
- 1【华为OD机试】2024年真题C卷(C++)-抢7游戏
- 2【任务分配】基于CBBA算法带有任务属性、任务价值、任务时间窗等多种约束下多无人机任务分配附Matlab代码_分支定界 图像分割
- 3kafka listeners和advertised配置_kafka advertised.listeners
- 4pdf、图片转OFD怎么实现?附详细代码_ofdwriter
- 5探秘Vue3-Socket-Chat:构建实时通讯应用的新选择
- 6linux的内存管理_linux目录opt可使用内存由什么决定
- 7【动态规划】【字符串】【行程码】1531. 压缩字符串_行程编码是一种简单有效的压缩算法,它可将连续的重复字符 压缩成“重复次数+字符
- 8MAC电脑无法登录 H3C inode 的解决办法_inode mac
- 9Json和Protobuf区别详细分析
- 10Unity 核心系统详解 -- UI 系统_unity ui
【机器学习】Transformer框架理论详解和代码实现
赞
踩
1. 引言
1.1.讨论背景
在本文中,我们将深入探讨近两年最具影响力的架构之一:Transformer模型。自从2017年Vaswani等人发表划时代论文《Attention Is All You Need》以来,Transformer架构便在众多领域,尤其是自然语言处理(NLP)领域,不断刷新性能上限。这种拥有庞大参数量的Transformer能够生成篇幅长且有说服力的文章,为人工智能领域开辟了新的应用天地。鉴于Transformer架构的热潮在接下来几年内似乎不会退去,掌握其工作原理并能够亲自实现它变得尤为关键,这也是我们本文的重点内容。
尽管Transformer在NLP领域取得了巨大成功,但在本文的讨论中,我们不会局限于NLP。原因何在?首先,阿姆斯特丹大学的Master AI课程已经提供了大量杰出的NLP相关课程,这些课程将更深入地挖掘Transformer架构在NLP领域的应用(例如NLP2、计算语义的高级主题)。其次,大多数读者已经较为详尽地探讨了基于字符级别的语言生成问题,你可以轻松地将我们介绍的Transformer架构应用于此任务。最后,也是最关键的一点,Transformer架构的应用潜力远不止于此。虽然NLP是Transformer最初提出并产生显著影响的领域,但它同样加速了其他领域的研究进展,近来甚至扩展到了计算机视觉领域。因此,本教程将重点放在Transformer和自注意力机制之所以普遍强大背后的原因。在后续的讨论课题中,我们将讨论Transformer在计算机视觉领域的应用前景。
1.2. 准备软件包和预训练模型
导入软件包
## 标准库 import os import numpy as np import random import math import json from functools import partial ## 绘图相关导入 import matplotlib.pyplot as plt plt.set_cmap('cividis') # 设置matplotlib的默认色彩映射表 %matplotlib inline # 使matplotlib的绘图显示在Jupyter Notebook中 from IPython.display import set_matplotlib_formats set_matplotlib_formats('svg', 'pdf') # 设置matplotlib输出格式,适用于导出 from matplotlib.colors import to_rgb import matplotlib matplotlib.rcParams['lines.linewidth'] = 2.0 # 设置matplotlib的线宽 import seaborn as sns sns.reset_orig() # 重置seaborn的默认设置 ## tqdm用于加载条 from tqdm.notebook import tqdm ## PyTorch import torch import torch.nn as nn import torch.nn.functional as F import torch.utils.data as data import torch.optim as optim ## Torchvision import torchvision from torchvision.datasets import CIFAR100 from torchvision import transforms # PyTorch Lightning try: import pytorch_lightning as pl except ModuleNotFoundError: # Google Colab默认没有安装PyTorch Lightning,如果需要则在此安装 !pip install --quiet pytorch-lightning>=1.4 import pytorch_lightning as pl from pytorch_lightning.callbacks import LearningRateMonitor, ModelCheckpoint # 数据集存放的文件夹路径(例如CIFAR10) DATASET_PATH = "../data" # 预训练模型保存的文件夹路径 CHECKPOINT_PATH = "../saved_models/tutorial6" # 设置随机种子 pl.seed_everything(42) # 确保在GPU上的所有操作是确定性的(如果使用)以保证结果的可复现性 torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False # 根据是否可用选择GPU或CPU作为设备 device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu") print("设备:", device)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
下载预训练模型
import urllib.request from urllib.error import HTTPError # Github上存储本教程预训练模型的URL base_url = "https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial6/" # 需要下载的文件列表 pretrained_files = ["ReverseTask.ckpt", "SetAnomalyTask.ckpt"] # 如果检查点路径不存在,则创建它 os.makedirs(CHECKPOINT_PATH, exist_ok=True) # 对于每个文件,检查它是否已经存在。如果不存在,尝试下载它。 for file_name in pretrained_files: file_path = os.path.join(CHECKPOINT_PATH, file_name) # 如果文件名中包含"/",说明是目录结构,需要创建相应目录 if "/" in file_name: os.makedirs(file_path.rsplit("/", 1)[0], exist_ok=True) # 如果文件还不存在于指定路径,则尝试下载 if not os.path.isfile(file_path): file_url = base_url + file_name print(f"正在下载 {file_url}...") try: urllib.request.urlretrieve(file_url, file_path) except HTTPError as e: # 如果下载过程中出现错误,提示用户手动下载或联系作者 print("下载过程中出现问题。请尝试从提供的网络链接手动下载文件,或者联系作者,并附上包括以下错误的完整输出信息:\n", e)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
2. Transformer框架
首先我们将手工实现变换器架构。由于这种架构非常流行,已经存在一个Pytorch模块nn.Transformer(参考文档),并且提供了关于如何使用它进行下一个标记预测的教程。为了深入理解Transformer框架,本文我们将从头自己实现它,以便深入理解Transformer框架的运作逻辑。
当然,关于注意力机制和Transformer框架的论文非常多,如果你相关的研究非常感兴趣,希望继续深入研究transformer框架,以下学习资源可以重点关注和学习:
- Transformer:一种用于语言理解的新型神经网络架构(Jakob Uszkoreit,2017年) - 关于Transformer论文的原始谷歌博客文章,重点介绍在机器翻译中的应用。
- 图文并茂的Transformer(Jay Alammar,2018年) - 一篇非常受欢迎且出色的博客文章,直观地解释了Transformer架构,并提供了许多漂亮的可视化效果。重点是自然语言处理。
- 注意力?注意力!(Lilian Weng,2018年) - 一篇很好的博客文章,总结了包括视觉在内的许多领域的注意力机制。
- 图文并茂的自注意力(Raimi Karim,2019年) - 自注意力步骤的一个很好的可视化。如果下面的解释对你来说太抽象,建议阅读。
- Transformer家族(Lilian Weng,2020年) - 一篇非常详细地回顾了除了原始版本之外的更多变换器变体的博客文章。
2.1.注意力机制
注意力机制描述了过去几年中在神经网络中引起大量研究的一组新层,特别是在时间序列任务中。
在不同的文献中,“注意力”有很多不同的定义,本文中我们将注意力机制定义为:注意力机制描述了基于输入查询和元素键动态计算权重的(序列)元素的加权平均值。
怎么理解上面的定义呢?我们的目标是对多个元素的特征进行平均。然而,我们不想平等地对每个元素进行加权,而是想根据它们的实际值对它们进行加权。换句话说,我们想动态地决定我们更想“关注”那些输入。具体来说,注意力机制通常有四个部分需要我们指定:
- 查询:查询是一个特征向量,描述了我们在序列中寻找什么,即我们可能想关注什么。
- 键:对于每个输入元素,我们都有一个键,它也是一个特征向量。这个特征向量大致描述了元素“提供”了什么,或者何时可能很重要。键应该设计得能够让我们根据查询识别出我们想要关注的元素。
- 值:对于每个输入元素,我们也有一个值向量。这个特征向量是我们想要平均的。
- 分数函数:为了评估我们想要关注哪些元素,我们需要指定一个分数函数(f_{attn})。分数函数以查询和键作为输入,输出查询-键对的分数/注意力权重。它通常由简单的相似性度量实现,如点积或小型MLP。
平均的权重是通过所有分数函数输出上的softmax计算的。因此,我们为那些与查询最相似的值向量分配更高的权重:
α i = exp ( f a t t n ( key i , query ) ) ∑ j exp ( f a t t n ( key j , query ) ) , out = ∑ i α i ⋅ value i \alpha_i = \frac{\exp\left(f_{attn}\left(\text{key}_i, \text{query}\right)\right)}{\sum_j \exp\left(f_{attn}\left(\text{key}_j, \text{query}\right)\right)}, \hspace{5mm} \text{out} = \sum_i \alpha_i \cdot \text{value}_i αi=∑jexp(fattn(keyj,query))exp(fattn(keyi,query)),out=i∑αi⋅valuei
从视觉上看,我们可以按以下方式显示对一系列单词的注意力:

对于每个单词,我们都有一个键和一个值向量。查询与所有键通过分数函数(在这种情况下是点积)进行比较以确定权重。softmax没有可视化以简化。最后,使用注意力权重对所有单词的值向量进行平均。
大多数注意力机制理论,在它们使用的查询、键和值向量的定义,以及使用什么分数函数实现上述功能有所不同。在Transformer架构中,使用的注意力机制是自注意力。在自注意力机制中,每个序列元素提供一个键、值和查询。对于每个元素,我们执行一个注意力层,其中基于它的查询,我们检查所有序列元素的键的相似性,并为每个元素返回一个不同的、平均的值向量。
现在,我们将通过自注意力机制的代码实现来深入理解注意力机制的原理,Transformer的自注意力机制是缩放点积注意力。
2.1.1.缩放点积注意力
自注意力背后的核心概念是缩放点积注意力。我们的目标是拥有一个注意力机制,使得序列中的任何元素都可以高效地关注任何其他元素。点积注意力以查询集 、键 和值 作为输入,其中 是序列长度, 和 分别是查询/键和值的隐藏维度。现在为了简单起见,我们忽略了批量维度。来自元素 到 的注意力值基于查询 和键 的相似性,使用点积作为相似性度量。在数学上,我们计算点积注意力如下:
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
k
)
V
\text{Attention}(Q,K,V)=\text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
Attention(Q,K,V)=softmax(dk
QKT)V
矩阵乘法 对每一对查询和键执行点积,得到一个形状为 的矩阵。每一行代表特定元素 对序列中所有其他元素的注意力逻辑值。在这些上,我们应用softmax并乘以值向量,以获得加权平均值(权重由注意力确定)。另一种看待这种注意力机制的方式是下面可视化的计算图(图源 - Vaswani等人,2017)。
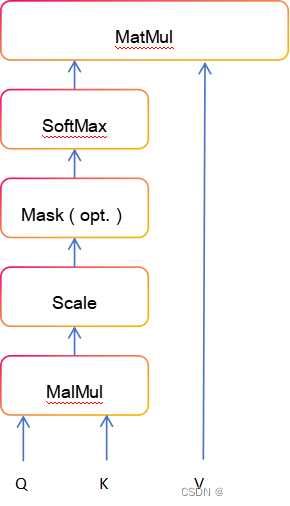
缩放因子 对于在初始化后保持注意力值的适当方差至关重要。记住,我们初始化我们的层的目的是在整个模型中具有相等的方差,因此, 和 也可能具有接近 的方差:
q
i
∼
N
(
0
,
σ
2
)
,
k
i
∼
N
(
0
,
σ
2
)
→
Var
(
∑
i
=
1
d
k
q
i
⋅
k
i
)
=
σ
4
⋅
d
k
q_i \sim \mathcal{N}(0,\sigma^2), k_i \sim \mathcal{N}(0,\sigma^2) \to \text{Var}\left(\sum_{i=1}^{d_k} q_i\cdot k_i\right) = \sigma^4\cdot d_k
qi∼N(0,σ2),ki∼N(0,σ2)→Var(i=1∑dkqi⋅ki)=σ4⋅dk
如果我们不将方差缩放回 ,softmax在逻辑值上的输出将对一个随机元素饱和为 ,对所有其他元素为 。通过softmax的梯度将接近零,以至于我们无法适当地学习参数。注意,额外的 因子,即有 而不是 ,通常不是问题,因为我们无论如何都保持原始方差 接近 。
上图中的块掩码(可选)表示在注意力矩阵中屏蔽特定条目的选项。例如,如果我们将具有不同长度的多个序列堆叠成一个批次,我们仍然希望从并行化中受益。我们将句子填充到相同的长度,并在计算注意力值时掩码掉填充标记。这通常通过将相应的注意力逻辑值设置为一个非常低的值来完成。
在我们讨论了缩放点积注意力块的细节之后,我们可以在下面编写一个函数,根据查询、键和值的三元组计算输出特征:
import torch import torch.nn.functional as F import math def scaled_dot_product(q, k, v, mask=None): # 获取q的最后一个维度的大小(通常是嵌入的维度) d_k = q.size()[-1] # 计算q和k的点积(即scaled dot-product attention中的"logits") attn_logits = torch.matmul(q, k.transpose(-2, -1)) # 将点积结果除以sqrt(d_k)进行缩放 attn_logits = attn_logits / math.sqrt(d_k) # 如果提供了mask,则将mask为0的位置的点积值替换为一个非常小的数(如-9e15),这样在softmax后这些位置的值会接近于0 if mask is not None: attn_logits = attn_logits.masked_fill(mask == 0, -9e15) # 应用softmax函数来计算attention权重 attention = F.softmax(attn_logits, dim=-1) # 使用attention权重对v进行加权求和,得到最终的输出 values = torch.matmul(attention, v) # 返回加权后的值和attention权重 return values, attention
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
在上面的代码中,我们考虑到了可能需要对一批数据进行处理,因此设计了支持在序列长度维度之前具有额外维度的结构。这意味着我们可以一次性处理多个输入序列,而不仅仅是单个序列。然而,为了更直观地理解注意力机制是如何工作的,我们可以生成几个随机的查询、键和值向量,并使用这些向量来计算注意力分数和最终的注意力输出。
# 序列长度和嵌入维度 seq_len, d_k = 3, 2 # 设置随机种子 seed_everything(42) # 生成q、k、v矩阵 q = torch.randn(seq_len, d_k) k = torch.randn(seq_len, d_k) v = torch.randn(seq_len, d_k) # 调用缩放点积注意力机制函数 values, attention = scaled_dot_product(q, k, v) # 打印结果 print("Q\n", q) print("K\n", k) print("V\n", v) print("Values\n", values) print("Attention\n", attention)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
在我们深入探索变换器模型的奥秘之前,让我们先来彻底掌握缩放点积注意力的计算。这不仅仅是一个数学练习,而是理解整个注意力机制如何工作的基础。所以,深呼吸,拿起纸和笔,让我们一步步地计算出这些具体的值,并且确保你能够理解每一步。
2.1.2.多头注意力
缩放点积注意力让网络能够聚焦于序列的每一个细节。但现实情况是,序列中的每个元素可能想要关注多个不同的方面,单一的加权平均可能就不够用了。这就像是用一个镜头看世界,你可能会错过一些重要的视角。因此,我们引入了多头注意力机制,它就像是给我们的网络配备了多个镜头,每个镜头都专注于捕捉序列的不同特征。
具体来说,我们把查询、键和值矩阵分割成 个小块,每个小块都独立地通过缩放点积注意力进行处理。然后,我们将这些小块的结果拼接起来,并通过一个最终的权重矩阵进行整合。数学上,我们可以这样描述这个过程:
Multihead
(
Q
,
K
,
V
)
=
Concatenate
(
head
1
,
…
,
head
h
)
⋅
W
O
\text{Multihead}(Q,K,V) = \text{Concatenate}(\text{head}_1, \ldots, \text{head}_h) \cdot W^{O}
Multihead(Q,K,V)=Concatenate(head1,…,headh)⋅WO
其中每个头 是这样计算的:
head
i
=
Attention
(
Q
⋅
W
i
Q
,
K
⋅
W
i
K
,
V
⋅
W
i
V
)
\text{head}_i = \text{Attention}(Q \cdot W_i^Q, K \cdot W_i^K, V \cdot W_i^V)
headi=Attention(Q⋅WiQ,K⋅WiK,V⋅WiV)
这里, 是我们的可学习参数,它们将帮助模型从不同的角度理解数据。而 则是将所有头的信息合并到一起的权重矩阵。
2.1.3.可视化多头注意力
如果我们把这个过程画出来,就像下面这样(感谢Vaswani等人,2017年的图示):
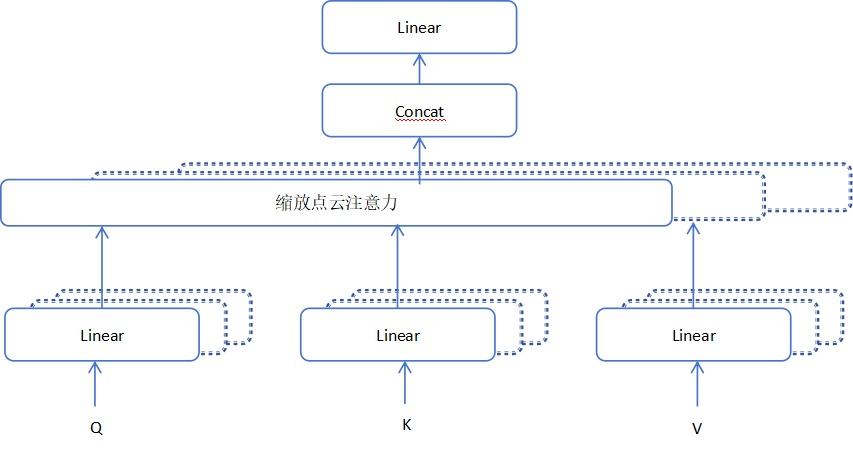
在这幅图中,你可以看到多头注意力是如何工作的:每个头都在独立地计算注意力,然后将它们合并起来,形成一个综合的、丰富的表示,这个表示捕捉了序列的多个不同方面。
多头注意力是变换器模型中的一个关键创新点。它不仅提高了模型处理序列数据的能力,也为模型提供了一种更加灵活和强大的方式来理解和解释输入的信息。通过这种方式,变换器模型能够更好地捕捉语言的细微差别,理解复杂的模式,并在各种自然语言处理任务中取得了前所未有的成功。
在神经网络中,如果我们没有现成的查询(query)、键(key)和值(value)向量作为输入,该如何应用多头注意力层呢?参考上面的计算图,我们可以采取一个简单而有效的实现策略:将神经网络当前的特征映射 直接作为 来使用(其中 代表批次大小, 代表序列长度, 代表 的隐藏层维度)。随后,我们可以使用一系列的权重矩阵 来将 转换成代表输入的查询、键和值的特征向量。通过这种方法,我们可以构建出以下的多头注意力模块。
# 辅助函数,用于支持不同形状的掩码。 # 输出形状支持(batch_size, number of heads, seq length, seq length) # 如果是2D: 在批量大小和头数上广播 # 如果是3D: 在头数上广播 # 如果是4D: 保持原样 def expand_mask(mask): # 确保掩码至少是二维的,即序列长度x序列长度 assert mask.ndim >= 2, "掩码必须是至少二维的,形式为seq_length x seq_length" # 如果掩码是三维的,增加一个维度使其成为四维,用于在头数上进行广播 if mask.ndim == 3: mask = mask.unsqueeze(1) # 当掩码的维度小于4时,通过增加维度使其达到四维 while mask.ndim < 4: mask = mask.unsqueeze(0) return mask
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
# 定义多头注意力模块 class MultiheadAttention(nn.Module): def __init__(self, input_dim, embed_dim, num_heads): super().__init__() # 调用父类初始化方法 # 确保嵌入维度可以被头数整除 assert embed_dim % num_heads == 0, "嵌入维度必须是头数的倍数。" self.embed_dim = embed_dim # 嵌入维度 self.num_heads = num_heads # 头数 self.head_dim = embed_dim // num_heads # 每个头的维度 # 将所有权重矩阵堆叠在一起以提高效率 # 注意:许多实现中会看到 "bias=False",这是可选的 self.qkv_proj = nn.Linear(input_dim, 3*embed_dim) # 用于投影Q、K、V的线性层 self.o_proj = nn.Linear(embed_dim, embed_dim) # 输出投影层 self._reset_parameters() # 重置参数的初始化 def _reset_parameters(self): # 使用原始变换器的初始化方法,参见PyTorch文档 nn.init.xavier_uniform_(self.qkv_proj.weight) # 使用Xavier均匀初始化Q、K、V投影层的权重 self.qkv_proj.bias.data.fill_(0) # 清零Q、K、V投影层的偏置 nn.init.xavier_uniform_(self.o_proj.weight) # 使用Xavier均匀初始化输出投影层的权重 self.o_proj.bias.data.fill_(0) # 清零输出投影层的偏置 def forward(self, x, mask=None, return_attention=False): # 获取输入序列的批次大小、序列长度和维度 batch_size, seq_length, _ = x.size() # 如果提供了掩码,扩展掩码以匹配多头注意力的输出形状 if mask is not None: mask = expand_mask(mask) # 通过线性层和分割操作生成Q、K、V qkv = self.qkv_proj(x) qkv = qkv.reshape(batch_size, seq_length, self.num_heads, 3*self.head_dim) qkv = qkv.permute(0, 2, 1, 3) # 重新排列形状以符合多头注意力的格式 q, k, v = qkv.chunk(3, dim=-1) # 将Q、K、V分离 # 计算缩放点积注意力 values, attention = scaled_dot_product(q, k, v, mask=mask) # 重新排列和重塑values的形状以匹配原始输入序列的形状 values = values.permute(0, 2, 1, 3) values = values.reshape(batch_size, seq_length, self.embed_dim) # 通过输出投影层生成最终的输出 o = self.o_proj(values) # 如果需要返回注意力权重,将其作为元组的第二个元素返回 if return_attention: return o, attention else: return o
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
多头注意力机制的一个至关重要的特性是它对于输入的排列是等变的。这表示如果我们在序列中交换两个输入元素的位置,例如 x 1 x_1 x1 与 x 2 x_2 x2 互换(目前先不考虑批次维度),输出结果除了元素1和2交换了位置外,其他部分将完全相同。因此,多头注意力实际上并不是将输入视为一个序列,而是作为一组元素来看待。这一特性赋予了多头注意力单元以及变换器架构强大能力,并大大扩展了它们的应用范围。
但如果任务的解决需要依赖输入的顺序,比如在语言建模中,我们又该如何是好?解决的办法是将位置信息编码进输入特征里,我们将在后续部分(位置编码主题)中更深入地探讨这个话题。
在深入构建变换器架构之前,我们先来比较一下自注意力机制与其他常见用于序列数据的层级结构:卷积层和循环神经网络。下面这张表格来自Vaswani等人(2017年的研究),展示了每层的计算复杂度、序列操作的数量以及最大路径长度。这里的复杂度是指执行操作数量的上限,而最大路径长度指的是前向或后向信号需要经过的最大步数以到达序列中的任何位置。这个长度越短,意味着梯度信号在反向传播时能更好地处理长距离依赖问题。让我们来审视一下这张表格:
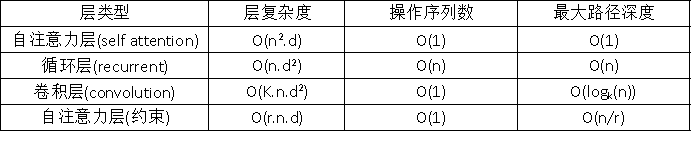
其中,
n
n
n代表序列长度,
d
d
d代表表示维度,
k
k
k是卷积核的大小。与循环网络相比,自注意力层能够并行处理所有操作,因此在处理较短序列时执行速度更快。然而,当序列长度超过表示维度时,自注意力的计算成本就会超过RNN。降低长序列计算成本的一个方法是限制自注意力只在一个输入邻域内进行,这个邻域用 表示。尽管如此,最近有很多研究集中在开发更高效的变换器架构上,这些架构仍然能够处理长距离依赖问题,如果你感兴趣,可以在Tay等人(2020年)的论文中找到更多相关信息。
2.2. Transformer编码器
接下来,我们将探讨如何在Transformer架构中应用多头注意力模块。最初,Transformer模型是为了机器翻译而设计的。因此,它采用了编码器-解码器结构,其中编码器负责接收原始语言的句子并生成基于注意力的表示。而解码器则依赖于编码器生成的信息,并以自回归的方式生成翻译后的句子,这与传统的RNN类似。尽管这种结构对于需要自回归解码的序列到序列任务非常有用,但在这里我们将重点放在编码器部分。许多NLP领域的进步都是基于纯编码器的Transformer模型实现的(如果感兴趣,可以了解BERT家族、视觉变换器等模型),在本文中,也将主要关注编码器部分。如果你已经理解了编码器的架构,那么解码器的实现将是一个相对简单的过程。完整的Transformer架构图示如下(图源来源自Vaswani等人,2017年):Transformer。

编码器由一系列相同的模块构成,这些模块按顺序执行。输入 首先通过我们之前实现的多头注意力模块处理。然后,处理结果通过残差连接加到原始输入上,并且对结果进行层归一化处理。简而言之,它执行的操作是
LayerNorm
(
x
+
Multihead
(
x
,
x
,
x
)
)
\text{LayerNorm}(x + \text{Multihead}(x, x, x))
LayerNorm(x+Multihead(x,x,x)) ,其中
X
X
X是传给注意力层的查询
Q
Q
Q、键
K
K
K和值
V
V
V
残差连接在Transformer架构中扮演着两个关键角色:
- 类似于残差网络,变换器设计得非常深,一些模型的编码器部分包含超过24个这样的模块。因此,残差连接对于确保模型能够顺利地进行梯度传播至关重要。
- 没有残差连接,原始序列的信息将会丢失。多头注意力层本身并不考虑元素在序列中的位置,它只能基于输入特征来学习位置信息。如果移除了残差连接,那么经过第一个注意力层之后,这些关于原始输入的信息就会丢失。由于查询和键向量是随机初始化的,第一个注意力层之后的输出向量可能与它们的原始输入没有任何关联。所有输出都可能表达相似或相同的信息,模型也就无法区分不同输入元素的信息来源。解决这个问题的一种替代方法是至少固定一个头来专注于其原始输入,但这既低效又不能带来梯度传播的好处。
层归一化在变换器架构中同样重要,因为它有助于加快训练速度并提供一定程度的正则化。此外,它确保了序列中各元素的特征具有相似的大小。我们不使用批量归一化,因为它依赖于批量大小,而变换器的批量大小通常很小(它们需要大量的GPU内存),并且在语言处理中,由于单词的特征方差很大(存在许多罕见单词,需要被考虑以获得良好的分布估计),批量归一化的表现特别差。
除了多头注意力之外,模型中还加入了一个小的全连接前馈网络,它对每个位置分别且独立地应用。具体来说,模型使用的是线性-ReLU-线性的多层感知机(MLP)。包括残差连接的完整转换可以表达为:
FFN ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 和 x = LayerNorm ( x + FFN ( x ) ) \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 \quad \text{和} \quad x = \text{LayerNorm}(x + \text{FFN}(x)) FFN(x)=max(0,xW1+b1)W2+b2和x=LayerNorm(x+FFN(x))
这个MLP为模型增加了额外的复杂性,允许对每个序列元素分别进行转换。你可以将其视为一种让模型“后处理”前一个多头注意力块添加的新信息,并为下一个注意力块做准备的方式。通常,MLP的内部维度是原始输入 的维度 的2到8倍。相比狭窄的多层MLP,更宽的层的优点在于它可以更快地并行执行。
最后,在审视了编码器架构的所有部分之后,我们可以开始实现它。我们首先实现一个单一的编码器块。除了上述的层之外,我们还将在线性层和MLP以及多头注意力的输出上添加dropout层,以进行正则化。
# 定义编码器模块 class EncoderBlock(nn.Module): def __init__(self, input_dim, num_heads, dim_feedforward, dropout=0.0): """ 参数: input_dim - 输入数据的维度 num_heads - 多头注意力模块中使用的头数 dim_feedforward - MLP中隐藏层的维度 dropout - dropout层使用的丢弃概率 """ super().__init__() # 多头注意力层 self.self_attn = MultiheadAttention(input_dim, input_dim, num_heads) # 两层MLP(多层感知机) self.linear_net = nn.Sequential( nn.Linear(input_dim, dim_feedforward), # 线性层,从输入维度到隐藏层维度 nn.Dropout(dropout), # dropout层,用于正则化 nn.ReLU(inplace=True), # ReLU激活函数 nn.Linear(dim_feedforward, input_dim) # 线性层,从隐藏层维度回到输入维度 ) # 用于主层之间的层 self.norm1 = nn.LayerNorm(input_dim) # 第一层归一化层 self.norm2 = nn.LayerNorm(input_dim) # 第二层归一化层 self.dropout = nn.Dropout(dropout) # dropout层 def forward(self, x, mask=None): # 注意力部分 attn_out = self.self_attn(x, mask=mask) # 执行多头注意力操作 x = x + self.dropout(attn_out) # 残差连接 + dropout x = self.norm1(x) # 第一层归一化 # MLP部分 linear_out = self.linear_net(x) # 执行MLP x = x + self.dropout(linear_out) # 残差连接 + dropout x = self.norm2(x) # 第二层归一化 return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
基于这个代码块,我们可以实现一个完整的Transformer编码器的模块。除了一个前向传播函数(它遍历编码器块的序列)外,我们还提供了一个名为get_attention_maps的函数。这个函数的目的是返回编码器中所有多头注意力(Multi-Head Attention)块的注意力概率。这有助于我们理解并在某种程度上解释模型。然而,应该谨慎地解释这些注意力概率,因为它们并不一定反映模型的真实解释(关于这一点有一系列论文,包括《Attention is not Explanation》和《Attention is not not Explanation》)。
# 定义变换器编码器类 class TransformerEncoder(nn.Module): def __init__(self, num_layers, **block_args): """ 参数: num_layers - 编码器中的层数 block_args - 编码器块的参数,作为关键字参数传递 """ super().__init__() # 创建编码器层的列表,每个层都是一个EncoderBlock实例 self.layers = nn.ModuleList([EncoderBlock(**block_args) for _ in range(num_layers)]) def forward(self, x, mask=None): # 前向传播,顺序通过每个编码器层 for l in self.layers: x = l(x, mask=mask) return x def get_attention_maps(self, x, mask=None): # 获取编码器层的注意力图 attention_maps = [] for l in self.layers: # 从每个编码器块获取注意力图和输出 _, attn_map = l.self_attn(x, mask=mask, return_attention=True) # 将注意力图添加到列表中 attention_maps.append(attn_map) # 更新x为当前层的输出,但不返回注意力图 x = l(x, return_attention=False) return attention_maps
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
2.2.1.位置编码
我们之前讨论过,多头注意力模块是排列等变的,并且不能区分序列中的输入哪个在前哪个在后。然而,在诸如语言理解这样的任务中,位置信息对于解释输入单词非常重要。因此,可以通过输入特征添加位置信息。我们可以为每个可能的位置学习一个嵌入,但这不会推广到动态输入序列长度。因此,更好的选择是使用网络能够从特征中识别出来并可能推广到更大序列的特征模式。Vaswani等人选择的特定模式是不同频率的正弦和余弦函数,如下所示:
P
E
(
p
o
s
,
2
i
)
=
sin
(
p
o
s
1000
0
2
i
/
d
model
)
如果
i
m
o
d
2
=
0
PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) 如果 i mod 2 =0
PE(pos,2i)=sin(100002i/dmodelpos)如果imod2=0
P
E
(
p
o
s
,
2
i
+
1
)
=
cos
(
p
o
s
1000
0
2
i
/
d
model
)
如果
i
m
o
d
2
≠
0
PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) 如果 i mod 2 \ne0
PE(pos,2i+1)=cos(100002i/dmodelpos)如果imod2=0
这里 表示序列中位置 的位置编码, 是隐藏维度。这些值,对于所有隐藏维度进行连接后,被添加到原始输入特征上(在变换器的可视化中,见“位置编码”),构成了位置信息。我们区分偶数 和奇数 隐藏维度,分别应用正弦/余弦。这种编码背后的直觉是,你可以将 表示为 的线性函数,这可能允许模型轻松地关注相对位置。不同维度中的波长范围从
1
/
d
model
1/d_{\text{model}}
1/dmodel到
10000
/
d
model
10000/d_{\text{model}}
10000/dmodel。
import torch import math from torch import nn # 定义位置编码模块 class PositionalEncoding(nn.Module): def __init__(self, d_model, max_len=5000): """ 参数: d_model - 输入的隐藏维度数。 max_len - 预期的序列最大长度。 """ super(PositionalEncoding, self).__init__() # 创建一个矩阵,大小为[序列最大长度, 隐藏维度],表示最大长度序列的位置编码 pe = torch.zeros(max_len, d_model) # 获取位置索引,并将它们转换为浮点数以便进行数学运算 position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # 计算用于正弦和余弦的除数项,这有助于在不同维度上创建不同频率的波 div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # 填充pe矩阵,偶数索引使用正弦函数,奇数索引使用余弦函数 pe[:, 0::2] = torch.sin(position * div_term) # 偶数索引填充正弦值 pe[:, 1::2] = torch.cos(position * div_term) # 奇数索引填充余弦值 # 增加一个维度,以匹配后续操作中所需的形状 pe = pe.unsqueeze(0) # 注册pe为模块的缓冲区,这意味着它不是模型参数,但应与模块在同一设备上 # persistent=False 表示在保存模型时不将此缓冲区添加到状态字典中 self.register_buffer('pe', pe, persistent=False) def forward(self, x): # 将位置编码加到输入x上,注意只添加与x长度相匹配的部分 x = x + self.pe[:, :x.size(1)] return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
为了更直观地理解位置编码的作用,我们可以将其进行可视化。我们将绘制一个图像,该图像将展示在序列的不同位置以及隐藏维度上位置编码的变化。通过这种方式,每个像素点都将代表我们为了编码特定位置而对输入特征所做的变换。下面我们将执行这一可视化过程。
# 创建位置编码模块实例,设置隐藏层维度为48,最大序列长度为96 encod_block = PositionalEncoding(d_model=48, max_len=96) # 获取位置编码张量,并去除第一个维度(batch维度),转置,然后转换为CPU上的NumPy数组 pe = encod_block.pe.squeeze().T.cpu().numpy() # 创建一个图像显示位置编码,使用热力图 fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(8, 3)) # 使用RdGy颜色映射显示编码,设置图像的extent以便于正确缩放 pos = ax.imshow(pe, cmap="RdGy", extent=(1, pe.shape[1] + 1, pe.shape[0] + 1, 1)) # 为图像添加颜色条 fig.colorbar(pos, ax=ax) # 设置x轴和y轴的标签 ax.set_xlabel("序列中的位置") ax.set_ylabel("隐藏维度") # 设置图像的标题 ax.set_title("隐藏维度上的位置编码") # 设置x轴的刻度,每隔10个位置标记一次 ax.set_xticks([1] + [i * 10 for i in range(1, 1 + pe.shape[1] // 10)]) # 设置y轴的刻度,每隔10个隐藏维度标记一次 ax.set_yticks([1] + [i * 10 for i in range(1, 1 + pe.shape[0] // 10)]) # 显示图像 plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
你可以清晰地看到在隐藏维度中编码位置信息的具有不同波长的正弦波和余弦波。具体来说,我们可以单独观察每个隐藏维度上的正弦波/余弦波,以更好地理解这种模式。下面我们将可视化隐藏维度 d 1 , d 2 d_1,d_2 d1,d2和 d 3 d_3 d3 上的位置编码。
import numpy as np import matplotlib.pyplot as plt import seaborn as sns # 设置Seaborn主题 sns.set_theme() # 创建一个2x2的子图网格,但只使用其中的4个子图 fig, ax = plt.subplots(2, 2, figsize=(12, 4)) # 将子图列表展平为一维列表 ax_flat = [a for sublist in ax for a in sublist] # 假设 pe 是一个预先计算好的位置编码矩阵,其中每一行代表一个隐藏维度的编码 # 这里我们只绘制前16个位置的编码,因为 ax 的数量只有4个 for i in range(len(ax_flat)): # 绘制位置编码 ax_flat[i].plot(np.arange(1, 17), pe[i, :16], color=f'C{i}', marker="o", markersize=6, markeredgecolor="black") # 设置子图标题 ax_flat[i].set_title(f"隐藏维度 {i+1} 的编码") # 设置x轴标签 ax_flat[i].set_xlabel("序列中的位置", fontsize=10) # 设置y轴标签 ax_flat[i].set_ylabel("位置编码", fontsize=10) # 设置x轴刻度 ax_flat[i].set_xticks(np.arange(1, 17)) # 设置主刻度和次刻度的标签大小 ax_flat[i].tick_params(axis='both', which='major', labelsize=10) ax_flat[i].tick_params(axis='both', which='minor', labelsize=8) # 设置y轴范围 ax_flat[i].set_ylim(-1.2, 1.2) # 调整子图之间的间距 fig.subplots_adjust(hspace=0.8) # 重置Seaborn到默认设置(如果需要的话) sns.reset_orig() # 显示图形 plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46

2.3. 学习率预热
学习率预热是训练Transformer模型时的一种常用技术。这指的是我们在最初几次迭代中,逐渐将学习率从0增加到我们原先设定的学习率。这样,我们能够逐步开始学习,而不是一开始就采取大步前进。事实上,如果不进行学习率预热,直接训练深层的Transformer模型可能会导致模型发散,从而在训练和测试上获得更差的性能。
预热显然是Transformer架构中的一个关键超参数。它为何如此重要?目前有两个普遍的解释。首先,Adam优化器使用了偏差校正因子,这可能在初始迭代中导致自适应学习率的高方差。像RAdam这样的改进型优化器已经显示出能够克服这个问题,使得训练Transformer时无需预热。其次,逐层应用的层归一化可能会在初始迭代中导致梯度非常高,这可以通过使用前层归一化(类似于前激活的ResNet)或用其他技术(例如自适应归一化、幂归一化)替换层归一化来解决。
尽管如此,许多应用和论文仍然使用原始的Transformer架构和Adam优化器,因为预热是一个简单而有效的解决方法,能够解决最初几次迭代中的梯度问题。我们可以使用许多不同的学习率调度器。例如,原始的Transformer论文使用了一个带有预热的指数衰减调度器。然而,目前最受欢迎的调度器是余弦预热调度器,它结合了预热和余弦形状的学习率衰减。我们可以在下面实现它,并可视化学习率因子随周期变化的情况。
import numpy as np import torch.optim.lr_scheduler as lr_scheduler # 定义余弦预热调度器类 class CosineWarmupScheduler(lr_scheduler._LRScheduler): def __init__(self, optimizer, warmup, max_iters): """ 参数: optimizer - 要应用学习率调度的优化器 warmup - 预热期间的迭代次数 max_iters - 训练过程中的最大迭代次数 """ self.warmup = warmup # 预热次数 self.max_num_iters = max_iters # 最大迭代次数 super(CosineWarmupScheduler, self).__init__(optimizer) def get_lr(self): # 根据当前epoch获取学习率因子 lr_factor = self.get_lr_factor(epoch=self.last_epoch) # 返回调整后的学习率列表 return [base_lr * lr_factor for base_lr in self.base_lrs] def get_lr_factor(self, epoch): # 当前epoch与最大迭代次数之比,用于计算余弦函数的参数 lr_factor = 0.5 * (1 + np.cos(np.pi * epoch / self.max_num_iters)) # 如果当前epoch在预热期内,则按线性增加学习率 if epoch <= self.warmup: lr_factor *= epoch * 1.0 / self.warmup return lr_factor
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
这段代码定义了一个名为 CosineWarmupScheduler 的学习率调度器类,它继承自 torch.optim.lr_scheduler._LRScheduler。这个调度器结合了学习率预热和余弦退火策略,以平滑地调整学习率。
在初始化方法 init 中,接收优化器、预热迭代次数和最大迭代次数作为参数,并调用父类初始化方法。
get_lr 方法根据当前epoch计算学习率因子,并将其应用到基础学习率上,返回新的学习率列表。
get_lr_factor 方法首先根据余弦函数计算学习率因子,如果在预热期内,则进一步将学习率因子与当前epoch成正比地调整,确保学习率从0开始逐渐增加到初始学习率。
这种调度器特别适用于Transformer模型的训练,因为它可以防止训练初期梯度过大导致的问题,并在训练后期通过余弦退火逐渐降低学习率,以精细化模型的参数。
import torch import torch.nn as nn import matplotlib.pyplot as plt import seaborn as sns import numpy as np # 用于初始化学习率调度器的参数 p = nn.Parameter(torch.empty(4, 4)) # 创建优化器,使用上面的参数,初始学习率设置为0.001 optimizer = optim.Adam([p], lr=1e-3) # 创建余弦预热调度器,设置预热迭代为100,最大迭代为2000 lr_scheduler = CosineWarmupScheduler(optimizer=optimizer, warmup=100, max_iters=2000) # 绘图 # 创建表示周期的列表,这里用0到1999表示2000个批次的迭代 epochs = list(range(2000)) # 设置seaborn绘图风格 sns.set() # 创建图形和坐标轴,大小为8x3英寸 plt.figure(figsize=(8, 3)) # 计算每个epoch的学习率因子并绘制 plt.plot(epochs, [lr_scheduler.get_lr_factor(e) for e in epochs]) # 设置y轴标签为"学习率因子" plt.ylabel("学习率因子") # 设置x轴标签为"迭代次数(按批次)" plt.xlabel("迭代次数(按批次)") # 设置图表标题 plt.title("余弦预热学习率调度器") # 显示图形 plt.show() # 重置seaborn的默认设置,以便在之后的绘图中不受影响 sns.reset_orig()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
这段代码演示了如何使用自定义的余弦预热学习率调度器,并将其学习率因子随迭代次数的变化绘制成图表。
- 首先,创建一个可训练的参数
p,用于初始化优化器和学习率调度器。 - 使用Adam优化器和初始学习率0.001来创建优化器实例。
- 接着,使用优化器实例、预热期为100迭代和总共2000迭代来创建余弦预热调度器实例。
- 然后,创建一个表示训练周期的列表
epochs,范围从0到1999,代表2000个批次的迭代。 - 使用seaborn设置绘图风格,并创建一个图形和坐标轴。
- 通过调用
lr_scheduler.get_lr_factor()方法计算每个epoch的学习率因子,并使用matplotlib绘制这些因子随迭代次数变化的折线图。 - 设置图表的标题、x轴和y轴的标签,并显示图表。
- 最后,使用
sns.reset_orig()重置seaborn的默认设置,确保之后的图表风格不会受到影响。

余弦预热的学习率曲线
我们可以将变换器(Transformer)架构整合到PyTorch Lightning模块中。在第5个教程中,你已经了解到PyTorch Lightning能够简化我们的训练和测试代码,并能够将代码结构化地组织到不同的函数中。我们将实现一个基于变换器编码器的分类器模板。这样,对于序列中的每个元素,我们都会有一个预测输出。如果我们需要对整个序列进行分类,通常的做法是向序列中添加一个额外的[CLS]标记,代表分类器的标记。但在这里,我们专注于每个元素都有输出的任务。
除了变换器架构,我们还增加了一个小型的输入网络(将输入维度映射到模型维度)、位置编码,以及一个输出网络(将输出编码转换为预测)。我们还添加了学习率调度器,它在每次迭代时都会进行一步调整,而不是每轮迭代一次。这对于实现预热和平滑的余弦衰减是必需的。训练、验证和测试步骤目前是空的,将根据我们特定任务的模型进行填充。
import torch.nn as nn import torch.optim.lr_scheduler as lr_scheduler import pytorch_lightning as pl class TransformerClassifier(pl.LightningModule): def __init__(self, input_dim, output_dim, d_model, max_len): super(TransformerClassifier, self).__init__() # 输入网络,将输入维度映射到模型维度 self.input_net = nn.Linear(input_dim, d_model) # 位置编码 self.positional_encoding = PositionalEncoding(d_model, max_len) # Transformer编码器 self.transformer_encoder = TransformerEncoder(num_layers=..., ...) # 输出网络,将编码器的输出转换为预测 self.output_net = nn.Linear(d_model, output_dim) # 学习率预热调度器 self.lr_scheduler = lr_scheduler.CosineAnnealingWarmRestarts(self.optimizer, ...) def forward(self, x): # 应用输入网络 x = self.input_net(x) # 应用位置编码 x = self.positional_encoding(x) # 通过Transformer编码器 x = self.transformer_encoder(x) # 应用输出网络 x = self.output_net(x) return x def training_step(self, batch): # 训练步骤 pass def validation_step(self, batch): # 验证步骤 pass def test_step(self, batch): # 测试步骤 pass def configure_optimizers(self): # 配置优化器和学习率调度器 optimizer = torch.optim.Adam(self.parameters(), lr=1e-3) return [optimizer], [self.lr_scheduler]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
3.总结和展望
3.1.总结
本文深入探讨了Transformer模型及其在自然语言处理(NLP)和其他领域的应用。自2017年Vaswani等人提出以来,Transformer模型凭借其自注意力机制,在多个NLP任务上取得了突破性进展。文章首先介绍了Transformer模型的背景和开发动机,随后详细阐述了模型的结构和工作原理,包括多头注意力、位置编码以及学习率预热等关键技术。
我们通过实例代码,展示了如何从零开始构建Transformer模型的各个组成部分,包括多头注意力模块、位置编码策略、编码器层的实现,以及如何将这些组件整合到一个PyTorch Lightning模块中。此外,文章还讨论了Transformer模型在处理长序列时的优势和挑战,并提出了相应的解决方案。
3.2. 展望
尽管Transformer模型已经在多个领域取得了显著成就,但仍存在进一步改进和扩展应用的空间:
效率优化:随着模型规模的增长,如何提高Transformer模型的训练和推理效率仍是一个重要研究方向。
2. 长序列处理:Transformer模型在处理极长序列时仍然面临挑战,研究者们正在探索更高效的长序列处理方法。
3. 跨领域应用:Transformer模型在计算机视觉和语音识别等领域的应用还处于起步阶段,未来有望在这些领域实现更多突破。
4. 模型泛化能力:提高模型的泛化能力,使其能够更好地适应不同语言和领域的特性。
5. 解释性和可信赖性:提高模型的可解释性,帮助研究人员和用户理解模型的决策过程,同时确保模型的可信赖性。
6. 伦理和偏见问题:持续关注和解决模型可能存在的偏见问题,推动构建更加公正和伦理的AI系统。
7. 新任务和新架构:探索Transformer模型在新任务上的应用,并根据任务需求设计新的模型架构。
通过不断的研究和创新,我们期待Transformer模型在未来能够解锁更多可能性,为人工智能的发展做出更大的贡献。
本文全面总结了Transformer模型的核心概念、实现细节以及应用前景,并对其未来发展进行了展望。随着技术的不断进步和研究的深入,我们有理由相信,Transformer模型将在AI领域扮演更加关键的角色。


