
- 1PyFlink核心知识点_pyflink richsourcefunction
- 23038. 相同分数的最大操作数目 I(Rust模拟击败100%Rust用户)
- 3Git——本地分支&远程分支_本地分支和远程分支
- 4OneDrive 遇到的坑--0x8004deed,目前的免费网盘分析
- 5嵌入式技术学习——c51——串口_c51 rs485tong
- 6瑞典保险公司百万客户数据泄露_保险公司用户数据泄露
- 7git的push以及遇到冲突解决_git push 冲突解决办法
- 8最强开源模型来了!一文详解 Stable Diffusion 3 Medium 特点及用法_sd3微调模型
- 9机器人操作系统ROS(十):机器人建模URDF_urdf机器人建模
- 10HarmonyOS开发案例:【音乐播放器】_鸿蒙开发音乐播放器
数据挖掘实战1:泰坦尼克号数据
赞
踩
一、数据挖掘流程
1.数据读取
-读取数据
-统计指标
-数据规模
2.数据探索(特征理解)
-单特征的分析,诸个变量分析对结果y的影响(x,y的相关性)
-多变量分析(x,y之间的相关性)
-统计绘图
3.数据清洗和预处理
-缺失值填充
-标准化、归一化
-特征工程(筛选有价值的特征)
-分析特征之间的相关性
4.建模
-特征数据的准备和标签
-数据集的切分
-多种模型对比:交叉验证、调参(学习曲线,网格搜索)
-集成算法(提升算法)XGBoost、GBDT、light-GBM、神经网络(多种集成)
二、代码实现
1.数据读取
数据集可以去kaggle下载:Titanic - Machine Learning from Disaster | Kaggle。
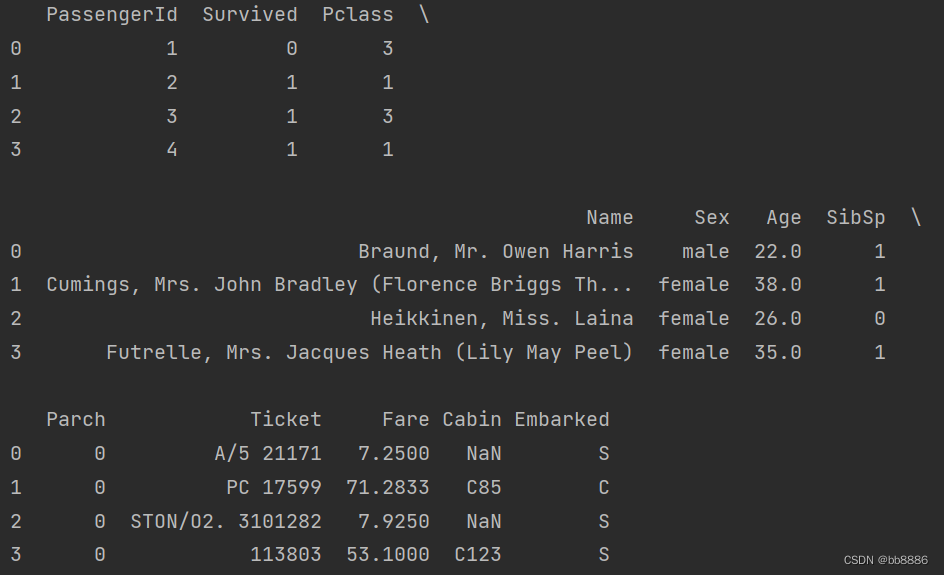
- data = pd.read_csv('./data/train.csv')
- pd.set_option('display.max_columns', 20)
- print(data.head(4))
print(data.info())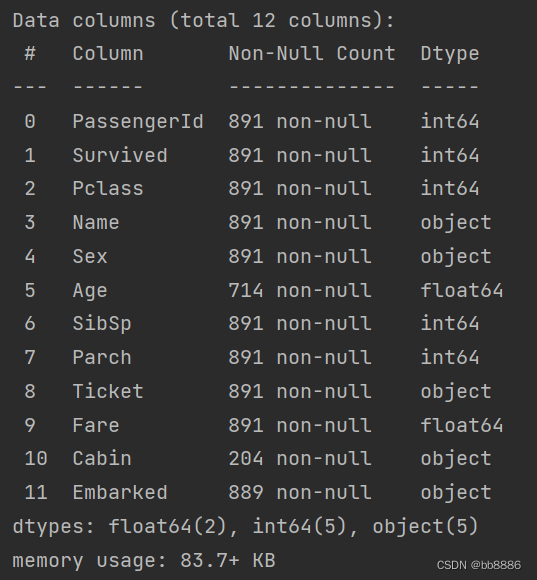
print(data['Survived'].value_counts()) # 当前列计数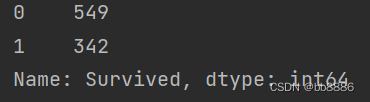
2、数据探索
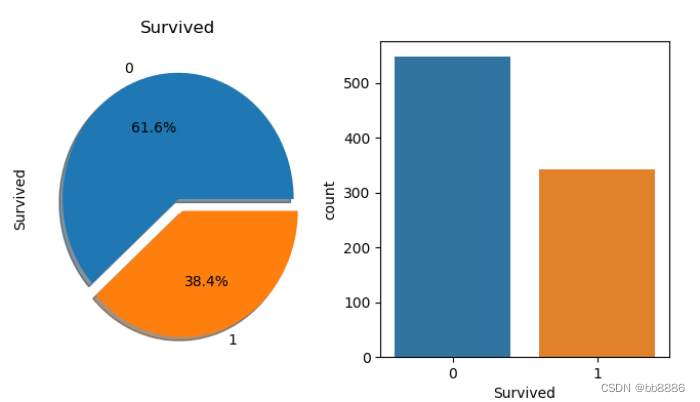
- # 标签比例 获救比例,饼图
- f, ax = plt.subplots(1, 2, figsize=(10, 6))
- data['Survived'].value_counts().plot.pie(explode=[0, 0.1], # 偏移量
- autopct='%1.1f%%', # 百分比保留小数位数
- ax=ax[0], shadow=True)
- ax[0].set_title('Survived') # 图一标题
- sns.countplot('Survived', saturation=0.75, # 饱和度
- data=data, ax=ax[1]) # 柱状图
- plt.show()
- # 男女获救比例
- print(data.groupby(['Sex', 'Survived'])['Survived'].count())
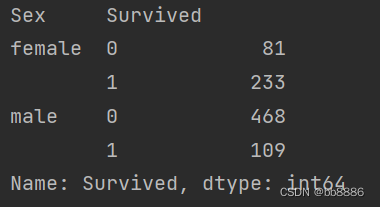
- sns.countplot('Sex', hue='Survived', data=data) # 柱状图
- plt.show()
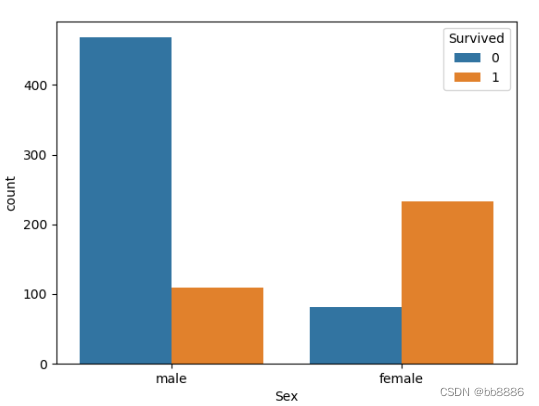
- # 船舱等级和获救之间的关系
- print(pd.crosstab(data['Pclass'], data['Survived'], margins=True))
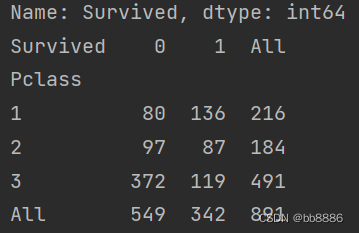
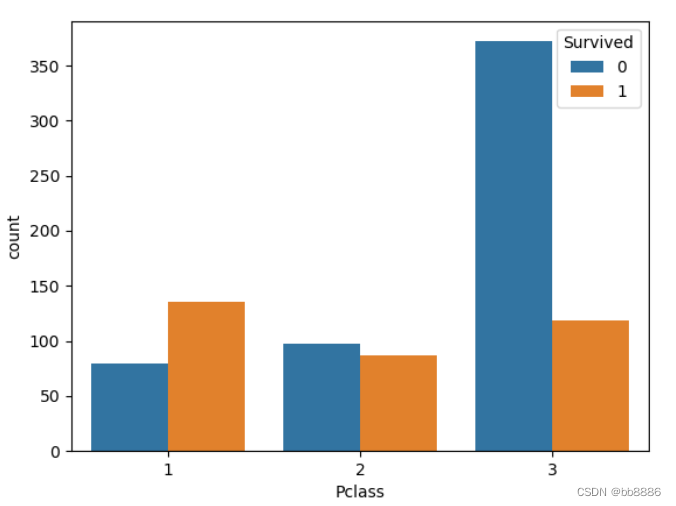
- sns.countplot('Pclass', hue='Survived', data=data)
- plt.show()
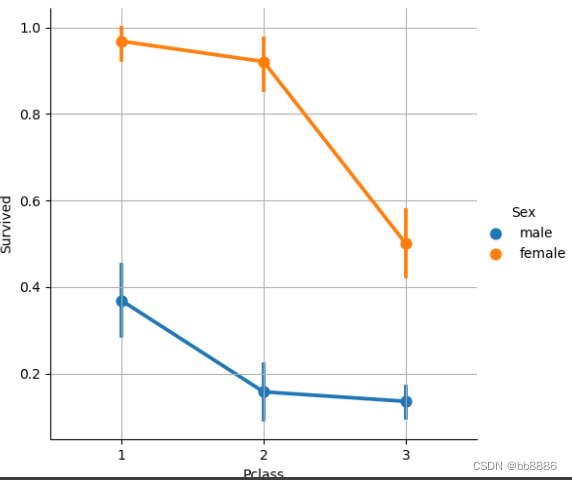
- # 不同性别及船舱等级和获救之间的关系
- print(pd.crosstab([data['Sex'], data['Survived']], data['Pclass'], margins=True))

- sns.factorplot('Pclass', 'Survived',
- hue='Sex', # 颜色
- data=data) # 降维画图
- plt.grid()
- plt.show()
3.数据清洗和预处理
3.1 提取性别身份,并将少数类归为其他
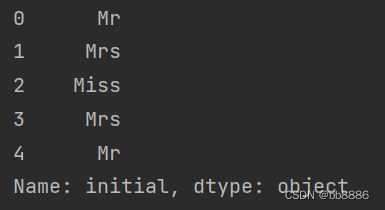
- data['initial'] = data['Name'].str.extract('([A-Za-z]+)\.') # 提取性别身份
- print(data['initial'].head(5))
print(pd.crosstab(data['initial'], data['Sex']).T)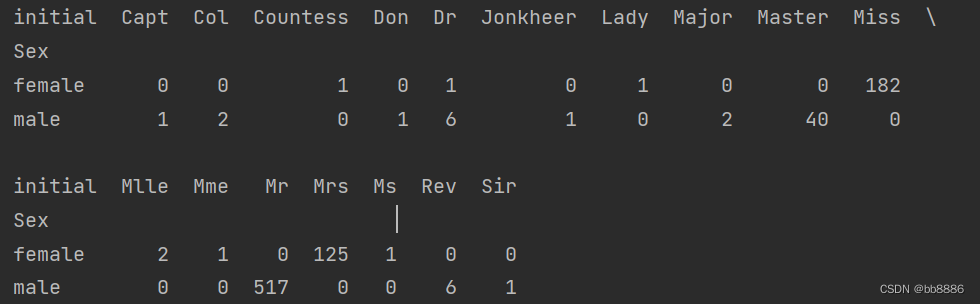
将少数的列变为other列。(除Master、Mr、Miss、Mrs外的其他列变为other列)
- def transformOther(str):
- if str != 'Master' and str != 'Miss' and str != 'Mr' and str != 'Mrs':
- str = 'other'
- return str
- data['re'] = data['initial'].apply(transformOther)
- print(data['re'].unique())
![]()
print(data.groupby('re')['Sex'].count())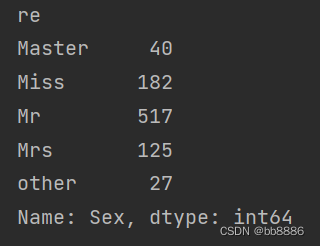
3.2 缺失值填充
3.2.1填补Age缺失值(用各性别下年龄均值去填补Age缺失值)
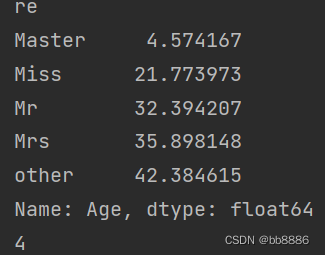
- # 各性别下年龄均值
- print(data.groupby('re')['Age'].mean())
- print(int(data.groupby('re')['Age'].mean()[0]))
- def FillNullAge(age):
- for str in data['re'].values:
- if np.isnan(age):
- age = int(data.groupby('re')['Age'].mean()[str])
- return age
-
- data['Age'] = data['Age'].apply(FillNullAge)
print(data['Age'].isnull().sum())![]()
3.2.2 填充港口数据
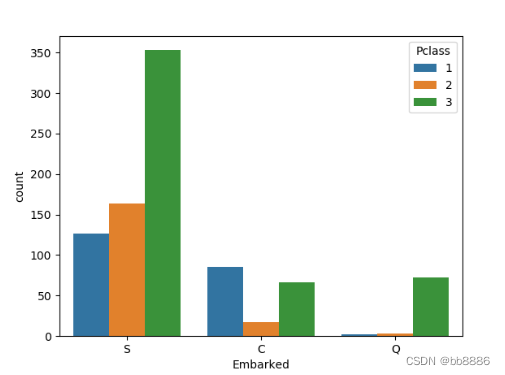
上船港口和船舱等级之间的关系。
- # 上船港口和船舱等级之间的关系
- print(pd.crosstab(data['Embarked'], data['Pclass'], margins=True))
- sns.countplot('Embarked', # 上船的港口
- hue='Pclass', data=data)
- plt.show()

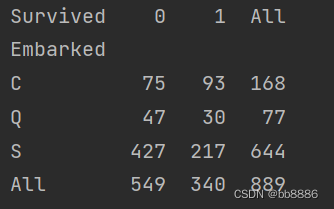
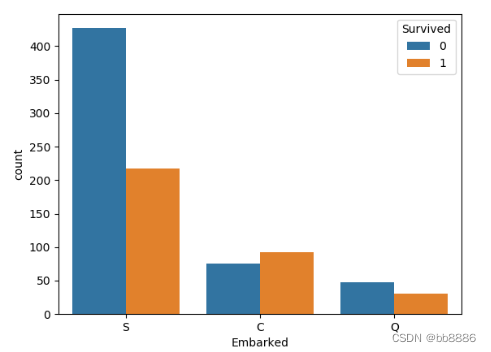
上船港口和获救之间的关系。
- # 上船港口和获救之间的关系
- print(pd.crosstab(data['Embarked'], data['Survived'], margins=True))
- sns.countplot('Embarked', hue='Survived', data=data)
- plt.show()
填补港口数据为s。
- data['Embarked'].fillna('s', inplace=True) # 填补港口数据
- print(data['Embarked'].isnull().any())

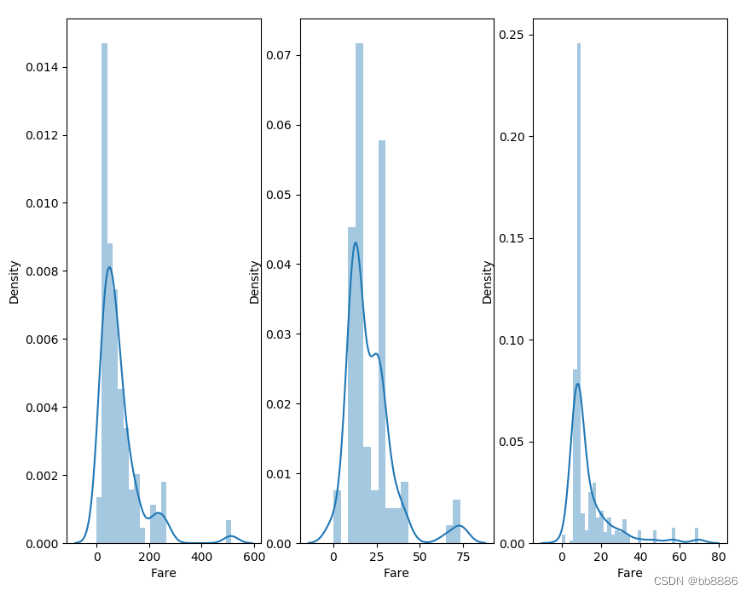
不同船舱的核密度估计图
- # 不同船舱的核密度估计图
- f, ax = plt.subplots(1, 3, figsize=(10, 8))
- sns.distplot(data[data['Pclass'] == 1].Fare, ax=ax[0])
- sns.distplot(data[data['Pclass'] == 2].Fare, ax=ax[1])
- sns.distplot(data[data['Pclass'] == 3].Fare, ax=ax[2])
- plt.show()
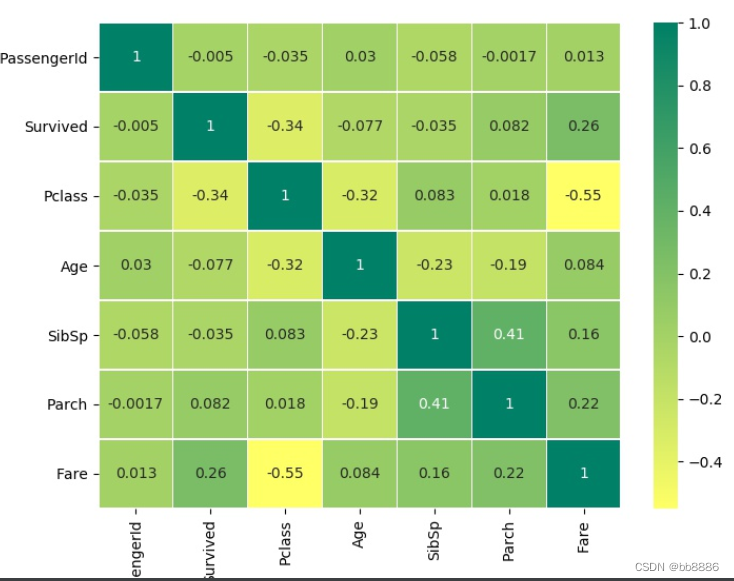
相关性热图
- # 相关性热图
- sns.heatmap(data.corr(), annot=True, linewidths=0.2, cmap='summer_r')
- fig = plt.gcf()
- fig.set_size_inches(8, 6)
- plt.savefig('heatmap.jpg')
3.3 数据处理
3.3.1 年龄分段(<16, 16< <32, 32< <48, 48< <65, >65)
- def AgeBand(age):
- if age <= 16:
- return 0
- elif age <= 32 and age > 16:
- return 1
- elif age <= 48 and age > 32:
- return 2
- elif age <= 65 and age > 48:
- return 3
- elif age >65:
- return 4
- data['Age_band'] = 0
- data['Age_band'] = data['Age'].apply(AgeBand)
- print(data.head(1))

3.3.2 数值化
- # 数值化(将Sex、Embarked、re列数值化)
- from sklearn import preprocessing
- lb = preprocessing.LabelEncoder()
- data['Sex'] = lb.fit_transform(data['Sex'])
- data['Embarked'] = lb.fit_transform(data['Embarked'])
- data['re'] = lb.fit_transform(data['re'])
- print(data.head(1))

哑变量:也叫虚拟变量,引入哑变量的目的是,将不能够定量处理的变量量化,在线性回归分析中引入哑变量的目的是,可以考察定性因素对因变量的影响。哑变量是人为虚设的变量,通常取值为0或1,来反映某个变量的不同属性。对于有n个分类属性的自变量,通常需要选取1个分类作为参照,因此可以产生n-1个哑变量。
print(data['Embarked'].unique()) # 哑变量![]()
将数值化的Embarked转换为one-hot编码。
- # 独热编码(将数值化的Embarked转换为one-hot编码)
- oh = preprocessing.OneHotEncoder(sparse=False)
- data['Embarked'] = oh.fit_transform(data[['Embarked']])
- print(data.head(2))
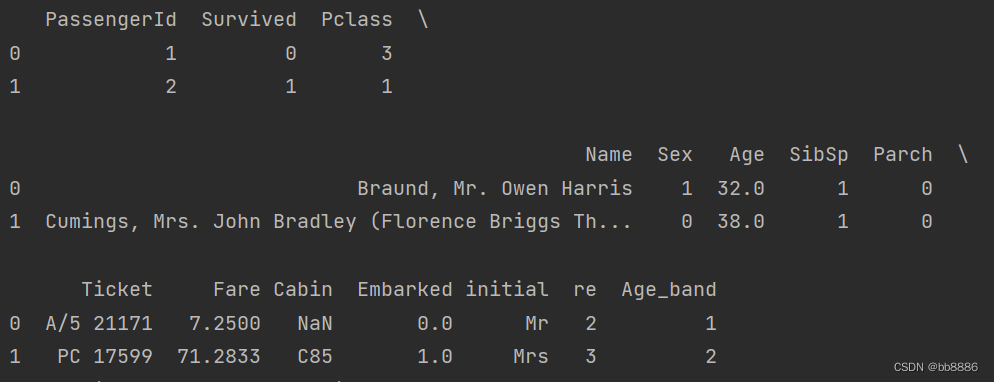
3.4 变量选择
- data.drop(['PassengerId', 'Name', 'Age', 'Ticket', 'Cabin', 'initial'], axis=1, inplace=True) # 删数据
- print(data.head(2))

4.建模预测幸存率。
导包
- from sklearn.linear_model import LogisticRegression, LinearRegression
- from sklearn.neighbors import KNeighborsClassifier
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.naive_bayes import GaussianNB, MultinomialNB, BernoulliNB
-
- from sklearn.model_selection import train_test_split
- from sklearn import metrics
- from sklearn.model_selection import cross_val_score
- from sklearn.metrics import confusion_matrix
划分数据集
- X = data.iloc[:, data.columns != 'Survived']
- y = data.iloc[:, data.columns == 'Survived']
- print(X.shape)
- print(y.shape)
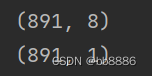
4.1 logistic(逻辑回归)
- # 逻辑回归
- l = LogisticRegression()
- l.fit(Xtrain, Ytrain)
- print(l.score(Xtest, Ytest))
![]()
- # 或者如下显示得分
- pre_l = l.predict(Xtest)
- print(metrics.accuracy_score(Ytest, pre_l))
![]()
4.2 knn近邻算法
- score = []
- for i in list(range(1, 11)):
- KNN = KNeighborsClassifier(n_neighbors=i)
- CVS = cross_val_score(KNN, Xtrain, Ytrain, cv=5)
- score.append(CVS.mean())
- # 绘图 knn算法选取的1-10的近邻与评价分数的折线图
- plt.plot([*range(1, 11)], score)
- fig = plt.gcf()
- fig.set_size_inches(12, 6)
- plt.show()

从图中可以看到,当k=3时,评价分数最高,模型效果最好。
- KNN = KNeighborsClassifier(n_neighbors=3)
- KNN.fit(Xtrain, Ytrain)
- print(KNN.score(Xtest, Ytest))
-
- pred_KNN = KNN.predict(Xtest)
- print(metrics.accuracy_score(Ytest, pred_KNN))

4.3 网格搜索
超参数:不是训练得到的,但是在训练时又需要预先给定的这样的变动的参数,即为超参数。
网格搜索:用于调参的方法,网格搜索是一种穷举的调参方式,循环遍历每个自由超参数的每一种可能性,每组参数值都会得到对应的一个模型。
- from sklearn.model_selection import GridSearchCV
- # 设置可选参数
- param_grid = {
- 'criterion': ['entropy', 'gini'],
- 'max_depth': range(2, 10),
- 'min_samples_leaf': range(1, 10),
- 'min_samples_split': range(2, 10)
- }
- # 设置网格
- # 创建网格对象,默认以R的平方评价拟合的好坏,本节以决策树去拟合
- GR = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=5) # cv表示交叉验证的折叠数
- # 建模 训练数据
- GR.fit(Xtrain, Ytrain)
-
- # 输出接口
- print(GR.best_params_)

- # 分数
- print(GR.best_score_)
![]()
4.4 决策树
- DTC = DecisionTreeClassifier(criterion='entropy', max_depth=6,
- min_samples_leaf=6,
- min_samples_split=4)
- DTC.fit(Xtrain, Ytrain)
- print(DTC.score(Xtest, Ytest))
- print(DTC.feature_importances_)
机器学习中特征重要性feature_importances_: 变量的重要性,在线性模型中,我们有截距和斜率参数。目前而言,这个参数好像只有在决策树和以决策树为基础的算法有。

- # 绘图(特征重要性的柱状图)
- f = plt.figure(figsize=(4, 4))
- DTC_series = pd.Series(DTC.feature_importances_, X.columns).sort_values(ascending=True)
- print(DTC_series)
- DTC_series.plot.barh(width=0.8)
- plt.show()

4.5 ROC曲线
ROC曲线含义:即Receiver Operating Characteristic Curve,受试者工作特征曲线。
以FPR(假正率)为横坐标、TPR(真正率)为纵坐标,将每一个阈值所对应的(FPR,TPR)放入坐标系中。用线条将所有的点连接起来——此即为ROC曲线。
ROC曲线的用途:阈值选择和模型比较。
AUC:即Area Under Curve,ROC曲线下的面积。
- 1.AUC在0.5和1之间。
- 2.在AUC>0.5的情况下,AUC越接近于1,说明效果越好。
AUC在0.5~0.7时有较低准确性,
AUC在0.7~0.9时有一定准确性,
AUC在0.9以上时有较高准确性。
- 3.AUC小于等于0.5时,说明该方法完全不起作用。
绘制决策树模型的roc曲线。
- # 绘制决策树模型的roc曲线
- y_pred =DTC.predict(Xtest)
- from sklearn.metrics import roc_curve, auc
- # 计算真正率 假正率
- fpr, tpr, threshold = roc_curve(Ytest, y_pred)
- # 计算AUC
- roc_auc = auc(fpr, tpr)
- plt.figure(figsize=(8, 8))
- plt.plot(fpr, tpr, color='darkorange',
- label='ROC curve (area=%0.2f)' % roc_auc)
- plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
- plt.xlim([0.0, 1.0])
- plt.ylim([0.0, 1.05])
- plt.xlabel('False Positive Rate')
- plt.ylabel('True Positive Rate')
- plt.title('Receiver operating characteristic example')
- plt.legend(loc='lower right')
- plt.show()


从上图可以看出:AUC值等于0.8,说明效果较好。
4.6 混淆矩阵
定义:混淆矩阵是用来总结一个分类器结果的矩阵。对于k元分类,其实它就是一个k x k的表格,用来记录分类器的预测结果。对于最常见的二元分类来说,它的混淆矩阵是2乘2的,如下:
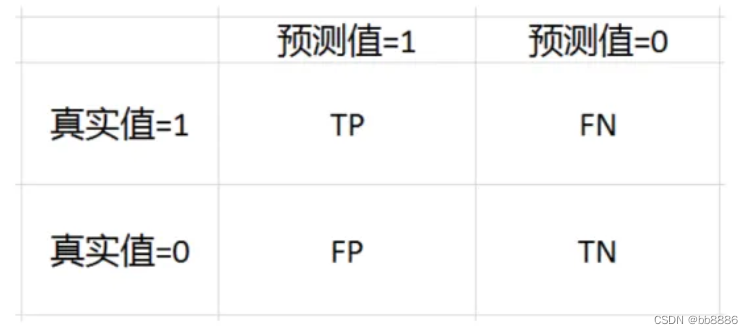
混淆矩阵的作用:
1)用于观察模型在各个类别上的表现,可以计算模型对应各个类别的准确率,召回率;
2)通过混淆矩阵可以观察到类别直接哪些不容易区分,比如A类别中有多少被分到了B类别,这样可以有针对性的设计特征等,使得类别更有区分性;
- plt.figure(figsize=(4, 4))
- KNN = KNeighborsClassifier(n_neighbors=3)
- KNN.fit(Xtrain, Ytrain)
- y_pred = KNN.predict(Xtest)
- sns.heatmap(confusion_matrix(Ytest, y_pred), annot=True, fmt='2.0f') # 展示分类结果的精度
- plt.show()
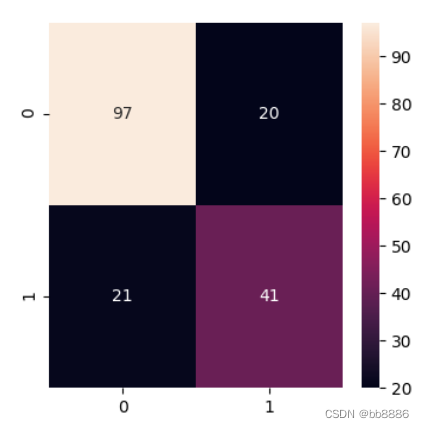
4.7 集成算法--装袋法
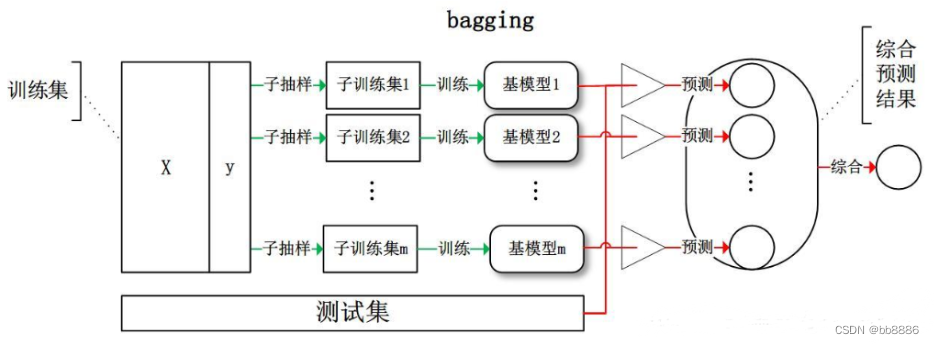
集成算法:集成学习(ensemble learning)本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务,所以常常比单一学习器具有更为显著的泛化性能。根据个体学习器的生成方式,目前的集成学习主要可以分为两类:①个体学习器之间存在强依赖关系、必须串行生成的序列化方法,代表是Boosting;②个体学习器之间不存在强依赖关系、可同时生成并行化方法,代表是Bagging和随机森林。
装袋法:Bagging算法,又称装袋算法,是机器学习领域的一种集成学习算法。bagging采用了一种有放回的抽样方法来生成训练数据。通过多轮有放回的对初始训练集进行随机采样,多个训练集被并行化生成,对应可训练出多个基学习器(基学习器间不存在强依赖关系),再将这些基学习器结合,构建出强学习器。其本质是引入了样本扰动,通过增加样本随机性,达到降低方差的效果。
bagging原理:
bagging与随机森林的区别:
随机森林(RF)是Bagging的一个改进版本:RF在以决策树为基学习器构建一个Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。
“随机”森林:
(1)样本选取随机。对于m个样本的原始训练集,我们每次先随机采集一个样本放入采样集,接着把该样本放回,也就是说下次采样时该样本仍有可能被采集到,这样采集m次,最终可以得到m个样本的采样集,由于是随机采样,这样每次的采样集是和原始训练集不同的,和其他采样集也是不同的,这样得到多个不同的弱学习器。
(2)节点选取随机。传统决策树在选择划分属性时是在当前结点的属性集合中选择一个最优属性(根据信息增益、增益率等准则),而在RF中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含K个属性的子集,然后再从这个子集中选择一个最优属性用于划分。这里的参数k控制了随机性的引入程度,推荐k=log(d)。
- from sklearn.ensemble import BaggingClassifier
- model = BaggingClassifier(base_estimator=DTC, # 装袋算法,是一种集成算法
- n_estimators=700,
- random_state=10)
- model.fit(Xtrain, Ytrain)
- print(model.score(Xtest, Ytest))
![]()

