
- 1Microsoft Office Word导出高清PDF步骤
- 2人工智能在信息系统安全中的运用(1),网络安全实战项目视频_人工智能在信息安全中的实现方式有哪些
- 3解决iTerm中‘zsh-syntax-highlighting‘找不到的问题_plugin 'zsh-syntax-highlighting' not found
- 4NetworkManager的前世今生
- 5Npm常用命令有哪些_npm run dev之前有过命令是?
- 6快速解决浏览器访问http或者不安全https 地址栏出现不安全或者Not secure_chrome not secure
- 7如何连接python和neo4j
- 8十大经典排序算法(全面总结+Java代码实现)_for(int j = 1; j < r; ++j)
- 9基于Python网易云音乐评论数据爬取+清洗+分析可视化 计算机毕业设计(附源码)✅_爬取网易云音乐热评
- 10从零开始学习大模型-第一章-大模型是什么_大模型如何学习
Mysql笔记(1)【DQL】_数据库查询倒数第二个字
赞
踩
目录
9)包含(in)操作符(可以采用多个or来表示,采用in会更简洁)
10)非(not)操作符(取非,主要用在 is 或 in中)
11)模糊查询(like)关键字(支持 % 或下划线 _ 匹配)
七、数据排序 order by(asc小到大 desc大到小)
一、SQL的分类
1)数据库查询语言(DQL)
简称:DQL,Data Query Language
代表关键字:select
2)数据库操作语言(DML)
简称:DML,Data Manipulation Language
代表关键字:insert、delete 、update
增、删、改表中的数据
3)数据库定义语言(DDL)
简称:DDL,Data Denifition Language
代表关键字:create、drop、alter
创建、删除、修改表的结构
4)事务控制语言(TCL)
简称:TCL,Trasactional Control Language
代表关键字:commit、rollback
5)数据控制语言(DCL)
简称:DCL,Data Control Language
代表关键字:grant、revoke
6)DML和DDL的区别是什么?
DML是修改数据库表中的数据,而DDL是修改数据中表的结构;
二、导入数据
1)使用MySQL命令行客户端来装载数据库
1.连接MySQL:mysql -u账号 -p密码
mysql - uroot -proot
2.创建数据库:create database bjpowernode;
3.选择数据库:use bjpowernode;
4.导入数据库:source D:\bjpowernode.sql;
5.删除数据库:drop database bjpowernode;
2)查看数据库相关命令
1.查看数据库管理系统中所有的数据库表:show databases;
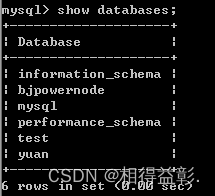
2.查看所有bjpowernode数据库中的所有表格:show tables;

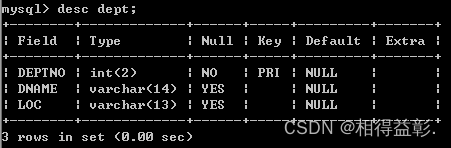
3.查看描述表的结构:desc 表名;
三、常用命令
1)查看MySQL版本(进入MySQL前)
1.mysql --version
![]()
2. mysql -V(注:大写字母V)
2)查询当前使用数据库及Mysql版本(进入Mysql)后
1.查看当前使用数据库 select database();

2.查看当前MySQL数据库版本

3)创建数据库
1.create database 数据库名称;
![]()
2.use 数据库名称;(在数据库中创建表的时候必须要先选择数据库)
![]()
3.终止一条SQL语句,可输入\c;
4.退出MySQL
1.使用exit,\q
2.快捷键crtl+c
四、数据结构
1)如何取得演示数据
1.查看和指定现有的数据库 Show databases;
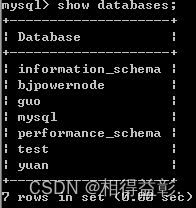
2.指定当前缺省数据库 use bjpowernode;
![]()
3.查看当前使用数据库 select database();

4.查看当前数据库中的表 show tables;
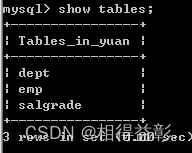
5.查看其它数据库中的表 show tables from 数据库名称

6.查看表结构 desc 表名称;
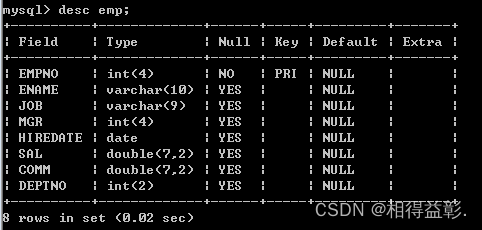
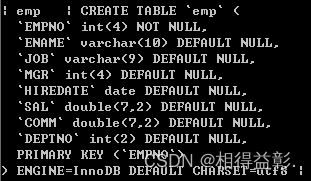
7.查看表的创建语句 show create table emp;
DQL(数据查询语言):查询语句,只要select语句都是DQL。
五、简单查询
1)查询一个字段
(在SQL语句中不区分大小写;SQL语句以“;”分号结束)
(select语句后面是要查询的字段,select和字段名称之间采用空格隔开,from表示将要查询的表,一样需要空格隔开)
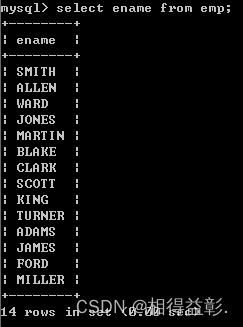
1.查看员工姓名 select ename from emp;
2)查询多个字段
(多个字段查询时,字段与字段之间用“,”隔开)
(查询多个字段,select中的字段采用逗号间隔即可,最后一个字段,也就是在from前面的字段不能使用逗号)
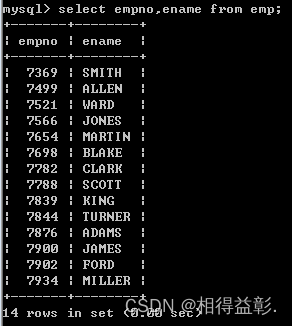
1.查询员工编号和员工姓名 select empno,ename from emp;
3)查询全部字段
(我们可以将所有字段都放到select语句之后,这种方案不方便,但是比较清楚,我们可以采用“*”星号的方式查询全部字段)
(采用 select * from emp,虽然简单,但是 * 号不是很明确,并且 select * 语句会先去编译,将“*”转换成字段,建议查询全部字段将相关字段写到 select 语句的后面,
在以后 java 连接数据库的时候,是需要在 java 程序中编写 SQL 语句的,这个时候编写SQL语句不建议使用 select * 这种形式,建议写明字段,这个 SQL 语句的可读性强。)
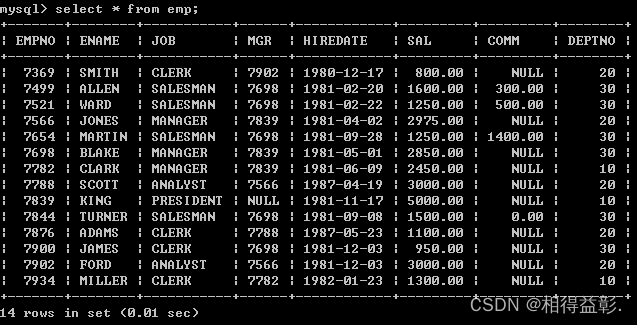
1.查询员工表 select * from emp;
4)计算员工的年薪
(字段上可以使用数学表达式,只要SQL语句中有 select 关键字,不会修改底层数据库字段的值;)
1.列出员工的编号,姓名和年薪 select empno,ename,sal*12 from emp;

5)将查询出来的字段重命名和显示为中文
(重命名使用as关键字,需要“,”隔开,也可以直接在字段后面重命名)
1. 重命名为中文时必须加单引号或双引号;
2. 标准SQL语句中类型为字符串时必须加单引号,加单引号适用亍任何数据库;
3. SQL语句中类型为字符串时也可加双引号,只适用于MySQL数据库中;
4. 为了SQL询句的通用性,建议全部使用单引号;
1.列出员工的编号,姓名和年薪(使用中文命名)
select empno '员工编号',ename '员工姓名',sal*12 '年薪' from emp;

六、条件查询
1)where支持如下运算符
(条件查询需要用到 where 语句,where必须放到 from 语句表的后面)
(执行顺序:先from再where过滤后再检索出来)
| 运算符 | 说明 |
| = | 等于 |
| <>或!= | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| between … and … | 两个值之间,等同于>= and <= |
| is null | 为null(is not null 不为空) |
| and | 并且 |
| or | 或者 |
| in | 包含,相当于多个or(not in 不在这个范围中) |
| not | not可以取非,主要用在 is 或 in中 |
| like | like称为模糊查询,支持 % 或下划线 _ 匹配; % 匹配任意个字符; 下划线 _,一个下划线只匹配一个字符 |
2)等号(=)操作符
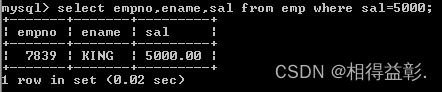
1.查询薪水为5000的员工
select empno,ename,sal from emp where sal=5000;
2.查询job为MANAGER的员工
select empno,ename,job from emp where job='manager';

3)不等号(<>、!=)操作符
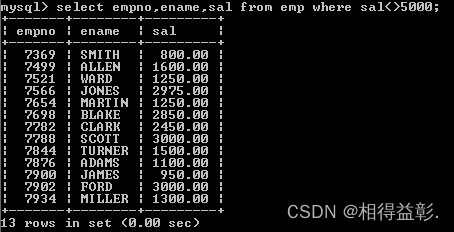
1.查询薪水不等于5000的员工
select empno,ename,sal from emp where sal<>5000;(建议这一种方法)
select empno,ename,sal from emp where sal!=5000;
select empno,ename,sal from emp where sal <> '5000';
2.查询工作岗位不等于MANAGER的员工

4)区间(between … and …) 操作符
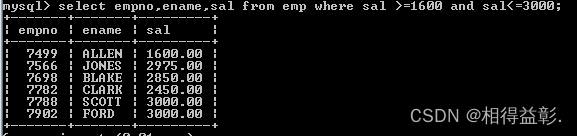
1.查询薪水为1600到3000的员工
(between … and … 它是包含最大值和最小值)
select empno,ename,sal from emp where sal between 1600 and 3000;(between … and …)

select empno,ename,sal from emp where sal >=1600 and sal<=3000;
2.(了解)between … and … 同样也可用在字符上,用在字符上区间为:前闭后开
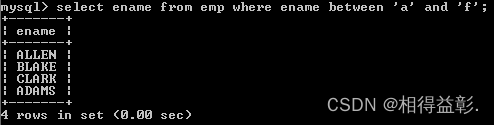
5)为空(is null)操作符
(Null为空,它不是一个数值,不是一个空串,为null可以设置这个字段不填值,如果查询为null的字段,采用is null)
1.查询津贴为空的员工
错误:select empno,ename,comm from emp where comm=null;(因为null类型比较特殊,必须使用is来比较)
![]()
select empno,ename,comm from emp where comm is null;
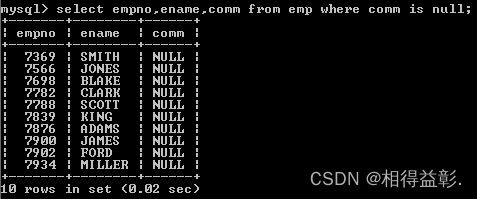
2.查询津贴不为空的员工
select empno,ename,comm from emp where comm is not null;
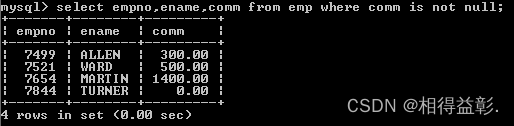
6)并且(and)操作符 (所有查询条件必须满足)
1.查询工作岗位为“MANAGER”并且薪水大于2500的员工
select empno,ename,job,sal from emp where job='MANAGER' and sal>2500;

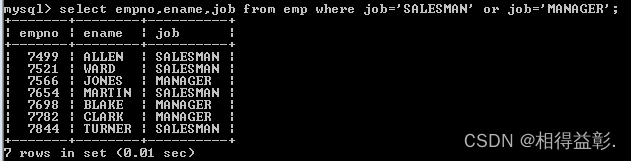
7)或者(or)操作符 (满足任意一个条件即可)
1.查询出job为SALESMAN和job为MANAGER的员工
select empno,ename,job from emp where job='SALESMAN' or job='MANAGER';
8)and与or表达式的优先级
(and的优先级高于or)
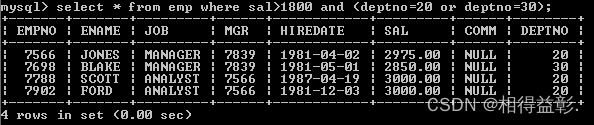
1.查询薪水大于1800,并且部门编号为20或30的员工
错误:select * from emp where sal>1800 and deptno=20 or deptno=30;(表达式的优先级导致的,首先SQL语句过滤了 sal > 1800 and deptno = 20,然后再将deptno = 30的员工合并过来,所以是不正确的。)

select * from emp where sal>1800 and (deptno=20 or deptno=30);
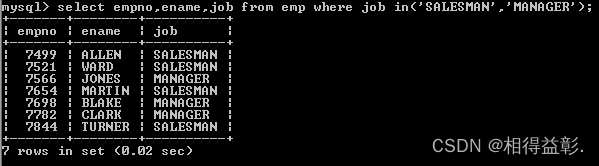
9)包含(in)操作符(可以采用多个or来表示,采用in会更简洁)
1.查询出job为 SALESMAN 和 job 为MANAGER 的员工
select empno,ename,job from emp where job in('SALESMAN ','MANAGER ');
2.查询出薪水为1600和3000的员工
select empno,ename,sal from emp where sal in(1600,3000);

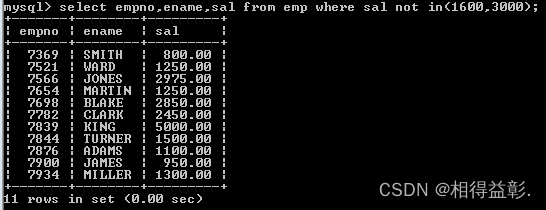
3.查询出薪水不是1600和3000的员工
select empno,ename,sal from emp where sal not in(1600,3000);
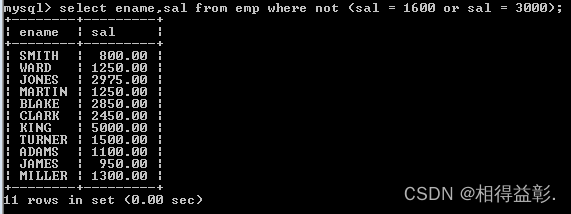
10)非(not)操作符(取非,主要用在 is 或 in中)
1.查询出薪水不是1600和3000的员工
select ename,sal from emp where sal <> 1600 and sal <> 3000;

select ename,sal from emp where not (sal = 1600 or sal = 3000);
select ename,sal from emp where sal not in (1600,3000);
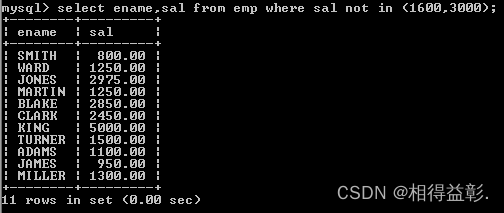
2.查询出津贴不为null的员工
select empno,ename,comm from emp where comm is not null;

11)模糊查询(like)关键字(支持 % 或下划线 _ 匹配)
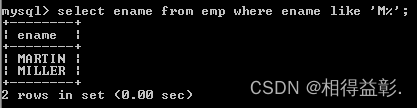
1.查询姓名以M开头的所有员工 ('M%')
select ename from emp where ename like 'M%';
2.查询姓名以 N 结尾的所有员工('%N')
select ename from emp where ename like '%N';

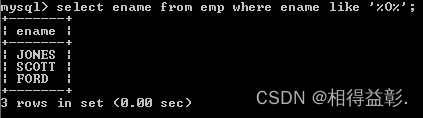
3.查询姓名中包含 O 的所有员工('%O%')
select ename from emp where ename like '%O%';
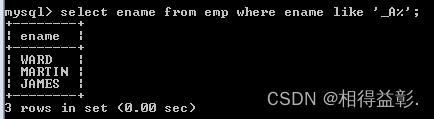
4.查询姓名中第二个字符为A的所有员工('_A%')
select ename from emp where ename like '_A%';

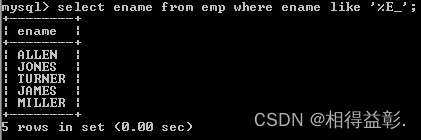
5.查询姓名中倒数第二个字符为E的所有员工('%E_')
select eanme from emp where ename like '%E_';
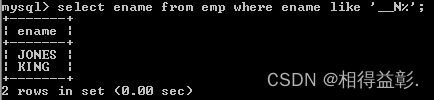
6.查询姓名中第三个字符为N的所有员工姓名('__N%')
select ename from emp where ename like '__N%';
七、数据排序 order by(asc小到大 desc大到小)
1)单一字段排序 order by 字段名称
(作用:通过那个或那些字段进行排序
含义:排序采用 order by 子句,order by 后面跟上排序字段,排序字段可以放多个,多个采用逗号间隔,order by默认采用升序(asc),如果存在 where 子句,那么 order by 必须放到where 语句后面。)
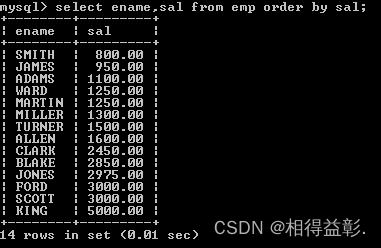
1.按照薪水由小到大排序(系统默认由小到大)
select ename,sal from emp order by sal;
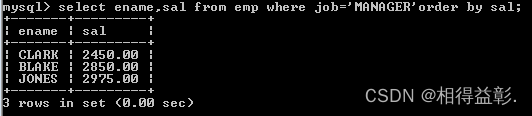
2.取得job为 MANAGER 的员工,按照薪水由小到大排序(系统默认由小到大)
(如果包含where语句 order by 必须放到 where 后面,如果没有 where 语句 order by 放到表的后面)
select ename,sal from emp where job='MANAGER' order by sal;
2)手动指定字段排序
1.手动指定按照薪水由小到大排序(升序关键字 asc)
select ename,sal from emp order by sal asc;

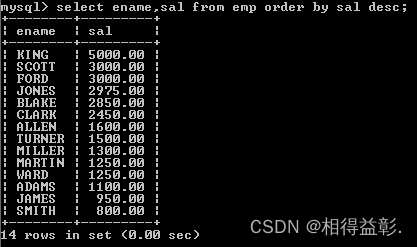
2.手动指定按照薪水由大到小排序(降序关键字desc)
select ename,sal from emp order by sal desc;
3)多个字段排序
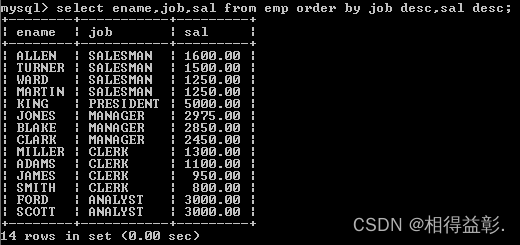
1.按照job和薪水倒序排序
(如果采用多个字段排序,如果根据第一个字段排序重复了,会根据第二个字段排序)
select ename,job,ename from emp order by job desc,sal desc;
4)使用字段位置排序
1.按照薪水升序排序(不建议采用此方法,采用数字含义不明确,可读性不强,程序不健壮)
select * from emp order by sal;

八、处理函数
一、单行函数
(注意:数据处理函数是该数据本身特有的,有些函数可能在其它数据库不起作用;)
| lower | 转换小写 |
| upper | 转换大写 |
| substr | 取子串(substr(被截取的字符串,起始下标,截取的长度)) |
| length | 取长度 |
| trim | 去空格 |
| str_to_date | 将字符串转换成日期 |
| date_format | 格式化日期 |
| format | 设置千分位 |
| round | 四舍五入 |
| rand() | 生成随机数 |
| Ifnull | 可以将null转换成一个具体值 |
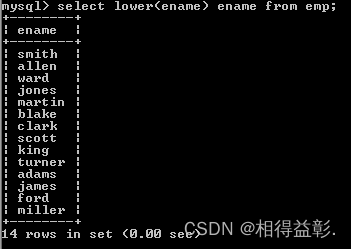
1)lower(字段名)函数:转换小写
用法:lower(字段名称)
1.查询员工姓名,将员工姓名全部转换成小写
select lower(ename) ename from emp;
2)upper(字段名)函数:转换为大写
用法:upper(字段名称)
1.查询员工姓名,将员工姓名全部转换为大写
select upper(ename) ename from emp;

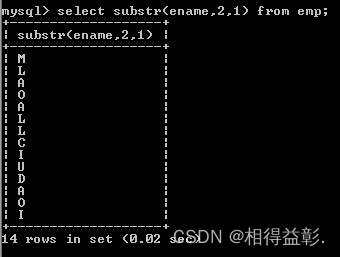
3)substr(字段名,起始下标,截取长度)函数:取子串
用法:substr(字段名称,起始下标,截取长度)(起始下标:1开始)
1.查询并显示所有姓名的第二个字母
select substr(ename,2,1) from emp;
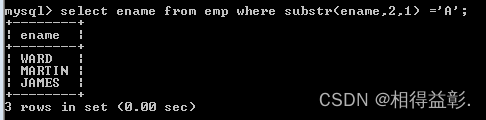
2.查询员工姓名中第二个字母为A的所有员工
select ename from emp where substr(ename,2,1) ='A';
select ename from emp where ename like '_A%';
4)length(字段名)函数:取字段长度
用法:length(字段名称)
1.取得员工姓名长度
select ename,length(ename) lengthename from emp;

5)trim('字符串')函数:去除首尾空格
(作用:trim函数去除首尾空格,不会去除中间空格)
用法:trim(字符串)
1.取得工作岗位为manager的所有员工
(MySQL默认去除字段后面的空格,原因:MySQL语法松散)
select * from emp where job=trim(' manager ');

6)str_to_date函数:将字符串转换为日期
(作用:将’日期字符串‘转换为’日期类型‘数据)执行结果:DATE类型
1.用法:str_to_date('日期字符串','日期格式')
①日期字符串:日期格式的字符串
②日期格式 :告诉MySQL输入日期字符串的格式是什么
MySQL日期格式:
| 序号 | 格式符 | 功能 | 格式符 | 功能 |
| 1 | %Y | 代表四位的年份 | %y | 代表两位的年份 |
| 2 | %m | 代表月,格式(01…12) | %c | 代表月,格式(1…12) |
| 3 | %d | 代表日 | ||
| 4 | %H | 代表24小时制 | %h | 代表12小时制 |
| 5 | %i | 代表分钟,格式(00…59) | ||
| 6 | %S或%s | 代表秒,格式(00…59) |
2.案例
①查询出1981-12-03入职的员工
select ename,hiredate from emp where hirdate='1981-12-03';
select ename,hiredate from emp where hirdate='1981/12/03';
select ename,hiredate from emp where hirdate='19811203';

1.在Mysql中日期作为查询条件时,可以使用字符串为其赋值,常用格式有三种:
1981-12-03
1981/12/03
19811203
输入的日期字符串格式与Mysql默认日期格式相同,Mysql默认日期格式:%y-%m-%d
②查询出02-20-1981入职的员工
select ename,hirdate from emp where hirdate =str_to_date('02-20-1981','%m-%d-%Y');

总结:
1.日期是数据库本身的特色,也是数据库本身机制中的一个重要内容,所以仍需掌握;
2.每一个数据库处理日期时采用的机制都不一样,都有自己的一套处理机制,所以在实际开发中将日期字段定义为DATE类型的情况很少;
3.如果使用日期类型,java程序将不能通用。实际开发中,一般会使用“日期字符串”来表示日期;
A、创建t_student 表【create语句】,插入含有日期的数据
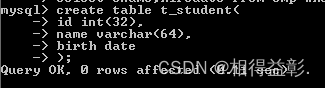
a.插入数据:1980-01-18【insert】
![]()
执行成功:‘1980-01-18’虽然是一个varchar类型,但是由于格式和MySQL数据库默认的日期格式相同,所以存在自动类型转换。
c.执行失败:再次插入01-18-1980
c.a.'01-18-1980'日期字符串的格式和Mysql默认的格式不同
c.b.'01-18-1980'是varchar类型,birth字段需要DATE类型,类型不匹配
d.正确写法:
![]()
结论:str_to_date函数通常使用在插入操作中;字段DATE类型,不接收varchar类型,需要先通过该函数将varchar变成date再插入数据。
7)date_format函数:将日期转换为特定格式字符串
(作用:将’日期类型‘转换为特定格式的’日期字符串‘类型)
用法:date_format(日期类型数据,'日期格式')
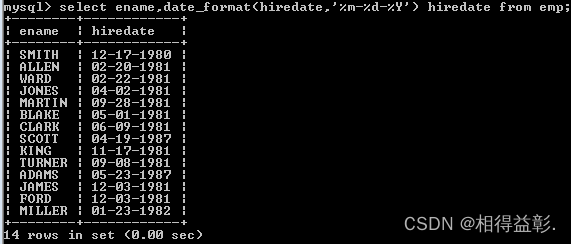
1.查询员工的入职日期,以’10-12-1980‘的格式显示到窗口中;
select ename,date_format(biredate,'%m-%d-%Y') biredate from emp;
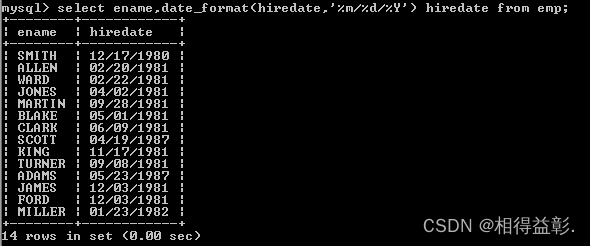
2.查询员工的入职日期,以’10/12/1980‘的格式显示到窗口中;
select ename,date_format(biredate,'%m/%d/%Y') biredate from emp;
3.MySQL日期默认格式示例
①以下两个DQL语句执行结果相同
第一种:hiredate转换字符串类型,默认使用的是:'%Y-m-%d';
select ename,hiredate from emp;
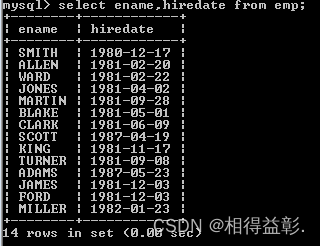
第二种:通过date_format(hiredate,'%Y-m-%d')函数
select ename,date_format(hiredate,'%Y-m-%d') hiredate from emp;

结论:date_format()函数主要应用在数据库查询操作上,实际工作中,用户需要日期以特定的格式展示出来的时候,需要用该函数实现
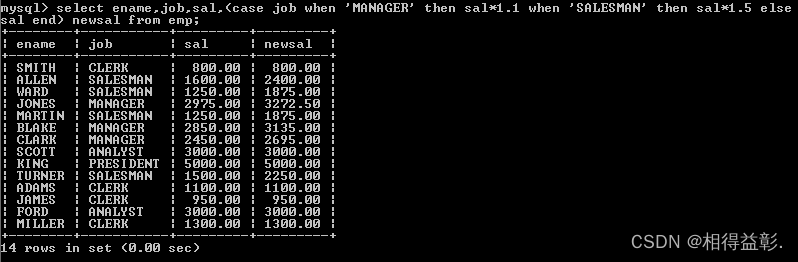
8)case…when…then…else…end(匹配…当…就…其他…不变)
用法:匹配工作岗位,当为MANAGER时,薪水上调10%,当为SALESMAN时,薪水上调50%,其他岗位薪水不变
case job
when 'MANAGER' then sal*1.1
when 'SALESMAN' then sal*1.5
else sal
end
注意:使用在DQL语句中
1.匹配工作岗位,当为MANAGER时,薪水上调10%,当为SALESMAN时,薪水上调50%,其他岗位薪水不变
select ename,job,sal
(case job
when 'MANAGER' then sal*1.1
when 'SALESMAN' then sal*1.5
else sal
end) newsal
from
emp;
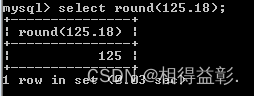
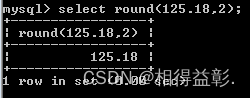
9)round(数字,保留小数位数)函数:四舍五入
用法:round(数字,数字哪一位)(默认保留整数位)
1.保留整数位或不保留小数位
select round(125.18);
select round(125.18,0);

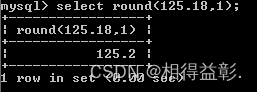
2.保留1位小数
select round(125.18,1);
3.保留2位小数
select round(125.18,2);
4.个位四舍五入
select round(125.18,-1);

10)rand()生成随机数;
1.生成一0≤ v ≤ 1.0个随机数
select rand();

2.生成一个0-100的随机数
select rand()*100;

11)ifnull(字段名,替换值)函数:空值处理函数
(结论:在数据库中,有Null参与数学运算的结果一定为Null;为了防止计算结果出现Null,建议先使用ifnull函数预先处理。)
用法:ifnull(字段名称,将要替换)
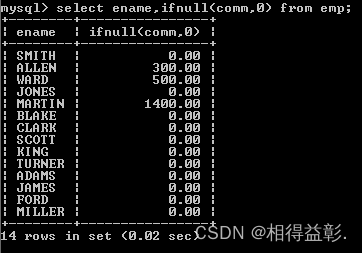
1. 查询员工姓名及补助,如果补助为Null设置为0;
select ename,ifnull(comm,0) from emp;
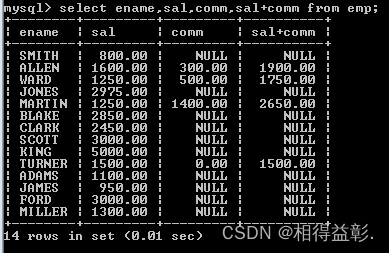
2.查询员工薪水和补助的和
错误:select ename,sal,comm,sal+comm from emp;
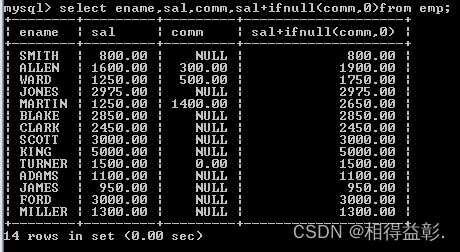
select ename,sal,comm,sal+ifnull(comm,0)from emp;
3.没有补助的员工,将每月补助100,求员工的年薪
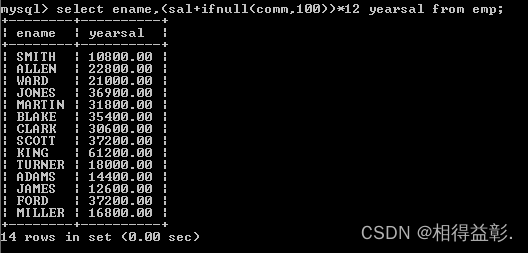
select ename,(sal+ifnull(comm,100))*12 yearsal from emp;
二、多行函数、聚合函数、分组函数
常用以下几种:
| sum | 求和 |
| avg | 取平均值 |
| max | 取最大值 |
| min | 取最小值 |
| count | 取记录条数 |
1)什么是单行处理函数,什么是多行处理函数?
单行函数:一行输入对应一行输出
多行函数:多行输入对应一行输出
2)注意:
1.分组函数自动忽略空值,不需要手动增加where条件排除空值;
2.分组函数不能直接使用在where 关键字后面;
3)sum(字段)函数
作用:求某一列的和,null会自劢被忽略;
用法:sum(字段名)
1.案例(null会被忽略不计)
a.取得薪水的合计
select sum(sal) from emp;

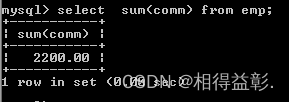
b.取得补助的合计
select sum(comm) from emp;
c.取得总共薪水(工资+补助)合计
select sum(sal+ifnull(comm,0)) from emp ;

1.comm字段有null值,在多列进行运算时,只要有null参与的数学运算结果都为null;
2.sum函数会自动忽略掉null值,正确的做法是将comm的null值转换为0,如:ifnull(comm,0)
4)avg(字段名)函数
作用:求某一列的平均值,null会被自动忽略
用法:avg(字段名)
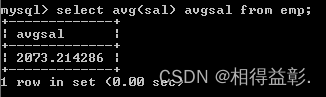
1.取得平均薪水
select avg(sal) avgsal from emp;
5)max(字段名)函数
作用:取得某一列的最大值
用法:max(字段名)
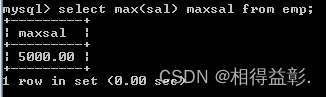
1.取得最高薪水
select max(sal) maxsal from emp;
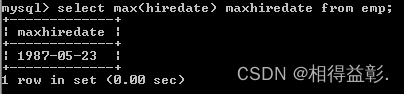
2.取得最晚入职的员工
select max(hiredate) maxsal from emp;
6)min(字段名)函数
作用:取得某一列最小值
用法:min(字段名)
1.取得最低薪水
select min(sal) mignsal from emp;

2.取得最早入职的员工
select min(hiredate) minhiredate from emp;

7)count函数
作用:取得摸个字段值不为null的记录总数
用法:count(字段名称)或count(*)
注意:
1.count(*)表示取得当前查询表所有记录
2.count(字段名),不会统计为null的记录
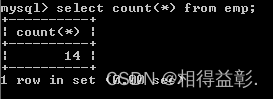
1.取得所有员工数
select count(*) from emp;
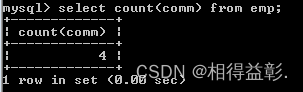
2.取得补助不为空的所有员工数
select count(comm) from emp;
select count(comm) from emp where comm is not null;

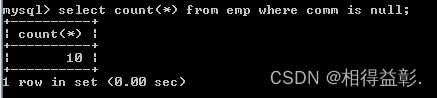
3.取得补助为空的员工数量
select count(*) from emp where comm is null;
8)组合聚合多行函数sum,avg,max,min,count
1.查询员工条数,工资总和,工资平均值,工资最大值,工资最小值
select count(*),sum(sal),avg(sal),max(sal),min(sal) from emp;

三、distinct去除重复记录
作用:将查询结果中某一个字段的重复记录去除掉
用法:distinct 字段名或distinct 字段名1,字段名2……
distinct 字段名A:去除与字段名A相同的记录
distinct 字段名A,字段名B:去除与字段名A和字段名B同时相同的记录
注意:distinct只能出现在所有字段最前面,后面如果有多个字段及多字段联合去重
1)查询该公司有哪些工作岗位
select distinct job from emp;

2)查询该公司工作岗位数量
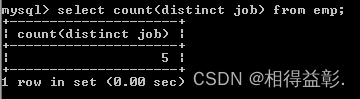
select count(distinct job) from emp;
3)去除部门编号deptno和工作岗位job重复的记录
select distinct deptno,job from emp;

四、分组查询:group by
作用:通过那个或那些字段进行分组
用法:group by 字段名
1)找出每个工作岗位的最高薪水
思路:按照工作岗位分组,然后对每一组求最大值
select ename,job,max(sal) from emp group by job;

结论:有group by 的DQL语句中,select 语句后面只能跟 分组函数+参与分组的字段;
2)计算每个工作岗位的最高薪水,并且按照由低到高进行排序
思路:按照工作岗位分组,然后求每一组的最大值,再按照求出的值由低到高进行排序
select ename,job,max(sal) from emp group by job order by sal;
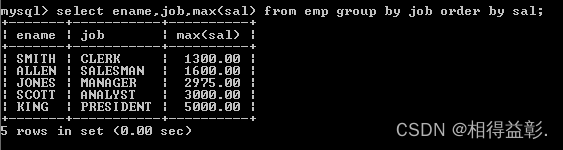
结论:如果orderby 参与,必须放在group by后面
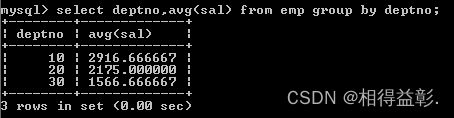
3)计算每个部门的平均薪水
思路:按照部门分组,然后求每一组的平均值;
select deptno,avg(sal) from emp group by deptno;
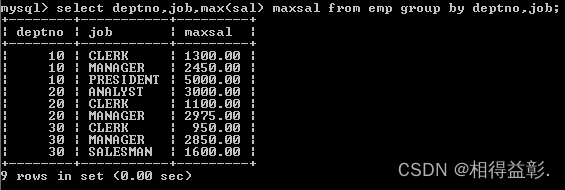
4)计算不同部门不同岗位的最高薪水
思路:按照部门,岗位分组,然后求每个部门,每个岗位的最高值;
select deptno,job,max(sal) maxsal from emp group by deptno,job;
5)找出每个工作岗位的最高薪水,除MANAGER之外
思路:先将job=manager的去掉,然后按照工作岗位分组,求每一组的最大值;
select job,max(sal) maxsal from emp where job !='MANAGER' group by job;

2.having
作用:如果想要分组的数据再进行过滤,需要使用having子句
2.1找出每个工作岗位的平均薪水,要求显示平均薪水大于2000的;
思路:先对工作岗位进行分组,然后对求每一组薪水平均值,最后对每一组平均值大于2000的进行条件过滤;
select job,avg(sal) avgsal from emp group by job having avgsal>2000;

注意:能够在where中过滤的数据不要放到having中进行过滤,否则影响SQL询句的执行效率
3.where 与 having 区别:
1. where 和 having 都是为了完成数据的过滤,它们后面都是添加条件;
2. where 是在 group by之前完成过滤;
3. having 是在 group by 之后完成过滤;
九、select语句总结
一个完整的SQL语句如下:
select
xxx
from
xxx
where
xxx
group by
xxx
having
xxx
order by
xxx
以上关键字的顺序不能变,严格遵守
以上语句的执行顺序:
1)from:将硬盘上的表文件加载到内存
2)where:将符合条件的数据取出来。生成一张新的临时表
3)group by:根据列中的数据种类,将当前临时表划分成若干个新的临时表
4)having:可以过滤掉 group by 生成的不符合条件的临时表
5)select:对当前临时表进行整列读取
6)order by:对select 生成的临时表,进行重新排序,生成新的临时表
7)limit:对最终生成的临时表的数据行,进行截取

