
- 1neo4j如何创建多个数据库_neo4j社区版建立两个库
- 2python毕业设计作品基于django框架 二手物品交易系统毕设成品(6)开题答辩PPT_二手交易网站答辩ppt
- 3高新面试系列 性格篇_我满脑子创业并有所行动心理测试
- 4点击劫持技术原理简述_点击劫持的原理及方法
- 5智慧校园平台建设中教育软件信创化的全面审视与战略部署
- 6Tomcat 8 性能优化_tomcat8 protocol=
- 7如何很好的理解机器学习模型,为什么大数据(Big data) 和大语言模型(Large Language Model, LLM)会变得那么火,会变得有效?_大语言模型与大数据
- 8鸿蒙一次开发,多端部署(七)响应式布局_鸿蒙breakpointsystem
- 9C++数据结构补充(双向链表)_c++ 双向链表
- 10倒计时2天!WAVE SUMMIT+ 2023将开启,五大亮点抢鲜看!
LLaMA-Factory微调多模态大语言模型教程_pip install -e .[torch,metrics]
赞
踩
本文旨在结合笔者自身的实践经历,详细介绍如何使用 LLaMA-Factory 来微调多模态大语言模型。目前仓库已支持若干流行的MLLM比如LLaVA-1.5,Yi-VL,Paligemma等。
2024.5.29 注:本文后续不再更新,如果想了解更新的特性和功能欢迎访问知乎博客:https://zhuanlan.zhihu.com/p/699777943
值得注意的是现在LLaMA-Factory引入了CLI,因此调用方式更加简单,只需要简单的几行命令即可开始微调。
环境准备
首先安装LLaMA-Factory
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .[torch,metrics]
- 1
- 2
- 3
检查机器含有可用GPU
import torch
try:
assert torch.cuda.is_available() is True
except AssertionError:
print("Please set up a GPU before using LLaMA Factory")
- 1
- 2
- 3
- 4
- 5
多模态多轮对话数据集构建
这里出于方便的考虑,以仓库自带的 mllm_demo 数据集作为例子。在此也推荐一些笔者创建的hf数据集可供使用,都能适配LLaMA-Factory,场景分别是通用,医学,动漫。
https://huggingface.co/datasets/BUAADreamer/llava-en-zh-300k
https://huggingface.co/datasets/BUAADreamer/llava-med-zh-instruct-60k
https://huggingface.co/datasets/BUAADreamer/pokemon-gpt4-1k
本地图像准备
项目的 data/mllm_demo_data 目录下有三张比较新的图像,两张为拜仁慕尼黑的球员本赛季在主场庆祝,1张为桂海潮教授在演讲。本文以这三张图像作为例子进行讲解,读者可以换成任意的自己的图像

data/mllm_demo_data/1.jpg

data/mllm_demo_data/2.jpg

data/mllm_demo_data/3.jpg
本地多轮对话数据构建
直接修改 data/mllm_demo.json 即可,这里用python写入文件作为演示,格式遵循类似openai的聊天格式。images 参数设置为含有一张图像所在路径的列表。注意:这里的图像路径为绝对路径或相对于当前位置的相对路径。
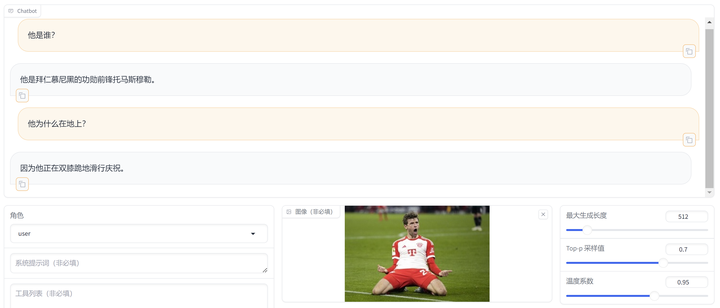
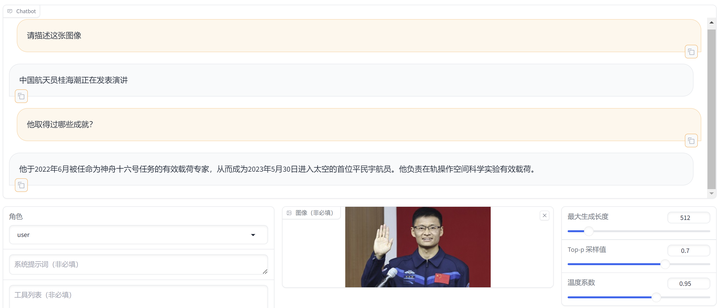
[ { "messages": [ { "content": "他们是谁", "role": "user" }, { "content": "他们是来自拜仁慕尼黑的主力中锋凯恩和主力中场格雷茨卡。", "role": "assistant" }, { "content": "他们在做什么?", "role": "user" }, { "content": "他们在拜仁慕尼黑主场激情庆祝。", "role": "assistant" } ], "images": [ "data/mllm_demo_data/1.jpg" ] }, { "messages": [ { "content": "他是谁?", "role": "user" }, { "content": "他是拜仁慕尼黑的功勋前锋托马斯穆勒。", "role": "assistant" }, { "content": "他为什么在地上?", "role": "user" }, { "content": "因为他正在双膝跪地滑行庆祝。", "role": "assistant" } ], "images": [ "data/mllm_demo_data/2.jpg" ] }, { "messages": [ { "content": "请描述这张图像", "role": "user" }, { "content": "中国航天员桂海潮正在发表演讲", "role": "assistant" }, { "content": "他取得过哪些成就?", "role": "user" }, { "content": "他于2022年6月被任命为神舟十六号任务的有效载荷专家,从而成为2023年5月30日进入太空的首位平民宇航员。他负责在轨操作空间科学实验有效载荷。", "role": "assistant" } ], "images": [ "data/mllm_demo_data/3.jpg" ] } ]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
本地数据更新至dataset_info.json
如果是自己创建的本地新数据集,需要在 data/dataset_info.json 里加入对应的信息
"mllm_demo": {
"file_name": "mllm_demo.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
},
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
上传数据集到huggingface
以上是图像存储在本地的使用方法,如果想分享自己的数据集,可以使用下列代码,需要先到huggingface申请自己的key:https://huggingface.co/settings/tokens
import huggingface_hub huggingface_hub.login("hf_xxxxx") #替换为你自己的key从而登录hf from datasets import Dataset, Features, Image, Sequence, Value def gen(): for data in examples: yield data #构建数据集feature features = Features( { 'messages': [ { 'role': Value(dtype='string', id=None), 'content': Value(dtype='string', id=None), } ], 'images': Sequence(feature=Image(decode=True, id=None), length=-1, id=None), } ) #使用迭代生成 dataset = Dataset.from_generator(gen, features=features) #push到huggingface dataset.push_to_hub("BUAADreamer/mllm_demo")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
huggingface数据更新至dataset_info.json
将上传好的huggingface数据集信息更新在 data/dataset_info.json 中
"mllm_demo_hf": {
"hf_hub_url": "BUAADreamer/mllm_demo",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
},
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
多模态对话微调
配置监督微调Yaml文件
这里以lora为例,我们创建一个 config/llava_lora_sft.yaml
根据自己需求,需要修改的参数主要有:
- model_name_or_path 和 template,对应模型和聊天模板,目前主要支持:
- llava-1.5 和 vicuna
- yi-vl 和 yi_vl
- paligemma 和 gemma
- finetuning_type 和 lora_target ,finetuning_type 可以改为 full 从而全参数微调
- dataset 对应 data/dataset_info.json 对应的数据集的key名字,这里以本地的 mllm_demo 为例
- 其他训练参数比如 learning_rate num_train_epochs output_dir 等。由于llava-1.5主要面向英文,因此中文数据需要较多轮次才能拟合。
### model model_name_or_path: llava-hf/llava-1.5-7b-hf visual_inputs: true ### method stage: sft do_train: true finetuning_type: lora lora_target: q_proj,v_proj ### dataset dataset: mllm_demo template: vicuna cutoff_len: 1024 max_samples: 1000 overwrite_cache: true preprocessing_num_workers: 16 ### output output_dir: saves/llava1_5-7b/lora/sft logging_steps: 10 save_steps: 500 plot_loss: true overwrite_output_dir: true ### train per_device_train_batch_size: 1 gradient_accumulation_steps: 8 learning_rate: 0.0001 num_train_epochs: 50.0 lr_scheduler_type: cosine warmup_steps: 0.1 fp16: true train_mm_proj_only: false ### eval do_eval: false
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
配置LLaVA式的预训练yaml文件
LLaVA中的预训练是只训练 multi_modal_projector ,冻结 language_model 和 vision_tower 。因此我们需要将 finetuning_type 设置为 full ,将 train_mm_proj_only 设置为 true。预训练数据使用单轮图生文对话数据,可以参考以下 mllm_pt_demo 数据集:
https://huggingface.co/datasets/BUAADreamer/mllm_pt_demo
开始微调
一条命令微调。Lora微调只需要16G显存,2min即可跑完
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train config/llava_lora_sft.yaml
- 1
网页聊天测试
一条命令部署。LLaVA-7B只需要16G显存。注意如果是其他模型需要更换为训练中使用的template
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \
--model_name_or_path llava-hf/llava-1.5-7b-hf \
--adapter_name_or_path saves/llava1_5-7b/lora/sft \
--template vicuna \
--visual_inputs
- 1
- 2
- 3
- 4
- 5
微调后Demo展示
以下是三条数据的测试,对于这些比较新鲜的知识模型完全拟合了,(仁迷狂喜
data/mllm_demo_data/1.jpg 测试结果:
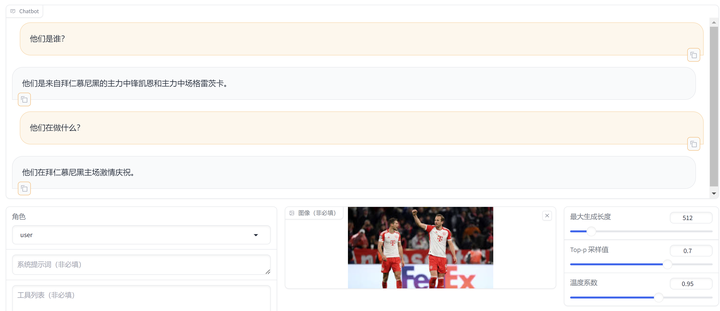
data/mllm_demo_data/2.jpg 测试结果:
data/mllm_demo_data/3.jpg 测试结果:
模型导出和上传huggingface
先配置 config/llava_lora_sft_export.yaml 文件,记得替换 export_hub_model_id 和 hf_hub_token
# model
model_name_or_path: llava-hf/llava-1.5-7b-hf
adapter_name_or_path: saves/llava1_5-7b/lora/sft
template: vicuna
finetuning_type: lora
visual_inputs: true
# export
export_dir: models/llava1_5-7b
export_size: 2
export_device: cpu
export_legacy_format: false
export_hub_model_id: xxxxx/My-LLaVA-7B
hf_hub_token: xxxxx
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
一行命令导出并上传到huggingface
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export config/llava_lora_sft_export.yaml
- 1
总结
所有代码都可以在以下仓库复现
https://github.com/BUAADreamer/MLLM-Finetuning-Demo
同时,笔者也使用 LLaMA-Factory 训练了一个中文医学多模态大模型 Chinese-LLaVA-Med,目前还在探索中,欢迎关注!更多MLLM的微调例子可以参考此项目:
https://github.com/BUAADreamer/Chinese-LLaVA-Med
此外,还有 @hiyouga 大佬训练的多轮对话版本paligemma,值得一提的是,这个模型小而强大,可以做许多多模态任务,还是多语言的:
https://huggingface.co/hiyouga/PaliGemma-3B-Chat-v0.1
![[nlp] torch.load 和 torch.load_state_dict 有什么区别](https://img-blog.csdnimg.cn/img_convert/77fcfea2a41749d7867f62f0e98b01ca.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)

