataSource【数据库驱动注册、连接数据库的用户名、密码】,MYSQLControl【连接数据库,插入操作、更新操作、建表操作等】。
model:用来封装对象,比如我要获取京东书籍的ID、书名、价格,则需要在model写入对应的属性。说的直白一些,封装的就是我要操作数据对应的属性名。有不明白的看之前写的一个简单的网络爬虫。
util:主要放的是httpclient的内容,主要作用时将main方法,传过来的url,通过httpclient相关方法,获取需要解析的html文件或者json文件等。
parse:这里面存放的是针对util获取的文件,进行解析,一般采用Jsoup解析;若是针对json数据,可采用正则表达式或者fastjson工具进行解析,建议使用fastjson,因其操作简单,快捷。
main:程序起点,也是重点,获取数据,执行数据库语句,存放数据。
网络爬虫的逻辑顺序
针对我的网络爬虫框架,网络爬虫的逻辑顺序,可以描述为:首先,main方法,将url传给util获取响应的html文件,然后util将其获得的html文件,传给parse进行解析,获取最终数据,封装在集合中。解析完毕后,数据返回到main,接着main操作db将数据导入到mysql中。
网络爬虫实例教学
通过上面的框架,我们可以看出写一个网络爬虫,其实很简单(当然有很复杂的网络爬虫哦)。下面,我将带大家写一个基于java爬虫京东图书信息的网络爬虫,只是做讲解使用,供大家学习和参考。
首先,起点是什么?你可能觉得是main方法,其实不然,起点是你要知道你要获取网站中的哪些数据,然后针对要抓取的数据去写model。如下图,我要获取京东上的图书的价格,和图书名,还有图书的id(id是唯一标识,可作为数据表的主键)
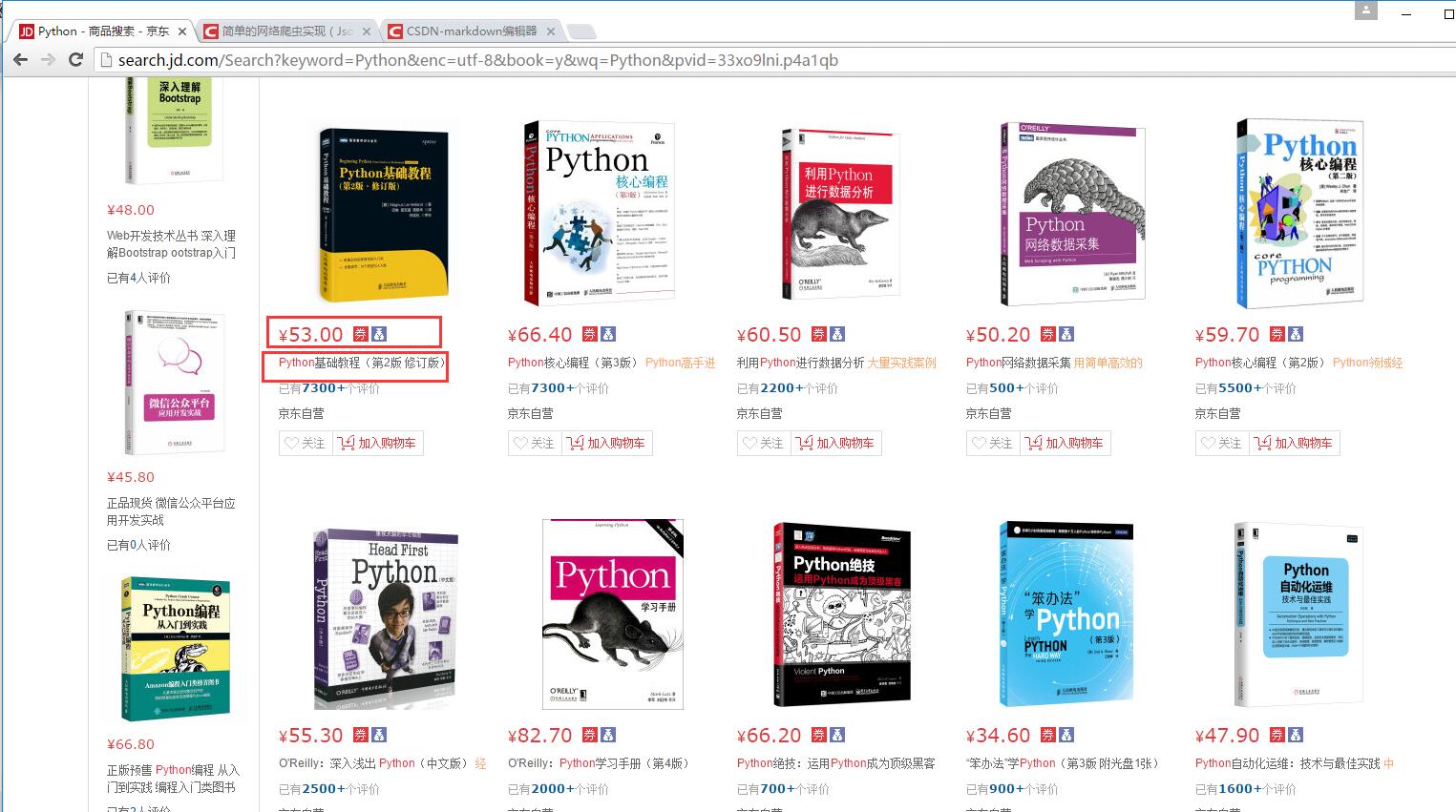
model
用来封装对象,我要抓取一本书的数据包括,书籍的id,书名及价格。ecliplse中生成set、get方法的快捷键是shift+alt+s然后选择生成setter、getter
package model;
/*
* 合肥工业大学 管理学院 qianyang 1563178220@qq.com
*/
public class JdModel {
private String bookID;
private String bookName;
private String bookPrice;
public String getBookID() {
return bookID;
}
public void setBookID(String bookID) {
this.bookID = bookID;
}
public String getBookName() {
return bookName;
}
public void setBookName(String bookName) {
this.bookName = bookName;
}
public String getBookPrice() {
return bookPrice;
}
public void setBookPrice(String bookPrice) {
this.bookPrice = bookPrice;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
main
主方法,尽量要求简单,这里我就这样写了。这里面有注释,很好理解。
package main;
import java.util.List;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.http.client.HttpClient;
import org.apache.http.impl.client.DefaultHttpClient;
import db.MYSQLControl;
import model.JdModel;
import util.URLFecter;
/*
* 合肥工业大学 管理学院 qianyang 1563178220@qq.com
*/
public class JdongMain {
//log4j的是使用,不会的请看之前写的文章
static final Log logger = LogFactory.getLog(JdongMain.class);
public static void main(String[] args) throws Exception {
//初始化一个httpclient
HttpClient client = new DefaultHttpClient();
//我们要爬取的一个地址,这里可以从数据库中抽取数据,然后利用循环,可以爬取一个URL队列
String url="http://search.jd.com/Search?keyword=Python&enc=utf-8&book=y&wq=Python&pvid=33xo9lni.p4a1qb";
//抓取的数据
List<JdModel> bookdatas=URLFecter.URLParser(client, url);
//循环输出抓取的数据
for (JdModel jd:bookdatas) {
logger.info("bookID:"+jd.getBookID()+"\t"+"bookPrice:"+jd.getBookPrice()+"\t"+"bookName:"+jd.getBookName());
}
//将抓取的数据插入数据库
MYSQLControl.executeInsert(bookdatas);
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
util
util中包含两个文件,URLFecter 与HTTPUtils,其中URLFecter 调用了HTTPUtils类。
package util;
import java.util.ArrayList;
import java.util.List;
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.util.EntityUtils;
import model.JdModel;
import parse.JdParse;
/*
* 合肥工业大学 管理学院 qianyang 1563178220@qq.com
*/
public class URLFecter {
public static List<JdModel> URLParser (HttpClient client, String url) throws Exception {
//用来接收解析的数据
List<JdModel> JingdongData = new ArrayList<JdModel>();
//获取网站响应的html,这里调用了HTTPUtils类
HttpResponse response = HTTPUtils.getRawHtml(client, url);
//获取响应状态码
int StatusCode = response.getStatusLine().getStatusCode();
//如果状态响应码为200,则获取html实体内容或者json文件
if(StatusCode == 200){
String entity = EntityUtils.toString (response.getEntity(),"utf-8");
JingdongData = JdParse.getData(entity);
EntityUtils.consume(response.getEntity());
}else {
//否则,消耗掉实体
EntityUtils.consume(response.getEntity());
}
return JingdongData;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
上面程序调用的HTTPUtils这个类,以下是HTTPUtils这个类。
package util;
import java.io.IOException;
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
import org.apache.http.HttpVersion;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.message.BasicHttpResponse;
/*
* 合肥工业大学 管理学院 qianyang 1563178220@qq.com
*/
public abstract class HTTPUtils {
public static HttpResponse getRawHtml(HttpClient client, String personalUrl) {
//获取响应文件,即html,采用get方法获取响应数据
HttpGet getMethod = new HttpGet(personalUrl);
HttpResponse response = new BasicHttpResponse(HttpVersion.HTTP_1_1,
HttpStatus.SC_OK, "OK");
try {
//执行get方法
response = client.execute(getMethod);
} catch (IOException e) {
e.printStackTrace();
} finally {
// getMethod.abort();
}
return response;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
parse
parse主要是通过Jsoup来解析html文件。并将解析后的数据,封装在List集合中,将数据通过层层返回到main方法中。
package parse;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import model.JdModel;
/*
* author qianyang 1563178220@qq.com
* 用于将上面传下来的html解析,获取我们需要的内容
* 解析方式,采用Jsoup解析,有不明白Jsoup的可以上网搜索API文档
* Jsoup是一款很简单的html解析器
*/
public class JdParse {
public static List<JdModel> getData (String html) throws Exception{
//获取的数据,存放在集合中
List<JdModel> data = new ArrayList<JdModel>();
//采用Jsoup解析
Document doc = Jsoup.parse(html);
//获取html标签中的内容
Elements elements=doc.select("ul[class=gl-warp clearfix]").select("li[class=gl-item]");
for (Element ele:elements) {
String bookID=ele.attr("data-sku");
String bookPrice=ele.select("div[class=p-price]").select("strong").select("i").text();
String bookName=ele.select("div[class=p-name]").select("em").text();
//创建一个对象,这里可以看出,使用Model的优势,直接进行封装
JdModel jdModel=new JdModel();
//对象的值
jdModel.setBookID(bookID);
jdModel.setBookName(bookName);
jdModel.setBookPrice(bookPrice);
//将每一个对象的值,保存到List集合中
data.add(jdModel);
}
//返回数据
return data;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
db
db中包含两个java文件,MyDataSource,MYSQLControl。这两个文件的作用已在前面说明了。
package db;
import javax.sql.DataSource;
import org.apache.commons.dbcp2.BasicDataSource;
/*
* 合肥工业大学 管理学院 qianyang 1563178220@qq.com
*/
public class MyDataSource {
public static DataSource getDataSource(String connectURI){
BasicDataSource ds = new BasicDataSource();
//MySQL的jdbc驱动
ds.setDriverClassName("com.mysql.jdbc.Driver");
ds.setUsername("root"); //所要连接的数据库名
ds.setPassword("112233"); //MySQL的登陆密码
ds.setUrl(connectURI);
return ds;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
下面是MYSQLControl,主要使用QueryRunner方法操作数据库,使用时是batch方法。
package db;
import java.sql.SQLException;
import java.util.List;
import javax.sql.DataSource;
import org.apache.commons.dbutils.QueryRunner;
import model.JdModel;
/*
* author qianyang 1563178220@qq.com
* Mysql操作的QueryRunner方法
* 一个数据库操作类,别的程序直接调用即可
*/
public class MYSQLControl {
//根据自己的数据库地址修改
static DataSource ds = MyDataSource.getDataSource("jdbc:mysql://127.0.0.1:3306/moviedata");
static QueryRunner qr = new QueryRunner(ds);
//第一类方法
public static void executeUpdate(String sql){
try {
qr.update(sql);
} catch (SQLException e) {
e.printStackTrace();
}
}
//第二类数据库操作方法
public static void executeInsert(List<JdModel> jingdongdata) throws SQLException {
/*
* 定义一个Object数组,行列
* 3表示列数,根据自己的数据定义这里面的数字
* params[i][0]等是对数组赋值,这里用到集合的get方法
*
*/
Object[][] params = new Object[jingdongdata.size()][3];
for ( int i=0; i<params.length; i++ ){
params[i][0] = jingdongdata.get(i).getBookID();
params[i][1] = jingdongdata.get(i).getBookName();
params[i][2] = jingdongdata.get(i).getBookPrice();
}
qr.batch("insert into jingdongbook (bookID, bookName, bookPrice)"
+ "values (?,?,?)", params);
System.out.println("执行数据库完毕!"+"成功插入数据:"+jingdongdata.size()+"条");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
再看main方法
在main方法中有这样一句程序,这便是调用了操作数据库MYSQLControl程序,将抓取的数据插入到数据库中了
MYSQLControl.executeInsert(bookdatas);- 1
爬虫效果展示
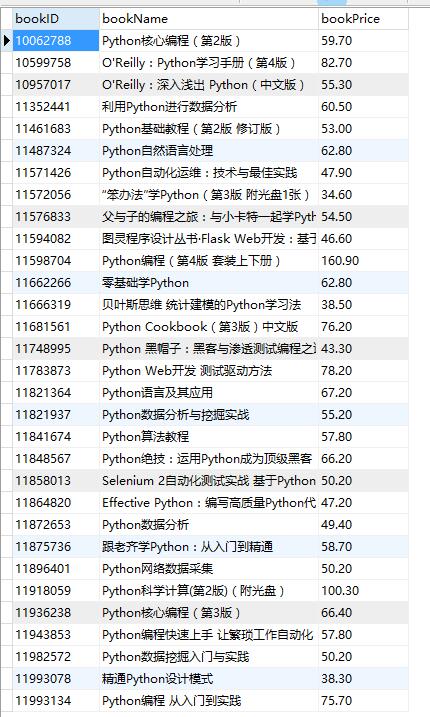
到此,便完成了这个简单网络爬虫的编程工作,下面来看看程序运行的结果吧。
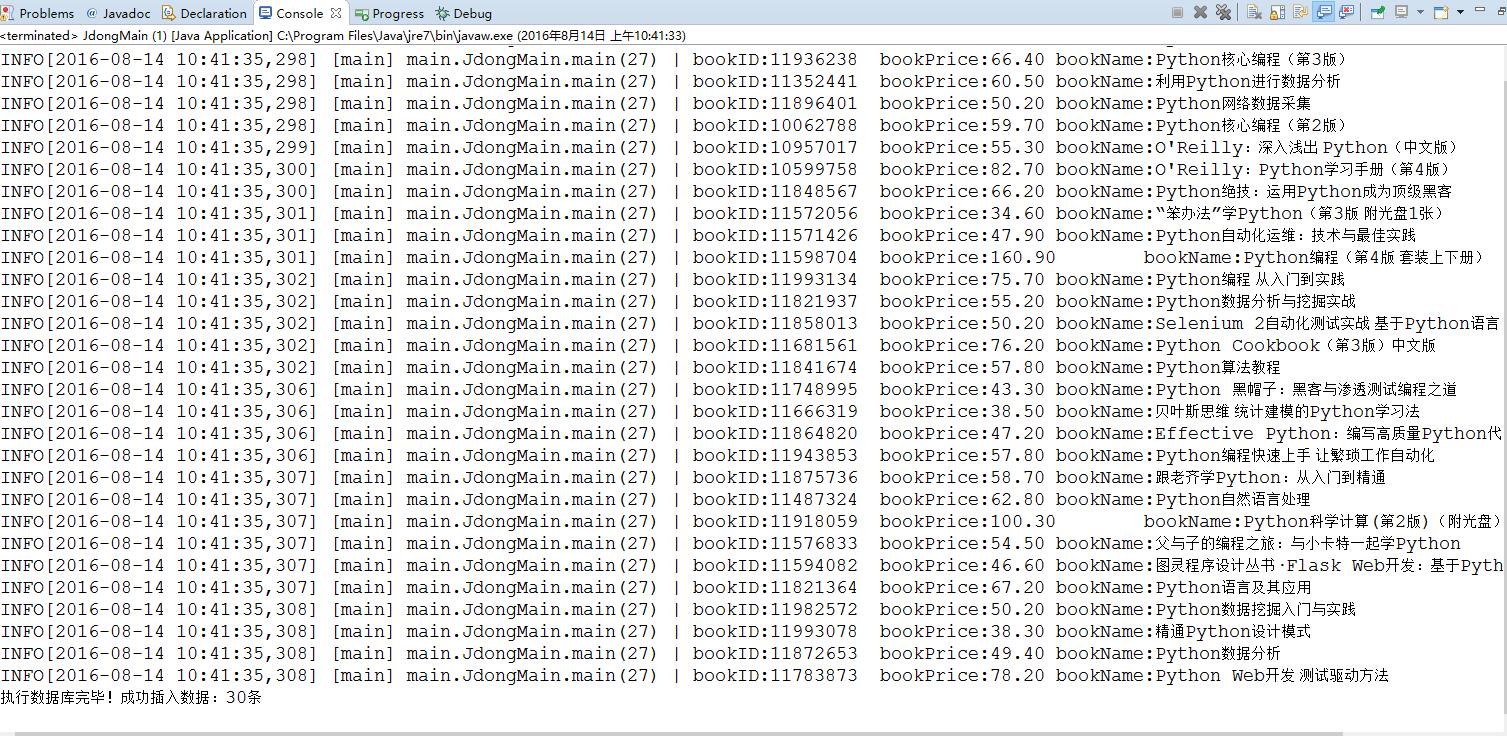
数据库中的结果如下:
有什么不明白的,请发邮件至1563178220@qq.com 合肥工业大学管理学院 qianyang

