
- 1给boss直聘的搜索结果加上hr活跃状态,少看点半年活跃的岗位,有书签版,油猴版_boss直聘半年前活跃还招人吗
- 2Android中Broadcast的Intent大全
- 3转载:大数据基础服务平台
- 4codeforce Round#521 C. Good Array_you are given an array consisting of n integers. y
- 52024年安卓最新面试 100% 完全掌握:重新认识 View 的绘制流程(1),字节跳动面试官级别_view的绘制流程
- 6使用腾讯云轻量应用服务器搭建Frp内网穿透到OpenWrt_腾讯云内网穿透
- 7Apache Tomcat安全限制绕过漏洞 CVE-2017-5664_tomcat 7.0.78漏洞
- 8富文本 考试 填空题_富文本填空题
- 9Redis详解及相应问题的解决方案_怎么使用的redis,有遇到过什么难题
- 10mac反向控制iphone_反向工程iPhone X Home指示灯颜色
十七、BART
赞
踩
前期回顾:BERT模型是仅使用 Transformer-Encoder 结构的预训练语言模型。GPT模型是仅使用 Transformer-Decoder 结构的预训练语言模型。
BART(Bidirectional and Auto-Regressive Transformers)模型是使用标准的 Transformer-Encoder and Decoder 模型整体结构的预训练语言模型。其在标准的 Seq2Seq Transformer Model 的基础之上,融合了 BERT 的 Bidirectional Encoder 和 GPT 的 Left-to-Right Recoder 的优点,使得它比 BERT 更适合文本生成的场景;相比 GPT,也多了双向上下文语境信息。
BART 发表在文章Denoising Sequence-to-Sequence Pre-training...中:
1 模型设计
BART 模型设计的目的很明确,就是在利用 Encoder 端的双向建模能力的同时,保留自回归的特性,以适用于生成式任务。
BART 模型的 Encoder 端的输入是加了多种噪声 Noise 的序列(意图是破坏掉这些有关序列结构的信息,防止模型训练去“依赖”这样的信息),Decoder 端的输入是 Shifted Right 的序列,Decoder 端的目标是原序列。
Q1:多种噪音 Noise 都包括什么?参考生成式预训练之BART
- Token Masking:随机将 Token 替换成 [MASK](即BERT的方法)。作用是训练模型推断单个 Token 的能力。
- Token Deletion:随机删去 Token。作用是训练模型推断单个 Token 及其位置的能力。
- Text Infilling:随机将一段连续的 Token(称作 Span)替换成一个 [MASK],Span的长度服从
= 3 的泊松分布。注意 Span 长度为 0 就相当于插入一个 [MASK]。作用是训练模型推断一段 Span 对应多少个 Token 的能力。
- Sentence Permutation:将一篇 Document 的句子顺序打乱。作用是训练模型推理前后句关系的能力。
- Document Rotation:从 Document 序列中随机选择一个 Token,然后使得该 Token 作为 Document 的开头。作用是训练模型找到 Document 开头的能力。
Q2:什么是 Shifted Right ?
Shifted Right 实质上是给输出添加起始符或者结束符,方便预测第一个 Token 或者结束预测过程。
BART 与 BERT 和 GPT 的模型对比图:
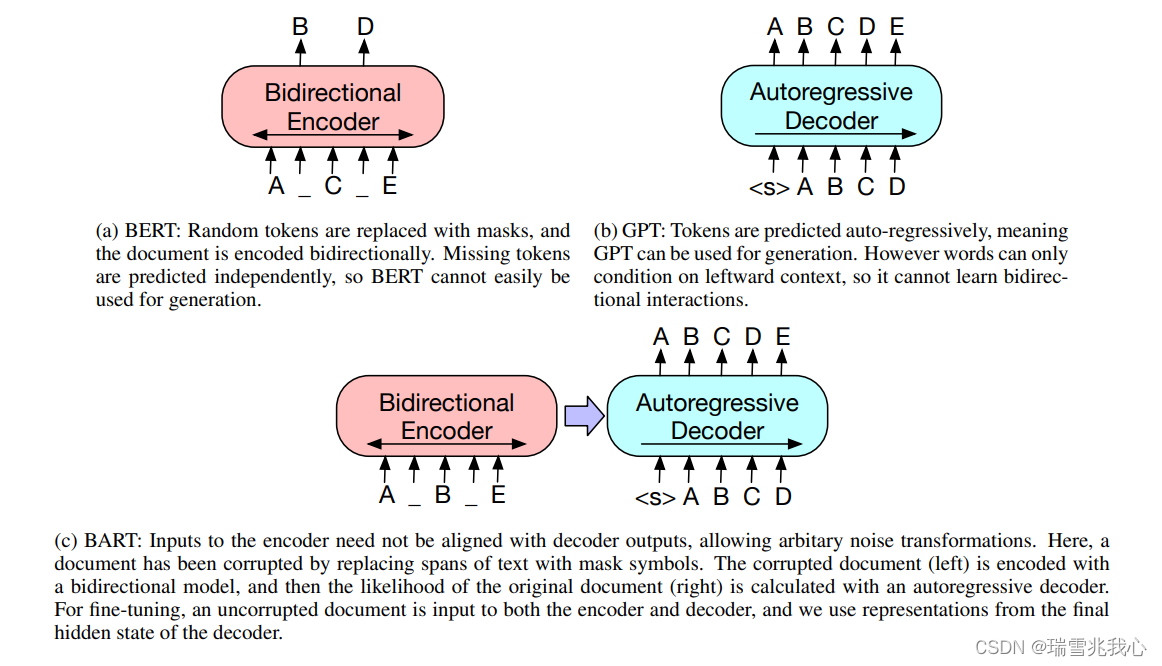
- 在 BART 中,输入输出并不需要严格的保持长度一致,即 Encoder 的输入与 Decoder 的输出不需要保持对齐;
- 左边部分 Encoder 接收被破坏后的文章结构,它经过 Encoder 双向编码,类似于 Bert;
- 右边部分接收来自 Encoder 的输出后,经过自回归解码输出预测结果,类似于 GPT(自回归解码依据的是最大似然概率)。
2 预训练
BART 的预训练主要依据以下两步走的思路:参考BART论文要点解读
- 通过随机选择的噪声函数(就是能够制造破坏文档结构的任何方法)来破坏文章结构;
- 通过训练一个序列到序列(Seqience2Sequence)的模型逼迫模型能够学会将已经被破坏了的文章结构进行重构,使文章变回原来的样子。
Q1:BART 和 BERT 预训练时的函参设置有什么不同?
- 激活函数使用了 GeLUs 而不是 ReLU;
- 参数随机初始化使用的是均值为 0,方差为 0.02 的正态分布;
- BART_BASE 有 6 层编码器和解码器;BART_LARGE 有 12 层编码器和解码器,1024维的 hidden size,8000 个 batch size,迭代了 50 万步;
- 结合了 30% 的 Text-Infilling 和所有句子 Sentence Permutation 的两种噪声方式,在最后 10% 的 step 中停用 dropout,共使用160Gb的数据。
3 下游任务
文章提到了几种下游任务的微调过程:参考BART
3.1 分类任务(Sequence Classification Tasks)
思路和 BERT 的分类任务微调极其相似,但 Token 的选取是不一样的(因为在 BERT 中,是在输入序列的第一个位置添加了 [CLS] Token,最后输出取得是这个 [CLS],而 BART 是在最后一个位置添加的 [CLS],所以最后取得也是最后一个 Token)。
BART 将该序列同时输入给 Encoder 和 Decoder,然后取 Decoder 的最后一个 Token 所对应的 Hidden State 作为 Label,接上一个线性多分类器进行微调(注意在序列的最后要加一个 Token,保证 Seq2Seq 模型输出的 Label 包含序列中每一个 Token 的信息(因为 Decoder 的输入是 Right-Shifted 的,不这样做的话 Label 将不包含最后一个 Token 的信息)
文本分类示意图:
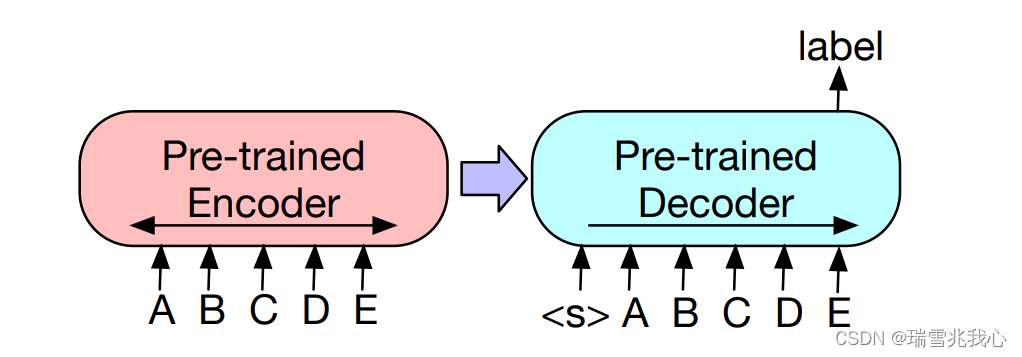
作者认为这样能使最后一个Token 的表示参考了前面所有 Token 的语义信息。
3.2 文本生成任务(Sequence Generation Tasks)
BART 本身就是在 Sequence2Sequence 的基础上构建,给模型一个原始文本和一个目标文本,编码器接收原始文本,解码器解码出预测文本,并和目标文本 ground truth 求损失,其天然比较适合做序列生成的任务(BART 的强项所在)。
3.3 机器翻译(Machine Translation)
将 BART 的 Encoder 端的 Embedding 层替换成 Randomly Initialized Encoder,新的 Encoder 也可以用不同的 Vocabulary。通过新加的 Encoder,可以将新的语言映射到 BART 能解码到 English(假设 BART 是在 English 的语料上进行的预训练)的空间。
机器翻译微调示意图:
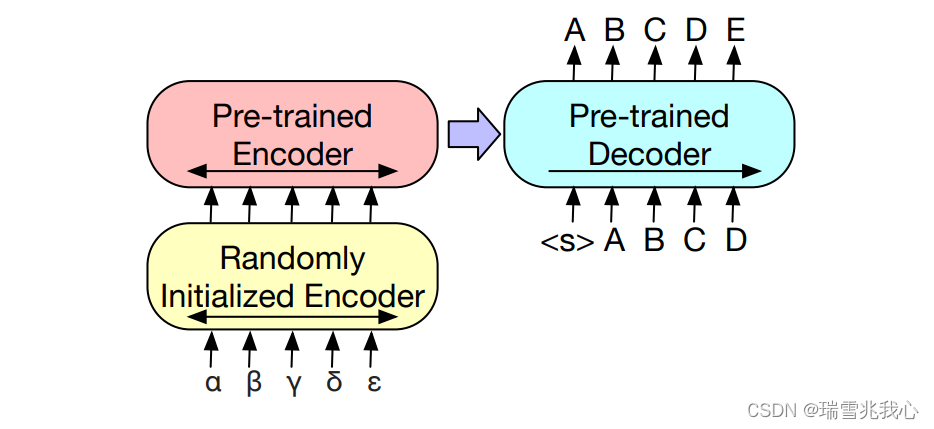
具体的 FineTune 的过程分为两个阶段:
- 第一步只更新 Randomly Initialized Encoder + BART Positional Embedding + BART的 Encoder 第一层的 Self-Attention 输入映射矩阵;
- 第二步更新全部参数,但是只训练很少的几轮。

