
- 1在Linux搭建测试环境-----PHP项目(详细)
- 2python flask 魔术方法
- 3(librealsense就是SDK)T265驱动安装就是编译librealsense的源码(非ROS环境)_librealsense源
- 4C语言小细节(1)——用指针实现函数形参改变实参_形参指针改变实参指针,赋字符串给实参
- 5React实例之完善布局菜单(二)
- 6无向图求三元环的个数
- 7Ubuntu20.04下载t265 深度摄像头的驱动realsense SDK(安装部分)_ubuntu20.04 t265
- 8软件测试——基础练习(期末复习)_软件测试基础知识题库
- 9chatgpt赋能python:Python设置开机自启动_python开机自动运行
- 10项目管理之需求管理的一些体会_需求管理心得
【GPT】中文大语言模型梳理与测评(C-Eval 、AGIEval、MMLU、SuperCLUE)_superclue c-eval哪个更权威
赞
踩

概述
中文英文模型,GPT-4性能是当着无愧的王者,但无法使用。中文评测平台榜单比较混乱,看个人使用习惯。
模型汇总: https://github.com/wgwang/LLMs-In-China
申请后直接使用大模型
- 遇事不决-
ChatGPT: https://chat.openai.com/ - 百度-文心一言:https://yiyan.baidu.com/
- 360智脑:https://chat.360.cn/
- 阿里-通义千问:https://qianwen.aliyun.com/
- 清华-chatGLM:chatglm.cn
- 科大讯飞-星火:https://xinghuo.xfyun.cn/
开源可本地部署
中文:清华60亿参数 ChatGLM2-6B : https://github.com/THUDM/ChatGLM2-6B
通识数据集测评(C-Eval 、AGIEval、MMLU、SuperCLUE)
自媒体报道
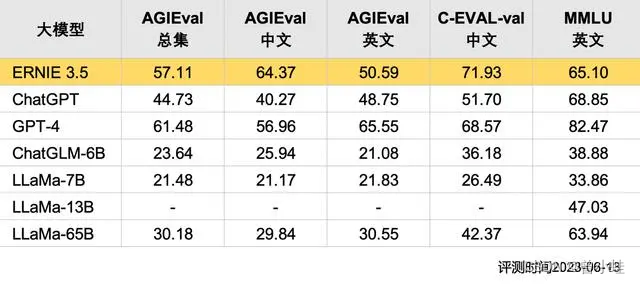
百度文心大模型3.5(ERNIE 3.5)
中文能力突出,部分超过 GPT-4 的表现;综合能力稍逊于GPT-4,但是平均能力超过chatgpt
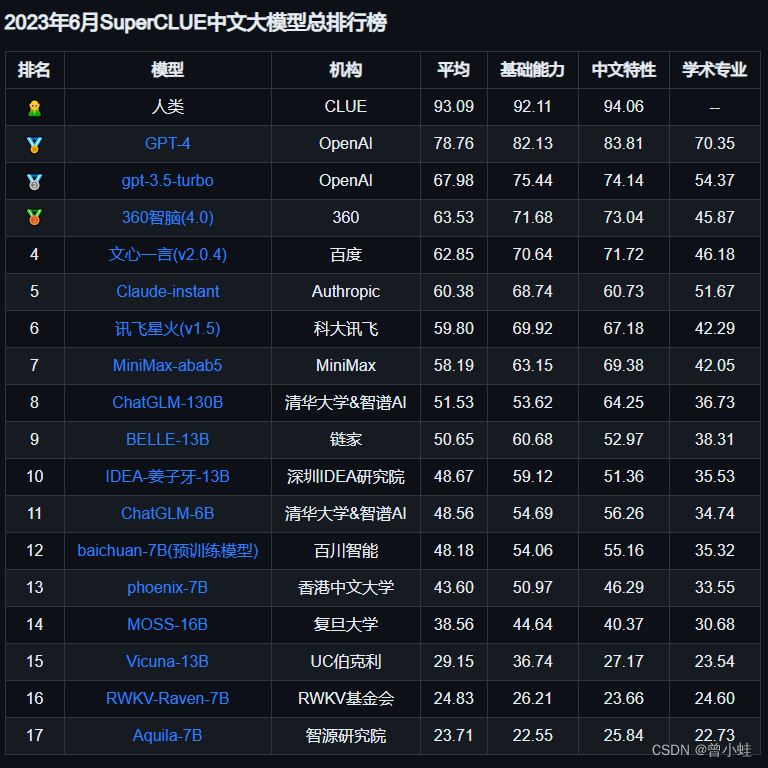
SuperCLUE:中文通用大模型综合性基准
评测地址:https://github.com/CLUEbenchmark/SuperCLUE
C-Eval:中英测评(清华上交提出)
论文:一个用于基础模型评估的多层次多学科的中文评估套件
C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models
当前排名(23.06.27)
该榜展示了,GPT-4在困难问题, 科学技术工程数学(STEM)上的强大准确的回答能力。
而chatglm在人文和社会科学方面遥遥领先。

数据集内容
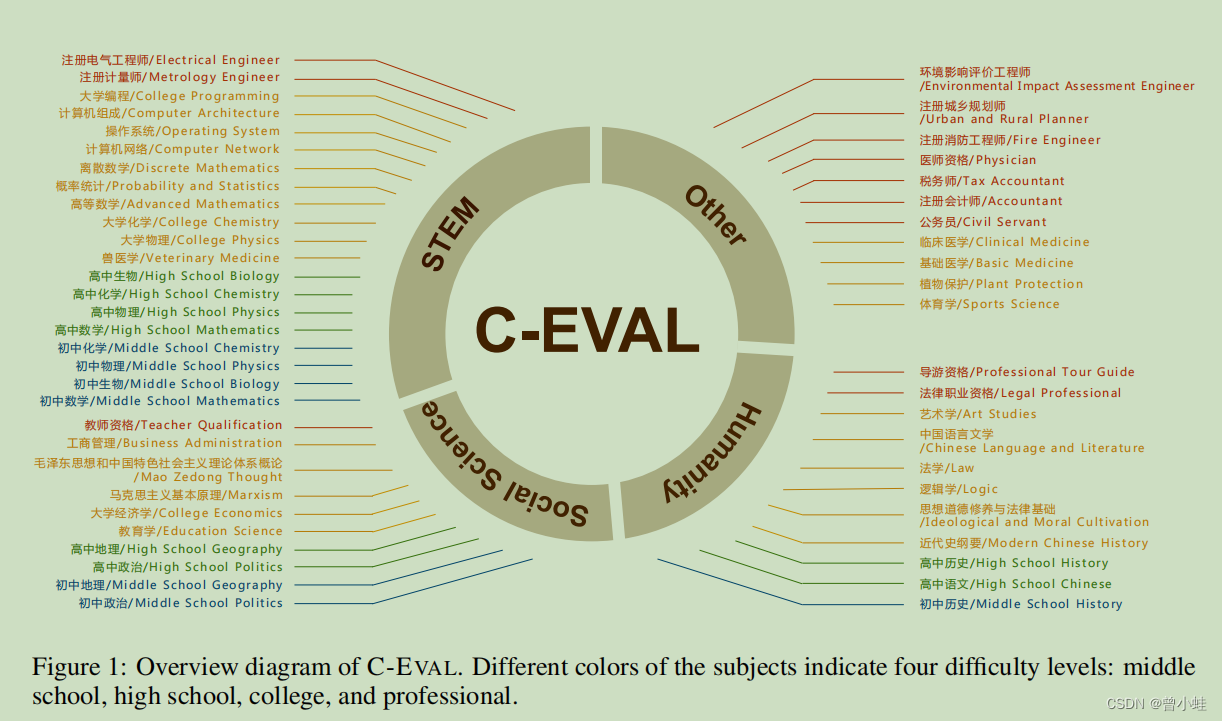
具体的科目 如下图:
4个圈分别表示:
人文学科(humanities)
社会科学(Social Science)
STEM是科学(Science)、技术(Technology)、工程(Engineering)和数学(Mathematics)四门学科英文首字母的缩写。
这些科目的不同颜色表示四个难度水平:中学、高中、大学和专业水平(professional)。
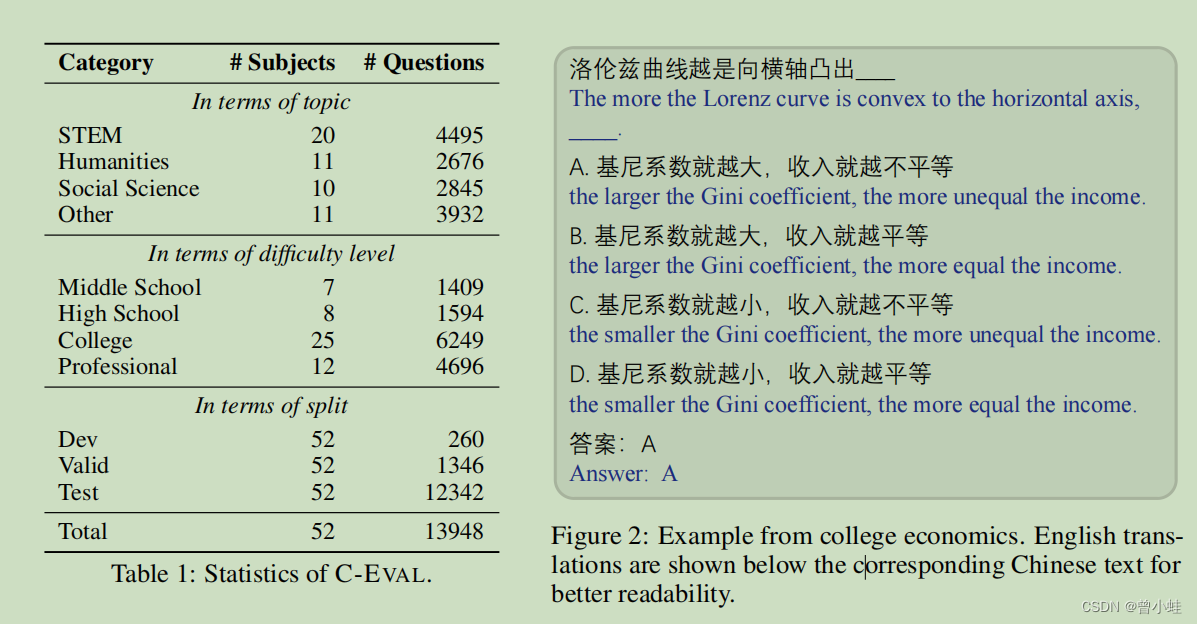
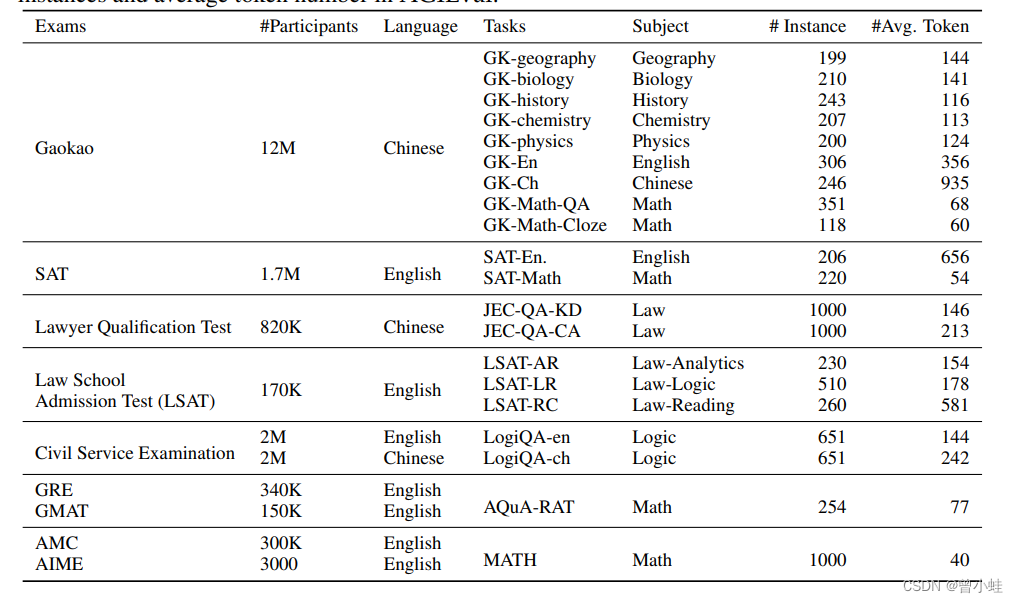
数据量与试题示例
论文中的测评结果
测评方式,API或者开源模型(weights)
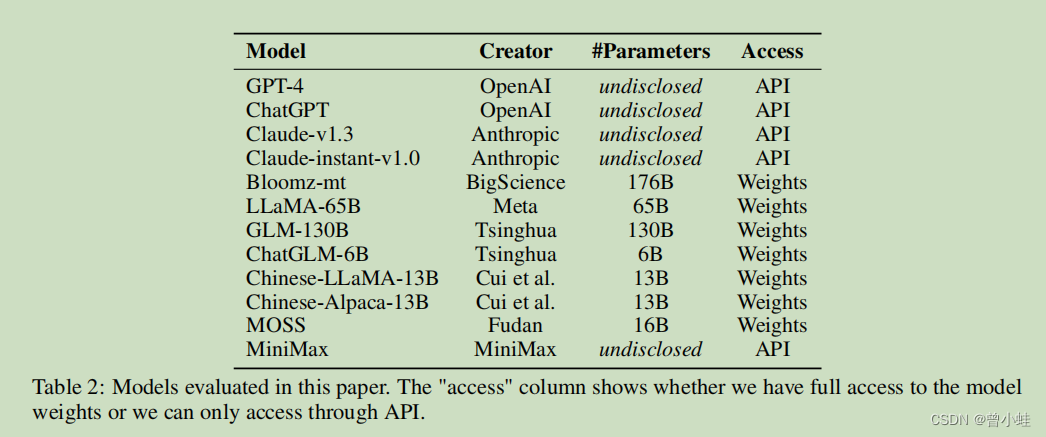
AGIEval:微软 中英文评测
论文:AGIEval(一个以人为本的): A Human-Centric Benchmark for Evaluating Foundation Models.
该基准选取20种面向普通人类考生的官方、公开、高标准的资格考试、包括普通大学入学考试(如中国的高考和美国的SAT考试)、司法考试、数学竞赛等
数据集内容
律师资格考试 (lawyer qualification exams)、
国家公务员考试 (civil servant exams)
GRE(Graduate Record Examination)是美国研究生入学考试)
GMAT(Graduate Management Admission Test)是经企管理类研究生入学考试)。
人类与国外主流模型差异
GPT-4

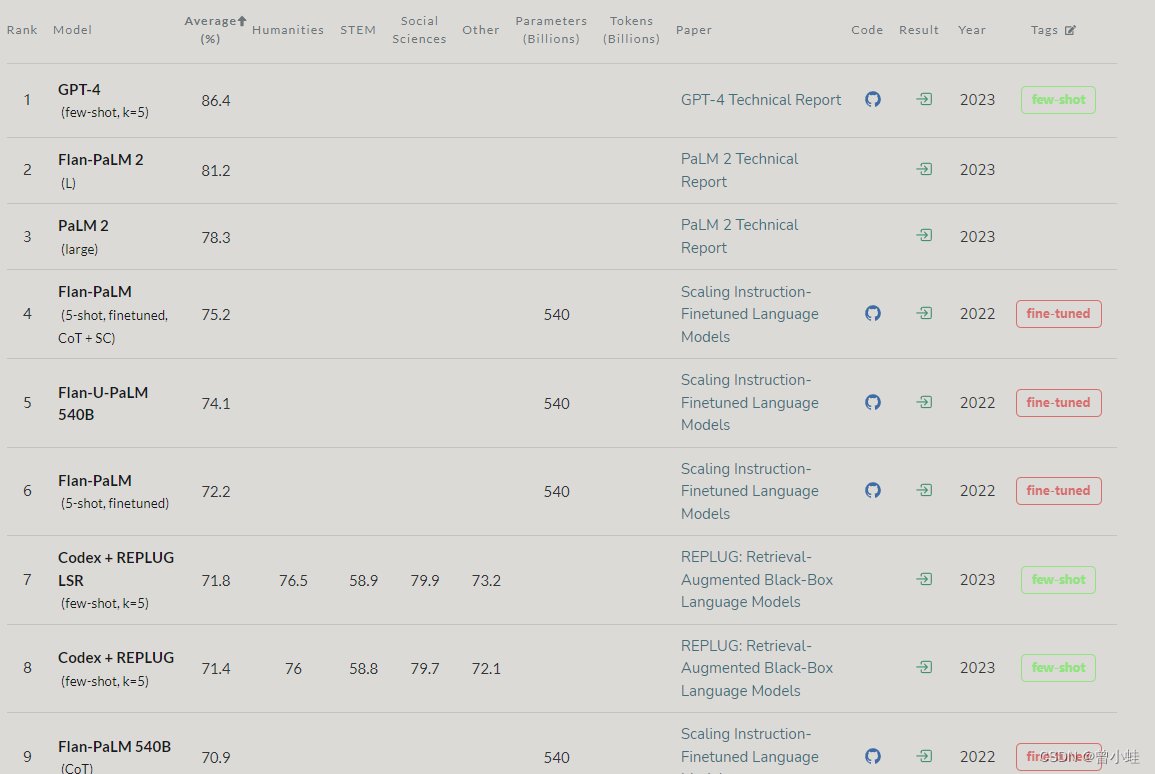
MMLU : 英文试题
测量大规模多任务语言理解:2009. Measuring Massive Multitask Language Understanding
该测试涵盖了57个任务,包括基础数学(elementary mathematics)、美国历史、计算机科学、法律等等。
用以测量模型是否,具备广泛的世界知识和问题解决能力
部分测评结果
https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu
试题内容
图来自论文
STEM是科学(Science)、技术(Technology)、工程(Engineering)和数学(Mathematics)四门学科英文首字母的缩写。


