- 1很薄很经典,这套写给程序员的技术书凭什么销量10万+
- 2Vue根据网络文件路径下载文件【自定义属性 v-down】_vue下载文件存放路径自定义
- 3Java教父Joshua Bloch访谈_josh bloch
- 4python开心消消乐辅助_用Python写个开心消消乐小游戏
- 5达梦数据库工具使用_达梦 truncate和replace
- 6AI编程篇-python高级进阶_ai辅助python编程
- 7如何在Windows环境下安装mysql并且设置自动启动(超详细)_windows设置mysql服务开机自启
- 8YOLOv5-Fog: A Multiobjective Visual DetectionAlgorithm for Fog Driving Scenes Based onImproved YOLOv_yolov5去雾
- 9Flink内核源码(七)Flink SQL提交流程_flinksql提交流程
- 10python一维数组排序_【Python】数组排序
elasticsearch7.x 集群的搭建和分片设置_es集群分片分配和再平衡
赞
踩
目录
一、es集群的基本核心概念
Cluster 集群:
一个 Elasticsearch 集群由一个或多个节点(Node)组成,每个集群都有一个共同的集群名称作为
标识。
Node节点:
一个 Elasticsearch 实例即一个 Node,一台机器可以有多个实例,正常使用下每个实例应该
会部署在不同的机器上。Elasticsearch 的配置⽂件中可以通过 node.master、node.data 来
设置节点类型。
node.master:表示节点是否具有成为主节点的资格
true代表的是有资格竞选主节点
false代表的是没有资格竞选主节点
node.data:表示节点是否存储数据
Node节点组合:
主节点+数据节点(master+data)
节点即有成为主节点的资格,又存储数据
node.master: true
node.data: true
数据节点(data):
节点没有成为主节点的资格,不参与选举,只会存储数据
node.master: false
node.data: true
客户端节点(client)
不会成为主节点,也不会存储数据,主要是针对海量请求的时候可以进行负载均衡
node.master: false
node.data: false
分片:
每个索引有一个或多个分片,每个分片存储不同的数据。分片可分为主分片( primary
shard)和复制分片(replica shard),复制分片是主分片的拷贝。默认每个主分片有一个复
制分片,一个索引的复制分片的数量可以动态地调整,复制分片从不与它的主分片在同一个
节点上。
二、es集群搭建
步骤:
拷贝elasticsearch-7.2.0安装包3份,分别命名elasticsearch-7.2.0-a, elasticsearch-7.2.0-b,
elasticsearch-7.2.0-c。
分别修改elasticsearch.yml文件。groupadd esgroup #只需要执行一次
useradd esuser -g esgroup #只需要执行一次
chown -R esuser:esgroup /usr/local/software/elasticsearch-7.2.0-a #三个目录都需要执行
su esuser 再分别进入bin文件夹下启动a,b,c三个节点
打开浏览器输入:http://localhost:9200/_cat/health?v ,如果返回的node.total是3,代表集
群搭建成功
a节点配置更改:
#集群名称
cluster.name: my-application
#节点名称
node.name: node-1
#是不是有资格主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#网关地址
network.host: 0.0.0.0
#端口
http.port: 9200
#内部节点之间沟通端口
transport.tcp.port: 9300
#es7.x 之后新增的配置,写⼊候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["localhost:9300","localhost:9400","localhost:9500"]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
b节点更改:
#节点名称
node.name: node-2#端口
http.port: 9201
#内部节点之间沟通端口
transport.tcp.port: 9400
c节点更改:
#节点名称
node.name: node-3#端口
http.port: 9202
#内部节点之间沟通端口
transport.tcp.port: 9500
kibana安装步骤
1.下载
https://www.elastic.co/cn/downloads/kibana
选择对应版本
2.启动
kibana-7.2.0-linux-x86_64.tar.gz 解压后,更改下配置文件
打开配置 kibana.yml,添加elasticsearch.hosts: ["http://localhost:9200","http://localhost:
9201","http://localhost:9202"]
sh ./kibana --allow-root
通过kibana查看
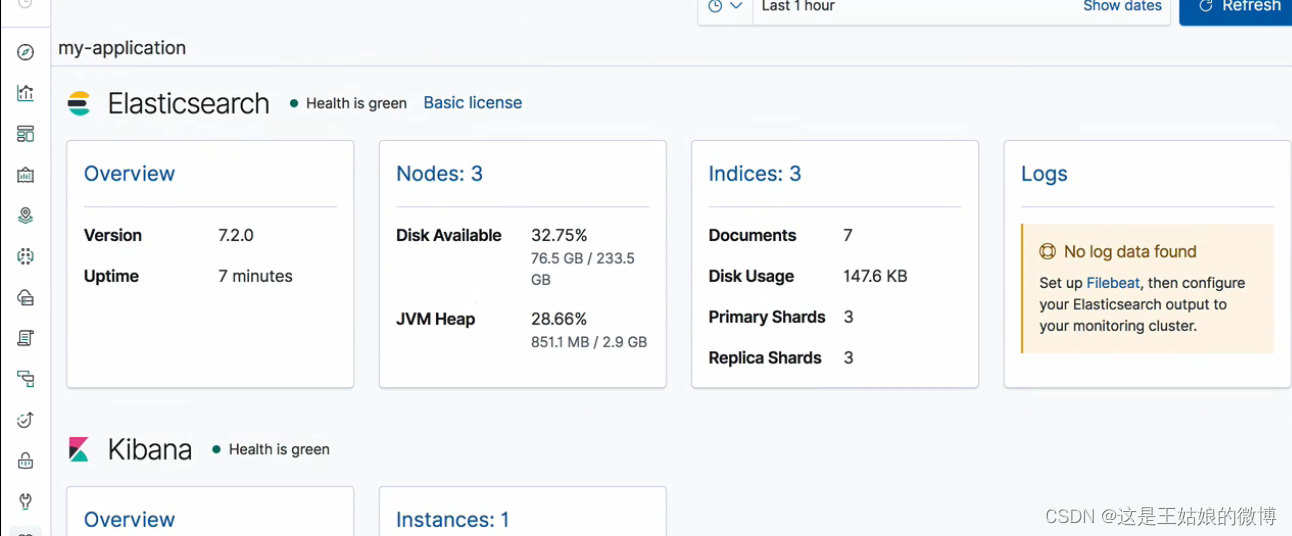
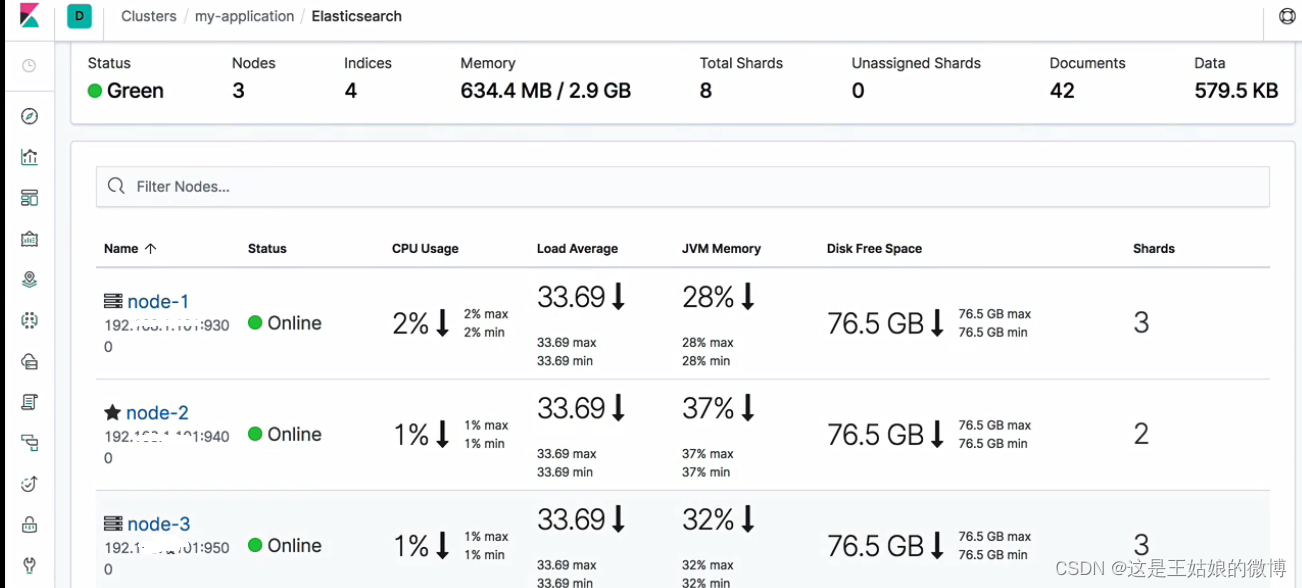
集群搭建成功~
三、es集群索引分片管理
分片(shard):因为ES是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 这些分布在
不同节点的数据就是分片. ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分
配, 所以用户基本上不用担心分片的处理细节。
副本(replica):ES默认为一个索引创建1个主分片, 并分别为其创建一个副本分片.
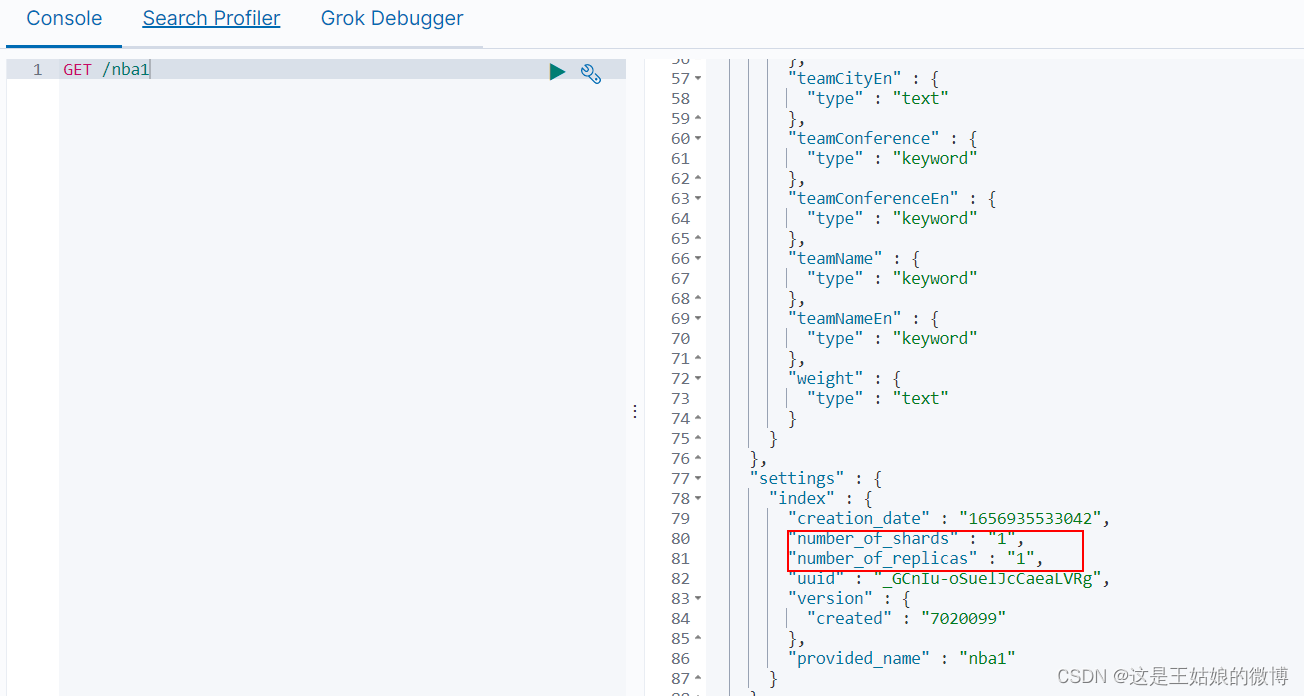
Elastic search7.x之后,如果不指定索引分片,默认会创建1个主分片和一个副分片,而7.x版
本之前的比如6.x版本,默认是5个主分片
3.1创建索引,指定分片
创建索引,不指定分片
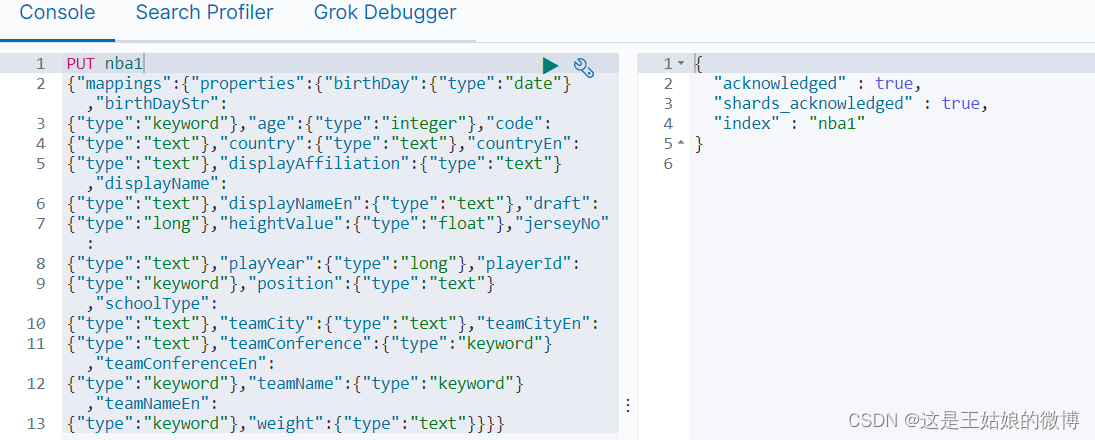
默认是一个分片
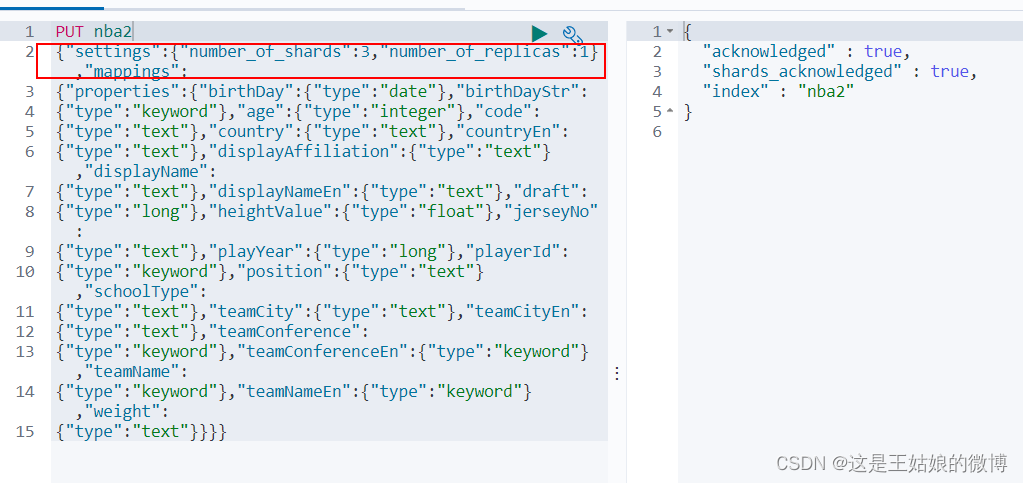
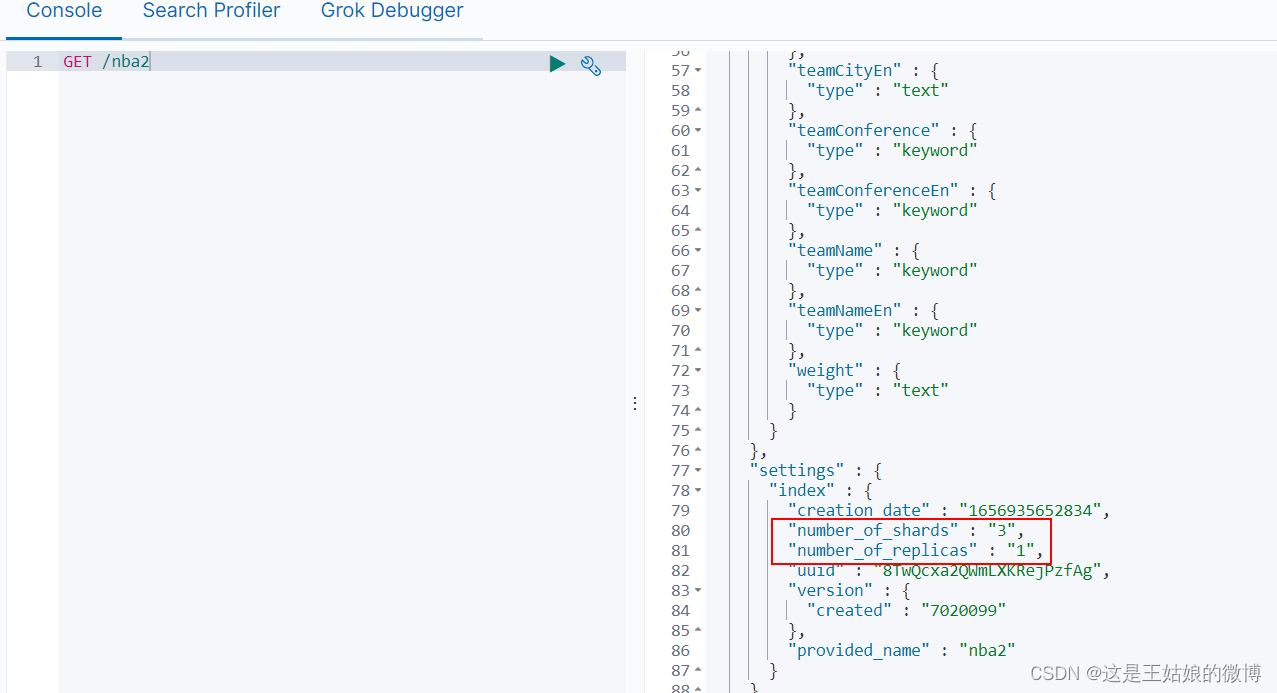
指定分区数量
"settings": { "number_of_shards": 3, "number_of_replicas": 1 },
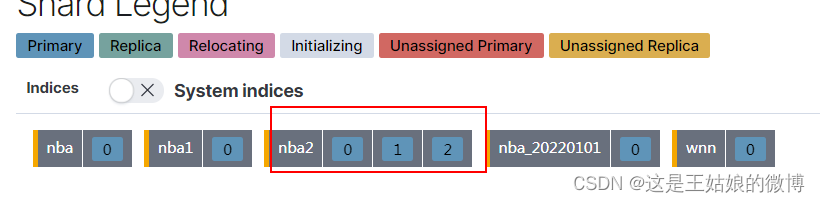
3.2索引分片的分配
分片分配到哪个节点是由ES自动管理的,如果某个节点挂了,那分片会重新分配到别的节
点上。
在单机中,节点没有副分片,因为只有一个节点没必要生成副分片,一个节点挂点,副分片
也会挂掉,完全是单故障,没有存在的意义。
在集群中,同个分片它的主分片不会和它的副分片在同一个节点上,因为主分片和副分片在
同个节点,节点挂了,副分片和主分机一样是挂了,不要把所有的鸡蛋都放在同个篮子里。
可以手动移动分片,比如把某个分片移动从节点1移动到节点2。
创建索引时指定的主分片数以后是无法修改的,所以主分片数的数量要根据项目决定,如果
真的要增加主分片只能重建索引了。副分片数以后是可以修改的
3.2.1 手动移动分片:
移动之前
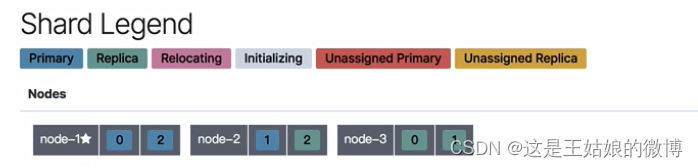
POST /_cluster/reroute { "commands": [ { "move": { "index": "nba", "shard": 2, "from_node": "node-1", "to_node": "node-3" } } ] }
把nba这个索引的第二个分片,从node-1服务中移动到node-2服务中
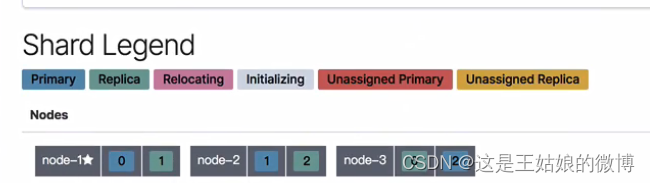
3.2.1 修改副分片数量
PUT /nba/_settings { "number_of_replicas": 2 }
更改之后,三个主分片 * 2 副本