
- 1关于前端开发的20篇文档与指南_前端开发指导文档
- 2Android Studio启动AVD报错:The emulator process for AVD Pixel_5_API_30 has terminated.最有效的解决方法_the emulator process for avd pixel 5 api 30has ter
- 3AutoDL平台Pycharm使用教程_pycharm jupyter使用autodl
- 4强制卸载 奇安信天擎_奇安信天擎怎么强制卸载
- 5C语言实现贪吃蛇游戏
- 6【SQLServer】JDBC连接SQLServer数据库_sqlserver jdbcurl string
- 7软考--各个网络层次的安全保障协议分类_物理层加密协议有哪些
- 8Gitee删除自己本地仓库_gitee怎么删除本地仓库
- 9零基础快速搭建Stable Diffusion(Windows版)_从0到1搭建stablediffusionxl
- 10RocketMQ —消费重试_rocketmq消费重试
c++ 优先队列_数据结构与算法系列 - 深度优先和广度优先
赞
踩

本文作者:何建辉(公众号:org_yijiaoqian)
前言
数据结构与算法系列(完成部分):
- 时间复杂度和空间复杂度分析
- 数组的基本实现和特性
- 链表和跳表的基本实现和特性
- 栈、队列、优先队列、双端队列的实现与特性
- 哈希表、映射、集合的实现与特性
- 树、二叉树、二叉搜索树的实现与特性
- 堆和二叉堆的实现和特性
- 图的实现和特性
- 递归的实现、特性以及思维要点
- 分治、回溯的实现和特性
- 深度优先搜索、广度优先搜索的实现和特性
- 贪心算法的实现和特性
- 二分查找的实现和特性
- 动态规划的实现及关键点
- Tire树的基本实现和特性
- 并查集的基本实现和特性
- 剪枝的实现和特性
- 双向BFS的实现和特性
- 启发式搜索的实现和特性
- AVL树和红黑树的实现和特性
- 位运算基础与实战要点
- 布隆过滤器的实现及应用
- LRU Cache的实现及应用
- 初级排序和高级排序的实现和特性
- 字符串算法
PS:大部分已经完成在公众号或者GitHub上,后面陆续会在头条补充链接(不允许有外部链接)
本篇讨论深度优先搜索和广度优先搜索相关内容。
关于搜索&遍历
对于搜索来说,我们绝大多数情况下处理的都是叫 “所谓的暴力搜索” ,或者是说比较简单朴素的搜索,也就是说你在搜索的时候没有任何所谓的智能的情况在里面考虑,很多情况下它做的一件事情就是把所有的结点全部遍历一次,然后找到你要的结果。
基于这样的一个数据结构,如果这个数据结构本身是没有任何特点的,也就是说是一个很普通的树或者很普通的图。那么我们要做的一件事情就是遍历所有的结点。同时保证每个点访问一次且仅访问一次,最后找到结果。
那么我们先把搜索整个先化简情况,我们就收缩到在树的这种情况下来进行搜索。
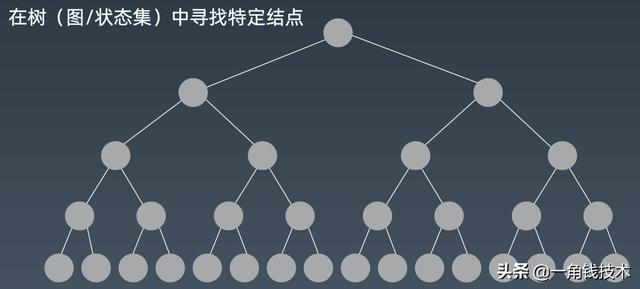
如果我们要找到我们需要的一个值,在这个树里面我们要怎么做?那么毫无疑问就是从根这边开始先搜左子树,然后再往下一个一个一个一个点走过去,然后走完来之后再走右子树,直到找到我们的点,这就是我们所采用的方式。
再回到我们数据结构定义,它只有左子树和右子树。
我们要实现这样一个遍历或者搜索的话,毫无疑问我们要保证的事情就是
- 每个结点都要访问一次
- 每个结点仅仅要访问一次
- 对于结点访问的顺序不限
-
- 深度优先:Depth First Search
- 广度优先:Breadth First Search
仅访问一次的意思就是代表我们在搜索中,我们不想做过多无用的访问,不然的话我们的访问的效率会非常的慢。
当然的话还可以有其余的搜索,其余的搜索的话就不再是深度优先或者广度优先了,而是按照优先级优先 。当然你也可以随意定义,比如说从中间优先类似于其他的东西,但只不过的话你定义的话要有现实中的场景。所以你可以认为是一般来说就是深度优先、广度优先,另外的话就是优先级优先。按照优先级优先搜索的话,其实更加适用于现实中的很多业务场景,而这样的算法我们一般把它称为启发式搜索,更多应用在深度学习领域。而这种比如说优先级优先的话,在很多时候现在已经应用在各种推荐算法和高级的搜索算法,让你搜出你中间最感兴趣的内容,以及每天打开抖音、快手的话就给你推荐你最感兴趣的内容,其实就是这个原因。
深度优先搜索(DFS)
递归写法
递归的写法,一开始就是递归的终止条件,然后处理当前的层,然后再下转。
- 那么处理当前层的话就是相当于访问了结点 node,然后把这个结点 node 加到已访问的结点里面去;
- 那么终止条件的话,就是如果这个结点之前已经访问过了,那就不管了;
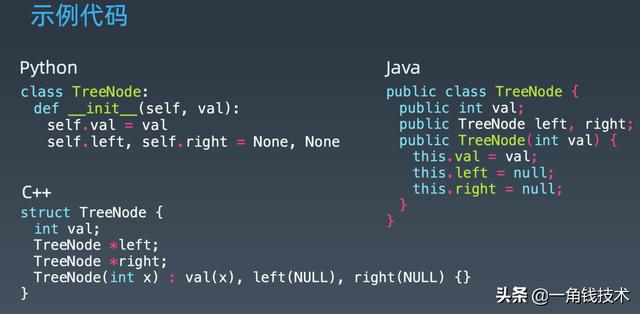
- 那么下转的话,就是走到它的子结点,二叉树来说的话就是左孩子和右孩子,如果是图的话就是连同的相邻结点,如果是多叉树的话这里就是一个children,然后把所有的children的话遍历一次。
- 二叉树模版
Java 版本
//C/C++//递归写法:map visited;void dfs(Node* root) { // terminator if (!root) return ; if (visited.count(root->val)) { // already visited return ; } visited[root->val] = 1; // process current node here. // ... for (int i = 0; i < root->children.size(); ++i) { dfs(root->children[i]); } return ;}Python 版本
#Pythonvisited = set() def dfs(node, visited): if node in visited: # terminator # already visited return visited.add(node) # process current node here. ... for next_node in node.children(): if next_node not in visited: dfs(next_node, visited)C/C++ 版本
//C/C++//递归写法:map visited;void dfs(Node* root) { // terminator if (!root) return ; if (visited.count(root->val)) { // already visited return ; } visited[root->val] = 1; // process current node here. // ... for (int i = 0; i < root->children.size(); ++i) { dfs(root->children[i]); } return ;}JavaScript版本
visited = set() def dfs(node, visited): if node in visited: # terminator # already visited return visited.add(node) # process current node here. ... for next_node in node.children(): if next_node not in visited: dfs(next_node, visited)- 多叉树模版
visited = set() def dfs(node, visited): if node in visited: # terminator # already visited return visited.add(node) # process current node here. ... for next_node in node.children(): if next_node not in visited: dfs(next_node, visited)非递归写法
Python版本
#Pythondef DFS(self, tree): if tree.root is None: return [] visited, stack = [], [tree.root] while stack: node = stack.pop() visited.add(node) process (node) nodes = generate_related_nodes(node) stack.push(nodes) # other processing work ...C/C++版本
//C/C++//非递归写法:void dfs(Node* root) { map visited; if(!root) return ; stack stackNode; stackNode.push(root); while (!stackNode.empty()) { Node* node = stackNode.top(); stackNode.pop(); if (visited.count(node->val)) continue; visited[node->val] = 1; for (int i = node->children.size() - 1; i >= 0; --i) { stackNode.push(node->children[i]); } } return ;}遍历顺序
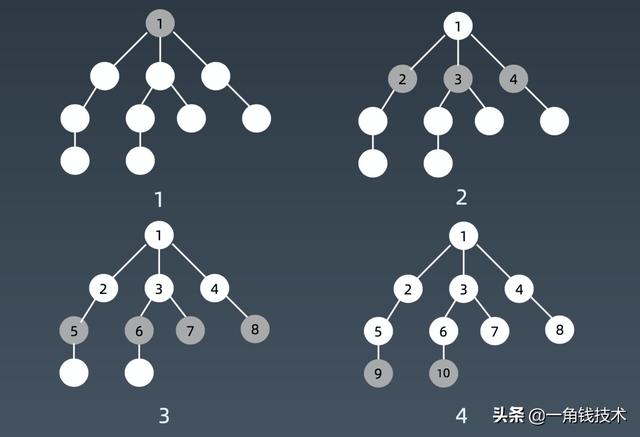
我们看深度优先搜索或者深度优先遍历的话,它的整个遍历顺序毫无疑问根节点 1 永远最先开始的,接下来往那个分支走其实都一样的,我们简单起见就是从最左边开始走,那么它深度优先的话就会走到底。
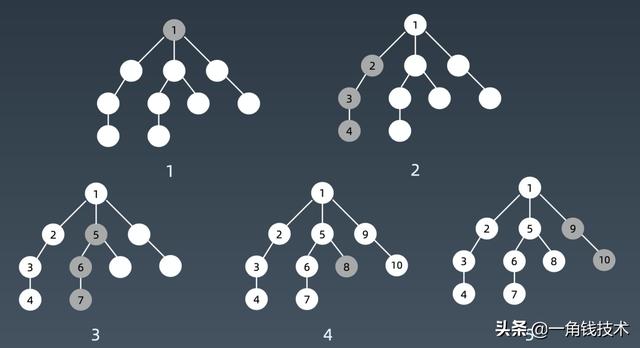
参考多叉树模版我们可以在脑子里面或者画一个图把它递归起来的话,把递归的状态树画出来,就是这么一个结构。
- 就比如说它开始刚进来的话,传的是 root 的话,root 就会先放到 visited 里面,表示 root 已经被 visit,被 visited之后就从 root.childern里面找 next_node,所有它的next_node都没有被访问过的,所以它就会先访问最左边的这个结点,这里注意当它最左边这个结点先拿出来了,判断没有在 visited里面,因为除了 root之外其他结点都没有被 visited过,那么没有的话它就直接调dfs,next_node 就是把最左边结点放进去,再把 visited也一起放进去。
- 递归调用的一个特殊,它不会等这个循环跑完,它就直接推进到下一层了,也就是当前梦境的话这里写了一层循环,但是在第一层循环的时候,我就要开始下钻到新的一层梦境里面去了。
图的遍历顺序
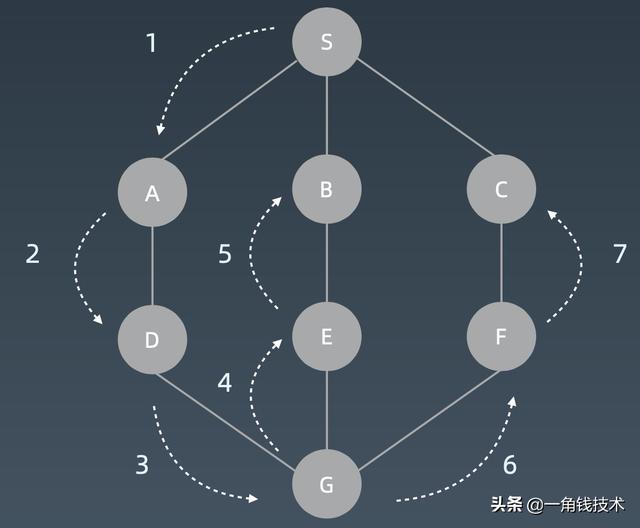
广度优先搜索(BFS)
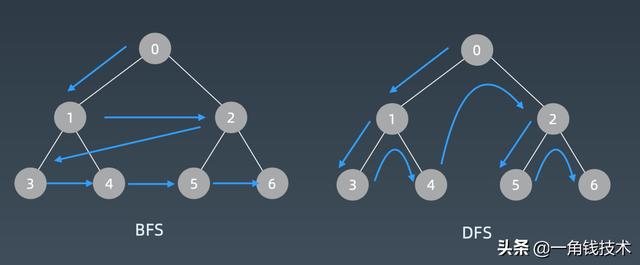
广度优先遍历它就不再是用递归也不再是用栈了,而是用所谓的队列。你可以把它想象成一个水滴,滴到1这个位置,然后它的水波纹一层一层一层扩散出去就行了。
两者对比
BFS代码模板
//Javapublic class TreeNode { int val; TreeNode left; TreeNode right; TreeNode(int x) { val = x; }}public List> levelOrder(TreeNode root) { List> allResults = new ArrayList<>(); if (root == null) { return allResults; } Queue nodes = new LinkedList<>(); nodes.add(root); while (!nodes.isEmpty()) { int size = nodes.size(); List results = new ArrayList<>(); for (int i = 0; i < size; i++) { TreeNode node = nodes.poll(); results.add(node.val); if (node.left != null) { nodes.add(node.left); } if (node.right != null) { nodes.add(node.right); } } allResults.add(results); } return allResults;}# Pythondef BFS(graph, start, end): visited = set() queue = [] queue.append([start]) while queue: node = queue.pop() visited.add(node) process(node) nodes = generate_related_nodes(node) queue.push(nodes) # other processing work ...// C/C++void bfs(Node* root) { map visited; if(!root) return ; queue queueNode; queueNode.push(root); while (!queueNode.empty()) { Node* node = queueNode.top(); queueNode.pop(); if (visited.count(node->val)) continue; visited[node->val] = 1; for (int i = 0; i < node->children.size(); ++i) { queueNode.push(node->children[i]); } } return ;}//JavaScriptconst bfs = (root) => { let result = [], queue = [root] while (queue.length > 0) { let level = [], n = queue.length for (let i = 0; i < n; i++) { let node = queue.pop() level.push(node.val) if (node.left) queue.unshift(node.left) if (node.right) queue.unshift(node.right) } result.push(level) } return result};文章持续更新,可以微信搜一搜「 一角钱技术 」第一时间阅读, 本文 GitHub org_hejianhui/JavaStudy 已经收录,欢迎 Star。


