
- 1阿里大数据之路:数据模型篇大总结(收藏)
- 2PostgreSQL - 查询表结构和索引信息_postgres 查询表的索引字段信息
- 3Android Studio的Gradle错误解决方法_android studio 错误 丢失的gradle项目信息。请检查ide是否成功地将其状态与gr
- 4FPGA原理和结构- 理解FPGA的基础知识_fpga原理和结构天野英晴pdf
- 5一文读懂:区块链的原理、技术、应用领域_区块链技术应用总结
- 6记录一下一些收藏的网页
- 7【开源物联网平台】FastBee使用EMQX5.0接入步骤_java 开源的物联网项目
- 8大数据相关招聘岗位可视化分析-毕业设计_基于大数据的招聘岗位可视化分析与展示
- 9【深度学习论文翻译】基于LSTM深度神经网络的时间序列预测(Time Series Prediction Using LSTM Deep Neural Networks)_epochs = configs['training']['epochs'],
- 10ecc加解密算法 c++_ECC相关算法解析
AI 创业必备:GPU选型攻略_ai 商业gpu 选择
赞
踩
GPU 已成为目前互联网行业内的一大刚需。就算不是做 AI 工具、大语言模型的团队,也有大量场景需要它,比如做游戏的团队,特别是那些需要顶级光影效果的游戏,还有那些鱼流媒体编解码相关的场景,比如视频的超分辨率算法等。但是,对于 AI 创业的团队,更加关注 GPU 的算力如何?我们之前还收到过开发者的询问“应该怎么对比 GPU 的算力?”。我们都知道 NIVIDA 每次的宣传时强调的指标都不完全相同。那么怎么来对比不同架构、我们在这篇文章里,聊聊应该怎么正确对比 GPU 的算力。
先说说不同的品牌
首先,大多数人可能认为 GPU 的算力对比,就是横向比对一下核心处理器数量、核心频率、显存位宽,还有架构、功耗等。这些方法放在同一个品牌的 GPU 上,还可用,但不同品牌,就不一定严谨了。举个例子,AMD 的 GPU 就无法根据规格直接与 NVIDIA 进行比较,因为两者的理念不同。AMD 通常会说我们的内存更大,而 NVIDIA 会说我们的内存更快。而且两者在通用计算领域,其实差距早已经拉开了。
2008 年,NVIDA 发布了 Tesla 架构,在那个时候就提出了 scalable streaming processor 架构。他们给自己开辟了通用计算 GPU(GPGPU)的道路,从此,GPU不再局限于图形加速,还可以用在机器学习、密码学等需要并行运算的领域。
而 AMD 呢?它直到 2020 年发布的 CDNA 架构中才增加了可用于机器学习的矩阵计算能力。当然,AMD 在去年也发布了最新一代的 GPU MI300X,直接对标 NVIDIA 的 H100。据官方介绍,MI300X 可以在一颗芯片上运行 400 亿个参数模型。可是相对 NVIDIA来讲, AMD 关注 AI 的动作还是慢了一步。所以现在做 AI 研发的人,更关注的仍然是 NVIDIA 又发布了什么 GPU。
NVIDIA 不同架构不同系列的 GPU 如何对比?
我们主要从核心数、浮点运算次数、显存和功耗几个指标来进行对比。首先,我们目前常见的核心有这样几种:
- CUDA 核心:最通用的核心,适用于多种计算任务。
- Tensor 核心:针对某些机器学习计算进行了优化。
- RT核心:这类 GPU 更多用于游戏,而不是机器学习。
核心数是一个很直观的指标,但并非全部。不同的显卡拥有不同类型的核心——有些拥有更多的 Tensor 核心,有些拥有更多的 CUDA 核心而。且基于新架构的显卡可能还拥有某些类型核心的新一代版本。正确的比较需要一个更标准化的指标:浮点运算次数(FLOPS)。
FLOPS 代表每秒浮点运算次数,是衡量 GPU 性能的关键指标。不过,还有一个复杂因素。GPU 性能对不同精度浮点数的运算速度不同。
使用更高精度的数字格式进行计算需要更多的处理能力。但这就是 Tensor 核心发挥作用的地方。Tensor 核心可以进行混合精度计算,即它们对大多数计算使用较低的精度,然后以较高的精度验证结果。要对 GPU 进行公平的比较,需要在同一核心类型上使用相同的精度比较 FLOPS。
第三个指标就是 VRAM(Video RAM),即显卡上的内存。VRAM 之于 GPU 就如同 RAM 之于 CPU。在模型推理等计算过程中,VRAM 用于存储模型权重等数据以便快速访问。
模型部署的最重要因素是一个 GPU 所具有的VRAM量。为了快速调用,模型权重必须存储在 VRAM 中,因此 VRAM 的容量限制了模型的大小。
并非所有的VRAM都是相同的。需要考虑其他三个因素:
- 总线大小衡量了一次可以传输到 VRAM 或从 VRAM 传输的数据量。较大的总线有助于更快地加载模型权重。
- 时钟速度衡量VRAM处理数据的速度,时钟速度越高,内存读写速度就越快。
- GDDR 和 HBM 是两种不同类型的 VRAM。HBM(高带宽内存,将多个DDR芯片堆叠在一起后和GPU封装在一起,实现大容量、高位宽的DDR组合阵列)通常能以较低的功耗提供更高的带宽,但制造成本比 GDDR(图形双倍数据速率)内存高。最近的 100 系列显卡,如 A100 和 H100,都使用 HBM。
还有一点需要注意,同一系列的 GPU 并非都具有相同数量的 VRAM。例如,A100 有 40GB 和 80GB 两种版本。因此,在配置 GPU 之前,请确保它具有运行模型所需的正确数量的VRAM。2022年,NVIDIA 发布了 H100,并在 2023 年进行了升级,将其VRAM 也提升至 80GB。
第四个指标是TDP,即功耗,指的是 GPU 在运行过程中设计的最大耗电量(以瓦特为单位)。较高级别的显卡通常比较低级别的显卡具有更大的 TDP,但有时候也会有例外。
电力需要成本,而且它还会产生热量,消除这些热量也需要更多的成本。因此,具有较高 TDP 的显卡具有更高的运营成本。当然,只有自建 GPU 服务器的团队才需要考虑这些成本,如果是使用 GPU 云服务的团队,这些成本已经被计算在服务费中了,无需担心这些成本,更不用考虑机器的散热等基本的维护问题。
最后一个指标是GPU 之间的数据互通速率。因为使用多张 GPU 可以让模型的训练速度大幅加快。所以多个 GPU 机器之间的数据交换速率也决定了它的性能。据 NVIDIA 称,H100 的推理性能相比 A100 可提高 30 倍,训练性能可提高 9 倍。这得益于更高的 GPU 内存带宽、带宽高达 900 GB/s 的升级版 NVLink 以及更高的计算性能,H100 的每秒浮点运算次数 (FLOPS) 比 A100 高出 3 倍以上。
如果把以上几项参数横向对比,就可以得到如下的数据:
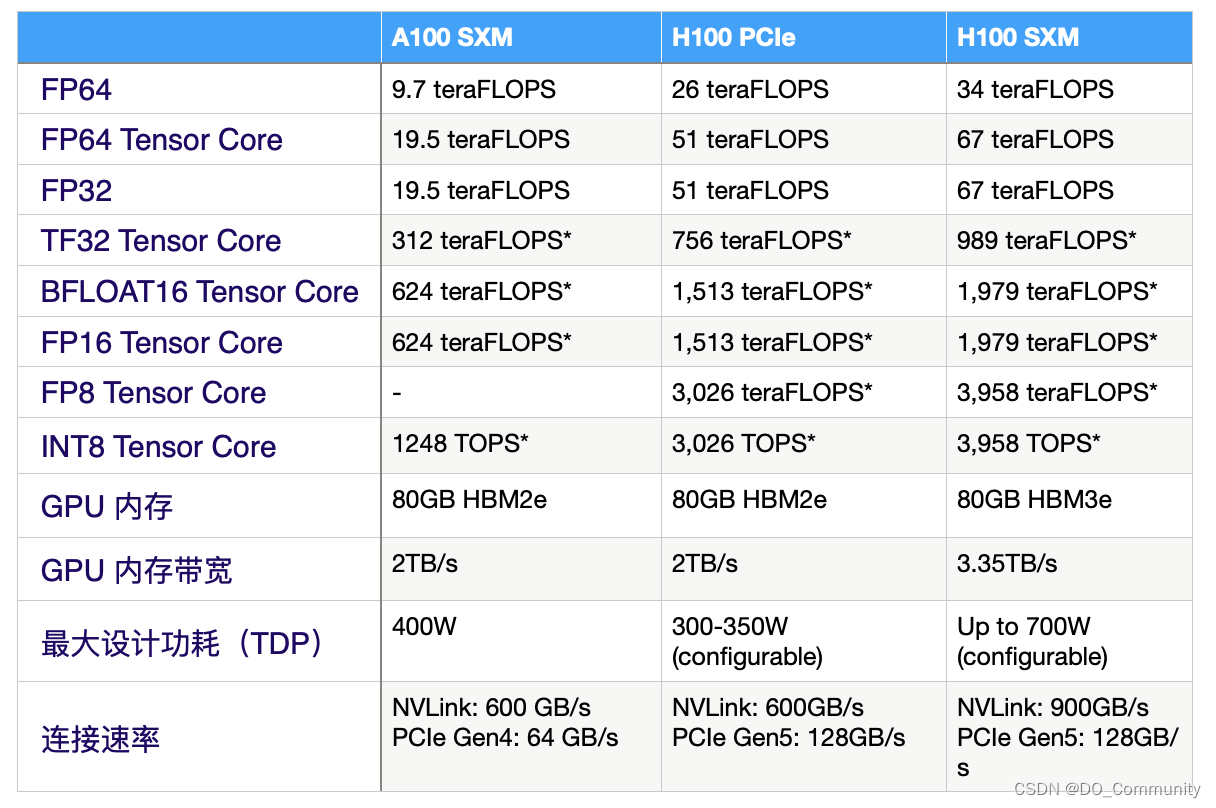
当然,通过参数可以初步对比 GPU 的性能,但是放到实际应用中,你还需要看他们运行不同参数量的模型时的表现。例如,使用 MosaicML 在语言模型,在 H100 GPU 上运行具有不同参数数量的测试,你会发现,H100 确实性能比 A100 高出了两倍:
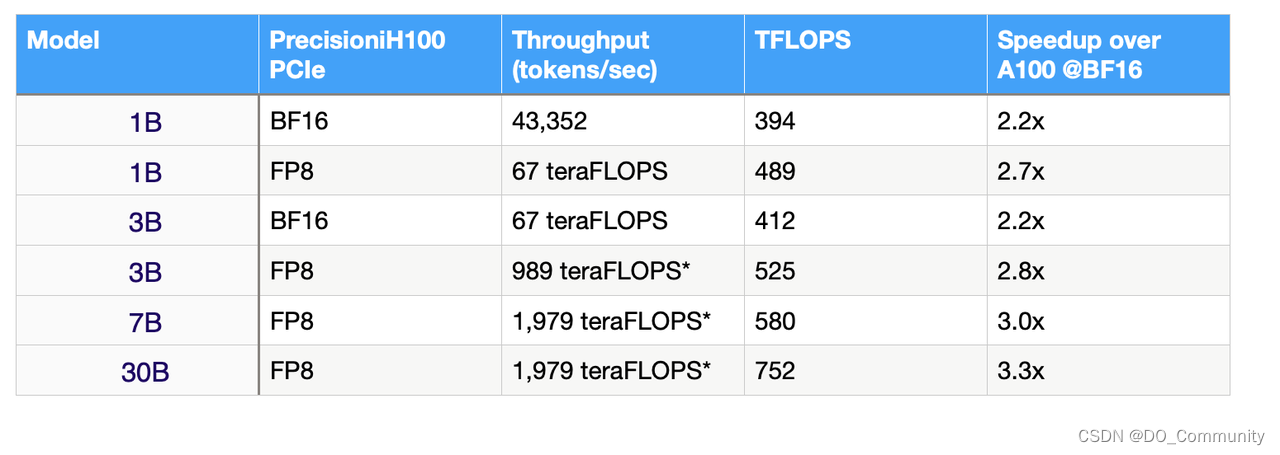
如果你也希望实际测试一遍,或体验一下在 H100 上运行 MosaicML 或其他模型,可以参考我们之前写的教程。最后,如果你需要 GPU 云服务,欢迎联系DigitalOcean 中国区独家战略合作伙伴卓普云科技。

