
- 1linux(euler) 重启网络服务后路由表丢失问题的解决方案_欧拉系统无法添加路由
- 2Verilog 顺序块、并行块,阻塞过程赋值、非阻塞过程赋值的区别_顺序块和并行块的区别
- 3Java8新特性--StreamAPI_java8 stream api
- 4云计算时代的运维职位展望
- 5Java栈_java 栈
- 6笔记连载 | Day6 FPGA三种建模方式区别及Verilog语法基础篇_fpga的建模方式
- 7Windows cmake-gui 添加c++ 11 c++ 14 c++ 17_cmake 指定c++14
- 8漫谈JVM热加载技术(一)---目前常见的解决方案
- 9go实践十 爬虫抓取网页数据_htmlquery.findone 获取 text
- 10【Linux】项目自动化构建工具——make/Makefile及拓展_linux makefile编译并安装新app
Flink内核源码(七)Flink SQL提交流程_flinksql提交流程
赞
踩
第七章就来学习一下Flink SQL的解析提交流程。
问题整理:
1. Flink中的Calcite是什么?
2. Flink SQL的提交流程是怎样的?
1. Calcite
Apache Calcite是一个动态数据管理框架 ,它具备很多典型数据库管理系统的功能,如SQL解析、SQL校验、SQL查询优化等,又省略了一些功能,如不存储相关数据,也不完全包含相关处理数据等。
Flink中的sql解析、sql校验和sql优化便是依赖calcite来完成的。
梳理一下Calcite SQL执行的几个阶段:

- 通过Parser解析器将传入的sql解析成一颗词法树,SqlNode作为树的节点
- 做词法的校验Validate,类型校验,元数据校验等等
- 将校验好的SqlNode树转换成对应的关系代数表达式,也是一颗树,RelNode作为节点
- 将RelNode关系代数表达式树,通过内置的两种优化器Volcano , Hep 优化关系代数表达式得到最优逻辑代数的一颗树,也是RelNode
- 最优的逻辑代数表达式(RelNode),会被转换成对应的可执行的物理执行计划(转换逻辑根据框架有所不同),像Flink就转成他的Operator去运行
2. Flink SQL 提交流程
先整体对Flink SQL 提交流程进行一个描述,再从源码角度进行详细解释。

总共包括两大阶段:
1. sql到operation的转换
-
SQL解析:调用parser方法,将SQL转为未经校验的AST抽象语法树,也就是SqlNode,它主要会用到词法解析和语法解析。词法解析就是将Sql语句转为一组token,而语法解析就是将token进行递归下降词法分析
-
SQL校验:就是将未经校验的抽象语法树校验成已经校验的抽象语法树,在校验阶段主要校验两部分:1)校验表名,字段名,函数名是否正确 2)校验特殊的类型是否正确,如join操作,groupby是否有嵌套等
-
调用rel()方法:将抽象语法树SqlNode转为关系代数树RelNode(关系代数表达式)和RexNode行表达式,在这个过程中,DDL它是不执行rel()方法的,因为DDL实际是对元素区的修改,不涉及复杂查询
-
调用convert()方法:最终会将RelNode转化为operation,operation它包括多种类型,但最终都会生成根节点modify operation
2. operation到transformations的转换
- 将modify operation最终转换成calcite的逻辑计划树(calcite logicalPlan),其次,将calcite logicalPlan转为flink的逻辑计划树(Flink LogicalRel)
- 调用optimize()方法,将Flink LogicalRel优化成物理计划FlinkPhysicalRel,包括两大优化规则:基于规则优化RBO和基于代价优化CBO
- 调用translateToExecNodeGraph方法,该方法是将物理计划转化为ExecGraph
- 调用translateToPlan()方法,会将最终的ExecGraph转化为transformations
3. 源码解析
3.1 Sql语句解析成语法树阶段(SQL - > SqlNode)
TableEnvironmentImpl是sql执行的入口类,TableEnvironmentImpl中提供了executeSql,sqlQuery等方法用来执行DDL和DML等sql,sql执行时会对sql进行解析,ParserImpl是flink调用sql解析的实现类,ParserImpl#parse()方法中通过调用包装器对象CalciteParser#parse()方法并创建并调用使用javacc生成的sql解析器(FlinkSqlParserImpl)中的parseSqlStmtEof方法完成sql解析,并返回SqlNode对象

核心代码:
public List<Operation> parse(String statement) {
CalciteParser parser = calciteParserSupplier.get();
FlinkPlannerImpl planner = validatorSupplier.get();
//TODO 在这里调用使用javacc生成的分析器,将sql语句解析成sqlNode
SqlNode parsed = parser.parse(statement);
//TODO 将sqlNode转换为Operation
Operation operation = SqlToOperationConverter.convert(planner, catalogManager, parsed)
.orElseThrow(() -> new TableException("Unsupported query: " + statement));
return Collections.singletonList(operation);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
其中parser.parse(…)方法,将sql语句解析成sqlNode。对应的表名、列名、with属性参数、主键、唯一键、分区键、水印、表注释、表操作(create table、alter table、drop table)都放到SqlNode对象的对应属性中,SqlNode是一个树形结构也就是AST。
3.2 Sql校验(SqlNode - > Operation)
sql解析完成后执行sql校验,flink sql中增加了SqlNode转换为Operation的过程,sql校验是在这个过程中完成。在SqlToOperationConverter#convert()方法中完成这个过程的转换,之间会通过FlinkPlannerInpm#validate()方法对表、函数、字段等完成校验并基于生成的validated SqlNode生成对应的Opeation。

不同的sql经过convert处理后返回不同的Operation,最后会根据不同的Operation有不同的处理行为。
3.3 Flink SQL优化(Operation - > RelNode->Transformation )
Blink中并没有直接使用Calcite的优化器,而是通过规则组合和Calcite优化组合分别为batch和stream实现了自定义的优化器。
优化执行前会先将SqlNode转为RelNode,基于RelNode调用PlannerBase#optimize()并执行StreamCommonSubGraphBasedOptimizer#doOptimize()方法完成优化
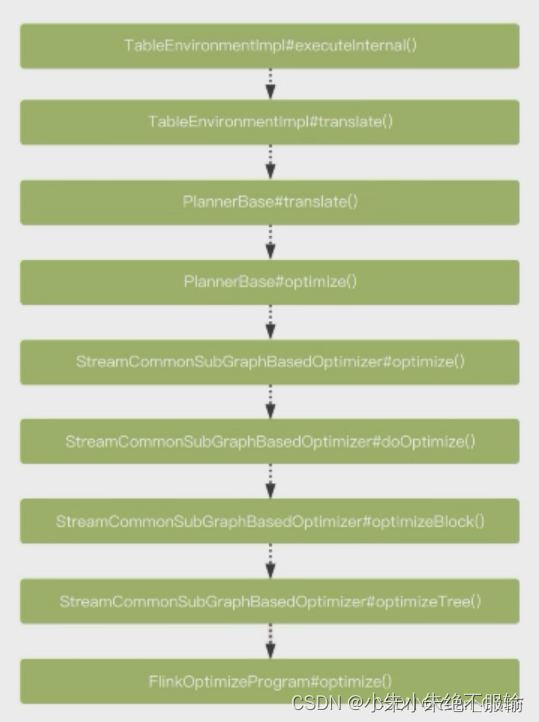
在完成Sql到RelNode的转换后,会执行executeOperation(…)操作,在这里先将sqlNode转换成RelNode。然后进行优化操作。
然后根据传入的sql语句类型,选择不同的操作。包含有Modify、CreateTable、DropTable等。
在这里,有进行转换和优化操作,重点是在translate方法中,最终调用的是PlannerBase里的translate(...)方法
override def translate(
modifyOperations: util.List[ModifyOperation]): util.List[Transformation[_]] = {
if (modifyOperations.isEmpty) {
return List.empty[Transformation[_]]
}
// prepare the execEnv before translating
getExecEnv.configure(
getTableConfig.getConfiguration,
Thread.currentThread().getContextClassLoader)
overrideEnvParallelism()
// TODO 在这里完成转换 SqlNode转换为RelNode
val relNodes = modifyOperations.map(translateToRel)
// TODO 在这里完成优化
val optimizedRelNodes = optimize(relNodes)
val execNodes = translateToExecNodePlan(optimizedRelNodes)
translateToPlan(execNodes)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
最终由translateToPlan方法将ExecNode转换成Transfomation列表
基于生成的Transformation对象调用StreamExecutor#createPipeline()方法生成StreamGraph便可以执行任务了。
参考:

