





<article class="baidu_pl">
<div id="article_content" class="article_content clearfix">
<link rel="stylesheet" href="https://csdnimg.cn/release/blogv2/dist/mdeditor/css/editerView/ck_htmledit_views-6e43165c0a.css">
<div id="content_views" class="markdown_views prism-atom-one-dark">
<svg xmlns="http://www.w3.org/2000/svg" style="display: none;">
<path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id="raphael-marker-block" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path>
</svg>
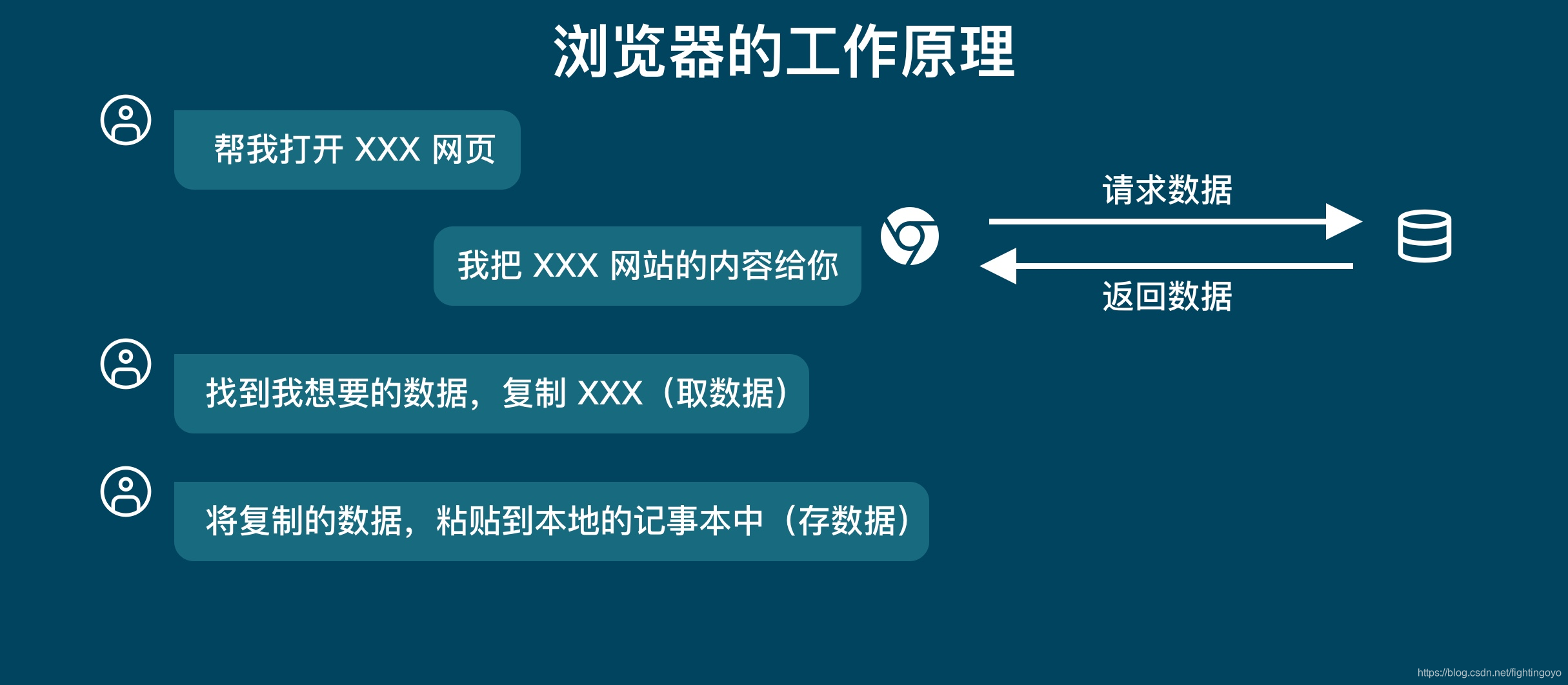
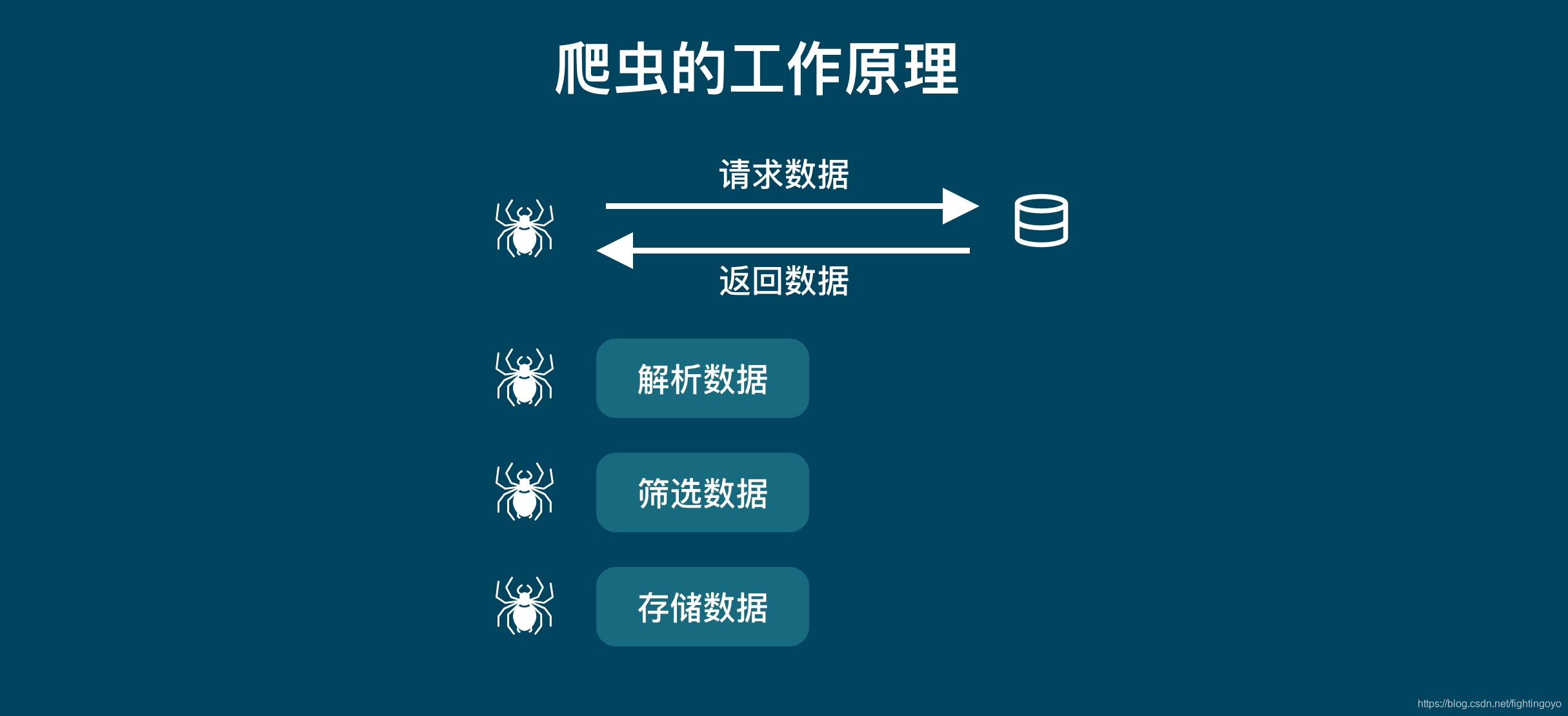
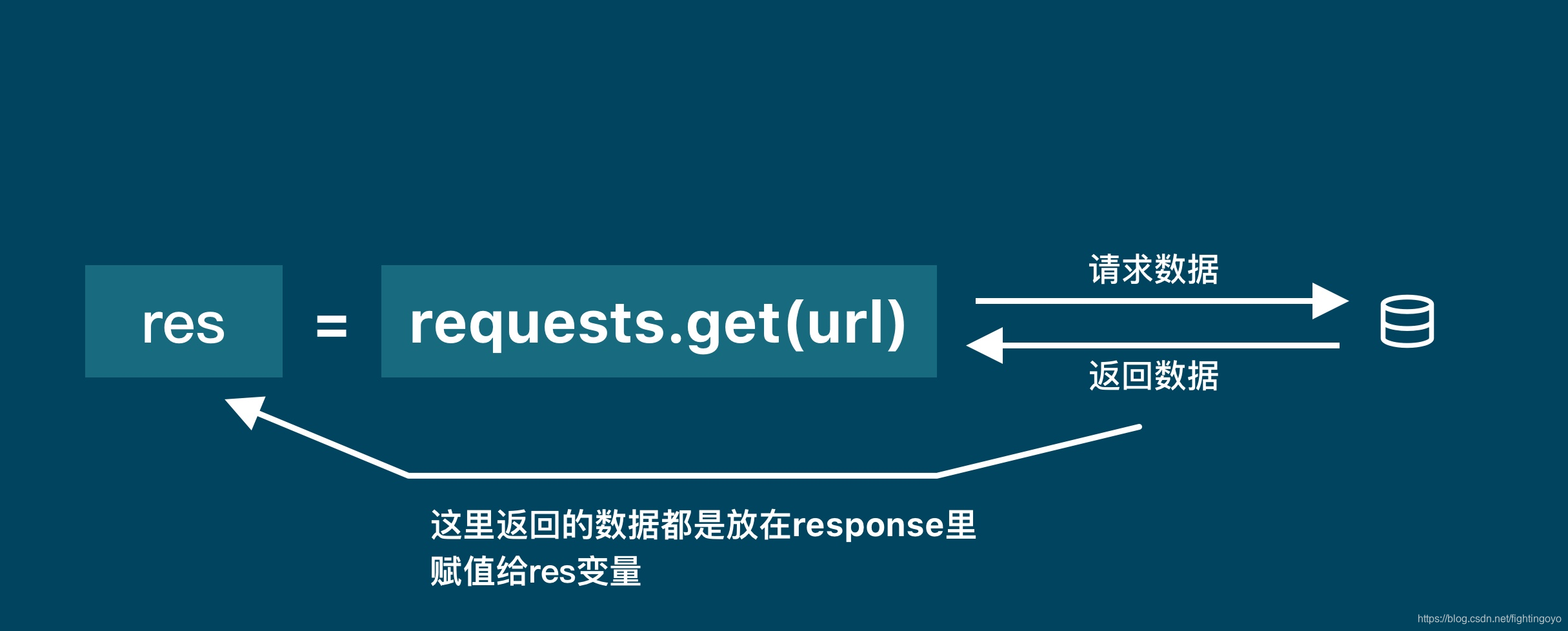
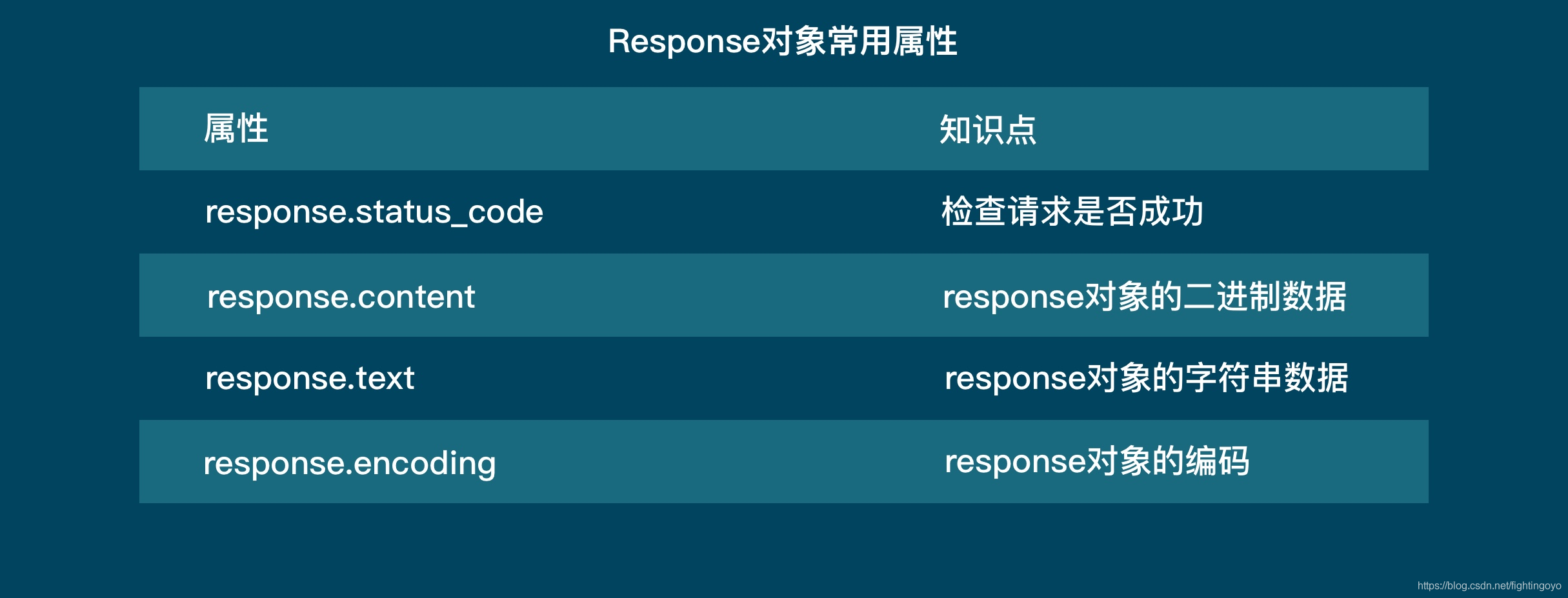
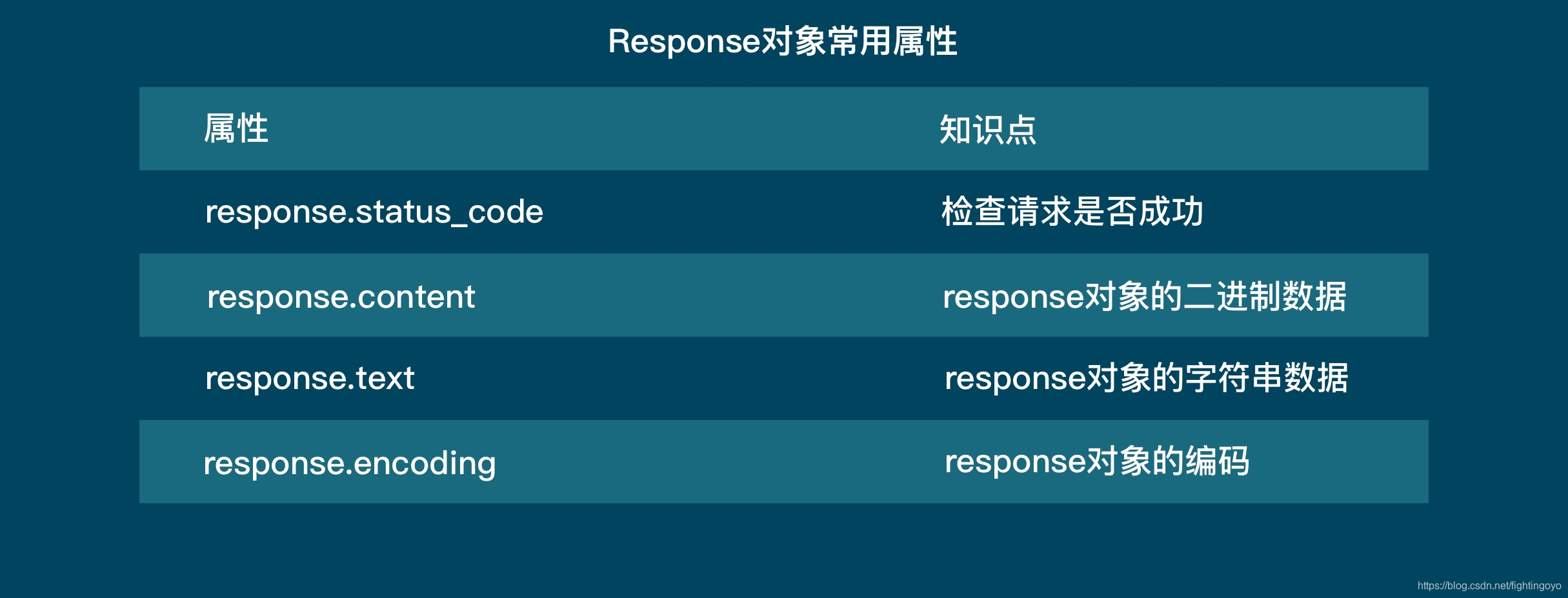
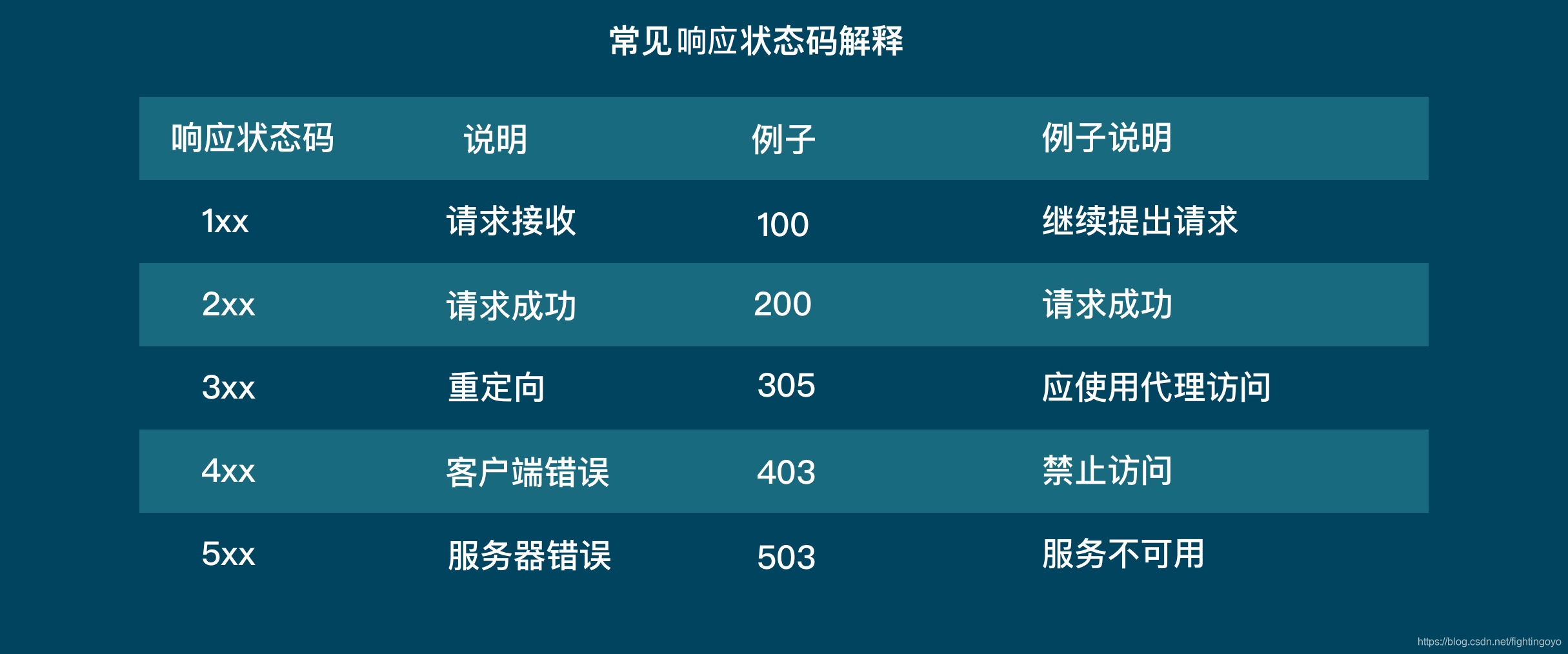
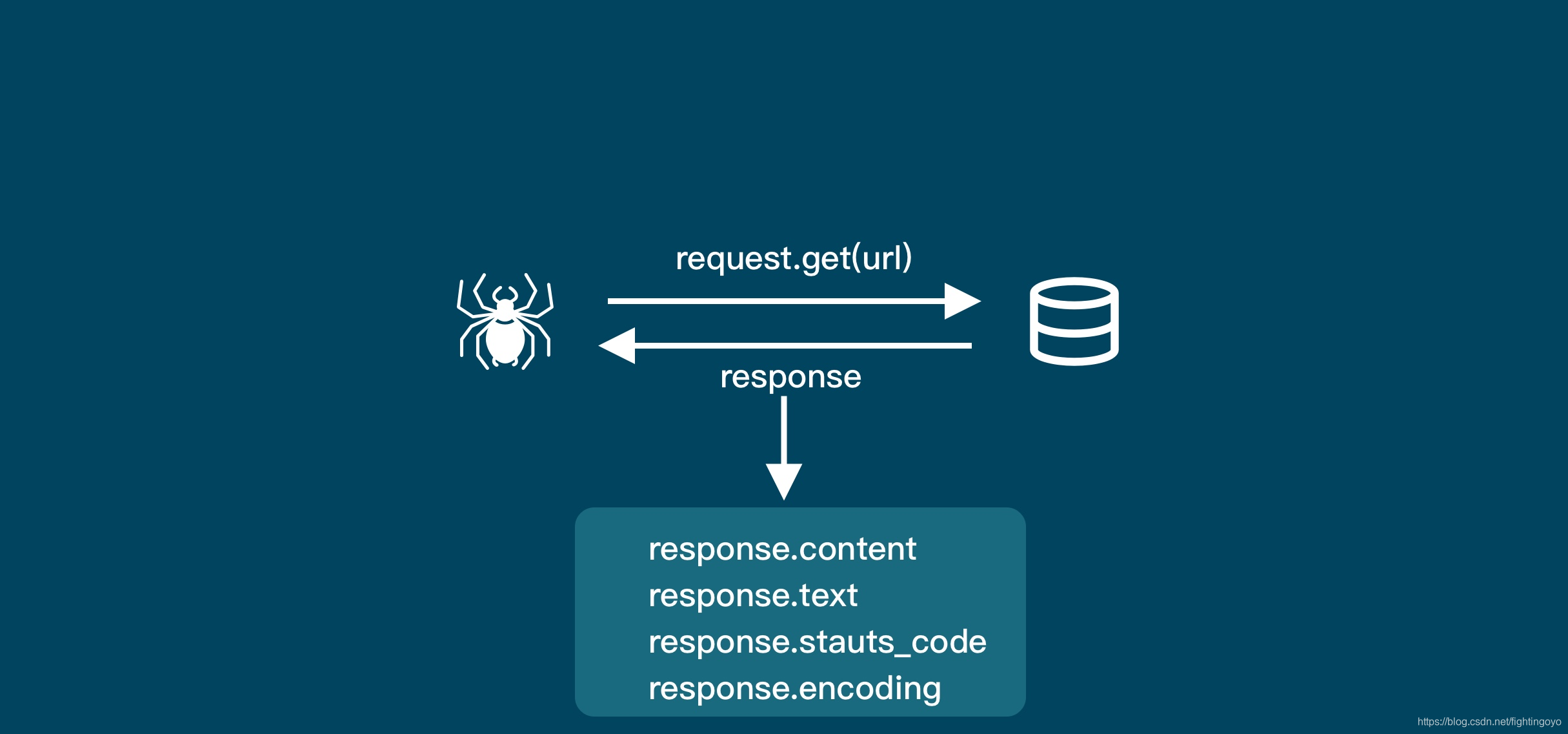
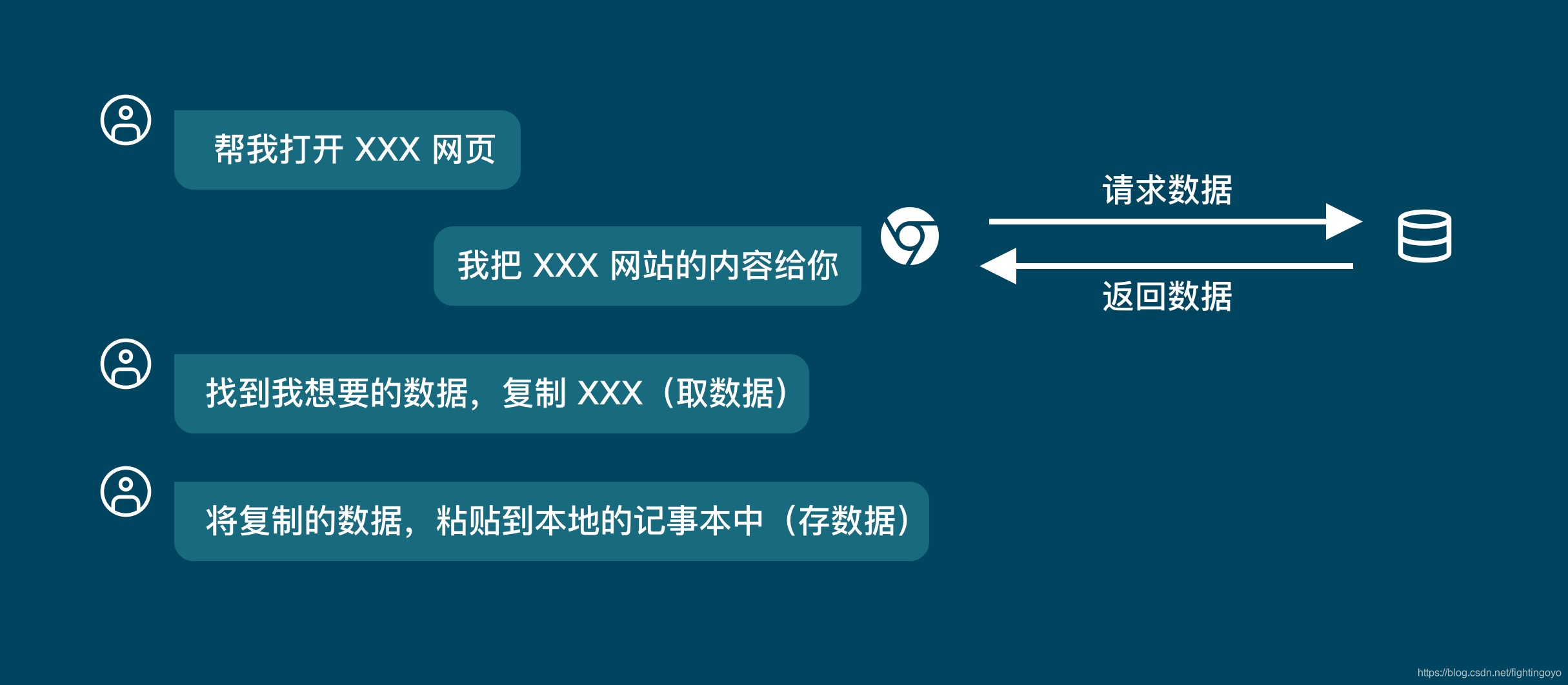
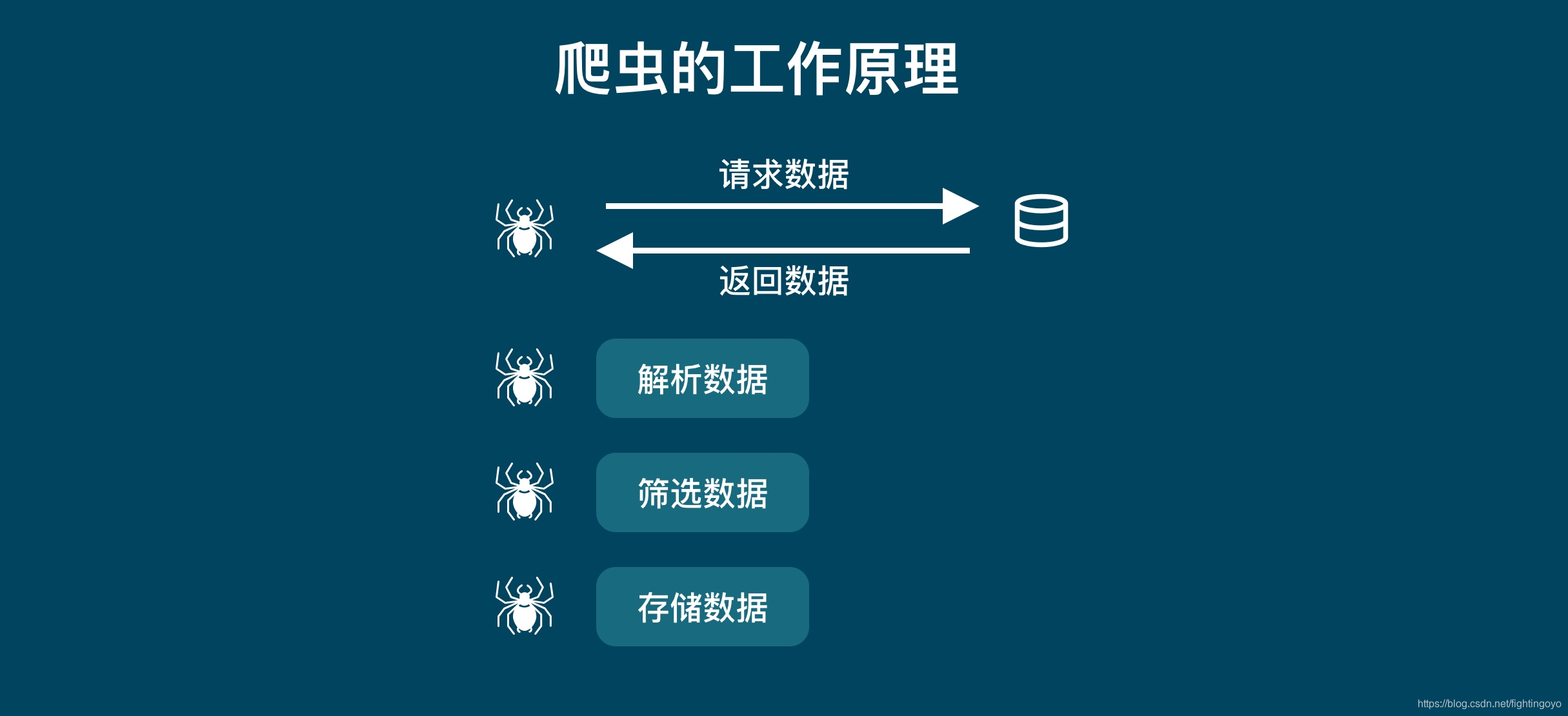
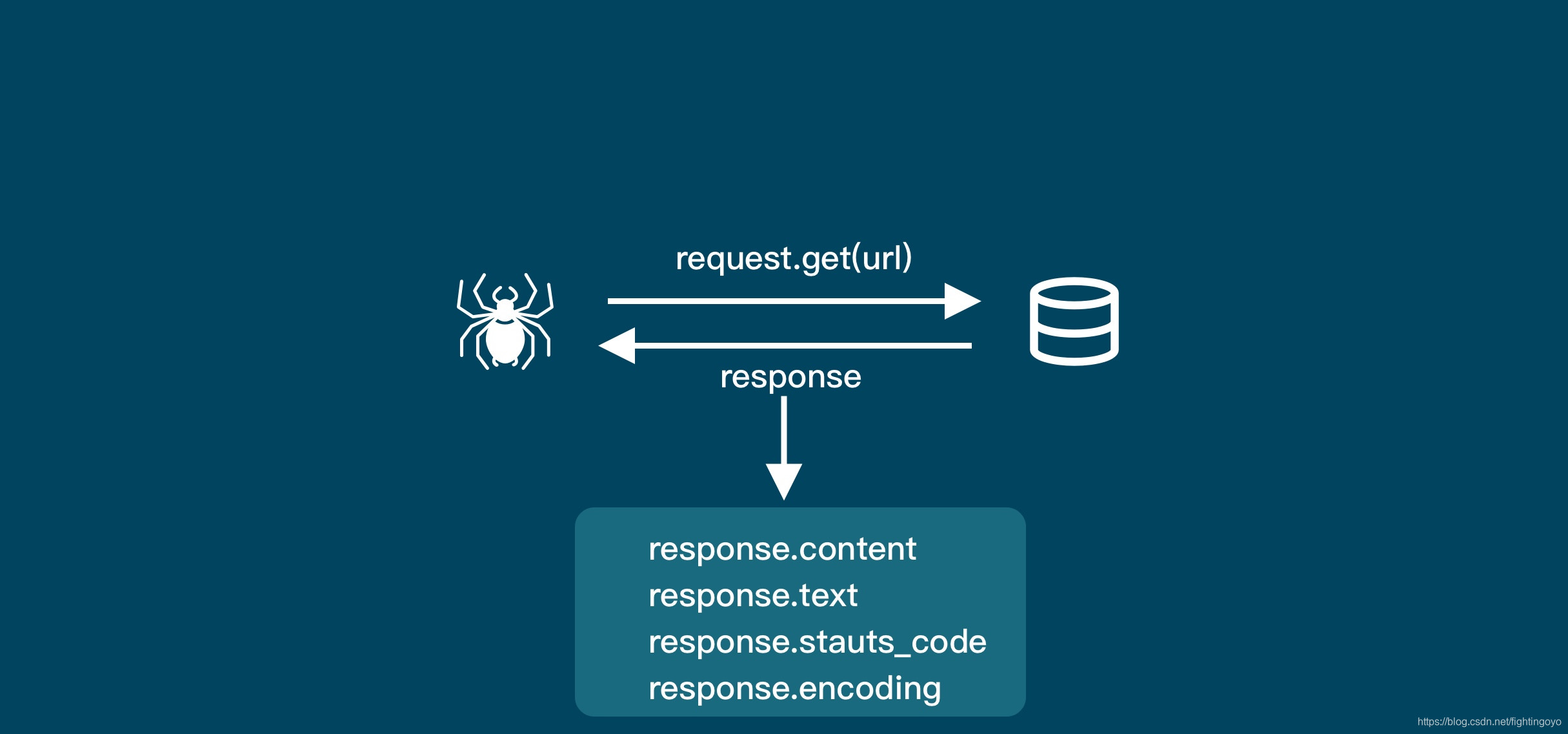
<h3><a name="t0"></a><a id="_0"></a>一、浏览器的工作原理</h3>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
















 3万+
3万+ 










 400-660-0108
400-660-0108 













 获取中
获取中

 扫码支付
扫码支付





weixin_43840345: pivot_table中有index有几个就对应有几层分类汇总
weixin_43840345: 大佬,有没有函数可以是实现多层分类汇总,感觉使用循环叠加会很麻烦
爱可劳特: 非常感谢博主,看了真的解了我得问题
python_xiaofeng: 收藏了。我是需要列索引是多层索引,不过方法是通用的,只是这里的index换成columns就可以了。
m0_51467506: 没有找到seaborn-data文件夹