
- 1大模型LLM(2):开源 LLMOps平台dify。_llmops开源平台
- 2【linux 使用ollama部署运行本地大模型完整的教程,openai接口, llama2例子】_ollama linux
- 3Monkey测试:Monkey的简单使用
- 4Java核心技术 卷1_斯维斯方法有两个参数 分别是什么类型的类型和什么类型的对象
- 5使用vscode调试带-m参数的python代码_vscode -m
- 6Hbase的安装与配置_hbase配置
- 7Java入门基础教程-字面量、变量、关键字与标识符
- 8AIGC行业现状和未来发展趋势
- 9Java编程学习入门、Java语言学习、Java入门必看
- 10【GitHub项目推荐--开箱即用的直播聊天系统,高颜值,支持二次开发】【转载】_开源直播平台 github
大数据知识框架(1),2024年最新零基础大数据开发开发_大数据基本框架
赞
踩
数仓分层(分层是站在数仓全集的视角,对于一系列的计算过程抽象出通用的职责,规定每一层只做某些职责,每一层有自己独特的命名,并且不同层之间有明确的前后关系。):
- 维护成本降低。试想一个上千行的代码从头一点点理解,有问题需要修改时的维护成本是相当高的,而且很容易出错。
- 隔离变化。试想一下,如果某天需要更换数据源A为C,只需要修改任务1的代码即可,对下游的可以做到屏蔽变化,无感知。
- 增加了复用性,进而带来一致性的提升和开发效率的提升。
- 持久化可以用空间换时间,节省计算资源。
- 提升数据安全
- 统一建设思路
- 血缘清晰
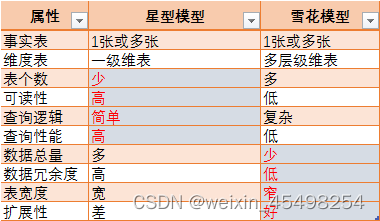
雪花模型和星型模型的区别
数据湖:iceberg、hudi
二、数据治理
数仓的目标:效率高、质量好、成本低、有价值。
计算优化
离线计算
存储优化
指标管理
三、具体技术原理及常见问题
mysql:
离线-MAPREDUCE:
Hadoop MapReduce介绍、官方示例及执行流程 - 知乎
离线-SPARK:
Spark SQL 任务执行过程
Spark 完成一个数据生产任务(执行一条 SQL )的基本过程如下:
(1)对SQL进行语法分析,生成逻辑执行计划。
(2)从 Hive metastore server 获取表信息,结合逻辑执行计划生成并优化物理执行计划。
(3)根据物理执行计划向 Yarn 申请资源(executor),调度 task 到 executor 执行。
(4)从 HDFS 读取数据,任务执行,任务执行结束后将数据写回 HDFS。
RDD、宽窄依赖
如上图表示方框表示RDD,实心矩形表示分区(partitions)
1,窄依赖表示的是子RDD的分区只是到父RDD的分区(一对一)
2,宽依赖表示的是子RDD的分区到父RDD的多个分区(多对多),就会产生shuffer操作
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

续会持续更新**
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-bdC3SnRr-1712574896375)]

