
- 1将Android手机打造成你的python开发者桌面#华为云·寻找黑马程序员#_termux无法刷流量
- 2干货分享:AI绘图学习心得-Midjourney绘画AI,让你的AI绘画之路少走弯路_ai绘画课程总结
- 3Oracle 数据库中 查询时如何使用日期(时间)作为查询条件_oracle 时间条件
- 4用python实现简易图书管理系统_python图书管理系统代码_图书管理系统python
- 5软件工程电商系统数据库定义_电子商务网站建立系统数据库
- 6程序员不得不收藏的十二个网站_uisources 会员
- 7【Java探索之旅】我与Java的初相识(二):程序结构与运行关系和JDK,JRE,JVM的关系_java编译与运行结构
- 8图解TCP/IP_图解tcpip
- 9【MySQL调优】如何进行MySQL调优?从参数、数据建模、索引、SQL语句等方向,三万字详细解读MySQL的性能优化方案(2024版)_mysql 临时表代替子查询
- 10域名注册后能改吗?
计算机视觉基础--特征提取_r2live视觉特征提取是怎么获取特征深度的
赞
踩
1.直方图均衡化
直方图:在图像处理中,经常用到直方图,如颜色直方图、灰度直方图等
图像的灰度直方图就描述了图像中灰度分布的情况,能够很直观的展示出图像中各个灰度级所占的多少
图像的灰度直方图是灰度级的函数,描述的是图像中具有该灰度级的像素的个数,其中,横坐标是灰度级,纵坐标是该灰度级出现的频率。
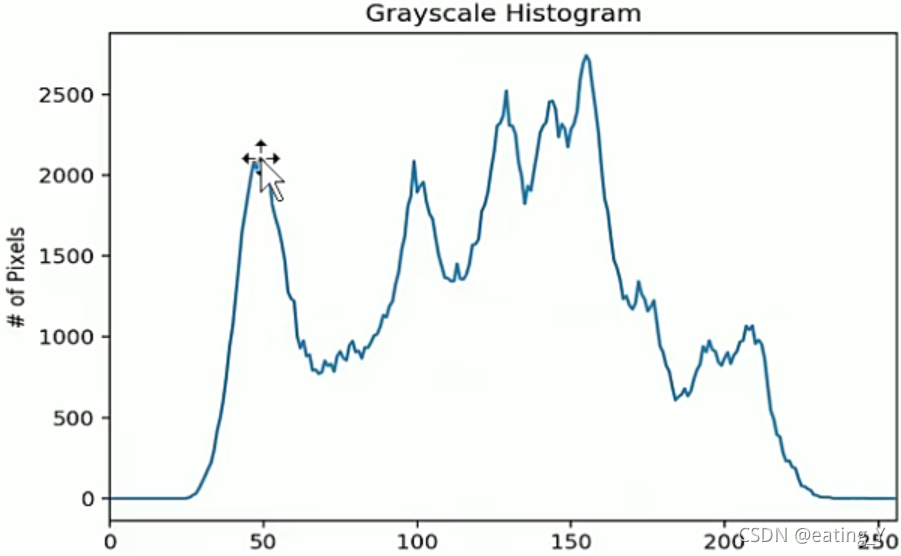
直方图的性质
- 直方图反映了图像中的灰度分布规律。他描述每个灰度级具有的像素个数,但不包含这些像素在图像中的位置信息。图像直方图不关心像素所处的空间位置,因此不受图像旋转和平移变化的影响,可以作为图像的特征。
- 任何一幅特定的图像都有唯一的直方图与之对应,但不同的图像可以有相同的直方图
- 如果一幅图像有两个不相连的区域组成,并且每个区域的直方图已知,则整幅图像的直方图是这两个区域的直方图之和

代码:




直方图均衡化:将原图像的直方图通过变换函数变为均匀的直方图,然后按均匀直方图修改原图像,从而获得一幅灰度分布均匀的新图像。直方图均衡化就是用一定的算法使直方图大致平和的方法
直方图均衡化的作用使图像增强

为了将原图像的亮度范围进行扩展,需要一个映射函数,将原图像的像素值均衡映射到新直方图中,这个映射函数有两个条件:
1)为了不打乱原有的顺序,映射后亮、暗的大小关系不能改变
2)映射后必须在原有的范围内,比如(0-255)
步骤:
a.依次扫描原始灰度图像的每一个像素,计算出图像的灰度直方图H
b.计算灰度直方图的累加直方图
c.根据累加直方图的直方图均衡化原理得到输入与输出之间的映射关系
d.最后根据映射关系得到结果:dst(x,y)=H‘(src(x,y))进行图像变化
具体计算步骤:
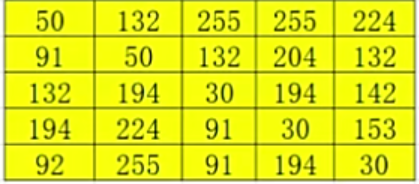
1)对于输入图像的任意一个像素p,p属于[0,255],总能在输出图像里有对应的像素q,q属于[0,255]使得下面的累加直方图等式成立(输入和输出的像素总量相等):
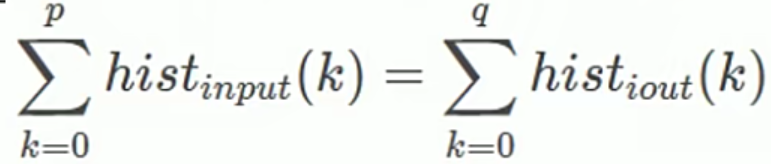 2)其中,输出图像每个灰度级的个数:
2)其中,输出图像每个灰度级的个数: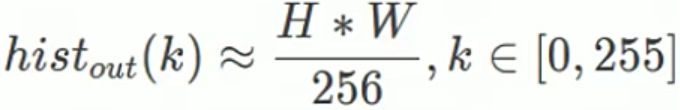
3)代入累加直方图公式:

手推过程:
公式:
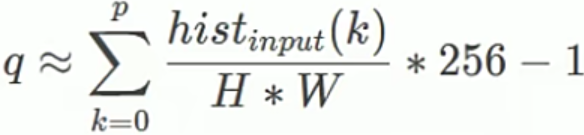
输入图像:


注:Ni 表示各个像素值的个数
输出图像:
代码:

2.卷积&滤波
滤波:全称为线性滤波,是图像处理最基本的方法,它可以允许我们对图像进行处理,产生很多不同的效果
卷积的原理与滤波类似,但是卷积却有着细小的差别
卷积操作也是卷积核与图像对应位置的乘积和。但是卷积操作
在做乘积之前,需要先将卷积核翻转180度,之后再做乘积。
对于滤波器,也有一定规则要求:
1)滤波器的大小应该是奇数,这样他才有一个中心,例如3x3,5x5或
7x7。有中心了,也有了半径的称呼,例如5x5大小的核的半径就是2。
2)滤波器矩阵所有的元素之和应该要等于1,就是为了保证滤波前后图像的亮度保持不变。但这不是硬性要求。
3)如果滤波器矩阵所有元素之和大于1,那么滤波后的图像就会比原图像更亮,繁殖,如果小于1,那么得到的图像就会变暗。如果和为0,图像不会变黑,但是会非常暗。
4)对于滤波后的结构,可能会出现负数或者大于255的数值。对于这种情况,我们将他们直接截断到0和255之间即可。对于负数,也可以取绝对值。
在具体应用中,往往有多个卷积核,可以认为,每个卷积核代表了一种图像模式。
如果某个图像块与此卷积核出的值大,则认为此卷积块十分接近于此卷积核。
例如,如果我们设计了6个卷积核,可以理解:我们认为这个图像上有6种底层纹理模型,也就是我们用6种基础模型就能描绘出一幅图像。
卷积可以提取边缘

卷积的应用
平滑均值滤波–起到平滑效果

高斯平滑–水平和垂直方向呈现高斯分布,更突出了中心点在像素平滑后的权重,相比于均值滤波而言,有着更好的平滑效果。

图像锐化–使用的是拉普拉斯变换核函数

Soble边缘检测–更强调了和边缘相邻的像素点对边缘的影响

卷积解决的问题
卷积负责提取图像中的局部特征
步长/Stride
如果用(f,f)的过滤器来卷积一张(h,w)大小的图片,每次移动一个像素的话,那么得出的结果就是(h-f+1,w-f+1)的输出结果。f是过滤器大小,h和w是图片的高宽。
如果每次不止移动一个像素,而是s个像素,那么结果就会变为:
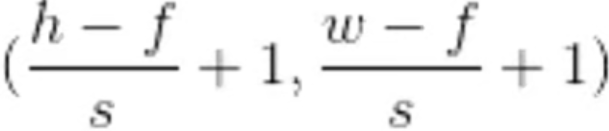
这个s就叫做步长
存在的问题:
- 只要f或s的值比1大的话,那么每次卷积之后结果的长宽,要比卷积前小一些。
- 丢失信息
填充/Pading



3.通道卷积

为什么三个通道用到的卷积核不一样?
因为不同通道上的特征不一样
输入通道数决定卷积核的通道数
卷积核的个数决定了输出的通道数
CNN的厉害之处:
卷积核的特征不是人为设定的,而是经过大量图片自己训练学习出来的
3.特征选择
特征选择:
特征:在一些实际问题中,我们通道的样本数据都是多个维度的,即一个样本使用多个特征来表征的。例如房价问题中影响房价的因素房子面积x1、卧室数量x2等.
为什么要做特征选择?
对于特定的学习算法来说,哪一个特征是有效的,这是一个未知问题。因此,需要从所有特征中选择出对于学习算法有益的相关特征。
进行特征选择的主要目的:
- 降维
- 降低学习任务的难度
- 提升模型的效率
特征选择定义:从N个特征中选择其中M(M<=N)个子特征,并且在M个子特征中,准则函数可以达到最优解。
特征选择想要做的是:选择尽可能少的子特征,模型的效果不会显著下降,并且结果的类别分布尽可能地接近真实地类别分布。
特征选择主要包括四个过程:
1)生成过程:生成候选地特征子集
2)评价函数:评价特征子集的好坏
3)停止条件:决定什么时候该停止
4)验证过程:特征子集是否有效

生成过程是一个搜索过程,这个过程主要有以下三个策略:
a)完全搜索:根据评价函数做完全搜索。完全搜索主要有两种:穷举搜素和非穷举搜索;
b)启发式搜索:根据一些启发式规则在每次迭代时,决定剩下的特征该被选择还是被拒绝;
c)随机搜索;每次迭代时会设置一些参数,参数的选择会影响特征选择的效果。由于会设置一些参数(例如最大迭代次数)
停止条件用来决定迭代过程什么时候停止,生成过程和评价函数可能会对于怎么选择停止条件产生影响。停止条件有以下四种选择:
a)达到预定义的最大迭代次数;
b)达到预定义的最大特征数;
c)增加(删除)任何特征不会产生更好的特征子集;
d)根据评价函数,产生最优特征子集
评价函数
评价函数主要用来评价选出的特征子集的好换,一个特征子集是最优的往往指相对于特定的评价函数来说的。主要用来度量一个特征(或者特征子集)可以区分不同类别的能力。根据具体的评价方法主要有三类:
- 过滤式(filter):先进性特征选择,然后取训练学习器,所以特征选择的过程与学习器无关。相当于先对于特征进行过滤操作,然后用特征子集来训练分类器。对每一维的特征“打分”,即给每一维的特征赋予权重,这样的权重就代表着该维度特征的重要性,然后依据权重排序。
- 包裹式(wrapper):直接把最后要使用的分类器作为特征选择的评价函数,对于特征的分类器选择最优的特征子集。将子集的选择看作是一个搜索寻优问题,生成不同的组合,对组合进行评价,再与其他的组合进行比较。这样就将子集的选择看作是一个优化问题。
- Filter和Wrapper组合式算法:先使用Filter进行特征选择,去掉不相关的特征,降低特征维度;然后利用Wrapper进行特征选择。
- 嵌入式(embedding):把特征选择的过程于分类器学习的过程融合在一起,在学习的过程中进行特征选择。其主要思想是:在模型既定的情况下学习出对提高模型准确性最好的属性。
5种比较常见的评价函数:
1)距离度量:如果X在不同类别种能产生比Y更大的差异,那么就说明X要好于Y
2)信息度量:主要是计算一个特征的信息增益(度量先验不确定性和期望,厚颜不确定性之间的差异)
3)依赖度量:主要用来度量从一个变量的值预测应一个变量值的能力。最常见的是相关系数:用来发现一个特征和一个类别的相关性。
4)一致性度量:对于两个样本,如果他们的类别不同,但是特征值是相同的,那么他们是不一致的。找到与全集具有同样区分能力的最小子集。严重一栏与特征的训练集和最小特征偏见的用法;找到满足可接受的不一致率(用户指定的参数)的最小规模的特征子集。
5)误差率度量:主要用于Wrapper式的评价方法中。使用特征的分类器,利用选择的特征子集来预测测试集的类别,用分类器的准确率来作为指标。这种方法准确率很高,但是计算开销较大。
4.PCA
特征提取:
特征是什么:常见的特征有边缘、角、区域等
特征提取:使通过属性间的关系,如组合不同的属性得到新的属性,这样就改变了原来的特征空间。
特征选择:是从原始特征数据集中选择出子集,是一种包含的关系,没有更改原始的特征空间。
目前图像特征的提取主要有两种方法:传统图像特征提取方法和 深度学习方法
1)传统的特征提取方法:基于图像本身的特征进行提取;
2)深度学习方法:基于样本自动训练出图像的特征分类器
特征提取主要方法:主要目的式为了排除信息量小的特征,减少计算量等
主成分分析(PCA)
简单来说,就是将数据从原始的空间中转换到新的特征空间中,例如原始的空间式三维的(x,y,z),x、y、z分别式原始空间的三个基,我们可以通过魔种方法,用新的坐标系(a,b,c)来表示原始的数据,那么a、b、c就是新的基,他们组成新的特征空间。在新的特征空间中,可能所有的数据在c上的投影都接近0,即可以忽略,那么我们就可以直接用(a,b)来表示数据,正阳数据就从三位的(x,y,z)讲到二维的(a,b)。
如何求新的基(a,b,c)?
一般步骤:
1)对原始数据零均值化(中心化);
2 )求协方差矩阵;
3)对协方差矩阵求特征向量和特征值,这些特征向量组成了新的特征空间。
零均值化(中心化)
中心化即是指变量减去它的均值,使均值为0
其实就是一个平移的过程,平移后使得所有数据的中心是(0.0)

只有中心化数据之后,计算得到的方向才能比较好的“概括”原来的数据
下面图像表述了中心化的几何意义,就是将样本集的中心平移到坐标系的原点O上
PCA降维的几何意义:
对于一组数据,如果它在某一坐标轴上的方差越大,说明坐标点越分散,该属性能够比较好的反映源数据。所以在进行降维的时候,主要目的是找到一个超平面,他能使得数据点的分布差呈最大,这样数据表现在新的坐标轴上的时候就已经足够分散了。
方差:
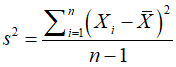
PCA算法的优化目标就是:1)降维后同一纬度的方差最大;2)不同维度之间的相关性为0
协方差就是一种用来度量两个随机变量关系的统计量
同意元素的协方差就表示该元素的方差,不同元素之间的协方差就表示他们的相关性

性质:
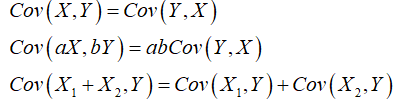
Cov(X,X)=D(X)
协方差矩阵定义:



对协方差矩阵求特征值、特征矩阵


代码:


应用:鸢尾花分类

PCA算法的优缺点:
优点:
1)完全无参数限制。在PCA的计算过程中完全不需要认为的设定参数或是根据任何经验模型对计算进行干扰,最后的结果只与数据相关,与用户是独立的。
2)用PCA技术可以对数据进行降维,同时对新求出的“主元”向量的张耀性进行排序,根据需要取前面最重要的部分,将后面的维数省去,可以达到降维且简化模型或是对数据进行压缩的效果。同时最大程度的保持了原有数据的信息。
3)各主成分之间正交,可以消除原始数据成分之间的相互影响
4)计算方法简单,易于在计算机上实现
缺点:
1)如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的向量,效率也不高
2)贡献率小的主成分往往可能含有对样本差异的重要信息
注:参考八斗人工智能视频,仅作基础巩固用

