
- 1Github 2024-06-26 C开源项目日报 Top10
- 2鸿蒙OS开发实例:【ArkTS类库异步并发简述Promise】_鸿蒙开发[object promise]
- 3小白篇--如何在本地搭建 go环境
- 4Linux系统资源监控nmon工具下载及使用介绍_linux 在线下载 nmon
- 5第七篇:微信小程序的跳转页面_小程序跳转页面
- 6使用supportFragmentManager管理多个fragment切换_the fragment supportrequestmanagerfragment{45c75e5
- 7Linux中永久挂载_linux永久挂载
- 8数电(第一章 数制和码制)_数电第一章
- 9基于STM32单片机智能无人机姿态检测MPU6050陀螺仪角度设计23-179_单片机控制陀螺仪
- 10基于Visual Studio Code搭建Python开发环境_vscode配置python开发环境_visual studio code python
c语言实现数据结构中的单向链表_c语言 单向链表
赞
踩
一.顺序表的缺点
我们在上一篇文章当中学习了顺序表,但是我们发现顺序表存在着如下几个明显的缺点:
- 顺序表从中间或者头部插入一个数据或者删除一个数据的话,我们的时间复杂度都是O(N),这个效率是不是就很低啊。
- 顺序表的整容会像空间申请数据,而这个增容的过程会有异地扩容的可能,这个异地扩容会有拷贝数据和释放空间的过程,那么这样的话就会有不小的性能上的消耗。
- 顺序表的增容,一半都是以两倍的增率进行扩张,那么这就势必会造成一定程度上的空间的浪费,比如说我们这里的已经有1w个数据了,那么我们要在想插入数据的话,我们就得扩容,扩容之后我们的空间就是可以存放2w个数据,但是我们这里只需要再装两个数据呢?那么这里是不是就照成了很大程度上的空间浪费啊。
那么上面的三个问题想必大家在实现顺序表的时候以及发现了,那么我们是不是就得想办法来解决我们上面出现的问题啊,那么我们这里就可以来看看我们这章主要的内容用c语言实现数据结构中的链表。
二.单向链表的基本介绍
顺序表的存储形式是一段连续的空间来存储数据,就像这样:

数据在内存当中一个挨着一个,但是我们的链表就不是这样,我们链表用图的形式来看的话就长这样:

这个图是什么意思呢?我们首先来看这里的data就是我们要储存的数据,然后我们这里将一个一个的方块看成一个整体,这些不同的方块他是储存在内存中不同的位置上的,所以我们这里在中间或者头部插入数据的时候就不存在挪动数据的一个说法,既然我们这不同的数据储存在内存中的不同的地方,那我们如何来找到我们要存储的数据呢?所以我们这里就有next这一个小的模块,这个模块中存储的就是下一个数据所在位置,也就是说我们可以通过第一个数据找到第二个数据的位置,然后我们有可以通过第二个数据找到第三个数据的位置,这样一一的遍历下去我们就可以找到整个顺序表中的数据,那么我们这里就可以来尝试着实现这个链表。
三.链表的基本创建
根据上面的图可以看到外面这里的一个方块里面有着两个模块,所以我们这里就得创建一个结构体的类型出来,我们这个结构体里面就得有两个数据,一个是用来存储数据的,另外一个用来记录下一个结构体在哪的,那么假设我们这里的链表是用来存储整型数据的,那么我们这里就得有一个ine类型的数据,和一个结构体类型的指针,那么为了方便以后我们的修改和增加内容我们就用typedef来改变一下名字,那么我们的结构体创建就如下:
typedef int SLTDataType;
typedef struct SListNode
{
SLDataType data;
struct SListNode* next;
}SLTNode;
- 1
- 2
- 3
- 4
- 5
- 6
有些小伙伴看到我们这里重命名之后就想着这样写代码,他说既然我们这里进行重命名的话,那我们能不能将结构体里面的那个结构体指针类型也来替换一下呢?比如说下面的代码:
typedef struct SListNode
{
SLDataType data;
SLTNode* next;
}SLTNode;
- 1
- 2
- 3
- 4
- 5
大家要是这么写的话那就会报出错误,因为我们的重命名成功的前提是我们这里的重命名的对象首先得存在并且没有出错,就比如说typedef int a;这个执行过程是先检查int这个东西是存在并且没错之后,他才能将a赋予与int一样的功能,那反观我们上面的代码typedef struct SListNode SLTNode 在执行这个语句的时候是不是就得先看看这个struct SListNode这个结构体是否存在且正确啊,但是这里在检查的时候就会发现我们这个结构体里面出现了一个不认识的东西SLTNode* next;因为我们还没有执行到下一步所以现在的SLTNode并没有和struct SListNode一样的功能所以我们这里就会报错,大家可以类比先有鸡还是先有蛋来理解理解。还有小伙伴们见过这样的代码:
typedef struct SListNode
{
SLDataType data;
struct SListNode* next;
}*PSLTNode;
- 1
- 2
- 3
- 4
- 5
那么我们这个代码中的PSLTNode的功能就和该结构体的指针是一模一样的。我们之前聊过嘛这里就稍微提醒一下,以免突然懵了。
四.链表的打印
好有了前面的基础,那么我们这里来一步一步实现我们链表的种种功能,首先就是我们这里的链表的打印,因为我们之前说过结构体在传参的时候尽量都传结构体的指针,所以我们这里函数的参数就是只有一个结构体的指针,那该函数的声明就是这样:
void SLPrint(SLTNode* psl);
- 1
好我们这里的函数声明完成之后我们就来实现我们的函数体,我们这里就先想一个问题:我们这里需不需要断言啊,根据我们之前实现顺序表的时候每个函数都断言了,那么我们这里需要断言吗?如果这里大家犹豫不决的话,我们先来想想我们这里断言的目的是什么?我们之前在实现顺序表的时候是因为你传过来的指针他不可能是空指针,所以我们来进行一下断言来防止你传过来一个空指针,那要是这么看的话,我们这里断不断言完全取决于,你这里传过的值可不可能是个空指针,所以我们这里来想一下,我们这里先创建出来一个结构体的指针变量,让这个变量指向我们链表的头部,嗯?头部?那要是我们没有头呢?我们的链表一个元素都没有呢?那你这个指向是不是就是为空啊,所以我们这里传过来的值是可能为空的对吧,那么我们这里就不需要断言,因为他本来就可以为空。我们讨论完是否该断言之后接着就来看看如何来打印顺序表中的元素,首先我们这里的元素是放到每个结构体中的date,那么我们这里就可以通过传过来的结构体指针来访问我们这里的数据,因为我们这里的数据肯定是不止一个的,所以我们还得通过结构体里面的指针来找到下一个元素的位置,所以我们这里得创建一个变量cur来记录当前打印数据的位置,并且我们还得创建出来一个循环,在该循环不停的找到下一个元素的位置,并且打印出该元素的值,那我们这里的循环结束的条件是什么呢?我们说这个结构体里面的next装的是下一个结构体的位置,那我要是最后一个元素呢?该结构体里面的next装的又是什么呢?是不是NULL啊,所以我们这里循环结束的条件就是当cur==NULL时就结束循环,那么我们的代码就如下:
void SListPrint(SLTNode* phead)
{
SLTNode* cur = phead;
while (cur != NULL)
{
printf("%d ", cur->data);//打印链表中的数据
cur = cur->next;//将指针跳转到下一个结构体的位置上去
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
五.链表的头插
我们知道了如何来打印数据,但是打印数据的前提是不是得先有数据啊,所以我们这里就来看看如何插入数据,我们先来实现头插,在插入数据之前我们得先开辟一个空间来装一个结构体,然后把我们要插入地数据放到这个结构体里面,最后把这个结构体装到链表里面啊,所以我们这里就得使用malloc在堆区上面开辟一个空间,那这里为什么是堆区呢?因为我们在栈区上开辟的空间会随着函数的结束而自动地释放,所以我们这里使用地是堆区。那我们这里又是如何将这个结构体插入这个链表呢?我们说链表之所以能够连接起来就是因为每个元素都是一个结构体,该结构体里面有一个指针,该指针指向的是下一个元素的地址,因为我们这里是头插,所以我们这里要想将新开辟插入这个链表只用将新开辟出来的结构体里面的指针指向当前的第一个结构体就可以了,因为我们这里很多地方都要使用开辟一个结构体的这个功能,所以我们这里就将其写成一个函数,可以减少我们之后的工作量,我们该函数的实现就如下:
SLTNode* BuySLTNode(SLTDataType x)//创建节点
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode)); //在堆上开辟一个空间
if (newnode == NULL)//判断是否开辟成功
{
perror("malloc fail");//开辟失败就提醒一下使用者
exit(-1);
}
newnode->data = x;//开辟成功就将你的数据放到这个结构体里面
newnode->next = NULL;//将指针的内容初始化为空
return newnode;//返回开辟成功的地址
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
那么我们这里创建节点的函数就完成了,我们再来实现头插的函数,我们首先来看看这个函数的声明该如何来写?那么这里最关键的就是这里的参数是什么?首先可以确定的一点就是肯定有SLTDataType x因为你要告诉我们你插入的数据是什么对吧,就这一个吗?当然不是,我们还得来一个来一个头节点,该节点是在main函数里面进行创建的,用来记录该链表的第一个位置的,我们之前说要想将该结点与整个链表连起来是不是得知道该链表的第一个节点的位置啊,所以我们这里就得将链表的第一个位置传过来,但是将地址传过来没用,因为我们这里是头插会改变链表中第一个节点的位置,所以我们这里传的是二级指针,得将main函数中记录头节点位置的变量的值进行修改,那么我们的函数实现如下:
void SListPushFront(SLTNode** pphead, SLTDataType x)//头插链表
{
assert(pphead);
SLTNode* newnode = BuySTLNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
好该函数实现完了我们就来测试一下看看是否是对的:
#include"SListNode.h"
int main()
{
SLTNode* phead = NULL;
SListPushFront(&phead, 1);
SListPushFront(&phead, 2);
SListPushFront(&phead, 3);
SListPushFront(&phead, 4);
SListPushFront(&phead, 5);
SListPrint(phead);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
我们来看看这段代码的运行结果:
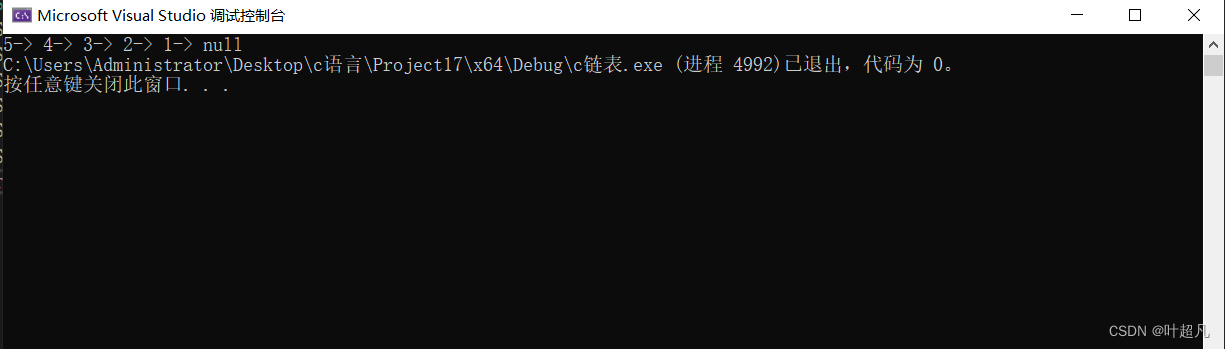
那么这里打印的结果却是和我们的预料的一模一样,所以我们这里的函数实现就是正确的。
六.链表的尾插
既然我们实现了头插,那么这里我们就再来实现一下尾插。那我们这里先来想一想第一个问题,我们这个函数需要的参数是一级指针还是二级指针,我们先来想想我们之前的头插为什么要传二级指针?是不是因为我们这里传过来的地址是指向这个链表的头部,而我们头插的时候得找到头部才能进行头插啊,但是又因为我们这里的头插会改变我们这里头部的地址,所以我们得传二级指针来改变我们外部的指向头部的一级指针啊,那么我们这里的尾插会改变头部的地址吗?那么这时候肯定有小伙伴们会说啊,这尾插怎么可能会改变头部的地址呢!肯定传的是一级指针啊,那如果你是这么想的话,那就考虑的不周全了啊,如果我们这里一个元素都没有呢?那传过来的是不是就是一个空指针啊,那这时我们再尾插是不是就得改变我们这里的头部的地址啊,所以我们这里的尾插就得你风情况来讨论,如果是我们传过来的指针是空的话我们就得改变这个指向头部的指针,如果不是我们就不用改变,好经过我们上面的分析我们知道了传过来的得是一个二级指针,那我们这里就再来看看如何实现尾插,那么我们这里的链表是通过指针连接起来的,所以我们这里的尾插就得先找到这个链表的最后一个元素,然后再将这个最后一个元素中的next指针指向我们这里要插入的元素,所以我们这里就存在一个问题我们如何来找到尾呢?那么我们这里就得通过遍历的形式来找到我们的尾部,我们创建一个while循环,然后在创建一个指针变量cur将他的值初始化为指向这个链表的头部,那么我们这个while循环里面干的事就是将cur的值赋值为指向链表中的下一个元素的地址,代码就是这样:cur=cur->next;那该循环结束的标志就是当cur->next==NULL的时候我们就结束循环,此时cur就指向链表中的最后一个元素,那这时再来进行链表的连接就非常的简单了,一种情况讨论完了,我们再来看看第二种情况:要是一个元素都没有呢?那这也很简单嘛,跟我们之前的头插一样,那我们来看看下面的代码:
#include"SListNode.h"
int main()
{
SLTNode* phead = NULL;
SListPushFront(&phead, 1);
SListPushFront(&phead, 2);
SListPushFront(&phead, 3);
SListPushFront(&phead, 4);
SListPushFront(&phead, 5);
SListPushBack(&phead, 6);
SListPrint(phead);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
那我们来看看这个测试打印的结果为:
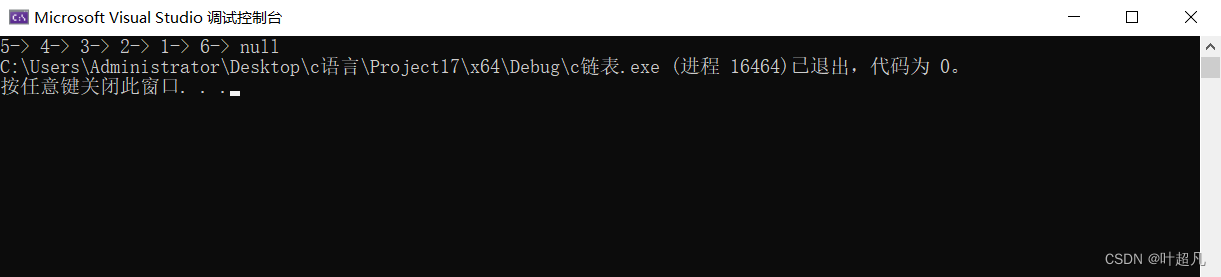
好我们这里有元素的尾插实现成功了,那我们再来看看没有元素的尾插还能达到效果吗:
#include"SListNode.h"
int main()
{
SLTNode* phead = NULL;
SListPushBack(&phead, 6);
SListPushBack(&phead, 5);
SListPushBack(&phead, 4);
SListPrint(phead);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
我们再来看看打印的结果:
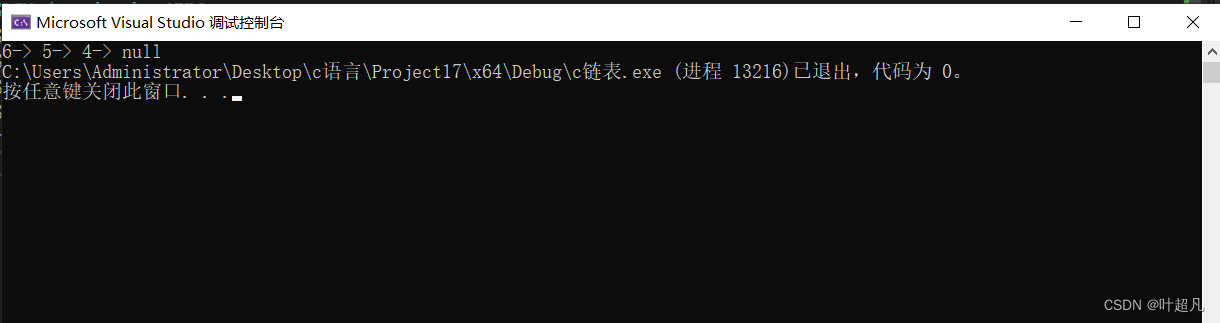
那么我们这里打印的结果也符合我们的预期,那么我们这个函数的实现就成功了,那我们接着往下看。
七.链表的头删
首先毫无悬念的我们这里需要的是一个二级指针,因为我们这里的头删需要改变这里指向头部的指针,然后我们这里的在删除前是不是还得做一件事就是判断一下我们这里还能不能删除,要是我一个元素都没有了你还执行删除指令的话是不是就会出错啊,所以我们这里就得来判断一下还能不能删除,那么我们这里就可以使用assert来进行断言,当我们一个元素都没有的话我们这里传过来的指针是不是就是一个空指针啊,所以我们这里的断言就可以这么写:assert(phead),好我们的判断完之后我们就来想想如何来进行删除,因为我们这里申请的是一个元素一个元素的申请的,所以我们这里的删除就可以直接将其free掉就可以了,但是在free之前我们得将头指针指向第二个元素,那么这时候我们就创建出来一个变量出来,这个变量就是用来记录第二个元素的地址的,那么此时我们free完之后再将头指针进行一下改变,那么我们的代码就如下:
void SListPopFront(SLTNode** pphead)//头删
{
assert(pphead);
assert(*pphead);
SLTNode* cur = ( * pphead)->next;
free(*pphead);
*pphead = cur;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
我们再来进行一下测试:
#include"SListNode.h"
int main()
{
SLTNode* phead = NULL;
SListPushBack(&phead, 6);
SListPushBack(&phead, 5);
SListPushBack(&phead, 4);
SListPopFront(&phead);
SListPopFront(&phead);
SListPushBack(&phead, 3);
SListPushBack(&phead, 2);
SListPrint(phead);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
我们来看看这段代码的运行结果为:
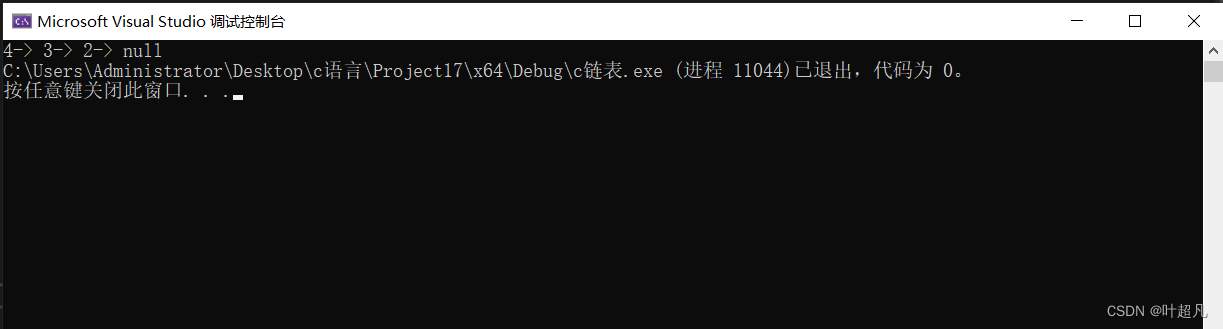
那么我们这里就达到了我们预期的结果,所以我们的函数实现是正确的。
八.链表的尾删
有了头删按道理来说就有尾删,那么我们这个根据前面的经验我们这里要实现尾删的话就得先找到尾,然后再将这个尾释放掉就可以了,就像下面的代码这样:
void SListPopBack(SLTNode* phead)//尾删
{
assert(phead);//防止过度删除
SLTNode* cur = phead;
while (cur->next != NULL)
{
cur = cur->next;
}
free(cur);
cur = NULL;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
那我们来测试一下这个代码的结果:
#include"SListNode.h"
int main()
{
SLTNode* phead = NULL;
SListPushBack(&phead, 6);
SListPushBack(&phead, 5);
SListPushBack(&phead, 4);
SListPopBack(phead);
SListPopBack(phead);
SListPushBack(&phead, 3);
SListPushBack(&phead, 2);
SListPrint(phead);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
但是我们将其调试起来的话就会发现他爆出来了这样的问题:
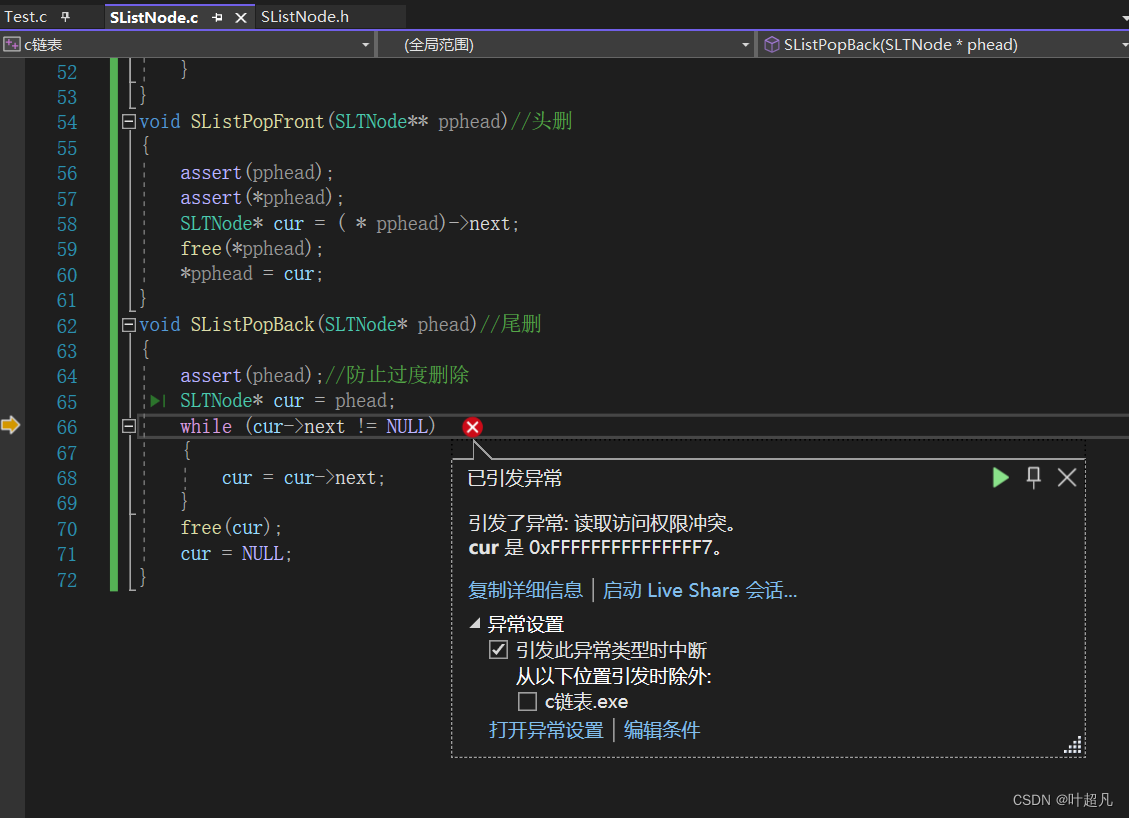
那这是为什么呢?大家想一下我们在尾删的时候是不是直接将最后一个元素进行删除了的啊,我们删除之后这个元素对应的空间是不是就应该是属于我们的操作系统了啊,但是我们这里的倒数第二个元素中的next指针却依然指向这个空间,所以这里的循环找的尾依然是删除之后的那个空间,但是那个空间已经属于我们的操作系统了啊,所以这里就会报出错误,原因是野指针引起来的错误,那么我们这里的解决方法就是还得找到倒数第二个元素,删除元素之后还得将倒数第二个元素中的next指针置为空,那么我们这里就得创建两个变量,这个一个变量在前一个变量在后,每次循环都将两个变量往后走一位,当后面的那个变量指向的元素中的next为空的话就结束循环,那么这是我们就得到了最后两位的元素的地址,那么我们的代码如下:
void SListPopBack(SLTNode* phead)//尾删
{
assert(phead);//防止过度删除
SLTNode* prev = NULL;
SLTNode* cur = phead;
while (cur->next != NULL)
{
prev = cur;
cur = cur->next;
}
prev->next = NULL;
free(cur);
cur = NULL;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
我们再来测试一下上面的代码是否正确:
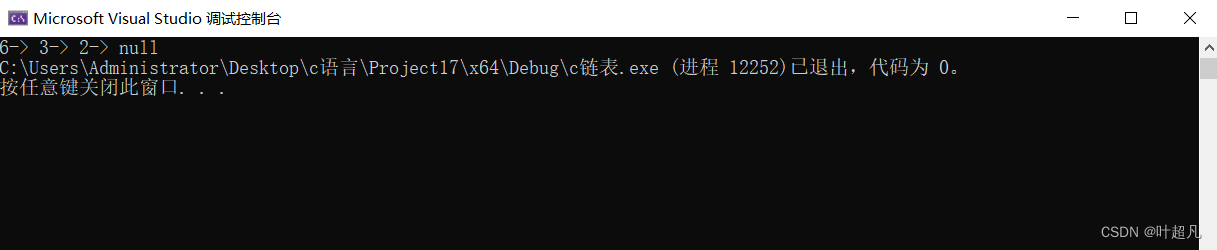 我们发现这里却是是正确的,但是这个函数的实现就一定是对的吗?答案并不是的,我们来想一下当我们只有一个元素的时候,这个代码还正确吗?那么这里我们带到这个逻辑里面看的话就会发现完全不正确,如果只有一个元素的话我们这个循环都不会进去,所以我们的prev此时还是为空的,所以后面代码就完全不用看了,并且当我们只有一个元素的时候我们还得改变外面指向头部的那个指针的值,所以我们这里的函数的参数还得修改一下:将一级指针改成二级指针,那么我们这里的代码就是这样:
我们发现这里却是是正确的,但是这个函数的实现就一定是对的吗?答案并不是的,我们来想一下当我们只有一个元素的时候,这个代码还正确吗?那么这里我们带到这个逻辑里面看的话就会发现完全不正确,如果只有一个元素的话我们这个循环都不会进去,所以我们的prev此时还是为空的,所以后面代码就完全不用看了,并且当我们只有一个元素的时候我们还得改变外面指向头部的那个指针的值,所以我们这里的函数的参数还得修改一下:将一级指针改成二级指针,那么我们这里的代码就是这样:
void SListPopBack(SLTNode** pphead) { assert(pphead); assert(*pphead); if ((*pphead)->next == NULL) { SListPopFront(pphead); } else { SLTNode* prev = NULL; SLTNode* cur = *pphead; while (cur->next != NULL) { prev = cur; cur = cur->next; } prev->next==NULL; free(cur); cur = NULL; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
九.链表的查找
那么我们这里的查找那肯定是遍历式的查找,如果找到这个值我们就返回这个值的地址,如果没有找到,那么我们就返回一个空指针,我们这个函数的参数就有两个一个是你要查找的值,另一个就是指向头部的指针但是这个函数的返回值得是一个结构体的指针,那我们函数的声明就是这样:void SListFind(SLTNode* phead, SLTDataType x);而我们函数的具体实现就很简单了嘛,直接通过循环来遍历寻找,找到了就直接返回该元素的地址,在循环外面就返回一个空指针,因为我们循环结束的话就说明我们已经把整个链表都找完了,如果此时还没有返回地址的话就说明找不到了,那么我们的代码就如下:
void SListFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
while (cur->next != NULL)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
这个函数的测试我们就放到后面来和其他的函数一起测试。
十.函数指定位置的插入
只有头插和尾插肯定是满足不了我们日常的需求的,所以我们这里还有一个指定位置的插入,那么这个插入是前插,首先我们这个函数的参数就是一个你要插入的值,另外一个就是你要插入的地方,还有一个就是指向这个链表的头指针,那么我们函数声明就是这样:void SListInsert(SLTNode** pphead,SLTNode*pos, SLTDataType x);那么接下来就是我们函数实现的过程首先我们得通过循环来找到这个这个指定的位置,找到之后我们就来创建节点newnode,然后我们这里就得将newnode插入到指定位置的前面,而我们这里插入的时候就得先将newnode的next指向pos,再将pos前面的节点的next指向newnode,那么我们的代码就如下:
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pphead);
SLTNode* prev = *pphead;
while (prev->next!=pos)
{
prev = prev->next;
assert(prev);//找不到我们就报错
}
SLTNode* newnode = BuySLTNode(x);
newnode->next = pos;
prev->next = newnode;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
那么我们这里就来测试一下,我们测试的代码就是这样:
#include"SListNode.h"
int main()
{
SLTNode* phead = NULL;
SListPushBack(&phead, 6);
SListPushBack(&phead, 5);
SListPushBack(&phead, 4);
SListPushBack(&phead, 3);
SListPushBack(&phead, 2);
SLTNode*cur=SListFind(phead, 4);
SListInsert(&phead, cur, cur->data * 10);
SListPrint(phead);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
那么这里的代码运行结果就是这样:
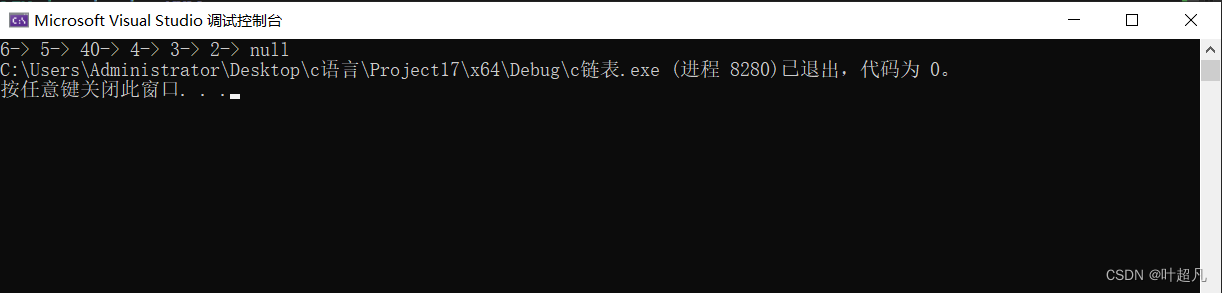
但是这里的代码运行结果是对的吗?是对的,但是我们这个代码是对的吗?不对!因为我们这里是中间插入代码的运行却是没有问题,那我这里想从头部插入呢?按照我们这个逻辑是不是就有问题啊,我们完全找不到前一项,所以我们这里的就得将其分开讨论,当这里的插入元素的位置为头部的时候和其他位置的时候,那么我们这里代码优化的结果就是这样:
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x) { assert(pphead); assert(pos); if (*pphead == pos) { SListPushFront(pphead,x); } else { SLTNode* prev = *pphead; while (prev->next != pos) { prev = prev->next; assert(prev);//找不到我们就报错 } SLTNode* newnode = BuySLTNode(x); newnode->next = pos; prev->next = newnode; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
十一.指定位置的删除
那么我们这里就可以来根据上面的那个思路来实现我们这个函数,首先找到前面的节点,再找到后面的节点,然后将前面的节点中的next指向后面的节点,再将指定位置的节点进行释放就可以了,那么这种思路也是要找前面的节点的,所以我们这里也得分情况来讨论一下:当指定是头部的时候,和其他位置的时候,那么我们这里的代码实现就如下:
void SListErase(SLTNode** pphead, SLTNode* pos) { assert(pphead); assert(pos); if (pos == *pphead) { SListPopFront(pphead); } else { SLTNode* cur = pphead; while (cur->next != pos) { cur = cur->next; } cur->next = pos->next; free(pos); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
十二.链表的销毁
那么我们创建了一个链表并使用了链表,那么我们这里的链表使用完了之后是不是就得将其进行销毁啊,所以我们这里就创建一个函数来负责将这个链表进行销毁,那么我们这里就得创建两个两个结构体的指针变量一个在前(next)一个在后(cur),那么我们这里就放到一个循环里面,先将next的值赋值为cur->next,再释放我们的cur,因为我们释放之后就无法通过cur找到下一个元素的位置,但是我们的next记录了下一个元素的位置,所以我们再把next的值赋值给我们的cur,那么我们这个循环结束的条件就是当cur值等于空的时候我们就结束了循环,那么我们的代码如下:
void SListDestory(SLTNode** pphead)
{
SLTNode* next = NULL;
SLTNode* cur = *pphead;
while (cur != NULL)
{
next = cur->next;
free(cur);
cur = next;
}
*pphead = NULL;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
十三.顺序表和链表的对比
1.顺序表的优点
1.尾插尾删的效率非常的高,我们可以直接把元素的个数作为下标来插入我们想要的元素。
2.随机访问,因为我们这里元素的储存是连续的,所以我们可以通过下标来实现元素的随机访问。
3.相对于链表的结果,顺序表cpu高速缓存的命中率更高。那这个是什么意思呢?就是说我们cpu在读取数据的速度比内存传送数据的速度要快很多,所以我们这里就有高数缓存这个东西,他可以提前将内存中的数据提取出来,然后我们的cpu再从高速缓存中提取数据出来,这样我们的效率就会更高,而且我们这里的提取数据不是只把那个数据提取出来就完了,而是把那个数据周围的一些数据也顺便提取出来,那么这样的话我们再来看看顺序表因为我们这里的数据放的都是在一起的,所以我们这里提取一次数据就会顺带着把很多有用的数据都提取出来,而我们的链表呢?他的存储特征是分散的,周围可能都是一些没有用的数据,而我每次要用的时候都得到主存中提取,而且提取一个有用的数据还会带着一堆没用的数据进入我们的高速缓存,高数缓存的大小还是固定的,所以提取多了之后还得清楚一些没有的数据,那么这也会照成效率的损耗,所以这就是我们顺序表的一个优点。
2.顺序表的缺点
1.头部和中部的插入删除的效率低–o(N),但是这个用到的地方并不多。
2.扩容的时候会照成内存和性能的损耗。
3.链表的优点
1.任意位置的插入和删除效率都很高–o(1)
2.还可以按需来申请和释放空间。
4.链表的缺点
1.不支持随机访问。
`

