
热门标签
热门文章
- 1MySQL 查询日期格式化_mysql 查询日期格式t-1
- 2Docker部署数据库--人大金仓(kingbase)_docker kingbase
- 3ubuntu下安装VSCODE 无法联网下载几个插件 提示: This undefined version of the extension is incompatible with your OS_this windows x86 version of the extension is incom
- 4美团2024年春招第一场笔试【技术】第五题:小美的区间删除_小美拿到了一个大小为 n的数组,她希望删除一个区间后,使得剩余所有元素的乘
- 5AI融合大数据:智能时代的新篇章与数据要素的革命_大数据和ai融合
- 6爆火的ChatTTS试用体验(附完整安装步骤和体验地址)_chattts-ui-0.84
- 7大模型核心技术原理: Transformer架构详解_大模型 transformer架构
- 8VSCode中终端运行在当前文件的路径_vsc终端运行
- 9http://www.gitblit.com/ https://git-scm.com/_gitblit官网
- 10【前端】静态个人网站页面布局模板(附源码)_静态网站模板
当前位置: article > 正文
扩散模型Stable Diffusion
作者:很楠不爱3 | 2024-06-15 03:54:09
赞
踩
扩散模型Stable Diffusion
扩散模型构成
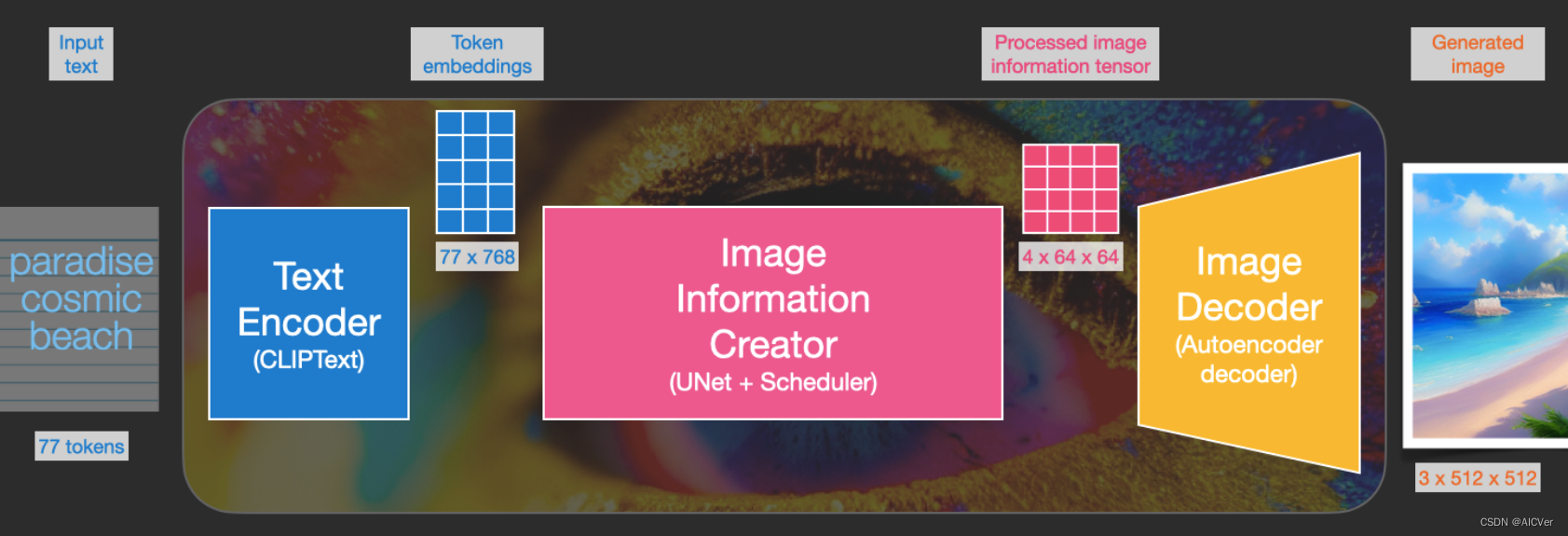
Text Encoder(CLIPText)
Clip Text为文本编码器。以77 token为输入,输出为77 token 嵌入向量,每个向量有768维度。
Diffusion(UNet+Scheduler)
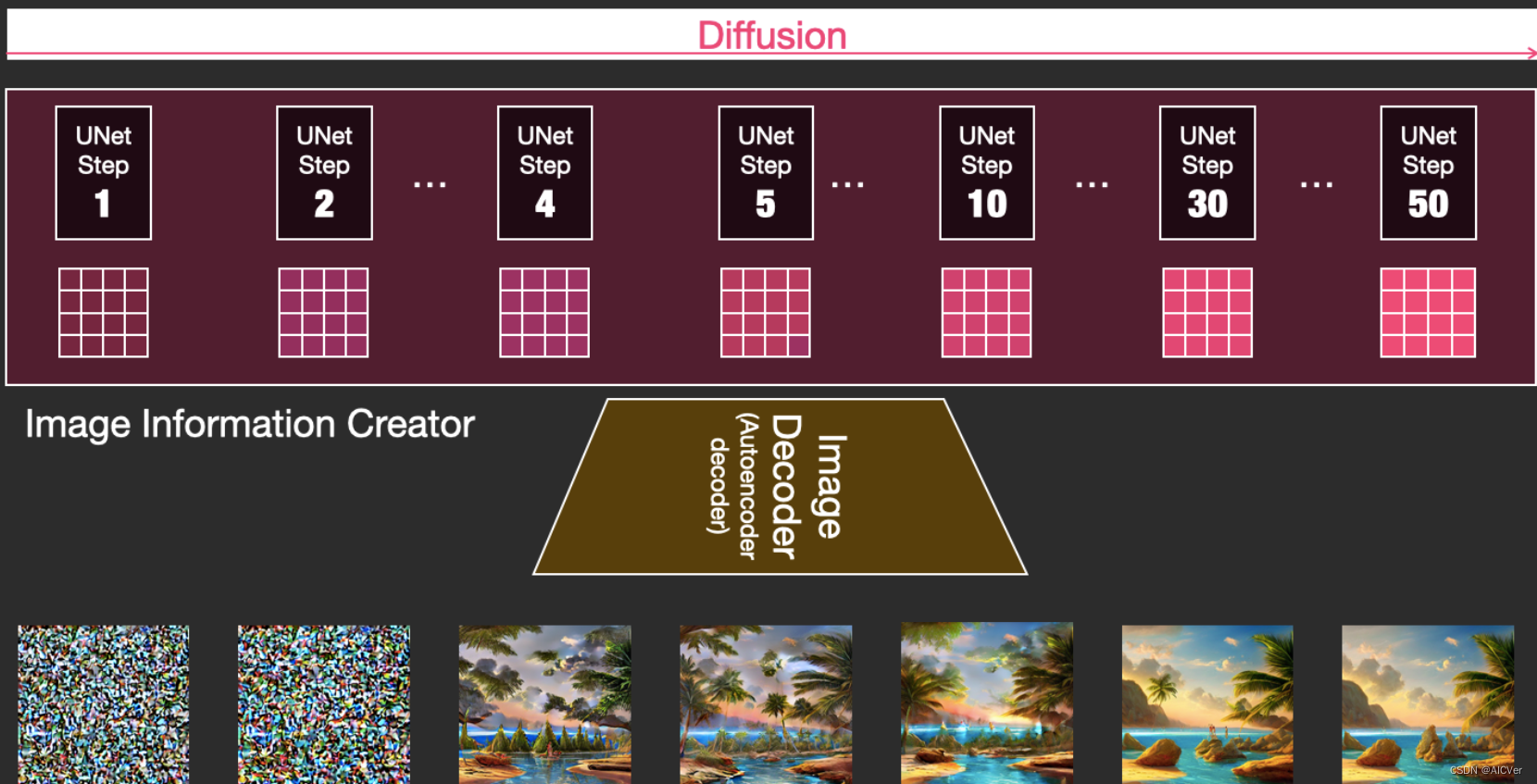
在潜在空间中逐步处理扩散信息。以文本嵌入向量和由噪声组成的起始多维数组为输入,输出处理的信息数组。
UNet
训练过程
- 随机噪声添加到图像上,构成一个训练样本
- 不同的噪声不同的图像,可构成训练集
- 使用上述训练集,训练噪声预测模型(Unet)
推理过程
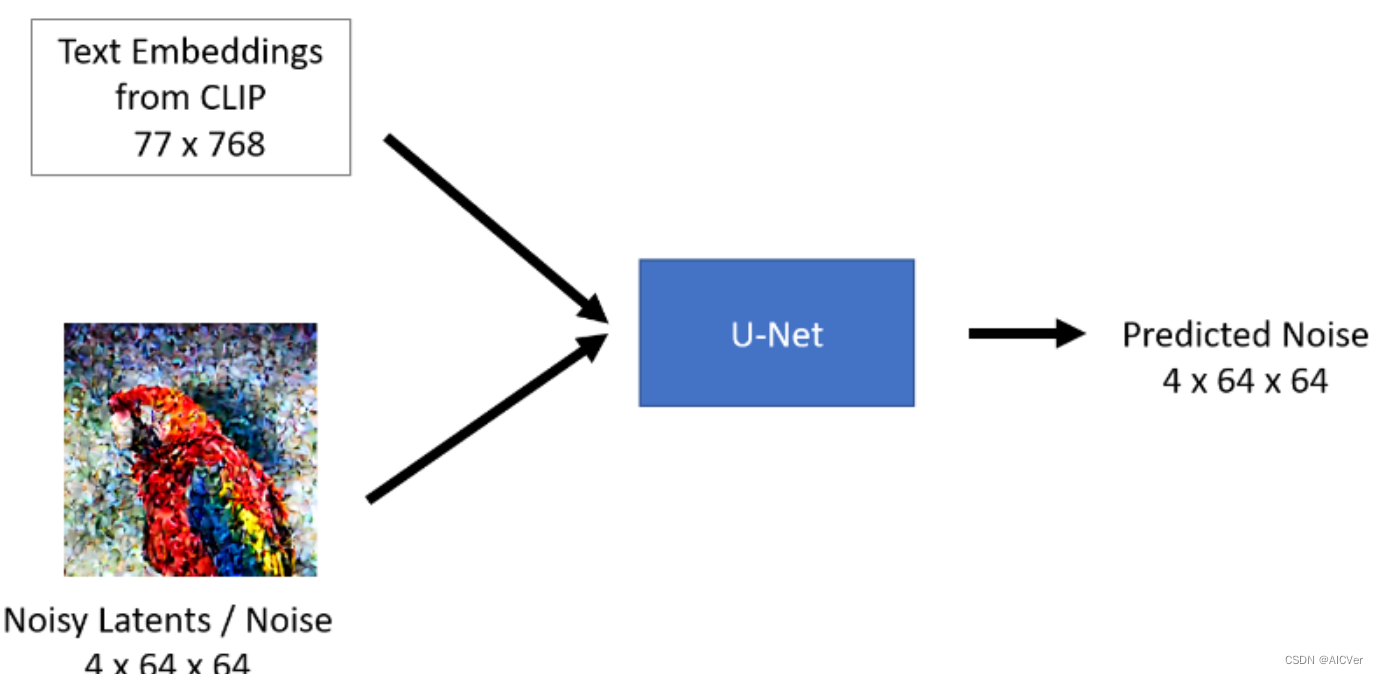
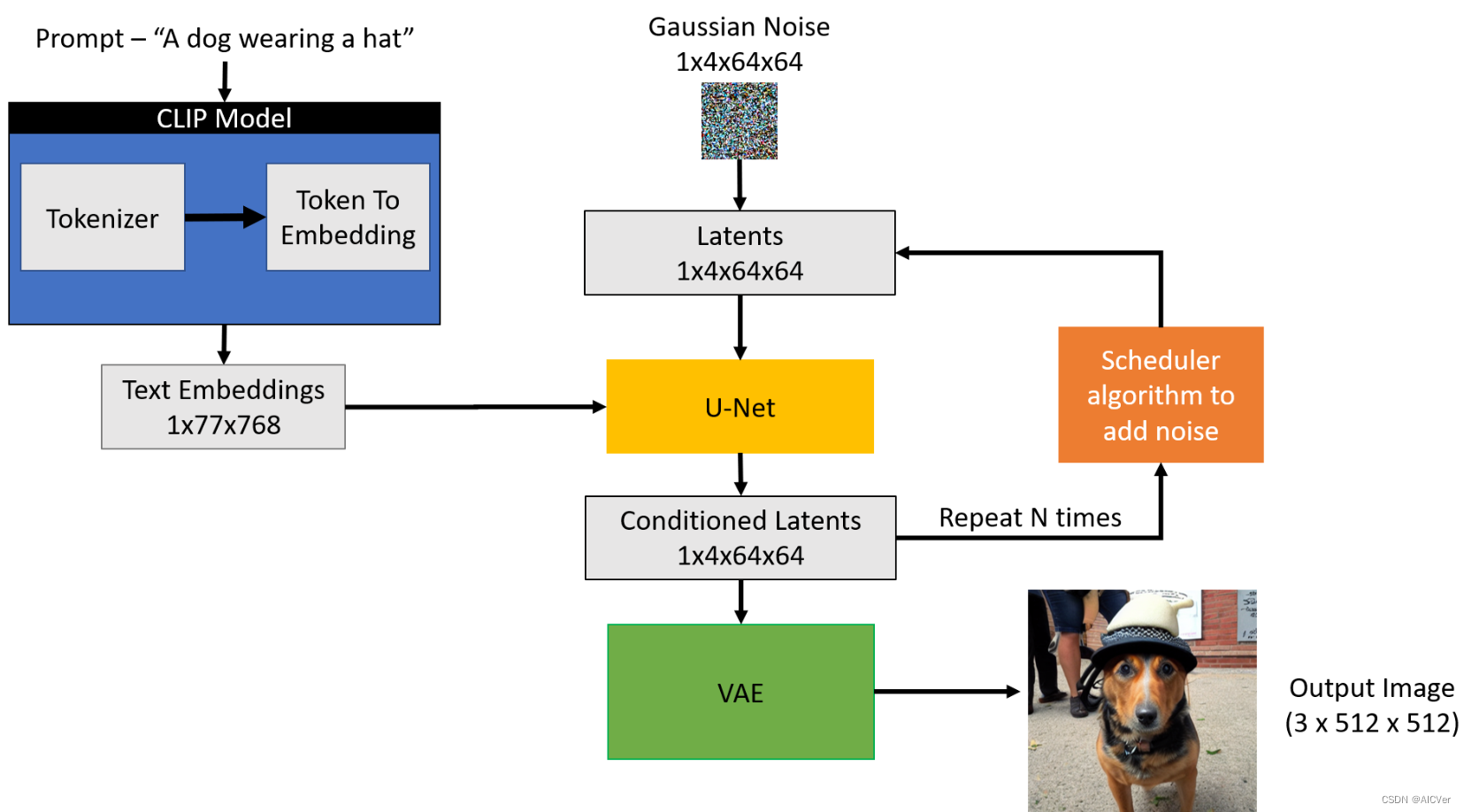
通常来说一个U-Net包含两个输入:
- Noisy latent/Noise : 该Noisy latent主要是由VAE编码器产生并在其基础上添加了噪声;或者如果我们想仅根据文本描述来创建随机的新图像,则可以采用纯噪声作为输入。
- Text embeddings: 基于CLIP的将文本输入提示转化为文本语义嵌入(embedding)
U-Net模型的输出:
- 从包含输入噪声的Noisy Latents中预测其所包含的噪声。换句话说,它预测输出的为Noisy Latents减去de-noised latents后的结果。
Scheduler
scheduler的目的是确定在扩散过程中的给定的步骤中向latent 添加多少噪声。随着step的增大,添加噪声的权重在逐渐减小。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/很楠不爱3/article/detail/720773
推荐阅读
相关标签

