- 1用evo工具评估SLAM轨迹_slam估计轨迹怎么得到
- 2第7章 Python字符串处理_使用单引号定义 1 个字符串变量,使得 print 输出后的结果对齐
- 3软考中级信息系统监理师(第二版)-第4章信息资源系统_信息系统监理师第二版教程电子版
- 4mysql connector c++ 使用_MySQL Connector/C++ 使用 | 学步园
- 5大数据从入门到实战——Hive综合应用案例 ——学生成绩查询_第1关:计算每个班的语文总成绩和数学总成绩
- 6android 后台运行服务之创建后台服务篇_编制一个在安卓手机后台运行的程序
- 7快速上手Python数据分析——Matplotlib要点总结
- 8编写一个录音软件,使用AudioRecorder录制音频,并使用MediaCodeC编码(aac格式),编码封装成mp4文件,保存到对应目录_mediacodec 保存mp4
- 9智谱AI大模型ChatGLM3-6B更新,快來部署体验_智谱 ai 开源
- 10vmware安装龙蜥操作系统
CVPR2024 | 改善多模态大模型底层视觉能力,NTU与商汤联合提出Q-Instruct,已开源_cvpr2024 多模态
赞
踩

https://arxiv.org/pdf/2311.06783.pdf
https://github.com/Q-Future/Q-Instruct
以 GPT-4V 为代表的多模态大语言模型(MLLM)为视觉感知和理解任务引入了范式转变,即可以在一个基础模型中实现多种能力。虽然当前的 MLLM 表现出了从低级视觉属性(例如清晰度、亮度)识别到图像质量评估的初级低级视觉能力,但仍然有必要进一步提高 MLLM 的准确性,以大幅减轻人类负担。
-
为了解决这个问题,我们收集了第一个数据集,其中包含对低级视觉的人类自然语言反馈,每个反馈都提供了图像低级视觉属性的全面描述,最终形成整体质量评估。构建的 Q-Pathway 数据集包括对 18,973 幅具有不同低级外观的多源图像的 58K 详细人类反馈。
-
为了确保 MLLM 能够熟练地处理不同的查询,我们进一步提出了一种 GPT 参与的转换,将这些反馈转换为一组丰富的 200K 指令响应对,称为 Q-Instruct。
实验结果表明,Q-Instruct 持续提升了多个基础模型的各种低级视觉能力。我们预计我们的数据集可以为未来铺平道路,基础模型可以帮助人类完成低级视觉任务。

本文方案

作为数据集构建的基本部分,我们引入了 Q-Pathway,这是第一个收集人类在低级视觉方面的文本反馈的大规模数据集。为了使不同的低级外观多样化和平衡,我们对七个来源的图像进行了子采样,并减少了来源分布的偏差(见表 1)。准备好图像后,我们讨论了路径反馈的合理性和详细的任务定义,路径反馈是一种自然语言反馈,在 Q-Pathway 中收集。
数据准备

Q-Pathway 中的图像是从各种来源采样的,包括四个野外 IQA 数据集,以及两个包含 AI 生成图像的数据集。如图1所示,图像的子采样群体经过精心构建,以在Q-Pathway中引入更多样的低级外观,既不偏向正面外观,也不偏向负面外观。此外,为了进一步使所收集图像的低级外观多样化,我们设计了 imagecorruptions 的自定义变体,以随机损坏 COCO数据集中的 1,012 张原始原始图像,其中人工扭曲率为 15 分之一。组装的子采样数据集由 18,973 张图像组成,这些图像进一步馈送到人类受试者以提供通路反馈。
路径反馈

对于 Q-Pathway,为了收集对人类对低级视觉方面的感知更丰富、更细致的理解,我们选择了一种称之为“路径反馈”的注释格式对低级视觉属性进行详尽的自然语言描述,例如噪声、亮度、清晰度),然后是一般性结论。这种格式的理由如下:
-
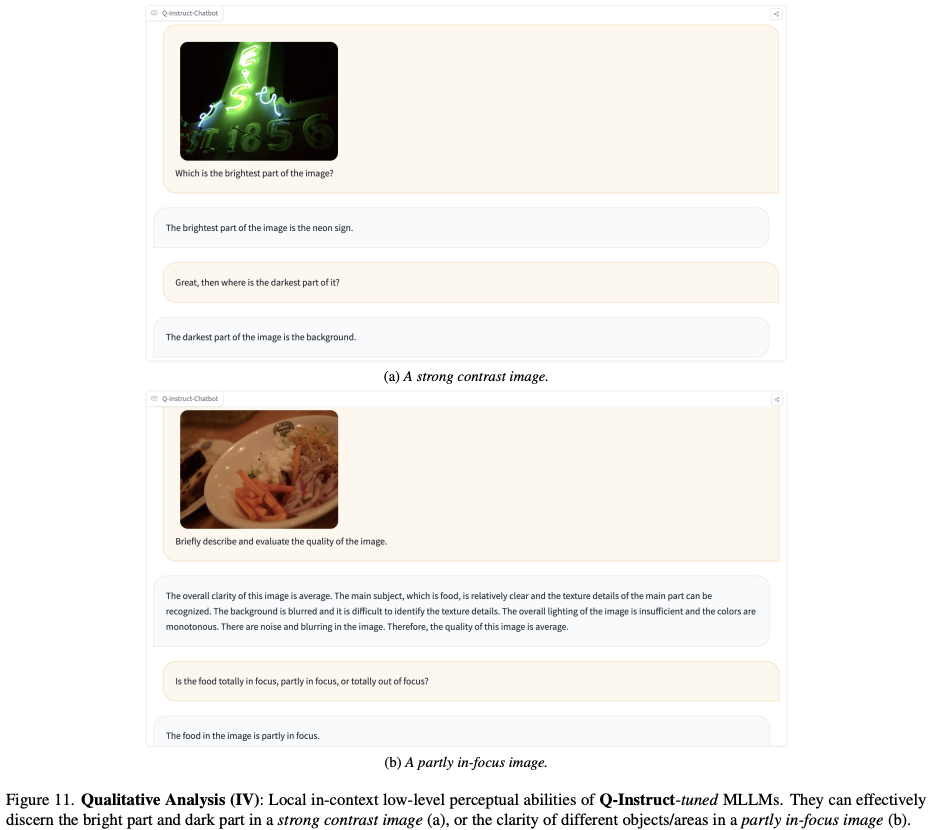
首先,描述可以更完整、更准确地保留人类的感知。例如,如果图像同时具有黑暗和明亮区域,如图上图所示,则亮度得分可能无法正确记录这种情况:无法保留位置上下文,并且得分的可靠性可能会降低也会受到损害,因为将其标记为“黑暗”或“明亮”都是不准确的。
-
此外,与自由形式的文本反馈不同,路径反馈中两部分的顺序通常与人类推理过程一致。例如,虽然人类受试者显示的图像曝光不足但清晰,但他们可以提供直观的推理,从而得出折衷的结论,例如“因此,图像的质量是可以接受的”。这种推理将帮助 MLLM 更好地模拟人类对低级视觉的感知和理解。虽然这种路径式格式在过去面临着转化为机器学习目标的挑战,但 MLLM 的出现提供了从这些直接人类反馈中学习的机会,以便让机器能够更精确、更稳健地与人类感知保持一致。
主观学习过程
主观研究是在控制良好的实验室环境中进行的,期间总共邀请了 39 名经过训练的人类受试者。基于任务定义,培训材料不仅包括对整体质量的校准,还包括对视觉中显示的不同低级外观的各自文本描述。
此外,由于大多数图像来自 IQA 数据集,它们的平均意见得分 (MOS) 也会显示给受试者,以便更好地通过对质量的共同理解来校准它们。为了促进他们的反馈过程,我们还展示了可在描述中使用的参考属性集。为避免受试者测试疲劳,连续反馈超过30张图像将被警告和劝阻; 50 张图像后将进一步强制暂停。在研究过程中收集了 58K 通路反馈,如图 3(a) 所示。
Q-Instruct
Q-Pathway 中的长且多样化的反馈为用于低级视觉指令调整的指令-响应对的自动生成过程提供了足够的参考。虽然路径反馈本身可以教会 MLLM 推理低级方面并预测质量,但我们设计了更多的指令类型以允许 MLLM 响应各种人类查询,包括视觉问答子集以获得更准确的低级感知能力,以及扩展的对话子集以允许 MLLM 与人类无缝地讨论与低级视觉方面相关的主题。总体而言,Q-Instruct数据集包括20万个指令-响应对,其详细信息如下。

与图像字幕类似,一般的低级视觉描述能力对于 MLLM 也至关重要。通路反馈是直接且整体的人类反应,通常描述低级视觉外观。此外,这些反馈提供了从低级属性(亮度、清晰度)到总体质量评级(好/差)的推理,这可以激活 MLLM 在 IQA 上的潜在推理能力。从此以后,以每个通路反馈作为响应,以一般提示作为指令,我们将 58K 通路推理(图 4(a))作为 Q-Instruct 数据集的主要部分。
除了直接将 Q-Pathway 应用于低级视觉指令调整之外,我们还设计了一个 GPT参与的管道,将它们转换为视觉问答(VQA)子集。一般来说,我们要求 GPT 从通路反馈中生成与低水平视力相关的多样化问题,并以尽可能少的文字提供答案。通过这个过程,我们将反馈转化为 76K 问题,包括如何用与观点相关的形容词(例如好/差、高/低)回答问题,或者即用属性相关(模糊/噪音/焦点)或上下文回答哪些问题相关(左/孔雀/背景)名词,如图4(b)上半部分所示。我们进一步指示 GPT 根据反馈生成二元判断(是/否,下图 4(b)),并将是和否平衡为 1:1 的比例,最终收集到 57K 是或否问题。至于回答格式,遵循A-OKVQA,尽管有直接答案,我们也为问题创建了几个分散注意力的答案,并将它们转换为附加的多项选择题(MCQ)格式(图1中的粉红色框)。 4(b))。
前两个子集旨在增强低级视觉的基本语言相关能力,而 Q-Instruct 的第三个子集即扩展对话(图 4(c))则侧重于提高与他人讨论的能力。人类基于输入图像的低级视觉方面。这些讨论包括五个主要范围:
-
1)检查低级视觉模式的原因;
-
2)提供摄影方面的改进建议;
-
-
提供图像恢复、增强或编辑工具;
-
-
4)向各自的消费者推荐形象;
-
-
鉴于路径反馈中提供的低级视觉描述,可能发生的其他对话。
-
同样,扩展对话子集也是由 GPT 生成的,为 Q-Instruct 收集了总共 12K 个对话。
底层视觉指令调整

在本节中,我们讨论低级视觉指令调整的标准训练策略,即在 MLLM 训练期间何时涉及 Q-Instruct 数据集。一般来说,开源MLLM的训练包括两个阶段:首先,将视觉主干和LLM的表示空间与百万级网络数据对齐。其次,结合人类标记的数据集进行视觉指令调整。
考虑到 Q-Instruct 的规模,一般策略是将其指令-响应对与第二阶段的高级数据集混合,以便在一般高级意识中理想地构建其低级视觉能力,如如图5(a)所示。另一种更快、更方便的策略是在原始高级调整后仅使用 Q-Instruct(图 5(b))的第三阶段。在我们的实验中,我们验证了它们都对各种低级视觉任务带来了显着的改进,并且涉及高级意识有助于这两种策略的有效性。
本文实验