
- 1基于hadoop短视频数据爬虫可视化分析系统的设计与实现_可以在hadoop中完成网站数据爬取和数据处理最后完成可视化吗
- 2【git】git commit后如何撤销或修改_git在commit没有push的情况下删除变更
- 3STM32F103驱动VL53L0X激光测距模块_vl53l0x stm32
- 4如何在Ubuntu系统上安装Git_ubuntu如何安装git
- 505_解决mac百度网盘下载速度慢问题
- 6YOLOv5训练遇到的问题(上)_attributeerror: 'nonetype' object has no attribute
- 7什么是WePY?
- 8(器件应用)安全Cortex-M3闪存微控制器:MAX32561-LNJ、MAX32561-LBJ,超低功耗 MAX32664GWEZ、MAX32664GTGZ生物识别传感器集中器
- 92024最新最全【虚幻4引擎】下载安装零基础教程_ue4下载
- 10Linux永久挂载硬盘_linux永久挂载磁盘
Structured Streaming详解
赞
踩
一、Structured Streaming概述
(1)Structured Streaming背景
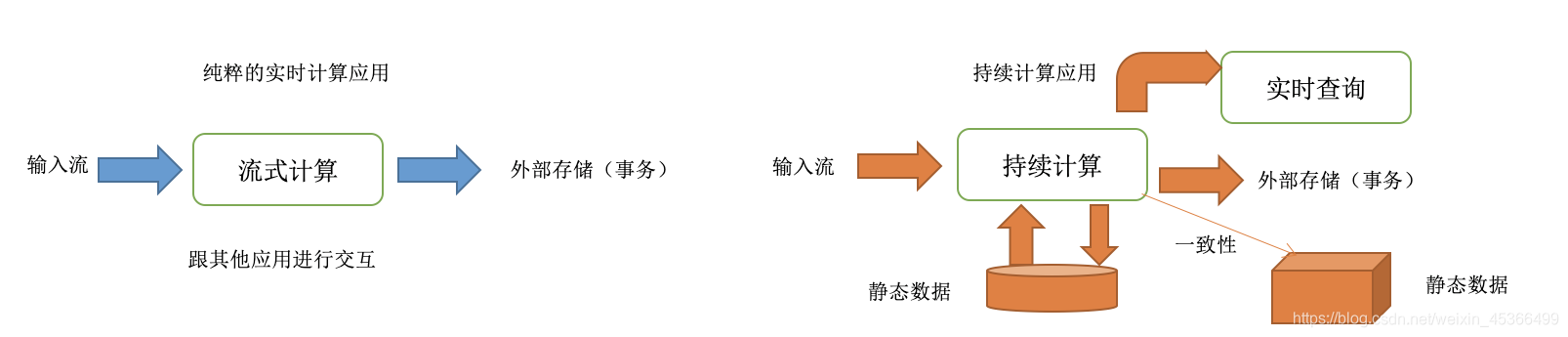
大多数的流式计算引擎(比如storm、spark streaming等)都仅仅关注流数据的计算方面:比如使 用一个map函数对一个流中每条数据都进行转换,或者是用reduce函数对一批数据进行聚合。但是, 实际上在大部分的流式计算应用中,远远不只是需要一个流式计算引擎那么简单。相反的,流式计 算仅仅在流式应用中占据一个部分而已。因此现在出现了一个新的名词,叫做 持续计算/应用 , continuous application。比如以下一些持续应用的例子:
1、更新需要以服务形式实时提供出去的数据:
例如,我们可能需要更新一份数据,然后其他用户会 通过web应用来实时查询这些数据。这种情况下,一个技术难题就是实时计算应用如何与实时数据服 务进行交互,比如说,当实时计算应用在更新数据的时候,如果用户通过实时数据服务来进行查询, 此时该如何处理?因此为了处理这种场景下的技术难题,就必须以一个完整的持续计算应用的方式 来构建整个系统,而不是站在实时计算的角度,仅仅考虑实时更新数据。
2、实时ETL(Extract、Transform和Load):
实时计算领域一个常见的应用就是,将一个存储系统中的数 据转换后迁移至另外一个存储系统。例如说,将JSON格式的日志数据迁移到Hive表中。这种场景下的技术 难题就在于,如何与两边的存储系统进行交互,从而保证数据不会丢失,同时也不会发生重复。这种协调 逻辑是非常复杂的。
3、为一个已经存在的批量计算作业开发一个对应的实时计算作业:
这个场景的技术难题在于,大多数的 流式计算引擎都无法保证说,它们计算出的结果是与离线计算结果相匹配的。例如说,有些企业会通过实 时计算应用来构建实时更新的dashboard,然后通过批量计算应用来构建每天的数据报表,此时很多用户 就会发现并且抱怨,离线报表与实时dashboard的指标是不一致的。
4、在线机器学习:
这类持续计算应用,通常都包含了大型的静态数据集以及批处理作业,还有实时数据 流以及实时预测服务等各个组件。
以上这些例子就表明了在一个大型的流式计算应用中,流式计算本身其实只是占据了一个部分而已, 其他部分还包括了数据服务、存储以及批处理作业。但是目前的现状是,几乎所有的流式计算引擎都仅仅 是关注自己的那一小部分而已,仅仅是做流式计算处理。这就使得开发人员需要去处理复杂的流式计算应 用与外部存储系统之间的交互,比如说管理事务,同时保证他们的流式计算结果与离线批处理计算结果保 持一致。这就是目前流式计算领域急需要解决的难题与现状。
持续计算应用可以定义为,对数据进行实时处理的整套应用系统。spark社区希望能够让开发人员仅仅使 用一套api,就可以完整持续计算应用中各个部分涉及的任务和操作,而这各个部分的任务和操作目前都 是通过分离的单个系统来完成的,比如说实时数据查询服务,以及与批处理作业的交互等。举例来说,未来对于解决这些问题的一些设想如下:
1、更新那些需要被实时提供服务的数据:
开发人员可以开发一个spark应用,来同时完成更新实时数据, 以及提供实时数据查询服务,可能是通过jdbc相关接口来实现。也可以通过内置的api来实现事务性的、 批量的数据更新,对一些诸如mysql、redis等存储系统。
2、实时ETL:
开发人员仅仅需要如同批处理作业一样,开发一样的数据转换操作,然后spark就可以自动 完成针对存储系统的操作,并且保证数据的一次且仅一次的强一致性语义。
3、为一个批处理作业开发一个实时版本:
spark可以保证实时处理作业与批处理作业的结果一定是一致的。
4、在线机器学习:
机器学习的api将会同时支持实时训练、定期批量训练、以及实时预测服务。
(2)Structured Streaming概念
Spark 2.0之后,引入的structured streaming,就是为了实现上述所说的continuous application,也就是持续计算的。首先,structured streaming是一种比spark更高级的api,主要是基于spark的批处理中的 高阶api,比如dataset/dataframe。此外,structured streaming也提供很多其他流式计算应用所无法提 供的功能:
1、保证与批处理作业的强一致性:
开发人员可以通过dataset/dataframe api以开发批处理作业的方式来 开发流式处理作业,进而structured streaming可以以增量的方式来运行这些计算操作。在任何时刻,流 式处理作业的计算结果,都与处理同一份batch数据的批处理作业的计算结果,是完全一致的。而大多数的 流式计算引擎,比如storm、kafka stream、flink等,是无法提供这种保证的。
2、与存储系统进行事务性的整合:
structured streaming在设计时就考虑到了,要能够基于存储系统保证数 据被处理一次且仅一次,同时能够以事务的方式来操作存储系统,这样的话,对外提供服务的实时数据才能在 任何时刻都保持一致性。目前spark 2.4版本的structured streaming,已经支持核心的外部存储服务。事务 性的更新是流式计算开发人员的一大痛点,其他的流式计算引擎都需要我们手动来实现,而structured streaming希望在内核中自动来实现。
3、与spark的其他部分进行无缝整合:
structured steaming已经提供了核心外部系统的整合集成的API。
二、Structured Streaming编程模型
(1)编程模型
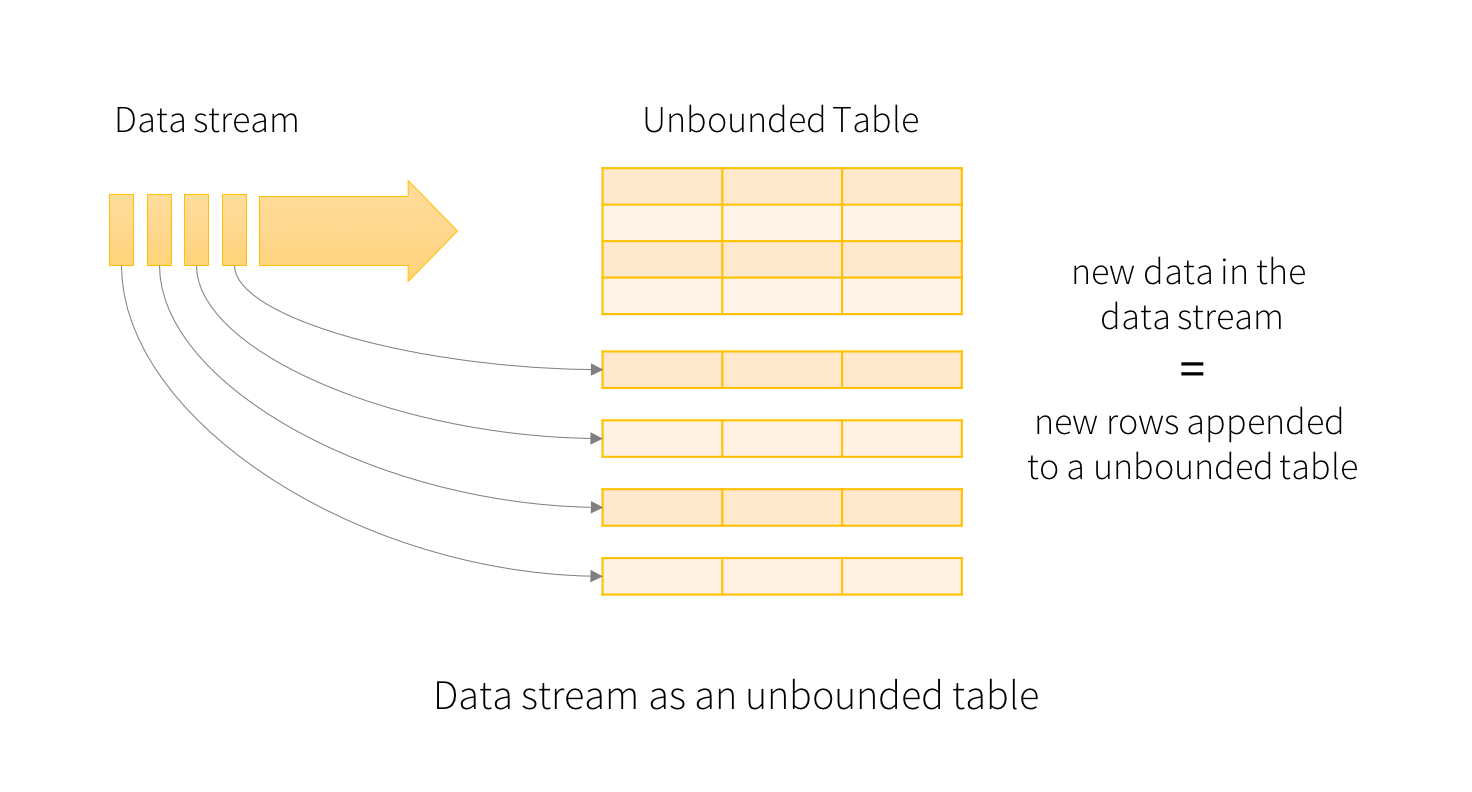
Structured Streaming的核心理念,就是将数据流抽象成一张表,而源源不断过来的数据是持续地 添加到这个表中的。 这就产生了一种全新的流式计算模型,与离线计算模型是很类似的。你可以使 用与在一个静态表中执行离线查询相同的方式来编写流式查询。spark会采用一种增量执行的方式 来对表中源源不断的数据进行查询。我们可以将输入数据流想象成是一张input table。数据流中 每条新到达的数据,都可以想象成是一条添加到表中的新数据。
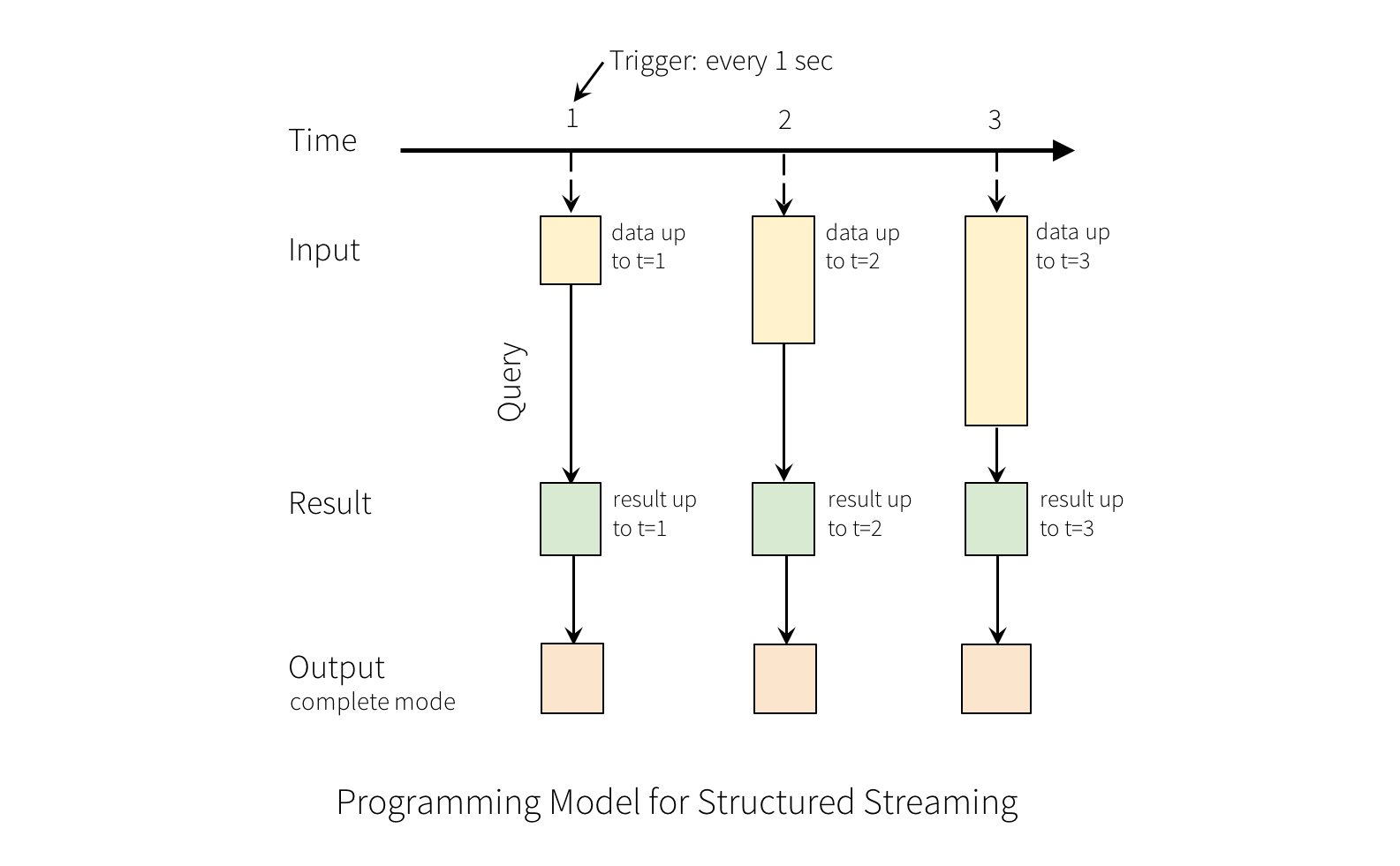
我们可以定义每次结果表中的数据更新时,以何种方式,将哪些数据写入外部存储。我们有多种模式的 output:
- complete mode: 被更新后的整个结果表中的数据,都会被写入外部存储。具体如何写入,是根据不 同的外部存储自身来决定的。
- append mode: 只有最近一次trigger之后,新增加到result table中的数据,会被写入外部存储。只 有当我们确定,result table中已有的数据是肯定不会被改变时,才应该使用append mode。
- update mode: 只有最近一次trigger之后,result table中被更新的数据,包括增加的和修改的,会 被写入外部存储中。
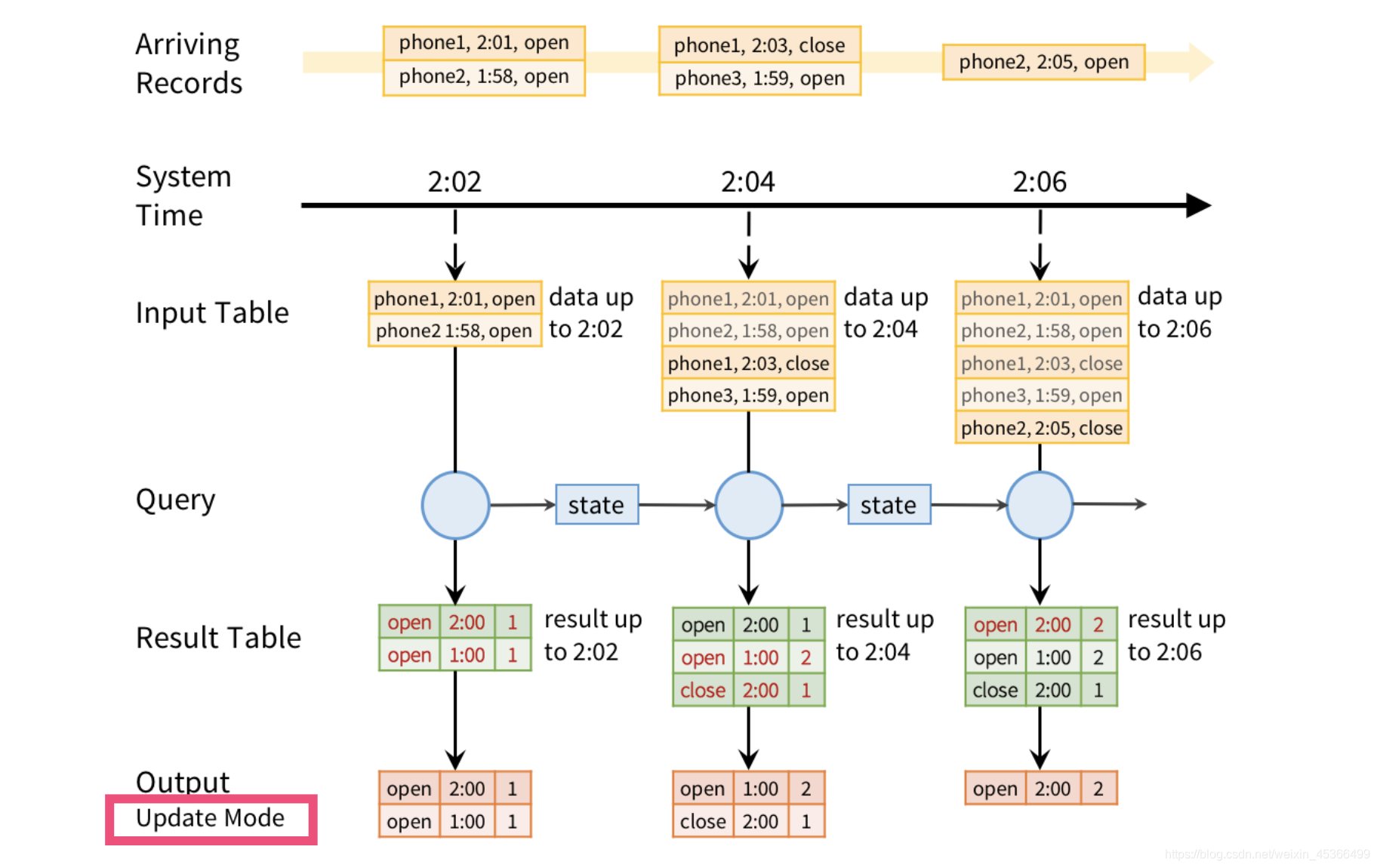
(2)EventTime
event-time指的是嵌入在数据自身内部的一个时间。在很多流式计算应用中,我们可能都需要根据 event-time来进行处理。例如,可能我们需要获取某个设备每分钟产生的事件的数量,那么我们就需要使 用事件产生时的时间,而不是spark接受到这条数据的时间。设备产生的每个事件都是input table中的一 行数据,而event-time就是这行数据的一个字段。这就可以支持我们进行基于时间窗口的聚合操作(例如 每分钟的事件数量),只要针对input table中的event-time字段进行分组和聚合即可。每个时间窗口就 是一个分组,而每一行都可以落入不同行的分组内。因此,类似这样的基于时间窗口的分组聚合操作,既 可以被定义在一份静态数据上,也可以被定义在一个实时数据流上。
此外,这种模型也天然支持延迟到达的数据,late-data。spark会负责更新result table,因此它有绝对 的控制权来针对延迟到达的数据进行聚合结果的重新计算。自Spark2.1之后Structured Streaming 开始支持 watermark(水印),允许用户指定延时数据的阈值,并允许引擎相应地清除阈值范围之外的旧状态。
(3)容错语义
Structured Streaming的核心设计理念和目标之一,就是支持一次且仅一次的语义。为了实现这个目标, structured streaming设计将source、sink和execution engine来追踪计算处理的进度,这样就可以在任 何一个步骤出现失败时自动重试。每个streaming source都被设计成支持offset,进而可以让spark来追 踪读取的位置。spark基于checkpoint和wal来持久化保存每个trigger interval内处理的offset的范围。 sink被设计成可以支持在多次计算处理时保持幂等性,就是说,用同样的一批数据,无论多少次去更新 sink,都会保持一致和相同的状态。这样的话,综合利用基于offset的source,基于checkpoint和wal的 execution engine,以及基于幂等性的sink,可以支持完整的一次且仅一次的语义。
三、基于WordCount程序讲解Structured Streaming编程模型
package com.kfk.spark.structuredstreaming; import com.kfk.spark.common.CommSparkSession; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Encoders; import org.apache.spark.sql.Row; import org.apache.spark.sql.SparkSession; import org.apache.spark.sql.streaming.StreamingQuery; import org.apache.spark.sql.streaming.StreamingQueryException; import java.util.Arrays; import java.util.Iterator; /** * @author : 蔡政洁 * @email :caizhengjie888@icloud.com * @date : 2020/12/21 * @time : 9:04 下午 */ public class WordCountJava { public static void main(String[] args) throws StreamingQueryException { SparkSession spark = CommSparkSession.getSparkSession(); // Create DataFrame representing the stream of input lines from connection to localhost:9999 Dataset<Row> lines = spark.readStream() .format("socket") .option("host", "bigdata-pro-m04") .option("port", 9999) .load(); // Split the lines into words Dataset<String> words = lines.as(Encoders.STRING()).flatMap(new FlatMapFunction<String, String>() { @Override public Iterator<String> call(String s) throws Exception { return Arrays.asList(s.split(" ")).iterator(); } },Encoders.STRING()); // Generate running word count Dataset<Row> wordCounts = words.groupBy("value").count(); // Start running the query that prints the running counts to the console StreamingQuery query = wordCounts.writeStream() .outputMode("complete") .format("console") .start(); query.awaitTermination(); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
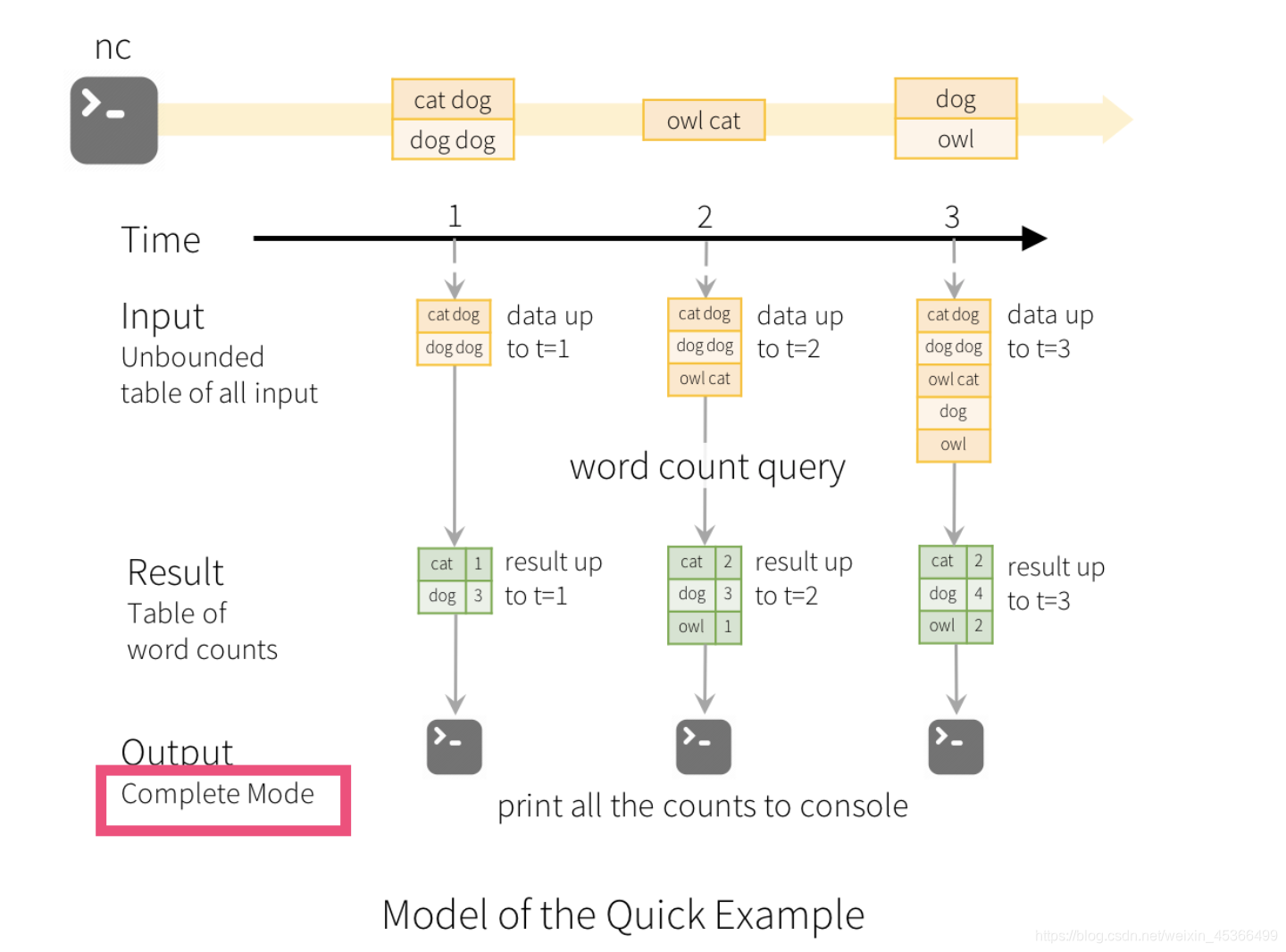
我们可以以wordcount例子作为背景来理解,lines dataframe是一个input table,而 wordcounts dataframe就是一个result table。当应用启动后,spark会周期性地check socket输入源中 是否有新数据到达。如果有新数据到达,那么spark会将之前的计算结果与新到达的数据整合起来,以增 量的方式来运行我们定义的计算操作,进而计算出最新的单词计数结果。
以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!

