
- 1Java中ArrayList的使用_java for : arraylist
- 2阿里云服务器安装nginx,以及相关配置_阿里云安装nginx
- 3Oracle启动和停止的方式详解_oracle startup过程中可以重启吗
- 4一个简单的HTML网页——传统节日春节网页(HTML+CSS)_春节html素材
- 5element-ui动态增加表单项并验证_element表单模块里面实现一个按钮 通过点击可以添加一个模块在表单上
- 6文心一言和ChatGPT最全对比!_文心一言与chatgpt对比
- 7Galance镜像服务_cirros-0.3.4-x86_64-disk.img
- 8Chrome您使用的是不受支持的命令行标记:--ignore-certificate-errors
- 9怎样进行 maven 离线编译 install
- 10Vue中使用require.context()自动引入组件和自动生成路由的方法介绍_vue自动引入组件
关于树莓派编译及运行Snowboy的详细教程。_百度sudo python3 demo.py resources/models/snowboy.um
赞
踩
首先什么是snowboy我就不讲了,毕竟能搜到我这篇文章的一般都是遇到困境了。
我这里讲的是一个简单的snowboy设置并下载编译,直到成功的移植到自己的程序里。
下面是snowboy的官网
用GitHub登陆(或者其他的方式登陆都可以)
https://snowboy.kitt.ai/
进去之后就是这样,可以在词表中选一个自己喜欢的唤醒词,录入自己的声音,训练自己的模型

在这里我就选择最火爆的jarvis,这里我已经训练好了,直接点下载就ok了。你可以自己选一个自己喜欢的,点击那个麦克风图标就可以录音并训练了,这里我就不多讲了(主要要注意的是,如果你是用的树莓派登进去的这个网站,一定要检测你的默认音频输入是不是你现在在用的麦克风,不然怎么吼它都没反应,usb麦克风的配置可以参考叮当机器人配置里的麦克风配置)

录制完并训练模型,然后下载文件 ”唤醒词.pmdl“ 文件 (也可能是其他后缀如 .umdl这里不用管,反正都是模型文件就是了)
然后打开你的树莓派
安装其他软件依赖:
安装 PyAudio:sudo apt-get install python3-pyaudio
安装 SWIG :sudo apt-get install swig
安装 ATLAS:sudo apt-get install libatlas-base-dev
获取snowboy源代码:git clone https://github.com/Kitt-AI/snowboy.git
(这里可能会出现下载很慢的情况,我就没在命令行里下载成功,我是直接在GitHub下载地址里下载的压缩包,然后传到树莓派上,解压出来的。有可能你下载压缩包的时候速度还是很慢你可以借鉴GitHub访问速度慢的一种优化方法来修改一下自己的Host)
解压出来,命名为snowboy。
编译 Python3 环境链接库: cd snowboy/swig/Python3 && make
(这里你可以选择任意一款snowboy支持的语言进行编译,只要把路径里的Python3,改为你要的语言目录就行了,如 cd snowboy/swig/Java && make 就是编译Java的链接库。)
有些人很懒,没有把代码进行编译,直接下载的官网说支持树莓派的这个包,这个包仅支持python且仅支持python2版本。这里值得注意,这是我踩的坑。

当你make执行完了之后,进行测试:
进入官方示例目录 snowboy/examples/Python3 并运行以下命令:
python3 demo.py resources/models/snowboy.umdl
(你会发现这里会出现一个错误,
这里要把官方案例文件中的 snowboydecoder.py 文件修改一下,把from . import snowboydetect改为import snowboydetect然后再运行。就ok了。
 )
)
运行结果如下,对着麦克风喊snowboy,它就会发出 “叮” 的一声,并打印出检测到词语。证明你就已经编译成功了!!

测试成功后,进入刚刚make的 snowboy/swig/Python3文件夹中,把文件里的东西复制到你的项目中,最好命名一个名为snowboy的文件夹。(最重要的还是 _snowboydetect.so文件)

然后把snowboy/resources 文件夹复制到自己的项目目录下面,就能在你的项目中运行snowboy了。
(这里千万不要直接复制snowboy/examples/Python3文件夹里的文件,因为里面的资源文件和动态库文件都是链接文件,相当于快捷方式,如果脱离了该路径,并不能运行,所以还是自己找到对应文件,自己拼接回一个完好snowboy模块)如图一个文件夹即为一个snowboy模块

这里如果需要运行检测之前录制的jarvis热词,只需要把jarvis.pmdl文件放到刚刚整理好的snowboy文件中 然后运行 一下 python demo.py jarvis.pmdl就可以了
到此其实已经很详细的讲解了怎么编译一个snowboy了。
下面是snowboy代码的简单讲述。
核心代码 snowboydetect.py
这里说不懂别乱动,那我们就不看这个了。直接看他的demo.py和snowboydecoder.py 怎么调用里面的函数就行了。

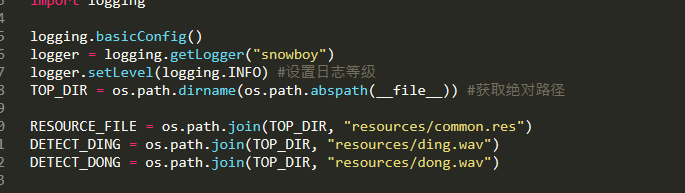
日志,以及几个文件的路径的初始化 ( 叮和咚声音文件 源文件)
从环形缓冲区里取出声音。

播放音频文件

主要的一个类

类的初始化函数,主要需要参数为 模型文件,敏感度。其他带有默认参数了,可以不输入。

执行函数。

终止函数
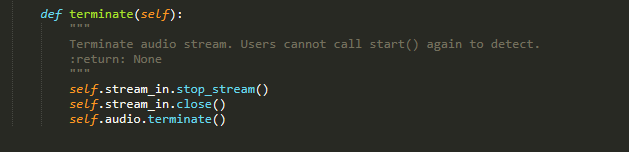
从这几段代码可以看出。要使用snowboy,要按这里面的初始化函数对类进行初始化,然后把语音数据传入一个函数里,就可以对这段语音是否有热词进行检测了。如果函数返回 ‘-1’则没有检测到,如果返回值大于零,则检测到了。

案例中不是进行录音,然后把录音文件传进snowboy的,而是直接在录音的唤醒缓冲区中取数据的,这样会导致经常误检测到唤醒词。所以最好还是自己写一个软件降噪的代码,让snowboy更好的捕捉到你的声音,然后我们就不是像案例一样直接用环状缓冲区的data,而是自己录制一个文件的data,这里把函数的data改一下就行了。
剩下不懂的结合着demo.py 来看就行了,非常简单。还是不懂就在下方留言,我看到了或者会的人看到了就会教你。
码字码到晚上三点,博主是初学者,python不精,Linux不精,写这个是希望能帮到大家,如果有错误的欢迎纠正。我确实是踩着坑过来的,查资料也没查到,一点一点自己摸索,实在不容易。

