
热门标签
热门文章
- 1555 电路_555构成反馈型施密特触发器
- 2【Linux】环境变量、进程替换、wait/waitpid
- 3毕业设计-基于Java web的图书馆预约占座管理系统_基于java web的图书馆座位预约系统
- 4C++领域新星创作者的申请与创作流程分享_csdn创作者认证要上传什么资料
- 5Apusic应用服务器文档_com.apusic.ams.embed
- 6java数据结构,线性表顺序存储(数组)的实现_java实现线性表
- 7Linux调度策略及线程优先级设置_linux 一个任务经常调度另一个线程偶尔调度该如何配置线程的调度方式和优先级
- 8GenAI---生成式AI的简介_gen ai
- 9springoot 集成百度文心千帆大模型应用,搭建企业微信应用消息,实现企业微信被动消息聊天服务_springboot 文心一言
- 10软考高项-第十二章 项目质量管理考点集锦
当前位置: article > 正文
nltk(1)——常用函数_concordance函数怎么用
作者:不正经 | 2024-05-16 05:50:31
赞
踩
concordance函数怎么用
搜索文本
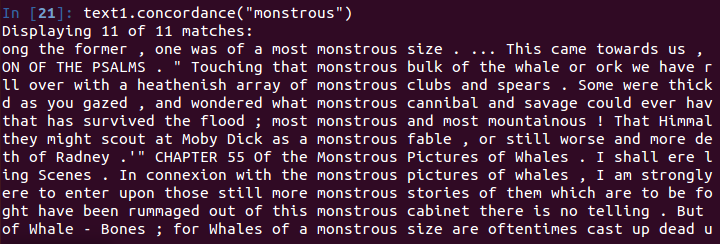
关键词上下文——concordance
使用函数concordance可以查找关键词每次的出现,以及连同关键词出现的上下文一起显示。(查看关键词出现的上下文)
from nltk.book import *
text1.concordance("monstrous")
相似上下文查找——similar
使用similar函数可以看到同关键词出现在相似的上下文中的词,即查找近义词
text1.similar("monstrous") #查找monstrous的近义词,出现在相似的上下文中的词

共同上下文——common_contexts
函数common_contexts允许研究两个或两个以上的词共同的上下文。
text2.common_contexts(["monstrous","very"])

注意此处的多个单词须要使用[]括起来
生成随意文本——generate
`text3.generate()` #基于文章生成新的随机文本
- 1
计数词汇
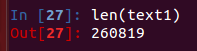
函数len
`len(text1)` #文本中出现的词和标点符号,从文本头到尾的长度
- 1
使用len()函数获取的是文本所有的标识符,其中有大量的重复成分,如何获取文本中的词汇数?
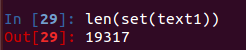
函数set
sorted(set(text1)) #获取文本text1的词汇表,并按照英文字母排序
len(set(text1)) #获取文本text1词汇表的数量(词类型)
注意set方法不能将文本中的标点符号过滤掉,其中包含了标点符号
标识符的平均使用次数
len(text1)/len(set(text1)) #词汇总数量/词汇表数量

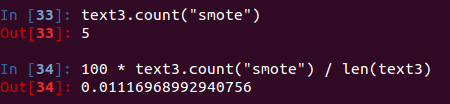
特定词的出现次数及占比
text3.count("smote") #单词smote在文本中出现次数
100 * text3.count("smote") / len(text3) #获取单词的占比
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

