- 1计算机操作系统原理复习笔记——考试版_计算机系统原理笔记
- 2Xcode13.3.1 upload ipa error:Invalid Provisioning Signature....STATE_ERROR.VALIDATION_ERROR.9016解决方案_xcode 13.3 1
- 3国产游戏引擎,竟然用来搞民航_腾讯的国产渲染引擎
- 4【STM32+HAL】语音识别模块LD3320(SPI版)_ld3320 spi版本
- 5小程序https启用tls1.2
- 6Import Error: Bad git executable._importerror: bad git executable.
- 7python 接口测试_python接口测试
- 8Python操作spark_pip install sparkapi
- 9java json 嵌套list_java-嵌套JSON的POJO格式?
- 10Java 老矣,尚能饭否?
Hadoop知识点
赞
踩
Hadoop是什么呢?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,它允许用户在不需要深入了解分布式底层细节的情况下,开发分布式程序,并充分利用集群的威力进行高速运算和存储。Hadoop的核心设计主要包括分布式文件系统(HDFS)和MapReduce编程模型。
HDFS是Hadoop的分布式文件系统,具有高容错性,并设计用来部署在低廉的硬件上。它提供高吞吐量来访问应用程序的数据,特别适合处理超大数据集。HDFS放宽了POSIX的要求,能以流的形式访问文件系统中的数据。
MapReduce是Hadoop的编程模型,它使得分布式计算变得简单和高效。开发人员只需编写Map函数和Reduce函数,Hadoop就能自动在集群中并行执行任务,处理大规模数据集。
Hadoop的主要特点包括可靠性、可扩展性、高性能、易用性、开源性和支持多种数据类型。其数据可靠性和可扩展性是传统文件系统无法比拟的,因此被许多大型企业和组织用于大数据存储和处理。
此外,Hadoop还广泛应用于数据处理和分析、数据挖掘和机器学习、日志分析、图像和音频处理等领域。例如,企业可以使用Hadoop的MapReduce框架处理和分析数据,发现数据中的模式和趋势,从而作出更好的业务决策;还可以使用Hadoop的机器学习库Mahout在大规模数据集上训练机器学习模型,进行客户行为分析、欺诈识别或风险评估等任务。
然而,随着技术的不断进步和业务需求的日益复杂,Hadoop也面临着新的挑战和机遇。为了满足日益增长的实时数据处理需求,Hadoop社区已经推出了一系列相关项目,如Apache Flink和Apache Spark,以弥补Hadoop在实时性方面的不足。
总的来说,Hadoop是一个功能强大且灵活的大数据处理框架,它正在不断地发展和完善,以适应日益复杂的数据处理需求。
1.Hadoop集群的搭建和配置
要完成Hadoop集群的搭建和配置首先要在个人计算机上安装配置虚拟机,然后在虚拟机中搭建Hadoop完全分布式集群。
个人计算机硬件的最低配置建议Hadoop相关软件安装包及其版本说明:
| 软 件 | 版 本 | 安 装 包 名 称 | 备注 |
|---|---|---|---|
| Linux OS | CentOS 7.8 | CentOS-7-x86_64-DVD-2003.iso | 64位 |
| JDK | 1.8+ | jdk-8u281-linux-x64.rpm | 64位 |
| VMware | 15 | VMware-workstation-full-15.5.7-17171714.exe | 虚拟机软件 |
| Hadoop | 3.1.4 | hadoop-3.1.4.tar.gz | 已编译好的安装包 |
| IDEA | 2018.3.6 | ideaIC-2018.3.6.exe | 64位 |
| SH连接工具 | 5 | Xme5.exe | 远程连接虚拟机 |
Hadoop完全分布式集群是主从架构,一般需要使用多台服务器组建。
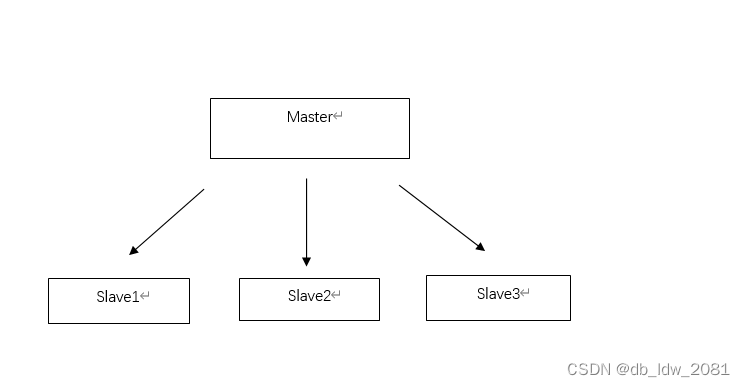
我们可以通过课程或者网络上的教程来创建虚拟机,然后再设置固定IP,然后用Xmanager(Xmanager是应用于Windows系统的Xserver服务器软件,通过Xmanager用户可以将远程的Linux桌面无缝导入至Windows系统中)远程连接虚拟机,配置本地YUM源及安装常用软件,在Linux虚拟机下安装Java,修改配置文件。
克隆虚拟机:在虚拟机master上配置完成Hadoop集群相关配置后,将虚拟机master克隆,生成3个新的虚拟机slave1、slave2、slave3,在虚拟机master的安装目录“E:\Vmware”下建立3个文件slave1、slave2、slave3。在master、slave1、slave2、slave3中配置SSH免密码登录,进行Hadoop集群配置时间同步服务。
启动关闭集群:完成Hadoop的所有配置后,即可执行格式化NameNode操作,该操作会在NameNode所在机器节点中初始化一些HDFS的相关配置,并且该操作在集群搭建过程中只需执行一次,执行格式化之前可以先配置环境变量,配置环境变量是在master、slave1、slave2、slave3节点上修改/etc/profile文件,文件修改完保存退出,使用“source /etc/profile”命令使配置生效。
监控集群:Hadoop集群有相关的服务监控端口
| 服务 | Web接口 | 默认端口 |
|---|---|---|
| NameNode | http://namenode_host:port/ | 9870 |
| ResourceManager | http://resourcemanager_host:port/ | 8088 |
| MapReduce JobHistoryServe | http://jobhistoryserver_host:port/ | 19888 |
(1)查看HDFS文件信息
依次选择“Utilities”→“Browse the file system”命令可以查看HDFS上的文件信息。
(2) YARN监控
在浏览器的地址栏中输入“http://master:8088”网址,即可看到YARN的监控界面。
(3)日志监控
在浏览器的地址栏中输入“http://master:19888 ”地址,即可看到Hadoop的日志监控界面。
2.HDFS分布式文件系统
查看、解除与开启Hadoop安全模式
1. 查看安全模式
当启动Hadoop集群时,首先会进入安全模式,主要是为了检查系统中DataNode节点上的数据块数量和有效性。在Linux系统上启动Hadoop集群,启动完成后可以在本机的浏览器输入“http://master:9870”网址,查看HDFS的监控服务。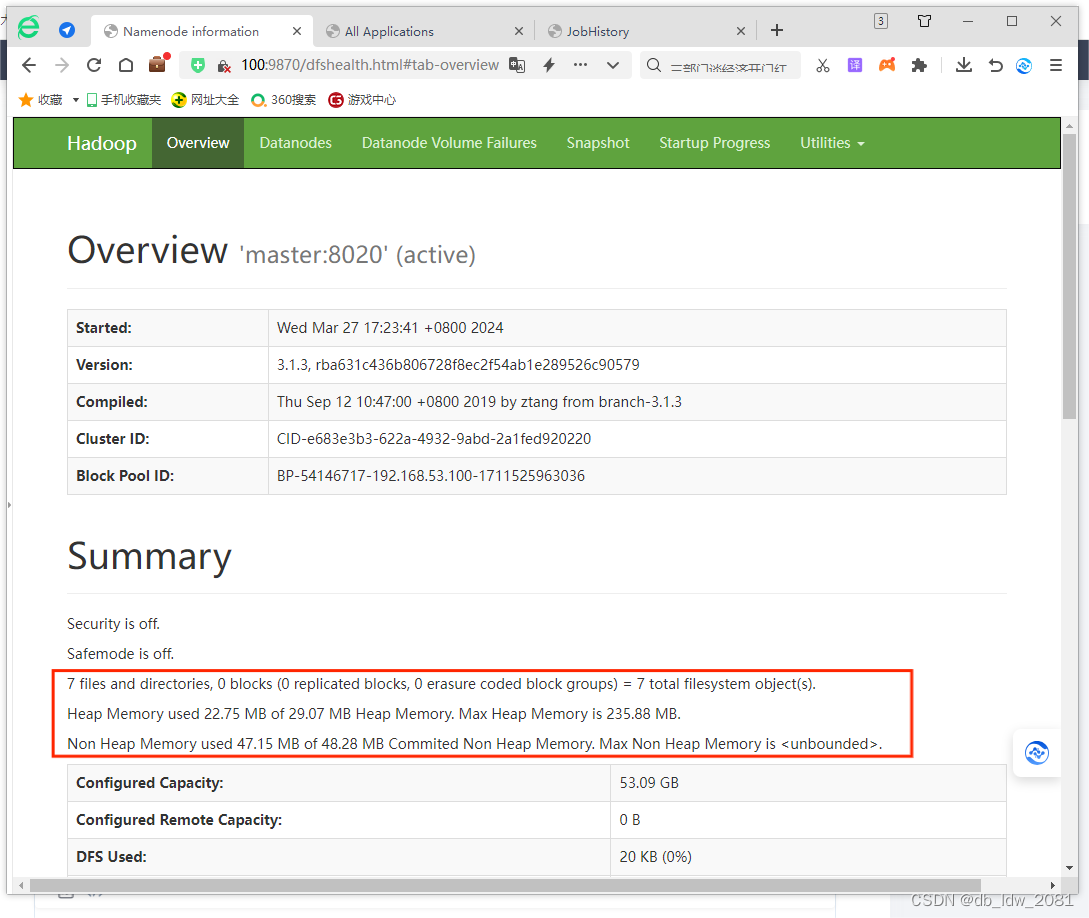
2. 解除和开启安全模式
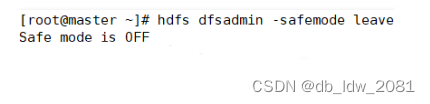
当启动Hadoop集群时集群会开启安全模式,原因是DataNode的数据块数没有达到总块数的阈值。如果没有先关闭Hadoop集群时,而直接关闭了虚拟机,那么Hadoop集群也会进入安全模式,保护系统。当再次开启Hadoop集群时,系统会一直处于安全模式不会自动解除,这时使用“hdfs dfsadmin -safemode leave”令可以解除安全模式。
查看Hadoop集群的基本信息
查询集群的存储系统信息
当HDFS文件系统完成启动时,在服务器集群上也将启动相关的监控服务。通过这些监控服务,即可查询到大量相与HDFS文件系统相关的信息。HDFS的监控服务默认是通过NameNode节点的9870端口进行访问。 在本机浏览器的地址栏输入“http://master:9870”网址,查看当前HDFS文件系统的基本统计信息。
继续单击页面中的“Datanodes”标签栏,可以显示出各数据节点的信息。在图中显示了组成HDFS的3个Datanode节点的状态与各自的存储使用情况。在HDFS中,数据是被分块进行存储的,每个数据块默认有3个副本,即每个数据节点上存储一份数据副本,因此各节点的存储用量是大致相等的。
Hadoop也提供了命令行查询HDFS文件系统资源信息的方式,即hdfs dfsadmin -report命令,该命令的基本语法格式如下。
hdfs dfsadmin -report [-live] [-dead] [-decommissioning]查询集群的计算资源信息
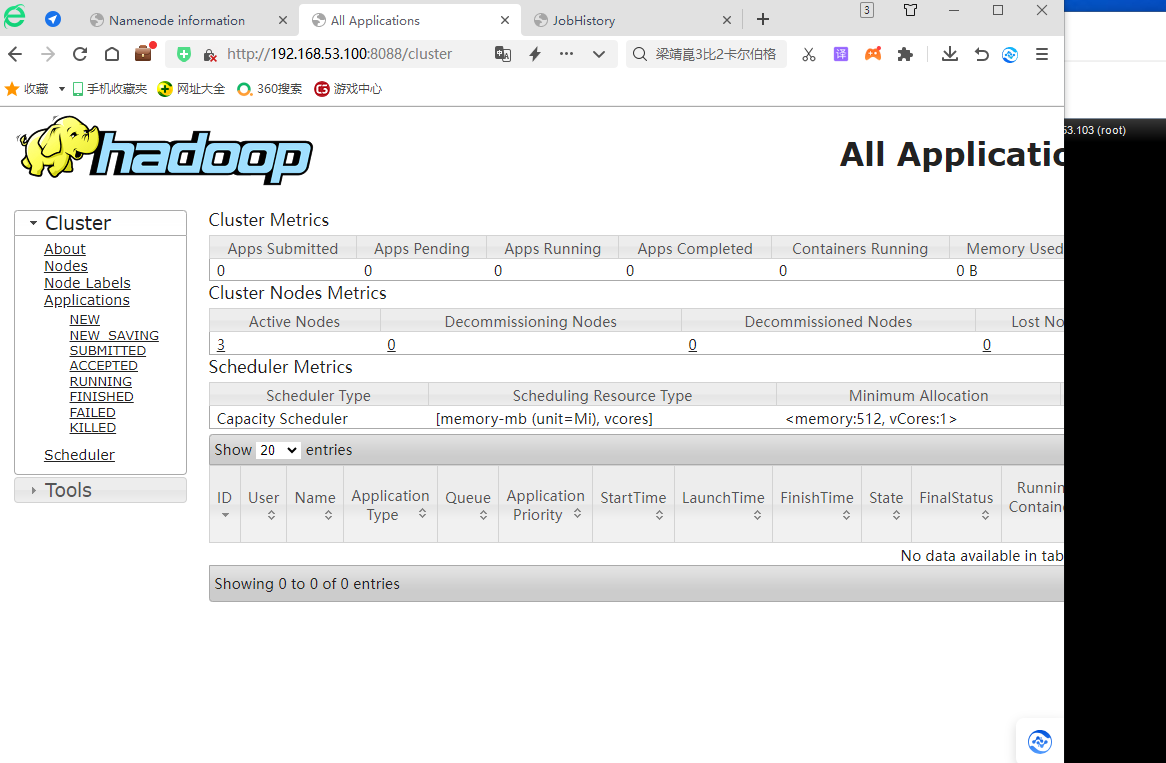
Hadoop集群的计算资源,是由YARN资源管理器的ResourceManager进行管理的。通过ResourceManager的监控服务,可以方便地查询目前集群上的计算资源信息。 在本机浏览器的地址栏输入“http://master:8088/cluster/nodes”网址,查看当前集群的计算资源信息。