
KGE-CL/ Contrastive Learning of Knowledge Graph Embeddings 阅读笔记_contrastive object detection using knowledge graph
赞
踩
作者在知识图谱嵌入任务中,针对于不同三元组中相关实体和实体-关系对间的语义相似性的问题,提出一个对于知识图谱嵌入简单且高效的对比学习框架,使用该框架作为一个额外的约束项一同训练KGE,这可以使不同三元组中相关实体和实体-关系对间的语义距离变小,因此可以提升知识图谱嵌入的表现。
0. 前言
Topic
data mine; topic mine;
problems in previous work
- 大多数以前的知识图谱嵌入模型忽略不同三元组中相关实体和实体-关系对间的语义相似性。
motivation
challenge
1. 作者试图解决什么问题?
提出一个对于知识图谱嵌入简单且高效的对比学习框架,这可以使不同三元组中相关实体和实体-关系对间的语义距离变小,因此可以提升知识图谱嵌入的表现。
2. 这篇论文的关键元素是什么?
contrastive learning;Knowledge graph embedding;
3. 论文中有什内容可以“为你所用”?
- 作者中使用对比学习方法额外在损失函数上加约束的方式可以借鉴。
4.有哪些参考文献你想继续研究?
5. 还存在什么问题
- 相当于在原有的KGE基础上,附加了一个约束;
- 使用对比学习的方式,似乎需要大量的数据预处理工作(寻找正实例对,和负实例对);
0.1 待学习知识
- Contrastive Learning
1 背景知识
Contrastive Learning
The key idea of contrastive learning is pulling the semantically close pairs together and push apart the negative pairs.
2 模型

正样例选择
- 对于一个头实体来说,具有相同关系和尾实体的头实体;尾实体相似。
- 对一个实体-关系对来说,具有相同另一个实体的 实体-关系对;
编码器
采用一个2层的MLP
对比损失
根据以前存在的框架,使用以下函数:
C
L
(
z
i
,
z
i
+
)
=
−
1
∣
P
(
i
)
∣
log
∑
z
i
+
∈
P
(
i
)
e
sim
(
z
i
,
z
i
+
)
/
τ
∑
z
j
∈
N
(
i
)
e
sim
(
z
i
,
z
j
)
/
τ
\mathrm{CL}\left(\mathbf{z}_{i}, \mathbf{z}_{i}^{+}\right)=\frac{-1}{|P(i)|} \log \frac{\sum_{z_{i}^{+} \in P(i)} e^{\operatorname{sim}\left(\mathbf{z}_{i}, \mathbf{z}_{i}^{+}\right) / \tau}}{\sum_{z_{j} \in N(i)} e^{\operatorname{sim}\left(\mathbf{z}_{i}, \mathbf{z}_{j}\right) / \tau}}
CL(zi,zi+)=∣P(i)∣−1log∑zj∈N(i)esim(zi,zj)/τ∑zi+∈P(i)esim(zi,zi+)/τ
- 其中,一个实例 z i z_{i} zi和它的所有正样例 z i + z_{i}^{+} zi+,黑体为其表示向量。sim是余弦相似度,P(i) 是 minibatch 中所有正例的集合,N(i) 是 batch 中所有负例的集合。
总损失函数为:
L
c
(
h
i
,
r
j
,
t
k
)
=
C
L
(
h
i
,
h
i
+
)
+
C
L
(
t
k
,
t
k
+
)
+
C
L
(
h
i
R
j
,
(
h
i
R
j
)
+
)
+
C
L
(
R
j
t
‾
k
,
(
R
j
t
‾
k
)
+
)
损失求导
h
i
t
+
1
=
h
i
t
−
η
∂
C
L
(
h
i
,
h
i
+
)
∂
h
i
=
h
i
t
+
η
∑
h
i
+
∈
P
(
i
)
h
i
+
τ
∣
P
(
i
)
∣
−
η
∑
h
j
∈
N
(
i
)
(
e
(
h
i
⋅
h
j
/
τ
)
h
j
)
τ
∣
P
(
i
)
∣
∑
h
j
∈
N
(
i
)
e
(
h
i
⋅
h
j
/
τ
)
- 通过求导后梯度下降的方向,可以看到,实例的优化方向和向所有正实例的方式一致,远离负样例的方向;
加权对比损失
作者发现不同的对比损失项对于不同的知识图谱有着不同的影响,所以作者设计一个超参数进行调整:
L
c
w
(
h
i
,
r
j
,
t
k
)
=
α
h
C
L
(
h
i
,
h
i
+
)
+
α
t
C
L
(
t
k
,
t
k
+
)
+
α
h
r
C
L
(
h
i
R
j
,
(
h
i
R
j
)
+
)
+
α
t
r
C
L
(
R
j
t
‾
k
,
(
R
j
t
‾
k
)
+
)
训练目标
L ( h i , r j , t k ) = L s + L r + L c w \mathcal{L}\left(h_{i}, r_{j}, t_{k}\right)=\mathcal{L}_{s}+\mathcal{L}_{r}+\mathcal{L}_{c}^{w} L(hi,rj,tk)=Ls+Lr+Lcw
- 其中 L s \mathcal{L}_{s} Ls衡量评分函数输出 f ( h i , r j , t k ) f\left(h_{i}, r_{j}, t_{k}\right) f(hi,rj,tk)和标签 X i j k X_{ijk} Xijk 之间差异的损失.(也就是原本的KGE损失函数,此处作者用的是full multiclass log-loss), L r \mathcal{L}_{r} Lr是正则项。
3 实验
常规实验结果,效果不错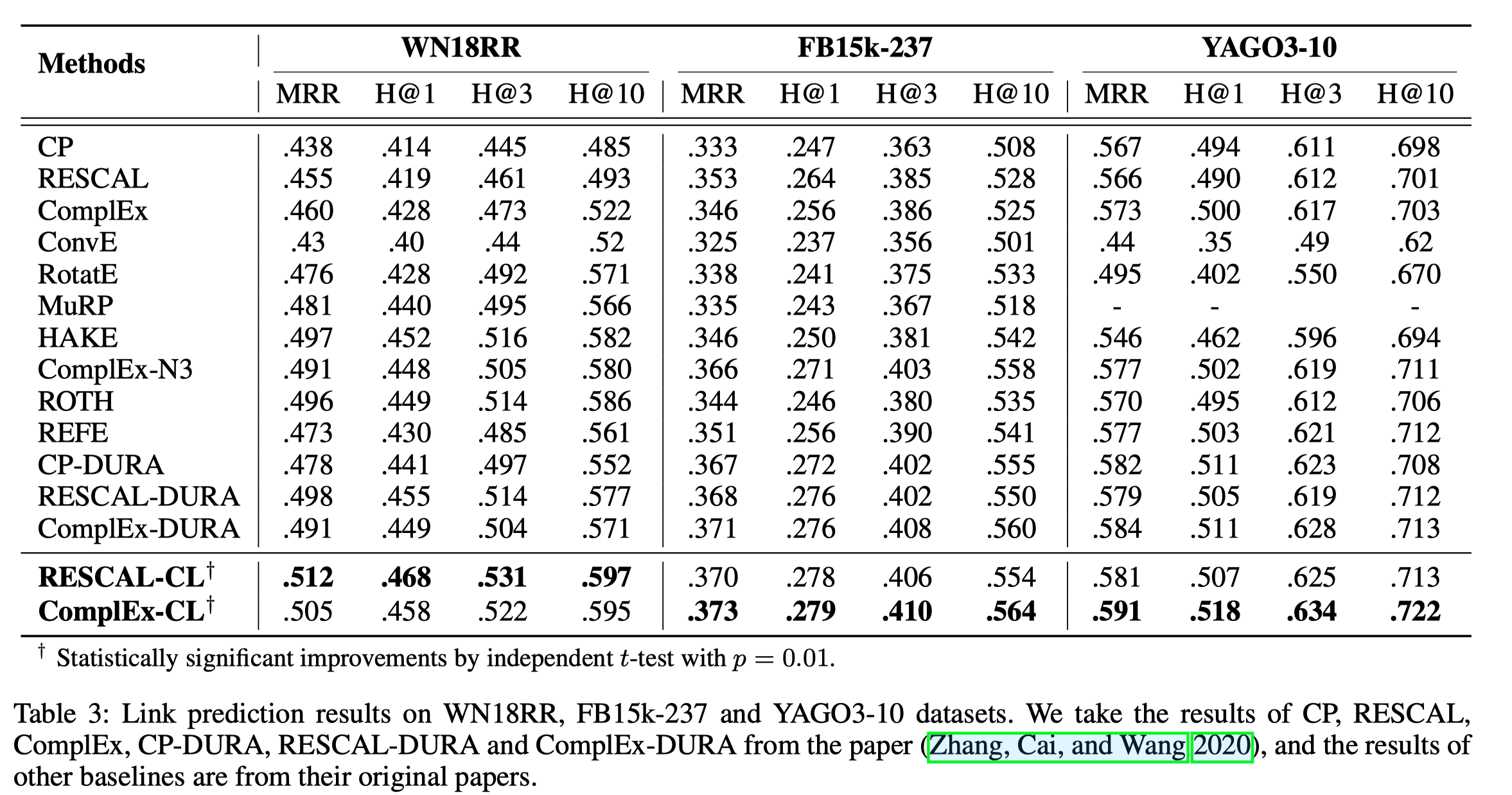
作者还展示了RESCAL-DURA和自己提出的方法RESCAL-CL在WN18RR上每种关系的效果对比,展示了其模型效果的普遍性。
作者还额外的提供了T-SNE的可视化展示:
其中,可以看到由于 RESCAL-DURA 无法捕获具有相同实体的对的语义相似性,因此具有相同尾部实体的对的分布仍然很宽。而作者的RESCAL-CL分布更为紧凑。

