
- 1Flutter现支持Web和桌面,一跃成为前沿大一统框架_flutter cupertinoslidingsegmentedcontrol
- 2IPF 2019:人工智能计算 驱动产业变革_ipf计算机
- 3记录python中自己调用winmm.dll中的函数播放自定义声音_python 调用winmm播放声音
- 4达梦数据迁移工具入门操作_达梦迁移工具
- 5(头哥)Storm完全分布式安装
- 6带你底层看Sqoop如何转换成MapReduce作业运行的(代码程序)
- 7smartGit过期解决方案_smartgit23.1一个月试用期过期的解决方法
- 8智能新经济的AI平台:左手技术,右手行业
- 9热门开源项目推荐
- 10高算力SoC芯片大战打响,国产车规级芯片的逆袭路径_国产高算力芯片
[医学分割大模型系列] (1) SAM 分割大模型解析_用sam大模型做图像分割
赞
踩
论文地址:Segment Anything
开源地址:https://github.com/facebookresearch/segment-anything
demo地址:Segment Anything | Meta AI
参考:
- SAM模型详解
- https://www.bilibili.com/video/BV1K94y177Ka/?spm_id_from=333.337.search-card.all.click&vd_source=6bf14836c2866f1a29042ffd4369a079
- https://www.bilibili.com/video/BV1Bu411s79u/?spm_id_from=333.337.search-card.all.click&vd_source=6bf14836c2866f1a29042ffd4369a079
1. 特点
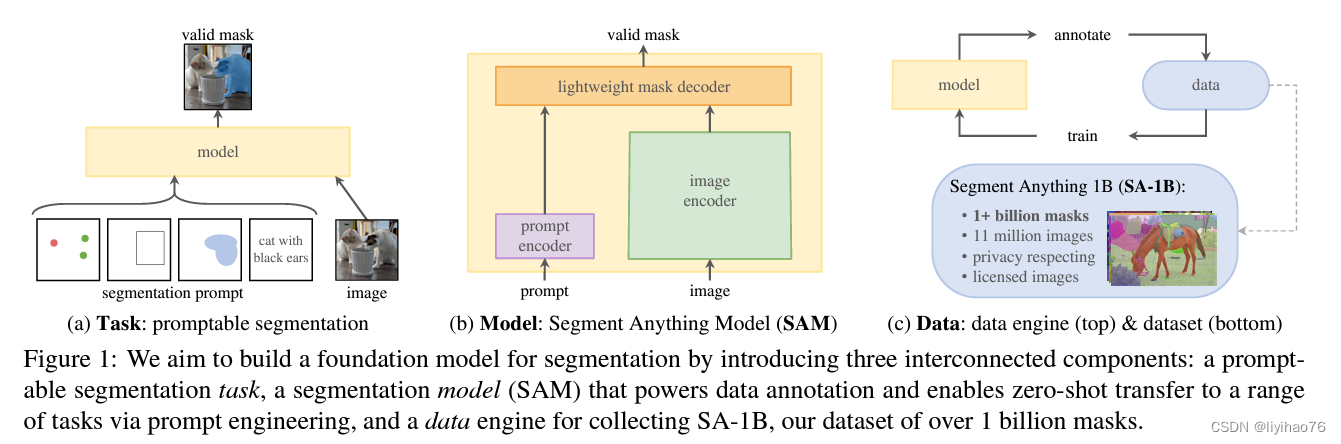
- 可提示的(Prompt)交互图像分割大模型(Foundation Models)
- 四种Prompt形式:点,框,Mask,文本
- 构建数据引擎:使用高效模型来协助数据收集和使用新收集的数据来帮助模型迭代。
2. 网络结构
模型整体上包含三个大模块,image encoder,prompt encoder和mask decoder。
2.1 Image encoder
image encoder旨在映射待分割的图像到图像特征空间。
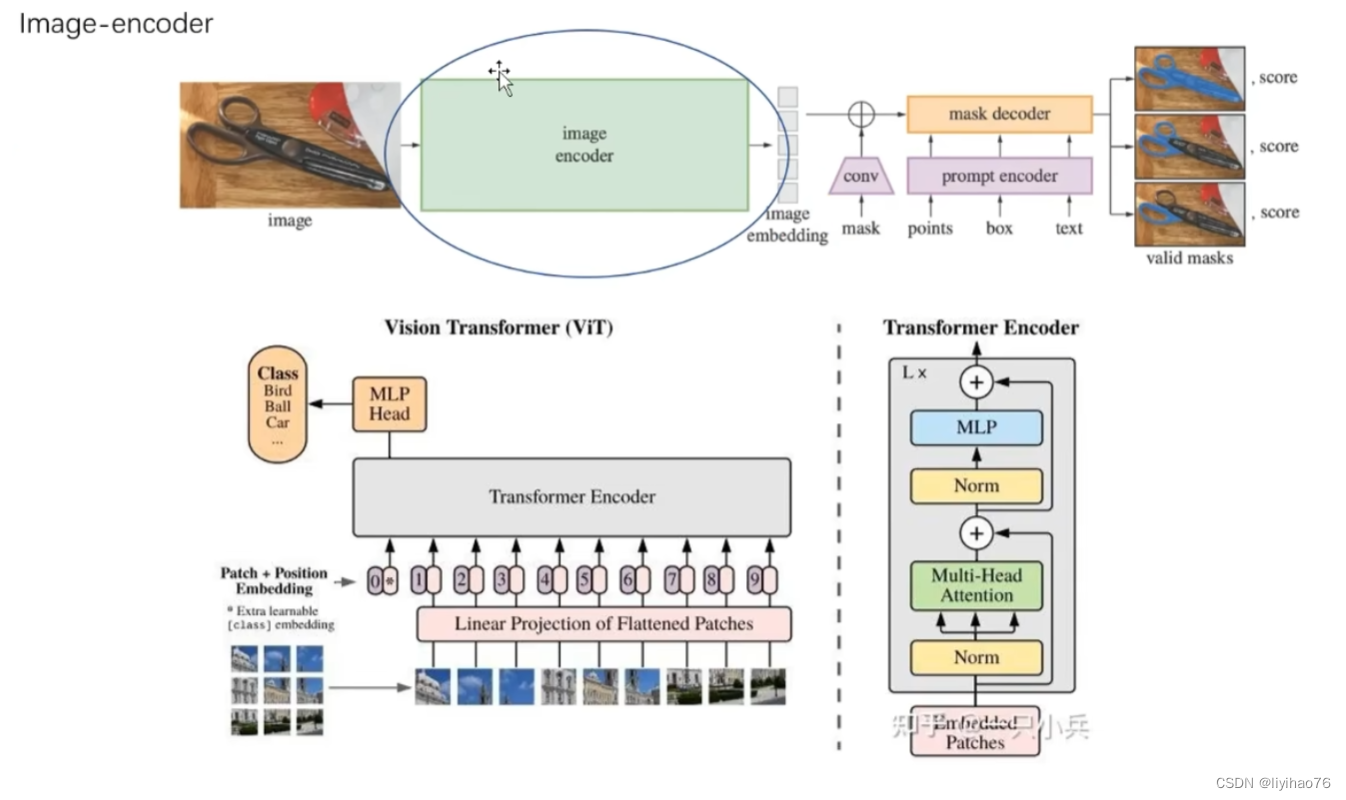
这里的ViT结构也并不是十分复杂,这里简单列出输入图像经过ViT的流程,其实整体只有4个步骤:
- 输入图像进入网络,先经过一个卷积base的patch_embedding:取16*16为一个patch,步长也是16,这样feature map的尺寸就缩小了16倍,同时channel从3映射到768。
- patch_embed过后加positional_embedding:positional_embedding是个可学习的参数矩阵,初始化是0。
- 加了positional_embedding后的feature map过16个transformer block,其中12个transformer是基于window partition(就是把特征图分成14*14的windows做局部的attention)的attn模块,和4个全局attn,这4个全局attn是穿插在windowed attention中的。
- 最后过两层卷积(neck)把channel数降到256(token长度),这就是最终的image embedding的结果。
整体来看,这个部分的计算量是相对来说比较大的,demo体验过程中,只有这个过程的计算是在fb的服务器上做的,prompt encoder和mask decoder体积比较小,都是在浏览器内部或者说用本地的内存跑的,整体速度还比较快。
其使用的预训练模型: Masked Autoencoders Are Scalable Vision Learners - 代码
# build_sam.py
sam_model_registry = {
"default": build_sam_vit_h,
"vit_h": build_sam_vit_h,
"vit_l": build_sam_vit_l,
"vit_b": build_sam_vit_b,
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.2 Prompt encoder
prompt encoder则是负责映射输入的prompt到prompt的特征空间,这里有一点要提就是作者定义了sparse(包括 点,框,文本)和dense(mask)两种prompt,其中sparse prompt比较好理解,就是指demo中我们可以输入的点,目标框或者是描述目标的text,而dense prompt在目前的线上demo中体验不到,paper中也只说它对应的是mask类型的prompt,从代码里看应该是训练时候用的比较多,一般是上一次迭代预测出的一个粗分割的mask,粗略指出待分割的目标区域。
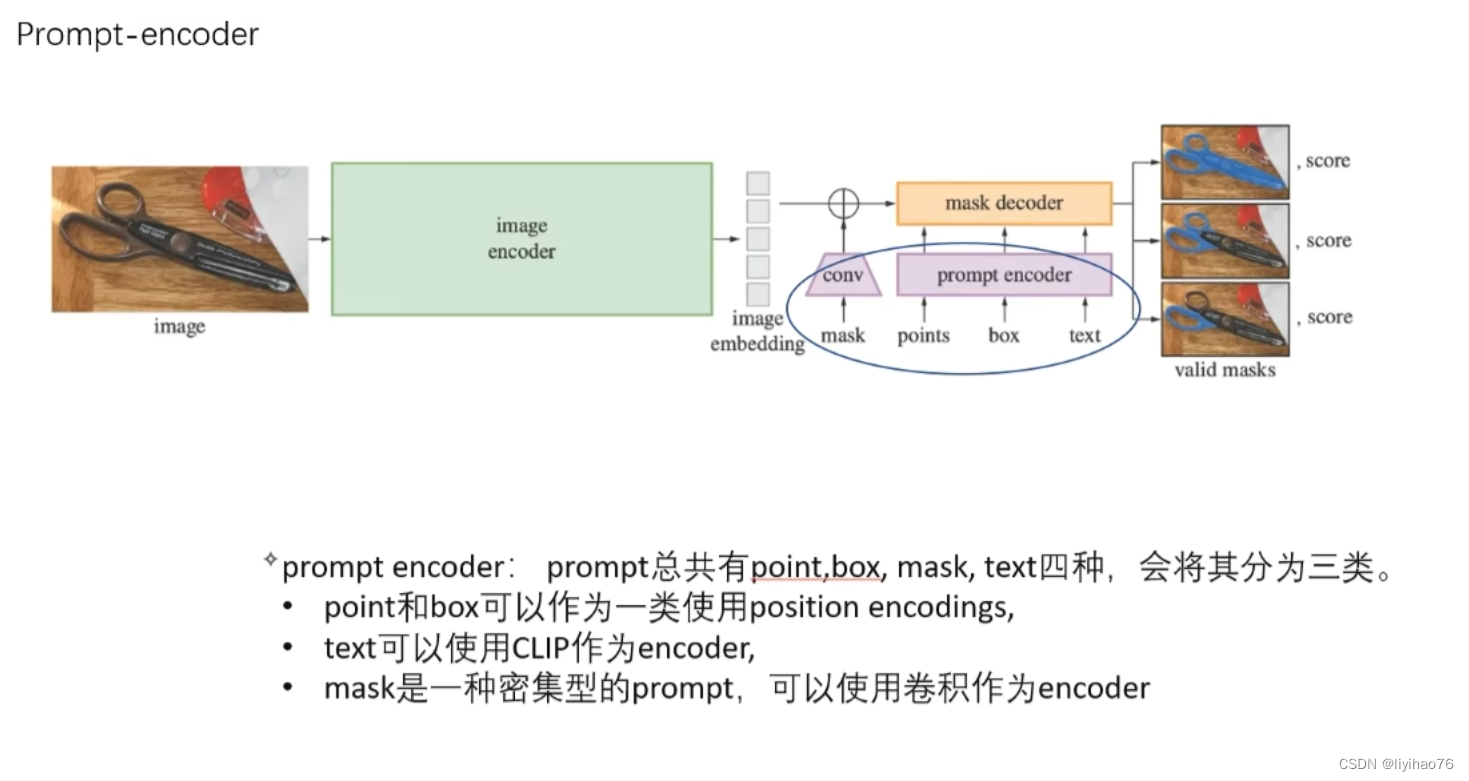
映射出的特征的channel和image embedding的channel一致(默认均为256),因为这两个后边要用attention进行融合。
- sparse prompt:
- 如果prompt是point,那么它的映射由两个部分相加组成,一个是位置编码,这里的位置编码使用的是Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains的编码方式,用空间坐标乘以高斯分布的向量来描述位置比直接的线性向量描述效果更好,另一个部分是一个描述当前点是前景还是背景(因为demo里可以选择pos点也可以选择neg点)特征的可学习的一维向量。换句话说,如果当前选择的点是positive,那么就在位置编码的2维向量上加一个表示postitive的一维向量,如果是neg,就加一个表示neg的一维向量,对于所有的positive的点,加上去的pos向量都是一样的。
- 如果prompt是box,那box的映射也是由两个部分相加组成,第一部分是左上和右下两个点的位置编码,第二部分是一组一维向量用来描述这个点是“左上”还是“右下”。也就是说,对于左上的点,他的映射就是位置编码+“左上”这个特征的描述向量,右下的点,就是位置编码+“右下”这个特征的描述向量。
- dense prompt:
- 对于mask这类的dense prompt,他的映射就比较简单粗暴。在输入prompt encoder之前,先要把mask降采样到4x,再过两个2x2,stride=2的卷积,这样尺寸又降了4x,就和降了16x的图像特征图尺寸一致了,再过一个1*1的卷积,把channel也升到256。如果没有提供mask,也就是我们实际inference时候的场景,这个结构会直接返回一个描述“没有mask”特征的特征图。
预训练: CLIP
# prompt_encoder.py def forward( self, points: Optional[Tuple[torch.Tensor, torch.Tensor]], boxes: Optional[torch.Tensor], masks: Optional[torch.Tensor], ) -> Tuple[torch.Tensor, torch.Tensor]: """ Embeds different types of prompts, returning both sparse and dense embeddings. Arguments: points (tuple(torch.Tensor, torch.Tensor) or none): point coordinates and labels to embed. boxes (torch.Tensor or none): boxes to embed masks (torch.Tensor or none): masks to embed Returns: torch.Tensor: sparse embeddings for the points and boxes, with shape BxNx(embed_dim), where N is determined by the number of input points and boxes. torch.Tensor: dense embeddings for the masks, in the shape Bx(embed_dim)x(embed_H)x(embed_W) """ bs = self._get_batch_size(points, boxes, masks) sparse_embeddings = torch.empty((bs, 0, self.embed_dim), device=self._get_device()) if points is not None: coords, labels = points point_embeddings = self._embed_points(coords, labels, pad=(boxes is None)) sparse_embeddings = torch.cat([sparse_embeddings, point_embeddings], dim=1) if boxes is not None: box_embeddings = self._embed_boxes(boxes) sparse_embeddings = torch.cat([sparse_embeddings, box_embeddings], dim=1) if masks is not None: dense_embeddings = self._embed_masks(masks) else: dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1, 1).expand( bs, -1, self.image_embedding_size[0], self.image_embedding_size[1] ) return sparse_embeddings, dense_embeddings

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
2.3 Mask decoder
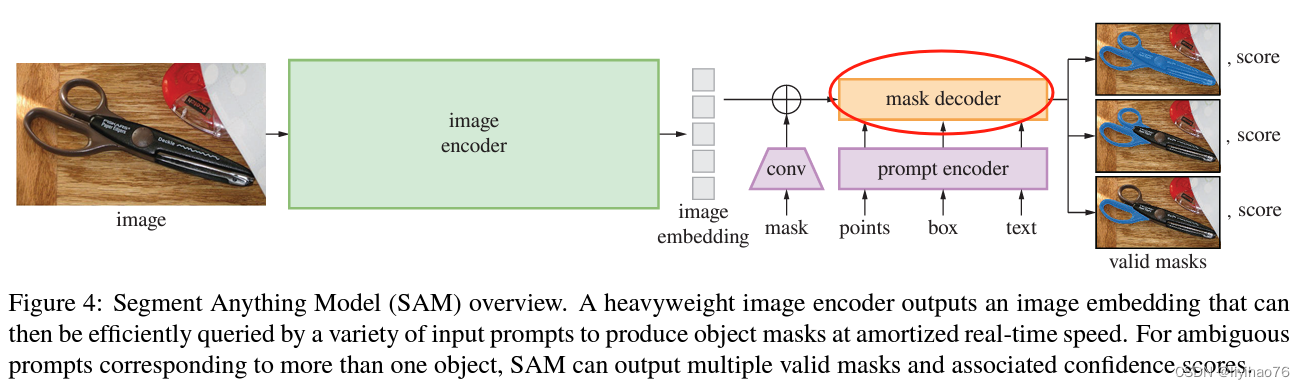
-
detr结构回顾
-
cross att:
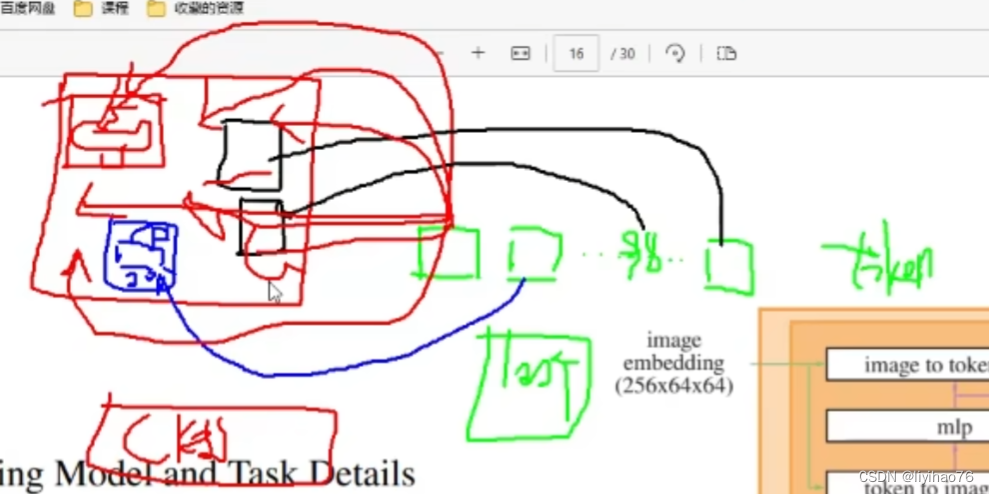
100个queries token对图片特征进行遍历,确定每个token要对应寻找的物体特征 -
self att:
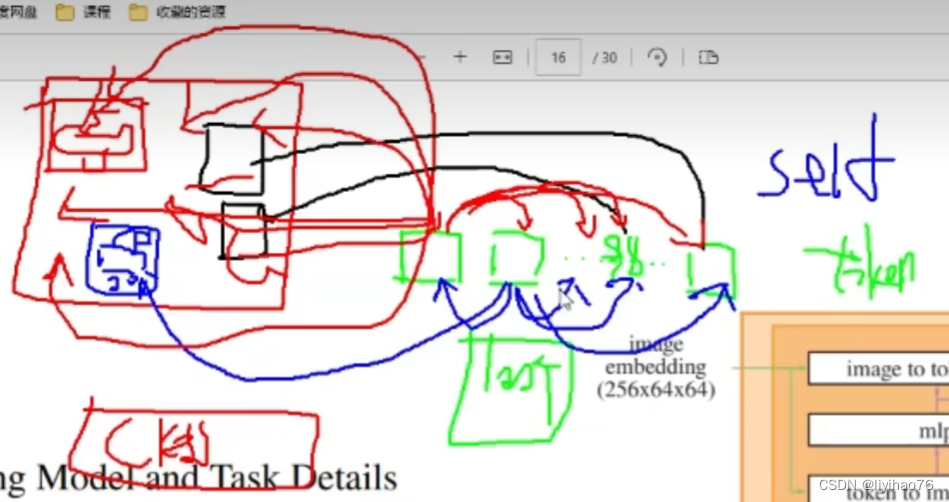
避免token之间寻找物体特征重复,queries token进行自注意力机制。
-
-
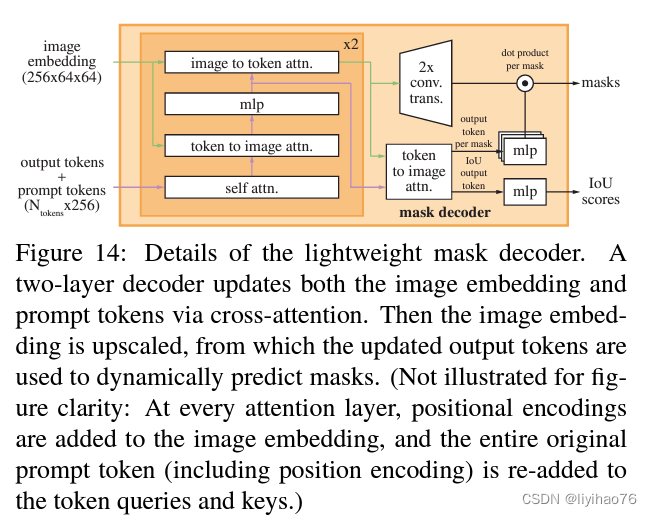
结构描述
- (1) self-attention on the tokens,
- (2) cross-attention from tokens (as queries) to the image embedding,
- (3) a point-wise MLP updates each token,
- (4) cross-attention from the image embedding (as queries) to tokens.
- (5) Additionally, the entire original prompt tokens (including their positional encodings) are re-added to the updated tokens whenever they participate in an attention layer. 提示加了两遍
-
结构分析
- 在prompt embedding进入decoder之前,先在它上面concat了一组可学习的output tokens (相当于dert的queries token,100个tokens),output tokens由两个部分构成:
- 一个是iou token,它会在后面被分离出来用于预测iou的可靠性(对应结构图右侧的IoU output token),它受到模型计算出的iou与模型计算出的mask与GT实际的iou之间的MSE loss监督;
- 另一个是mask token,它也会在后面被分离出来参与预测最终的mask(对应结构图右侧的output token per mask),mask受到focal loss和dice loss 20:1的加权组合监督。
- 这两个token的意义我感觉比较抽象,因为理论来说进入decoder的变量应该是由模型的输入,也就是prompt和image的映射构成,但这两个token的定义与prompt和image完全没有关系,而是凭空出现的。从结果反推原因,只能把它们理解成对模型的额外约束,因为它们两个参与构成了模型的两个输出并且有loss对他们进行监督。
- 最终prompt embedding(这一步改名叫prompt token)和刚才提到这两个token concat到一起统称为tokens进入decoder。
- image embedding在进入decoder之前也要进行一步操作:dense prompt由于包含密集的空间信息,与image embedding所在的特征空间一致性更高,所以直接与image embedding相加融合。因为后面要与prompt做cross attention融合,这里还要先算一下image embedding的位置编码。
- 接下来{image embedding,image embedding的位置编码,tokens}进入一个两层transformer结构的decoder做融合。值得注意的是,在transformer结构中,为了保持位置信息始终不丢失,每做一次attention运算,不管是self-attention还是cross-attention,tokens都叠加一次初始的tokens,image embedding都叠加一次它自己的位置编码,并且每个attention后边都接一个layer_norm。
- tokens先过一个self-attention。
- tokens作为q,对image embedding做cross attention,更新tokens。
- tokens再过两层的mlp做特征变换。
- image embedding作为q,对tokens做cross attention,更新image embedding。
- 更新后的tokens作为q,再对更新后的image embedding做cross attention,产生最终的tokens。
- 更新后的image embedding过两层kernel_size=2, stride=2的转置卷积,升采样到4x大小(依然是4x降采样原图的大小),产生最终的image embedding。
- 接下来兵分两路:
- mask token被从tokens中分离出来(因为他一开始就是concat上去的,可以直接按维度摘出来),过一个三层的mlp调整channel数与最终的image embedding一致,并且他们两个做矩阵乘法生成mask的预测。最终的image embedding大小为[token长度(channel),图像长,图像宽],mask token的大小为[token长度(channel),token个数(最终生成的mask个数)]。两者点乘后的大小为[token个数(最终生成的mask个数),图像长,图像宽]。也就是说有几个token个数生成几个mask。
- iou token被从tokens中分离出来,也过一个三层的mlp生成最终的iou预测。在反向传播时,排序mask,参与计算的只有loss最小的mask相关的参数。
- 最后,如前文所述,分别对mask的预测和iou预测进行监督,反向传播,更新参数。每一个mask,会随机产生11种prompt与之配对。
- 在prompt embedding进入decoder之前,先在它上面concat了一组可学习的output tokens (相当于dert的queries token,100个tokens),output tokens由两个部分构成:
对于一个输出,如果给出一个模糊的提示,该模型将平均多个有效的掩码。为了解决这个问题,我们修改了模型,以预测单个提示的多个输出掩码(比如说提示在衣服上,会分出来衣服的mask和人的mask)。我们发现3个掩模(output/mask token的个数为3)输出足以解决大多数常见的情况(嵌套掩模通常最多有三个深度:整体、部分和子部分)。在训练期间,我们只支持mask上的最小损失[匈牙利损失]。为了对掩码进行排名,该模型预测了每个掩码的置信度分数(即估计的IoU)

# transformer.py def forward( self, image_embedding: Tensor, image_pe: Tensor, point_embedding: Tensor, ) -> Tuple[Tensor, Tensor]: """ Args: image_embedding (torch.Tensor): image to attend to. Should be shape B x embedding_dim x h x w for any h and w. image_pe (torch.Tensor): the positional encoding to add to the image. Must have the same shape as image_embedding. point_embedding (torch.Tensor): the embedding to add to the query points. Must have shape B x N_points x embedding_dim for any N_points. Returns: torch.Tensor: the processed point_embedding torch.Tensor: the processed image_embedding """ # BxCxHxW -> BxHWxC == B x N_image_tokens x C bs, c, h, w = image_embedding.shape image_embedding = image_embedding.flatten(2).permute(0, 2, 1) image_pe = image_pe.flatten(2).permute(0, 2, 1) # Prepare queries queries = point_embedding keys = image_embedding # Apply transformer blocks and final layernorm for layer in self.layers: queries, keys = layer( queries=queries, keys=keys, query_pe=point_embedding, key_pe=image_pe, ) # Apply the final attention layer from the points to the image q = queries + point_embedding k = keys + image_pe attn_out = self.final_attn_token_to_image(q=q, k=k, v=keys) queries = queries + attn_out queries = self.norm_final_attn(queries) return queries, keys
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
3. 数据引擎
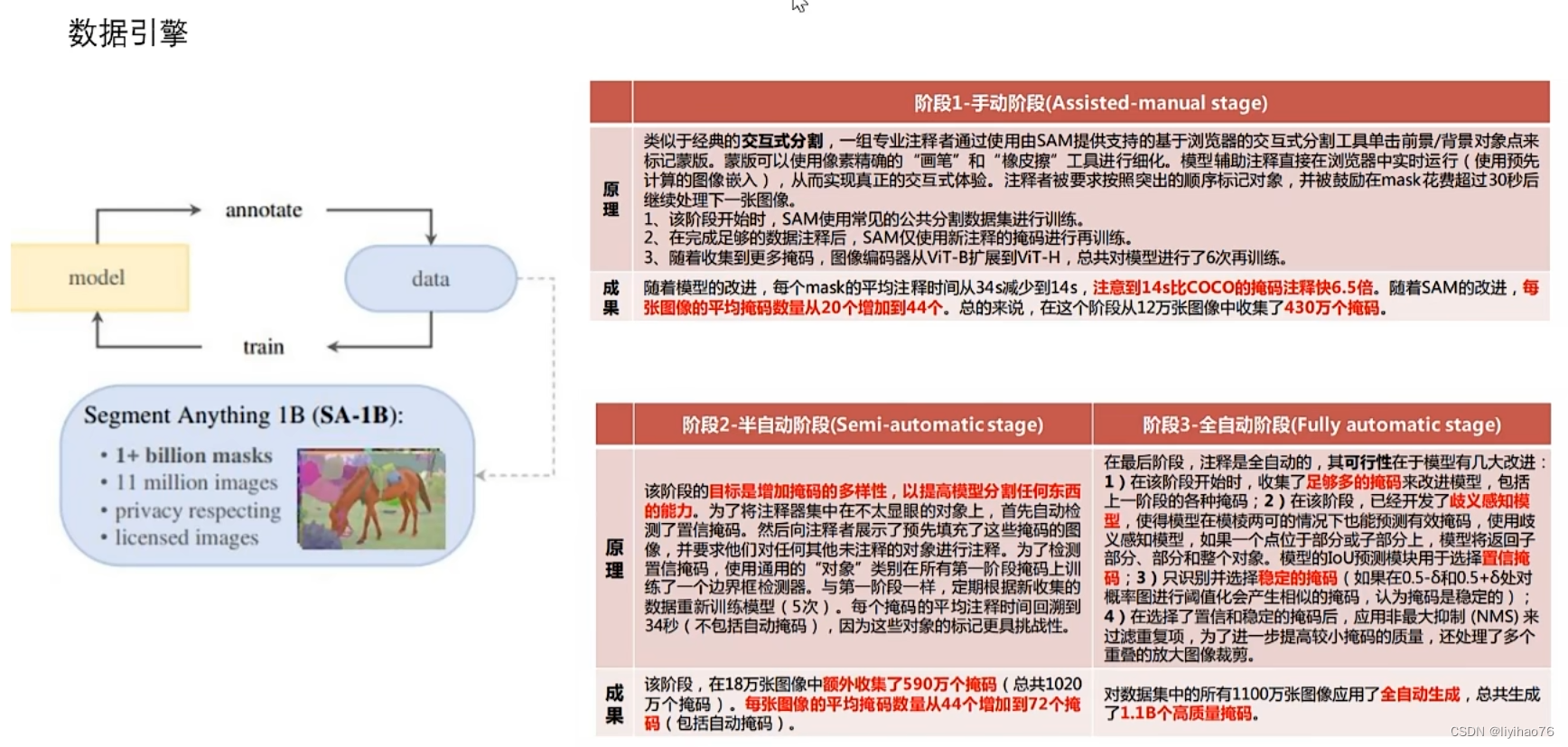
阶段一,手动阶段,模型越来越好,数据越来越多
- 拿现有已经表好的数据集训练一个粗糙版的SAM
- 粗糙版的SAM分割新数据,人工修正后,重新训练模型
- 上两部反复迭代
阶段二,半自动阶段,默认准确率够高,召回率不够好(漏标)
- 用训练好的SAM模型分割图像
- 把分割不出来的给人来标
- 重新训练模型
阶段三,全自动阶段
- SAM模型在图像上分割,对得分较高,准确率较高,符合设定规则的结果进行保留
4. 讨论

SAM的一个我个人认为比较新颖的点子是它从interactive segmentation引申出了一个新的任务类型,叫做promptable segmentation。从他的模型中也能看出,输入的prompt是模型在输出最终mask的关键指导信息,这也是为什么我发现目前的SAM模型在处理一些专业领域图像(比如我自己从事的医学图像分割)时,直接使用他的segment everything功能,也就是无prompt进行分割时效果不好的原因。
另一个要搞清楚的问题是在进行有prompt的分割时,实际上实现的是一个二分类的分割任务,模型要解决的问题是根据我们选择的点的特征,从图像(背景)中分割出这个点所在的目标物体(前景),它本质上并不关心这个目标物体是个什么东西。滑稽一点来说,整个过程实际上有点类似photoshop里魔棒的功能,adobe倒是可以考虑把这个模型整合进ps里提升一些性能。

