
- 1ComfyUI中使用 SD3 模型(附模型下载详细说明)_comfyui sd3
- 2ChatGLM4重磅开源! 连忙实操测试一波,效果惊艳,真的好用!_chatglm4 开源发布时间
- 310款国内可用的AI工具分享,每一款都能让你工作效率翻倍_魔术todo任务分解
- 4普通人也能搞的,0成本,热门副业AI绘画,月入1w+_2024年0成本如何日入10000
- 5聚类模型的算法性能评价
- 6NLP综述:知识脉络图、四大类任务【序列标注(分词、词性标注、NER)、分类任务(文本分类、情感分析)、句子关系判断(顺序判断、相似度计算)、生成式任务(机器翻译、问答 、文本摘要)】_图书馆nlp标注 脉络洞察
- 7百度云不限速客户端让你获取SVIP速度_加速链接获取中啥意思
- 8C++11 智能指针详解_c++ 11所有的智能指针
- 9大模型入门指南:基本技术原理与应用_大模型原理
- 10Kafka和Spark Streaming的组合使用学习笔记(Spark 3.5.1)_2. kafka和structured streaming组合使用 (1)编写生产者程序每1秒生成一
数据挖掘 泰坦尼克号数据集分析
赞
踩
一、分析目的:
(1) 可视化数据集中的Pclass属性,Sex属性,Age属性,SibSp属性,Fare属性和Embarked属性;
(2)考虑以下问题 , 可使用中心趋势度量和离散度度量进行分析:
1)年龄与生存情况之间的关系是什么?
2)性别与生存情况之间的关系是什么?
3)社会地位与生存情况之间的关系是什么?
4)为什么有些票的价格很高?票价的高低与哪些属性有关?
二、导入数据集
使用pd.read_csv()读入数据集,使用print(data_train.info())打印数据集基本信息,结果如下图所示:

从中可以看出Age, Cabin, Embarked属性存在缺失值。但本次实验只是为了数据分析,故不进行缺失值处理。
其中,PassengerId, Name, Ticket, Cabin, Embarked为标称属性;Survived, Sex为 二元属性;Pclass为序数属性;Age, SibSp, Parch, Fare为数值属性。
三、可视化相关属性
1. 可视化Pclass属性
Pclass一共有三个可能取值,分别为1, 2, 3。使用柱状图进行可视化。
2. 可视化Sex属性
Sex一共有两个可能取值,分别为male和female。使用柱状图进行可视化。
3. 可视化Age属性
Age属于连续型属性,使用直方图进行可视化。
4. 可视化SibSp属性
SibSp属于连续型属性,使用直方图进行可视化。
5. 可视化Fare属性
Fare属性最大值最小值差别很大,怀疑存在异常值,使用箱线图进行可视化。
6. 可视化Embarked属性
Embarked一共有三个可能取值,分别为C, P, Q。使用柱状图进行可视化。
对六个属性可视化结果如下图所示:
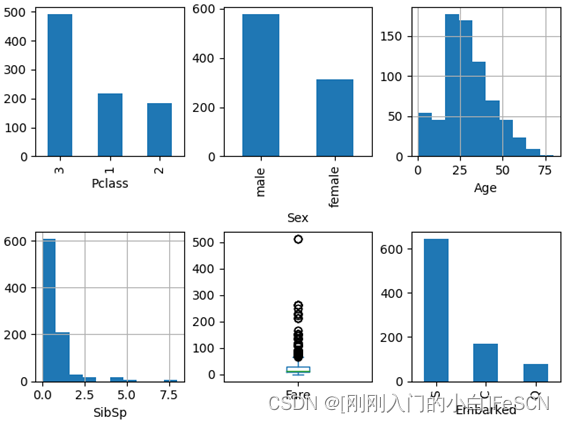
由图可知,1)乘客中来自3阶级的人数大于来自1阶级的人数大于来自2阶级的人数,2)乘客中男性人数明显高于女性人数,3)大部分乘客为年轻人,4)绝大多数乘客只有0或1位的兄弟姐妹或配偶在船上,5)船票平均价格在50以下,但仍有500左右的船票价格存在,6)上船地点人数S>C>Q。
实现可视化的代码如下:
- 1. plt.figure(constrained_layout=True)
- 2.
- 3. plt.subplot2grid((2, 3), (0, 0))
- 4. data_train['Pclass'].value_counts().plot(kind='bar')
- 5.
- 6. plt.subplot2grid((2, 3), (0, 1))
- 7. data_train['Sex'].value_counts().plot(kind='bar')
- 8.
- 9. plt.subplot2grid((2, 3), (0, 2))
- 10. data_train['Age'].hist()
- 11. plt.xlabel('Age')
- 12.
- 13. plt.subplot2grid((2, 3), (1, 0))
- 14. data_train['SibSp'].hist()
- 15. plt.xlabel('SibSp')
- 16.
- 17. plt.subplot2grid((2, 3), (1, 1))
- 18. data_train['Fare'].plot(kind='box')
- 19.
- 20. plt.subplot2grid((2, 3), (1, 2))
- 21. data_train['Embarked'].value_counts().plot(kind='bar')
- 22.
- 23. plt.show()

四、相关性分析
1. 年龄与生存情况
计算年龄的均值、中位数和众数并打印,发现年龄均值约为30,中位数为28,众数为24。

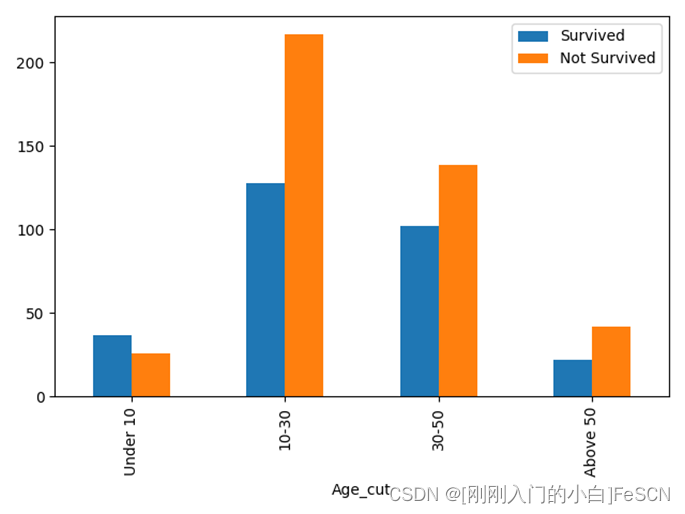
由于年龄均值为30,所以根据年龄划分为10岁以下、10-30岁、30-50岁、大于50岁四组,使用柱状图展示各年龄段中获救与未获救人数之间的关系,可视化结果如下图所示:
计算各年龄层生存率并打印结果:
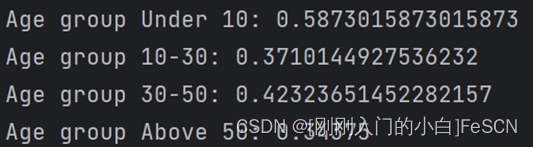
由此可以发现,10岁以下的乘客存活率最高,50岁以上的乘客存活率最低;小于平均年龄的乘客存活率高于大于平均年龄乘客的存活率。
实现可视化及相关数据打印的代码如下:
- 1. bins = [min(data_train['Age']), 10, 30, 50, max(data_train['Age'])]
- 2. bins_label = ['Under 10', '10-30', '30-50', 'Above 50']
- 3. #bins = [min(data_train['Age']), mean_age, max(data_train['Age'])]
- 4. #bins_label = ['Under mean_age', 'Above mean_age']
- 5. data_train['Age_cut'] = pd.cut(data_train['Age'], bins=bins, labels=bins_label)
- 6. # print(data_train['Age_cut'].value_counts())
- 7.
- 8. Age_0 = data_train.loc[data_train['Survived'] == 0, 'Age_cut'].value_counts()
- 9. Age_1 = data_train.loc[data_train['Survived'] == 1, 'Age_cut'].value_counts()
- 10. df_age = pd.DataFrame({'Survived':Age_1, 'Not Survived':Age_0})
- 11. df_age.plot(kind='bar')
- 12. for index, row in df_age.iterrows():
- 13. survived = row['Survived']
- 14. not_survived = row['Not Survived']
- 15. survival_rate = survived / (survived + not_survived)
- 16. print(f"Age group {index}: {survival_rate}")
- 17.
- 18. plt.tight_layout()
- 19. plt.show()
2. 性别与生存情况
使用柱状图绘制存活/非存活乘客中男性和女性的数量,可视化结果如下图所示:

由此可看出,未获救乘客中男性占比较大,而获救乘客中女性占比较大。
实现可视化的代码如下:
- 1. Survived_m = data_train.loc[data_train['Sex'] == 'male', 'Survived'].value_counts()
- 2. Survived_f = data_train.loc[data_train['Sex'] == 'female', 'Survived'].value_counts()
- 3. df_sex = pd.DataFrame({'Male':Survived_m, 'Female':Survived_f})
- 4. df_sex.plot(kind='bar', stacked=True)
- 5. plt.show()
3. 社会地位与生存情况
使用柱状图绘制不同阶级中存活/非存活乘客的数量,可视化结果如下图所示:

由此可看出,阶级1乘客获救率最高,甚至获救人数超过了未获救人数;阶级2乘客中未获救人数略高于获救人数;阶级3乘客中未获救人数远高于获救人数。
实现可视化的代码如下:
- 1. Pclass_0 = data_train.loc[data_train['Survived'] == 0, 'Pclass'].value_counts()
- 2. Pclass_1 = data_train.loc[data_train['Survived'] == 1, 'Pclass'].value_counts()
- 3. df_pclass = pd.DataFrame({'Survived':Pclass_1,'Not survived':Pclass_0})
- 4. df_pclass.plot(kind='bar')
- 5. plt.show()
4. 票价高低
由2.中箱线图结果发现,票价有高达500的异常值,也有低到0的值存在。推测极端值中,0可能是员工票或优惠票,极大值可能是最上等船舱的票价。
计算各属性之间的相关系数并使用热力图显示各属性之间的相关性。其中,PassengerId, Name, Ticket唯一确定,不进行相关性分析;Cabin属性缺失过多,不作考虑;在进行计算之前需要对Sex和Embarked属性进行One-Hot编码。
热力图结果如下:

打印相关系数矩阵,结果如下:
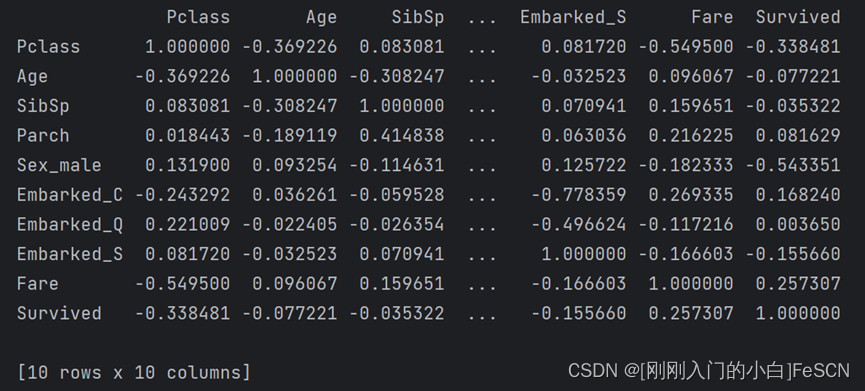
关察热力图最后一列及矩阵最后一列可发现,是否存活与性别相关性最大,其次与社会地位相关性也较大。
观察热力图倒数第二列及矩阵倒数第二列可发现,船票价格与社会地位相关性最大,与年龄相关性最小,与其他属性相关性都不算大。
实现可视化相关代码如下:
- 1. import seaborn as sns
- 2.
- 3. df_encoded = pd.get_dummies(data_train, columns=['Sex', 'Embarked'], drop_first=False)
- 4. print(df_encoded)
- 5. df_encoded = df_encoded[['Pclass', 'Age', 'SibSp', 'Parch', 'Sex_male', 'Embarked_C', 'Embarked_Q', 'Embarked_S', 'Fare', 'Survived']]
- 6. # 属性间相关系数
- 7. cor = df_encoded.corr()
- 8. print(cor)
- 9. # 属性间相关系数热力图
- 10. sns.heatmap(cor)
- 11. plt.show()
五、总结与结论
- 乘客中来自3阶级的人数大于来自1阶级的人数大于来自2阶级的人数;乘客中男性人数明显高于女性人数;大部分乘客为年轻人,平均年龄为30;绝大多数乘客只有0或1位的兄弟姐妹或配偶在船上;船票平均价格在50以下,但仍有500左右的船票价格存在;上船地点人数S>C>Q。
- 10岁以下的乘客存活率最高,50岁以上的乘客存活率最低;小于平均年龄的乘客存活率高于大于平均年龄乘客的存活率。
- 未获救乘客中男性占比较大,而获救乘客中女性占比较大。
- 阶级1乘客获救率最高,甚至获救人数超过了未获救人数;阶级2乘客中未获救人数略高于获救人数;阶级3乘客中未获救人数远高于获救人数。
- 船票价格极端值中,0可能是员工票或优惠票,极大值可能是最上等船舱的票价。
- 是否存活与性别相关性最大,其次与社会地位相关性也较大。
- 船票价格与社会地位相关性最大,与年龄相关性最小,与其他属性相关性都不算大。

