
- 1Android Studio音乐播放器(使用sqlite创建数据库)_音乐播放器android studio
- 2Java NIO编程实例_java nio编程案例
- 3全网首发亲测有用:python免费将chatgpt机器人接入个人微信(同时支持钉钉、QQ 以及别的语言模型如文心一言等)_chatgpt怎么接入微信
- 4逻辑回归——牛顿法矩阵实现方式
- 5[ELK实战] Elasticsearch 聚合查询二: Bucketing/桶聚合_elk es查询时间查询
- 6辅警考试怎么搜题答案?八个受欢迎的搜题分享了 #学习方法#学习方法#媒体_千鸟搜题
- 7最优化算法之粒子群算法PSO_粒子群算法是谁提出的
- 8H3C SSH远程登录配置_h3c ssh配置
- 9第23篇 Android Studio第一个程序HelloWorld_android studio 4.2.2 helloworld
- 10Ubuntu20.04安装微信等软件全过程_ubantu20.04 安装微信
Elasticsearch:简化数据流的数据生命周期管理_es 数据流
赞
踩
作者:来自 Elastic Andrei Dan

今天,我们将探索 Elasticsearch 针对数据流的新数据管理系统:数据流生命周期,从版本 8.14 开始提供。凭借其简单而强大的执行模型,数据流生命周期可让n 你专注于数据生命周期的业务相关方面,例如降采样和保留。在后台,它会自动确保存储数据的 Elasticsearch 结构得到有效管理。
Elasticsearch 中的数据生命周期管理演变
自 6.x Elasticsearch 系列以来,索引生命周期管理 (index lifecycle management - ILM) 已使用户能够通过自动在层之间迁移数据来维护健康的索引并节省成本。
ILM 根据索引独特的性能、弹性和保留需求来处理索引,同时提供对成本的显着控制并详细定义索引的生命周期。
ILM 是一种非常通用的解决方案,可满足广泛的用例,从时间序列索引和数据流到存储文本内容的索引。对于所有这些用例,生命周期定义将非常不同,当我们考虑每个单独部署的可用硬件和数据分层资源时,它会变得更加不同。因此,ILM 允许完全可定制的生命周期定义,但代价是复杂性(精确的滚动定义;何时强制合并、收缩和(部分)挂载索引)。
当我们开始研究无服务器(serverless)解决方案时,我们有机会通过新的视角来审视生命周期管理,我们的用户可以(并且将)免受 Elasticsearch 内部概念(如分片、分配或集群拓扑)的影响。更重要的是,在无服务器中,我们希望能够根据需要更改内部 Elasticsearch 配置,以保持用户的最佳体验。
在这种新情况下,我们研究了现有的 ILM 解决方案,该解决方案为用户提供了内部 Elasticsearch 概念作为构建块,并决定我们需要一个新的解决方案来管理数据的生命周期。
我们吸取了从大规模构建和维护 ILM 中吸取的经验教训,并为未来创建了一个更简单的生命周期管理系统。该系统更具体,仅适用于数据流(data streams)。它直接在数据流上配置为属性(类似于索引设置属于索引的方式),我们称之为数据流生命周期。它是一种内置机制(继续使用索引设置类比),始终处于开启状态,并且始终对数据流的生命周期需求做出反应。
通过将适用范围限定在数据流(即带有很少更新的时间戳的数据),我们能够避免自定义,转而使用易用性和自动默认值。数据流生命周期将自动执行数据结构维护操作,如滚动和强制合并,并允许你仅处理你应该关心的业务相关生命周期功能,例如降采样(downsampling)和数据保留(data retention)。
数据流生命周期的功能不如 ILM 丰富;最值得注意的是,它目前不支持数据分层、缩减或可搜索快照。但是,不需要这些特定功能的用例将更好地由数据流生命周期服务。
虽然数据流生命周期最初是为无服务器环境的需求而设计的,但它们也可用于常规本地和 ESS Elasticsearch 部署。
配置数据流生命周期
让我们创建一个 Elasticsearch Serverless 项目,并开始创建由数据流生命周期管理的数据流。
创建项目后,转到索引管理并为 my-data-* 索引模式创建索引模板并配置 30 天的保留期:

让我们浏览这些步骤并完成此索引模板(我在映射部分配置了一个文本字段,但这是可选的):
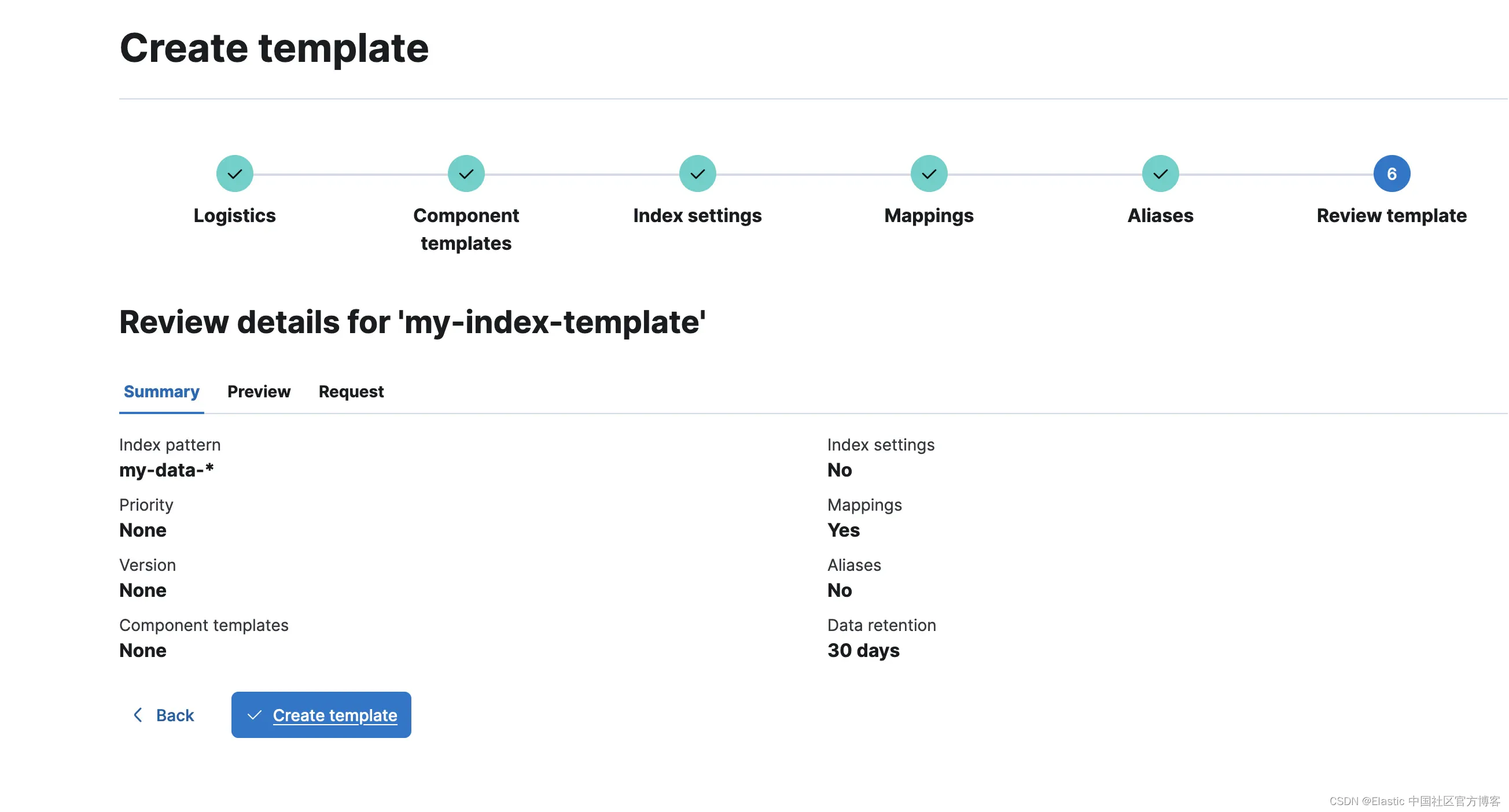
现在,我们将提取一些以 my-data-stream 命名空间为目标的数据。我将使用左侧的 Dev Tools 部分,但你也可以选择自己喜欢的数据提取方式:

my-data-stream 现已创建,它包含 2 个文档。让我们转到 Index Management/Data Streams 并检查一下:

就这样!声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

