
- 1知识图谱之《海贼王-ONEPICE》领域图谱项目实战(含码源):数据采集、知识存储、知识抽取、知识计算、知识应用、图谱可视化、问答系统(KBQA)等_知识图谱数据采集
- 2sourcetree 回滚提交_sourcetree回滚提交
- 3React 从入门到实战 一一开发环境基础搭建(小白篇)
- 4图神经网络 | (2) 图神经网络(Graph Neural Networks,GNN)综述_t2-gnn: graph neural networks for graphs with inco
- 52022下半年软件评测师真题评析_2022年软件评测师真题
- 6AI之DS/CV/NLP:Python与人工智能相关的库/框架(数据可视化常用库、机器学习常用库、数据科学常用库、深度学习常用库、计算机视觉常用库、自然语言处理常用库)的简介、案例应用之详细攻略_ds cv nlp
- 72023 最新 Java学习路线 java 学习资料_redis 书籍 pan
- 8信创应用软件之邮箱_信创邮箱
- 9【微服务-SpringCloud】详细介绍,搭建一套微服务项目_springcloud搭建一个微服务项目
- 10module ‘cv2‘ has no attribute ‘INTER‘_module 'cv2' has no attribute 'intersect
学生成绩排名预测(DC)_学生成绩预测
赞
踩
去年大数据分析课程的选题项目,最近考研不顺整理之前的杂碎半成品等丰富一下简历,准备找工作二战了,真是一个悲伤的现实,唉。
原题目链接:DC竞赛:学生成绩排名预测 【已挂】
相关数据:https://github.com/typeisgod/CSDN
题目背景和意义:
我们希望通过借助大数据相关的挖掘技术和基础算法,从学生的校园行为数据中,根据学生出入图书馆的次数,以及借书和消费情况等,挖掘用户作息规律、兴趣爱好等,精准地预测学生之间的相对排名。通过对这些日常行为的建模来预测学生的学业成绩,发现学生成绩和日常校园行为之间的潜在关系,可以实现提前预警学生的异常情况,并进行适当的干预,因而对学生的培养、管理工作将会起到极其重要的作用。
题目描述:
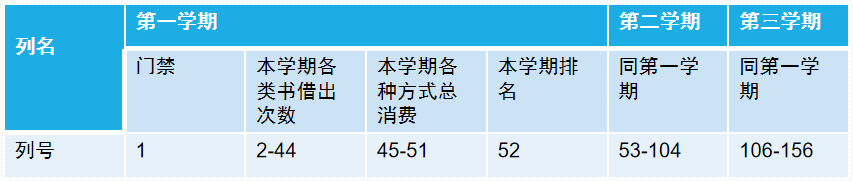
本次竞赛中,我们将从某高校的某个学院随机抽取一定比例学生,提供这些学生在三个学期的图书馆进出记录、一卡通消费记录、图书馆借阅记录、以及综合成绩的相对排名。这一部分数据将作为训练数据。我们从另外的某学院随机抽取一定比例的学生,然后提供他们在三个学期的图书馆进出记录、一卡通消费记录、图书借阅记录、以及前两个学期的成绩排名。第三学期的成绩排名作为预测目标。
提供文件:
训练\成绩.txt。训练集的成绩文件,包含学期、学号、以及相对排名
训练\借书.txt。训练集的图书借阅信息,包含学期、学号、书号、日期
训练\图书门禁.txt。 训练集的图书门禁进入,包含学期、学号、日期、时间
训练\消费.txt。训练集的消费数据,包含学期、学号、地点、日期、时间、金额
测试\成绩.txt。 测试集的成绩文件。字段同上 测试\借书.txt。 测试集的图书借阅信息。字段同上
测试\图书门禁.txt。 测试集的图书门禁进入。字段同上
测试\消费.txt。 测试集的消费数据。字段同上
评估标准:
算法通过衡量预测排名和实际排名的Spearman相关性,为[0,1]之间的值,值越大,表示越相关,排名的预测就越准确。若要考虑n个学生的排名,学生i的预测排名为pi,而实际的排名为ri,di = pi - ri,那么
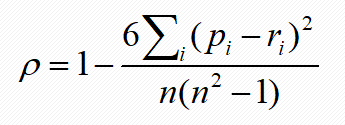
本数据统计模型(最后评分并不是很高,仅供参考):
后来觉得次数不一定决定成绩,应该还有稳定性。后来对门禁和借书计算了每个学期的月均值、月方差、日均值、日方差(第一、三学期五个月 第二学期六个月 每个月三十一天计算),扩展到了317维。之后归一化到了[0,1]之间。
我做的工作:提取成绩、图书馆门禁、借书;分析预测
汪东启的工作:提取图书类别(供借书使用)、消费;多维合并
一.书籍信息读取、检查与存储(汪东启)
0. 图书类别.txt 文件预览与格式:

1.文件的预读取与检查(test_check_book.py)
- # -*- coding: utf-8 -*-
- """
- Created on Mon May 7 14:53:24 2018
- @author: wangdongqi
- 读取书籍信息,检查数据中可能出现的问题
- """
-
- Book = dict()
- ClassNum = []
- err = []
-
- with open('图书类别.txt', encoding = 'utf-8') as f:
- f.readline();
- for line in f:
- (BookNumber, BookClass) = line.split('\t');
- if BookNumber not in Book.keys():
- Book[BookNumber] = [BookClass]
- else:
- Book[BookNumber].append(BookClass)
- print(BookNumber)
- err.append(BookNumber)
- if BookClass not in ClassNum:
- ClassNum.append(BookClass);
-
- # 测试重复的那些数据是否有变化
- err_list = []
- for i in err:
- tmp_list = Book[i]
- tmp = tmp_list[0]
- for j in tmp_list[1:]:
- if j != tmp:
- err_list.append(i)
- break
- # 结论:所有重复的数据的信息相同,对结果无影响
-
-
-

2.数据提取(test_read_book)
首先导入文件,将文件按行切分(split,代码使用replace直接替换)为BookNumber和bookclass,检查BookNumber是否为数字(防止图书编号中出现错切分的其他符号),如果是则放入字典BookInfo中;同时BookClass为list类型,用于存放一共出现的bookclass的种类数(文件中只有42种,但在其他文件中出现未在字典中的书籍,收集作为第43类)。最后通过pickle.load函数将BookInfo和BookClass数组存放下pkl中。
- # -*- coding: utf-8 -*-
- """
- Created on Mon May 7 15:49:55 2018
- @author: wangdongqi
- 读取书籍信息
- """
- BookInfo = dict()
- errInfo = dict()
- BookClass = []
-
- with open('图书类别.txt', encoding = 'utf-8') as f:
- f.readline();
- for line in f:
- line = line.replace('\n', '')
- (BookNumber, bookclass) = line.split('\t');
- if not BookNumber.isdigit():
- errInfo[BookNumber] = bookclass
- continue
-
- BookInfo[BookNumber] = bookclass
- if bookclass not in BookClass:
- BookClass.append(bookclass)
-
-
- # 排序
- BookClass.sort()
-
- # 打印42类书的类名
- for i in BookClass:
- print(i, end = ' ')
-
-
-
- # 保存信息
- import pickle
-
- # 保存
- pickle.dump(BookInfo, open('BookInfo.pkl', 'wb'))
- pickle.dump(BookClass, open('BookClass.pkl', 'wb'))
-
- # 读取
- BookInfo = pickle.load(open('BookInfo.pkl', 'rb'))
- BookClass = pickle.load(open('BookClass.pkl', 'rb'))
-
-
-
-
-
-
二.成绩、图书馆门禁、借书提取(Type) (pre.py)
0.文件预览与格式
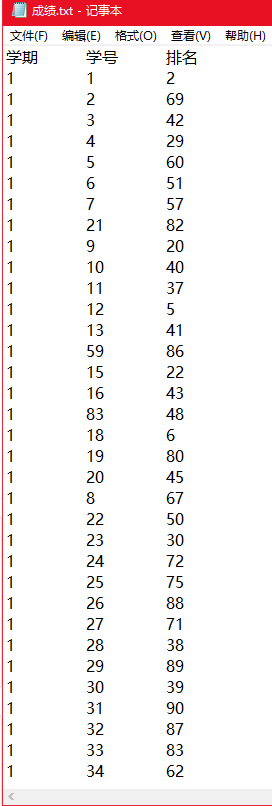


1.
依次读入成绩、图书馆门禁、借书三个txt文件,分别存入file_rank、file_ibrary、file_borrow变量中。
(1)file_rank:
每次读取一行(readline()),对每行未使用split等切割,而是手动实现的“字符切割”:(代码25-39行)
pre为某个字符段(数字段)的开始,初始化0,end为某个字符段(数字段)的结束,当没有扫描到行末尾时循环查找,当下标为pre的字符不为空(/t)时,end一直循环到下一个空(/t)或末尾的上一个字符(数字段结尾),然后取[pre:end](end不取),依次取数组段直到pre到行末,得到的多个数字段放入temp中,并合并到总data里(二维数组),读取下一行。全部读完后以学号为主key,学期为副key对data排序:data=sorted(data,key=lambda x:(x[1],x[0]))
此时data格式为:
| 学期 | 学号 | 排名 |
(2)file_library:
新增 月平均 月方差 月最大 月最小
日平均 日方差 日最大 日最小
06-22 小时点次数
(PS:月平均:平均每个月去图书馆的门禁次数,月最大:最多一个月去的门禁次数,其他同理
小时点次数:这个学期每个小时门禁次数汇总情况,并非每天每小时的次数)
新增共 25 维(最开始的模型只有下标3 新增4-28)
| 下标(从0开始) | 0 | 1 | 2 | 3 | 4-7 | 8-11 | 12-28 |
| 维/属性 | 学期 | 学号 | 排名 | 本学期图书馆门禁次数 | 月平均 月方差 月最大 月最小 | 日平均 日方差 日最大 日最小 | 06-22 小时点次数 |
从file_library提取的数据共26维(data下标对应3-28),建立一个和data等长(len(data)的)三维数组data3,用于存放每个学期每个学生每个月每天的图书馆门禁次数。
data3=np.zeros(shape=(len(data),6,31)).tolist();
用split('\t')分割每行为四个数字段,分别对应学期、学号、日期、时间。(代码中ent为回车符),通过学期和学号即可计算出对应data中的下标:index=(sid-1)*3+seme-1; (sid=学号,seme=学期)。
从时间提取出前二位数为小时hour([0:2]),同理从日期中提取出月份month和天day。并根据学期将每个学期的月份最低数规划到0,分别将每个月每天的次数存入data3中,将每小时(06时-22时)的门禁次数写入data中。(此上代码75-90行)
统计完毕后计算月均值mmean、月最大mmax、月最大mmax、月最小mmin、月方差mvar、日均值mmean、日最大mmax、日最大mmax、日最小mmin、日方差mvar并放入data的[4:12]中。
(3) file_borrow:(使用 一 中已经写好的pkl作为字典索引类别)
| 下标(从0开始) | 0 | 1 | 2 | 3-28 | 29-71 | 72-75 | 76-79 |
| 维/属性 | 学期 | 学号 | 排名 | file_library提取的属性列 | 每类书的借阅总次数(本数) | 月平均 月方差 月最大 月最小 | 日平均 日方差 日最大 日最小 |
读入pkl和file_library类似地统计每个人每个学期每类书(43类,用ABCD等表示)的总次数,和所有类型书的借阅月总次数、最大、最小、方差、日同理。
代码pre.py:
- # -*- coding: utf-8 -*-
- """
- Created on Mon May 7 13:28:12 2018
- @author: Type真是太帅了
- """
- import numpy as np
- import pickle
- file_rank=open('成绩.txt','r')
- file_library=open('图书馆门禁.txt','r')
- file_borrow=open('借书.txt','r')
- file_consume=open('消费.txt','r')
- #file_type=open('图书类别.txt','r')
-
- '''
- 学期 学号 图书馆门禁次数 食堂总消费 交通总消费 宿舍总消费 超市总消费 书类别 排名
- '''
- data=[]
- '''
- 读入成绩
- '''
- line = file_rank.readline()
- line = file_rank.readline()#直接读取第二行数据
- while line:
- temp=[]
- pre=0
- while pre<len(line)-2: #对于每行line的每个字符 将其转化为数字形式并存储于数组中 最后\n两个字符不读
- if line[pre]!='\t':
- end=pre+1
- while end<len(line)-1:
- if line[end]=='\t':
- temp=temp+[int(line[pre:end])]
- pre=end+1
- break
- else:
- end=end+1
- else:
- pre=pre+1
- end=pre+1
- data=data+[temp]
- line = file_rank.readline()
- '''
- 以学号为主key 学期为负key进行排序
- '''
- data=sorted(data,key=lambda x:(x[1],x[0]))
-
- '''
- 读入图书馆门禁次数(学期计)
- '''
-
- '''
- 新增 月平均 月方差 月最大 月最小
- 日平均 日方差 日最大 日最小
- 06-22 小时点次数
- 共 25 维
- 0 1 2 3 4567 891011 12-28 29-71
- 学期 学号 排名 总数 月 日 06-22 1-43
- '''
- line = file_library.readline()
- line = file_library.readline()#直接读取第二行数据
- zero26=np.zeros(26,int).tolist();#新建26维列表
- i=0
- while i<len(data):
- data[i]=data[i]+zero26;
- i=i+1
-
- data3=np.zeros(shape=(len(data),6,31)).tolist();#统计每天的次数 每个月取31天
- '''1/3学期 data3[index][0-4]表示 9-1月 9~0 10~1 11~2 12~3 1~4
- 2学期 data3[index][0-5]表示 2-7月
- '''
- n_1=5;#1 3 学期 5个月
- n_2=6;# 2 学期 6个月
- while line:
- readtime=0#记录读取次数 第一次读学期 第二次为学号
- (seme,sid,date,time,ent)=line.split('\t')
- seme=int(seme);
- sid=int(sid);
- index=(sid-1)*3+seme-1;#第seme的第sid号学生在data中的下标号
- data[index][3]+=1;#学期签到总数
- offset=6;#小时签到次数对应data列的偏移量
- #统计小时签到次数
- hour=int(time[0:2]);
- data[index][hour+offset]+=1;
- month=int(date[0:2]);
-
- day=int(date[2:])
- if seme!=2:
- data3[index][(month-9)%12][day-1]+=1;
- else:
- data3[index][month-2][day-1]+=1;
- line = file_library.readline()
-
- '''
- 根据data2和data3求均值 最大 最小 方差 并写入到data里
- '''
- i=0
- while i<len(data):
- if i%3==1:#是否为第二学期
- n=n_2;
- else:
- n=n_1;
- mmean=data[i][3]/n;
- dmean=data[i][3]/(n*31);
- m=np.zeros(n,int).tolist();#该人每个人的总数
- d=np.zeros(n*31,int).tolist()#该人每天的总数
- j=0#第j个月
- l=0#该学期第l天
- while j<n:
- m[j]=int(sum(data3[i][j]))
- k=0#第j月中的k天
- while k<31:
- d[l]=int(data3[i][j][k])
- l=l+1
- k=k+1
- j=j+1
- mmax=max(m);
- dmax=max(d);
- mmin=min(m);
- dmin=min(d);
- mvar=np.var(m);
- dvar=np.var(d);
- data[i][4:12]=mmean,mvar,mmax,mmin,dmean,dvar,dmax,dmin;
- i=i+1
- '''
- 借书
- '''
- """
- 读取书籍信息
- """
-
- BookInfo = dict()
- BookClass = ['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','TB','TD','TE','TF','TG','TH','TJ','TK','TL','TM','TN','TP','TQ','TS','TT','TU','TV','U','V','X','Y', 'Z','OO']
- '''
- pickle.dump(BookInfo,open('BookInfo.pkl','wb'))
- '''
- '''
- with open('图书类别.txt', encoding = 'utf-8') as f:
- f.readline();
- for line in f:
- line = line.replace('\n', '')
- (BookNumber, bookclass) = line.split('\t');
- if not BookNumber.isdigit():
- continue
-
- BookInfo[BookNumber] = bookclass
- '''
- '''
- 新增内容:
- 72 74 74 75 76 77 78 79
- 月总借书 日总借书
- 均值 方差 最大 最小
- ☞统计各种类书之和
- '''
- data2=np.zeros(shape=(len(data),6,31)).tolist();#统计每个学期每个人 某月的第某天借了几本书
-
- BookInfo=pickle.load(open('BookInfo.pkl','rb'))
- zero43=np.zeros(43,int).tolist()
- i=0
- offset=30 #书类别偏移
- while i<len(data):
- data[i]+=zero43
- i=i+1
- line=file_borrow.readline()
- line=file_borrow.readline()
-
- while line:
- (seme,sid,name,date,ent)=line.split('\t')
- index=(int(sid)-1)*3+int(seme)-1
- month=int(date[:2])
- day=int(date[2:])
- if int(seme)!=2:
- data2[index][(month-9)%12][day-1]+=1;
- else:
- data2[index][month-2][day-1]+=1;
- if name not in BookInfo.keys():
- data[index][42+offset-1]+=1
- else:
- i=0
- while i<len(BookClass)-1:
- if BookClass[i]==BookInfo[name]:
- break;
- i=i+1
- data[index][i+offset-1]+=1
- line=file_borrow.readline()
- i=0
- '''
- 计算月 日 放进 data
- '''
- zeros8=np.zeros(8,int).tolist();
- while i<len(data):
- data[i]+=zeros8
- i=i+1
- i=0
- while i<len(data):
- if i%3==1:
- n=n_2
- else:
- n=n_1
- num=sum(data[i][offset-1:])#某个人某学期总借书量
- mmean=num/n;
- dmean=num/(n*31);
- m=np.zeros(n,int).tolist();
- d=np.zeros(n*31,int).tolist();
- j=0#第j个月
- l=0#该学期第l天
- while j<n:
- m[j]=int(sum(data2[i][j]))
- k=0#第j月中的k天
- while k<31:
- d[l]=int(data2[i][j][k])
- l=l+1
- k=k+1
- j=j+1
- mmax=max(m);
- dmax=max(d);
- mmin=min(m);
- dmin=min(d);
- mvar=np.var(m);
- dvar=np.var(d);
- data[i][72:]=mmean,mvar,mmax,mmin,dmean,dvar,dmax,dmin;
- i=i+1
-
-
- ''' 学期、学号、排名、门禁、书籍信息 '''
- #pickle.dump(data, open('data_pre.pkl', 'wb'))
三 消费(汪东启,test_cost_read.py)
文件预览与格式:

(好像他给我说有的人一学期没有消费记录的,被他处理掉了,而且他把时间和日期之类的并没有考虑进来,当时我给他提出我的均值-最大-最小-方差体系的时候,他觉得很费劲没做,最后似乎就是统计了一下每类(食堂、宿舍、超市等)每人每学期的总消费)test_cost_read.py
- # -*- coding: utf-8 -*-
- """
- Created on Mon May 7 16:49:02 2018
- @author: wangdongqi
- 读取消费信息[term, stuID, place, date, time, cost]
- data、time两项暂定去除,不参与训练
- bug: 排序前将学号及学期改为数字,否则排序会错误
- """
-
- ''' ------------------读取消费信息----------------------- '''
- data = []
- with open('消费.txt') as f:
- f.readline();
- for line in f:
- line = line.replace('\n', '')
- tmp_list = line.split('\t')
- tmp_list = [int(tmp_list[0]), int(tmp_list[1]), tmp_list[2],
- int(tmp_list[3]), int(tmp_list[4]), float(tmp_list[5])]
- data.append(tmp_list)
-
- ''' -------------------获得地点列表---------------------- '''
- # 检查数据中的所有地点项
- AllPlace = [i[2] for i in data]
- AllPlace = list(set(AllPlace))
- AllPlace.sort()
- # 检查结果:['食堂', '交通', '超市', '宿舍', '教室', '图书馆', '打印']
-
- ''' --------------------进行排序--------------------- '''
- # 排序顺序:学号 > 学期 > 地点
- sort_list = sorted(data, key = lambda x : (x[1], x[0], x[2]))
-
- ''' ------------把相同地点的花费合并在一起------------- '''
- # 把相同地点的花费合并到一起
- resolve_list = []
- iterator = 0
- while iterator < len(sort_list):
- item = sort_list[iterator]
-
- # 获得基本信息
- info = item[:3]
-
- # 计算在某个地点的花费情况
- cost = item[-1]
- while iterator + 1 < len(sort_list) and info == sort_list[iterator + 1][:3]:
- iterator += 1
- cost += sort_list[iterator][-1]
-
- # 学号和学期转换为int类型,加入在某个地点处的消费情况
- info.append(round(cost, 2))
- resolve_list.append(info)
-
- iterator += 1
- # 格式:[学期(int),学号(int),地点,花费(float)]
-
- ''' ----------把每学期每个同学的消费情况合并------------- '''
- # 把每个学期每个同学的消费情况整理到一个数组中
- header = AllPlace
- iterator = 0
- result = []
- while iterator < len(resolve_list):
- item = resolve_list[iterator]
-
- # 获得基本信息
- info = item[:2]
-
- # 统计在每个地点的消费情况
- cost = dict()
- cost[item[2]] = item[3]
- while iterator + 1 < len(resolve_list) and info == resolve_list[iterator + 1][:2]:
- iterator += 1
- cost[resolve_list[iterator][2]] = resolve_list[iterator][3]
-
- # 整理到一个列表中
- cost_result = []
- for i in header:
- if i in cost.keys():
- cost_result.append(cost[i])
- else:
- cost_result.append(0)
-
- # 整合到一起
- info = info + cost_result
- result.append(info)
-
- iterator += 1
-
- ''' ------------------补全信息----------------------- '''
- # 把缺失的信息填补(置为0) 538个人 * 3个学期
- index = 0
- CostInfo = []
- for i in range(1, 538 + 1):
- for j in range(1, 3 + 1):
- if result[index][:2] == [j, i]:
- CostInfo.append(result[index])
- index += 1
- else:
- CostInfo.append([j, i, .0, .0, .0, .0, .0, .0, .0])
-
-
-
-
- ''' ------------------保存信息----------------------- '''
- import pickle
-
- # 保存
- pickle.dump(AllPlace, open('AllPlace.pkl', 'wb'))
- pickle.dump(CostInfo, open('CostInfo.pkl', 'wb'))
-
- # 读取
- # =============================================================================
- # AllPlace = pickle.load(open('AllPlace.pkl', 'rb'))
- # result = pickle.load(open('CostInfo.pkl', 'rb'))
- # =============================================================================
-
四 数据连接与重组(汪东启,Combine_data.py)
在这里把上边三部分产生的数据都存入了pkl文件中(pre的为pre_data.pkl),由于似乎每个学期之间是相互关联的(测试集为给你前两个学期的排名等信息和第三个学习的门禁等信息,预测第三个学期的排名),于是把每个人第二学期和第三学期的信息合并在了第一学期的右部分,即把每三列拉伸为一列:
把每个学期的排名放在每个学期的最后一列,同时去掉了学号、学期列。
抽出除最后一列的其他列作为train_x,最后一列作为train_y,保存在pkl中。
对于测试集同样处理,得到test_x,test_y从sample_submission.csv里直接读取。
Combine_data.py:
- # -*- coding: utf-8 -*-
- """
- Created on Sat May 12 14:13:18 2018
- @author: wangdongqi
- 组合所有的数据
- """
- import numpy as np
- import pickle
-
- data_pre = pickle.load(open('data_pre.pkl', 'rb'))
-
- AllPlace = pickle.load(open('AllPlace.pkl', 'rb'))
- BookClass = pickle.load(open('BookClass.pkl', 'rb')) + ['OO']
- BookInfo = pickle.load(open('BookInfo.pkl', 'rb'))
- CostInfo = pickle.load(open('CostInfo.pkl', 'rb'))
-
- if len(data_pre) != len(CostInfo):
- raise RuntimeError('信息不一致')
-
- length = len(data_pre)
-
- Data = []
- for index in range(length):
- if data_pre[index][:2] == CostInfo[index][:2]:
- Data.append(data_pre[index] + CostInfo[index][2:])
- else:
- raise RuntimeError('信息错误')
-
- labels = ['term', 'stuID', 'score', 'LibDoor']
- labels = labels + BookClass + AllPlace
-
- '''
- 存储格式:学期,学号,排名,门禁,
- '''
-
- pickle.dump(Data, open('Data.pkl', 'wb'))
- pickle.dump(labels, open('labels.pkl', 'wb'))
-
-
- '''
- 把三个学期的成绩合在一起,不要学期,学号,成绩放在最后
- '''
- label_tmp1 = ['term1_' + i for i in labels[3:]] + ['term1_score']
- label_tmp2 = ['term2_' + i for i in labels[3:]] + ['term2_score']
- label_tmp3 = ['term3_' + i for i in labels[3:]]
- train_label = label_tmp1 + label_tmp2 + label_tmp3
-
- pickle.dump(train_label, open('train_label.pkl', 'wb'))
-
- train_x = []
- train_y = []
- for index in range(int(len(Data) / 3)):
- tmp = []
- for i in range(3):
- d = Data[index * 3 + i]
- tmp = tmp + d[3:] + [d[3]]
- train_x.append(tmp[:-1])
- train_y.append(tmp[-1])
-
- pickle.dump(train_x, open('train_x.pkl', 'wb'))
- pickle.dump(train_y, open('train_y.pkl', 'wb'))
五:分析与预测(Type)
这个不多bb直接读入train_x、train_y、test_x、test_y,然后放入各种model预测分析就好了。
- # -*- coding: utf-8 -*-
- """
- Created on Mon May 21 15:07:52 2018
- @author: 71405
- """
-
- import pickle
- dir_name = './'
- x1=pickle.load(open(dir_name + 'train_x.pkl','rb'))
- y1=pickle.load(open(dir_name + 'train_y.pkl','rb'))
- x2=pickle.load(open(dir_name + 'test_x.pkl', 'rb'))
- y2=pickle.load(open(dir_name + 'test_y.pkl', 'rb'))
-
-
- #Label=pickle.load(open('train_label.pkl','rb'))
- from sklearn.ensemble import RandomForestRegressor
- from sklearn.neighbors import KNeighborsClassifier
- from sklearn import svm
- import numpy as np
-
- # 把训练数据归一化
- def Normalization(train_data, test_data):
- train_normal_data = np.zeros(train_data.shape, dtype = 'float')
- test_normal_data = np.zeros(test_data.shape, dtype = 'float')
-
- max_num = []
-
- if len(train_data.shape) == 2:
- # 训练数据
- for col in range(train_data.shape[1]):
- col_data1 = train_data[..., col]
- col_data2 = test_data[..., col]
-
- max_data = max(max(col_data1), max(col_data2))
- min_data = 0
- max_num.append(max_data)
-
- col_data1 = (col_data1 - min_data) / (max_data - min_data + 1)
- col_data2 = (col_data2 - min_data) / (max_data - min_data + 1)
-
- train_normal_data[..., col] = col_data1
- test_normal_data[..., col] = col_data2
-
- return train_normal_data, test_normal_data, max_num
-
-
-
- x_train=np.array(x1)
- y_train=np.array(y1)
- x_test=np.array(x2)
- y_test=np.array(y2)
-
- x_train, x_test, max_num = Normalization(x_train, x_test)
- y_train = y_train / max(y_train)
-
- # model = KNeighborsClassifier(10)
- # model=svm.SVC(C=2, kernel='linear',decision_function_shape='ovr')
- model = RandomForestRegressor(1000)
- model.fit(x_train,y_train)
- scores=model.score(x_test,y_test)
- y_predict=model.predict(x_test)
- scores=model.score(x_test,y_test)
- i=0
- t=0
-
- def sort_predict(y_predict):
- y = np.zeros(y_predict.shape)
-
- max_ = max(y_predict)
- for index in range(len(y_predict)):
- min_index = y_predict.argmin()
- y[min_index] = index + 1
- y_predict[min_index] = max_ + 1
-
- return y
-
- y_predict = sort_predict(y_predict)
-
- while i<len(y_predict):
- if(abs(round(y_predict[i])-y_test[i]) <= 3):
- t=t+1
- i=i+1
- t=t/len(y_predict)
-
- n = len(y_predict)
- rou = 1 - 1 * sum((y_predict - y_test) ** 2) / (n * (n ** 2 - 1))
最后的评分好像只有0.84(满分1)
PS:之前第一版代码中,数据连接(Combine_data)中出现了错误提取,导致最后的评分超级高(训练集提取一部分训练另一部分测试时接近于1,而测试集测试时评分是负值,后来发现在训练集的data里提出了排名列而未删掉,似乎是删错了列,然后分析的时候排名列权值接近于1);由于年久失修,可能贴的代码为最老的代码,有部分错误,然后想找最新版的时候找到了一些他改造后的乱七八糟的代码,就随便贴一下:
read_data.py:(这个应该是最后正确的连接,pre2和pre_treat为之前的pre代码改造版)
- # -*- coding: utf-8 -*-
- """
- Created on Thu Jun 7 09:06:31 2018
- @author: Administrator
- 读取数据的函数
- """
-
- import numpy as np
- import pickle
- from pre_treat import pre_train
- from pre2 import pre_test
-
- def SaveData(Data, filename):
- pickle.dump(Data, open(filename, 'wb'))
-
- def LoadData(filename):
- return pickle.load(open(filename, 'rb'))
-
- # 读取图书类别信息
- def read_bookinfo(bookinfo_path):
- BookInfo = dict();
- errBookInfo = dict();
- BookClass = [];
-
- with open('图书类别.txt', encoding = 'utf-8') as f:
- f.readline();
- for line in f:
- line = line.replace('\n', '')
- (BookNumber, bookclass) = line.split('\t');
- if not BookNumber.isdigit():
- errBookInfo[BookNumber] = bookclass
- continue
-
- BookInfo[BookNumber] = bookclass
- if bookclass not in BookClass:
- BookClass.append(bookclass)
-
- # 排序
- BookClass.sort()
-
- # 保存
- SaveData(BookInfo, 'BookInfo.pkl')
- SaveData(errBookInfo, 'errBookInfo.pkl')
- SaveData(BookClass, 'BookClass.pkl')
-
- return BookInfo, errBookInfo, BookClass
-
- # 读取消费信息文件
- def read_cost(cost_path, people_num = 0):
- ''' ------------------读取消费信息----------------------- '''
- ''' 消费信息:[term, stuID, place, date, time, cost] '''
- cost_data = []
- AllPlace = []
- with open(cost_path) as f:
- f.readline();
- for line in f:
- line = line.replace('\n', '')
-
- tmp_list = line.split('\t')
- tmp_list = [int(tmp_list[0]), int(tmp_list[1]), tmp_list[2],
- int(tmp_list[3]), int(tmp_list[4]), float(tmp_list[5])]
-
- cost_data.append(tmp_list)
- AllPlace.append(tmp_list[2])
-
- ''' -------------------获得地点列表---------------------- '''
- AllPlace = list(set(AllPlace))
- AllPlace.sort()
- # 检查结果:['食堂', '交通', '超市', '宿舍', '教室', '图书馆', '打印']
-
- ''' --------------------进行排序--------------------- '''
- # 排序顺序:学号 > 学期 > 地点
- sort_key = [1, 0, 2, 3, 4, 5]
- sorted_list = sorted(cost_data, key = lambda x : (x[sort_key[0]], x[sort_key[1]], x[sort_key[2]], x[sort_key[3]], x[sort_key[4]], x[sort_key[5]]))
-
- ''' ------------把所有数据合并到同一个字典中------------- '''
- resolve_dict = dict();
-
- for item in sorted_list:
- tmp = resolve_dict
- for index in range(4):
- if item[index] in tmp.keys():
- pass
- else:
- tmp[item[index]] = dict()
- tmp = tmp[item[index]]
-
- if item[4] not in tmp.keys():
- tmp[item[4]] = []
- tmp = tmp[item[4]]
-
- tmp.append(item[5])
-
- ''' -------处理数据--------- '''
- if people_num == 0:
- people_num = 0
- for i in resolve_dict:
- people_num = max(people_num, max(resolve_dict[i]))
-
- new_info = []
- for people in range(1, people_num + 1):
- # 学号
- people_info = []
-
- err_term = []
- for term in range(1, 4):
- # 学期 最大 最小 总和 次数
- if people not in resolve_dict[term].keys():
- people_info.extend([0] * 28)
- err_term.append(term)
- continue
-
- for place in AllPlace:
- if place not in resolve_dict[term][people].keys():
- people_info.extend([0] * 4)
- continue
-
- # 地点
- cost_info = resolve_dict[term][people][place]
- every_cost = []
- for key1 in cost_info:
- for key2 in cost_info[key1]:
- every_cost.extend(cost_info[key1][key2])
-
- max_num = max(every_cost)
- min_num = min(every_cost)
- sum_num = sum(every_cost)
- times = len(every_cost)
- people_info.extend([max_num, min_num, sum_num, times])
-
- # =============================================================================
- # # 如果某个学期全部为0的处理
- # if len(err_term) != 0:
- # True_term = []
- # for i in range(1, 4):
- # if i not in err_term:
- # True_term.append(people_info[(i - 1) * 28 : i * 28])
- # True_info = [0] * 28
- # True_num = 0
- # for i in True_term:
- # True_info = [True_info[j] + i[j] for j in range(28)]
- # True_num += 1
- # if True_num != 0:
- # True_info = [i / True_num for i in True_info]
- # for i in err_term:
- # people_info[(i - 1) * 28 : i * 28] = True_info
- #
- # =============================================================================
- tmp = [people] + people_info
- new_info.append(tmp)
-
- SaveData(new_info, 'cost_info.pkl')
-
- return new_info
-
- # 读取图书馆门禁文件
- def read_library(liabrary_path):
-
- pass
-
- # 读取借书文件
- def read_borrow(borrow_path):
-
- pass
-
- # 读取成绩文件
- def read_rank(rank_path):
-
- pass
-
- def combine_train():
- cost_path = './training/消费.txt'
- cost = read_cost(cost_path)
- # 先运行pre
- train_predata_x, train_y = pre_train()
- train_x = []
- for i in range(538):
- train_x.append(cost[i][1:] + train_predata_x[i][1:])
-
- SaveData(train_x, './train_x.pkl')
- SaveData(train_y, './train_y.pkl')
-
- return train_x, train_y
-
- def combine_test():
- cost_path = './test/消费.txt'
- cost = read_cost(cost_path, 91)
- # 先运行pre
- test_predata_x, test_y = pre_test()
- test_x = []
- for i in range(91):
- test_x.append(cost[i][1:] + test_predata_x[i][1:])
-
- SaveData(test_x, './test_x.pkl')
- SaveData(test_y, './test_y.pkl')
-
- return test_x, test_y
-
- #x,y = combine_train()
- test_x, test_y = combine_test()
- train_x, train_y = combine_train()
pre2.py:
- # -*- coding: utf-8 -*-
- """
- Created on Mon May 7 13:28:12 2018
- @author: Type真是太帅了
- """
- import numpy as np
- import pickle
-
- def pre_test():
- file_rank=open('./test/成绩.txt','r')
- file_library=open('./test/图书馆门禁.txt','r')
- file_borrow=open('./test/借书.txt','r')
- file_consume=open('./test/消费.txt','r')
- file_type=open('图书类别.txt','r')
-
- '''
- 学期 学号 图书馆门禁次数 食堂总消费 交通总消费 宿舍总消费 超市总消费 书类别 排名
- '''
- data=[]
- '''
- 读入成绩
- '''
- line = file_rank.readline()
- line = file_rank.readline()#直接读取第二行数据
- while line:
- (seme,sid,rank,)=line.split('\t')
- temp=[int(seme),int(sid),int(rank)]
- data=data+[temp]
- line = file_rank.readline()
-
- i=1
- while i<538:
- temp=[3,i,-1]
- data=data+[temp]
- i=i+1
-
- '''
- 以学号为主key 学期为负key进行排序
- '''
- data=sorted(data,key=lambda x:(x[1],x[0]))
-
- '''
- 读入图书馆门禁次数(学期计)
- '''
-
- '''
- 新增 月平均 月方差 月最大 月最小
- 日平均 日方差 日最大 日最小
- 06-22 小时点次数
- 共 25 维
- 0 1 2 3 4567 891011 12-28 29-71
- 学期 学号 排名 总数 月 日 06-22 1-43
- '''
- line = file_library.readline()
- line = file_library.readline()#直接读取第二行数据
- zero26=np.zeros(26,int).tolist();
- i=0
- while i<len(data):
- data[i]=data[i]+zero26;
- i=i+1
-
- data3=np.zeros(shape=(len(data),6,31)).tolist();#统计每天的次数 每个月取31天
- '''1/3学期 data3[index][0-4]表示 9-1月 9~0 10~1 11~2 12~3 1~4
- 2学期 data3[index][0-5]表示 2-7月
- '''
- n_1=5;#1 3 学期 5个月
- n_2=6;# 2 学期 6个月
- while line:
- readtime=0#记录读取次数 第一次读学期 第二次为学号
- (seme,sid,date,time,)=line.split('\t')
- seme=int(seme);
- sid=int(sid);
- index=(sid-1)*3+seme-1;#第seme的第sid号学生在data中的下标号
- data[index][3]+=1;#学期签到总数
- offset=6;#小时签到次数对应data列的偏移量
- #统计小时签到次数
- hour=int(time[0:2]);
- data[index][hour+offset]+=1;
- month=int(date[0:2]);
-
- day=int(date[2:])
- if seme!=2:
- data3[index][(month-9)%12][day-1]+=1;
- else:
- data3[index][month-2][day-1]+=1;
- line = file_library.readline()
-
- '''
- 根据data2和data3求均值 最大 最小 方差 并写入到data里
- '''
- i=0
- while i<len(data):
- if i%3==1:#是否为第二学期
- n=n_2;
- else:
- n=n_1;
- mmean=data[i][3]/n;
- dmean=data[i][3]/(n*31);
- m=np.zeros(n,int).tolist();#该人每个人的总数
- d=np.zeros(n*31,int).tolist()#该人每天的总数
- j=0#第j个月
- l=0#该学期第l天
- while j<n:
- m[j]=int(sum(data3[i][j]))
- k=0#第j月中的k天
- while k<31:
- d[l]=int(data3[i][j][k])
- l=l+1
- k=k+1
- j=j+1
- mmax=max(m);
- dmax=max(d);
- mmin=min(m);
- dmin=min(d);
- mvar=np.var(m);
- dvar=np.var(d);
- data[i][4:12]=mmean,mvar,mmax,mmin,dmean,dvar,dmax,dmin;
- i=i+1
- '''
- 借书
- '''
- """
- 读取书籍信息
- """
-
- BookInfo = dict()
- BookClass = ['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','TB','TD','TE','TF','TG','TH','TJ','TK','TL','TM','TN','TP','TQ','TS','TT','TU','TV','U','V','X','Y', 'Z','OO']
- '''
- pickle.dump(BookInfo,open('BookInfo.pkl','wb'))
- '''
- '''
- with open('图书类别.txt', encoding = 'utf-8') as f:
- f.readline();
- for line in f:
- line = line.replace('\n', '')
- (BookNumber, bookclass) = line.split('\t');
- if not BookNumber.isdigit():
- continue
-
- BookInfo[BookNumber] = bookclass
- '''
- '''
- 新增内容:
- 72 74 74 75 76 77 78 79
- 月总借书 日总借书
- 均值 方差 最大 最小
- ☞统计各种类书之和
- '''
- data2=np.zeros(shape=(len(data),6,31)).tolist();#统计每个学期每个人 某月的第某天借了几本书
-
- BookInfo=pickle.load(open('BookInfo.pkl','rb'))
- zero43=np.zeros(43,int).tolist()
- i=0
- offset=30 #书类别偏移
- while i<len(data):
- data[i]+=zero43
- i=i+1
- line=file_borrow.readline()
- line=file_borrow.readline()
-
- while line:
- (seme,sid,name,date,)=line.split('\t')
- index=(int(sid)-1)*3+int(seme)-1
- month=int(date[:2])
- day=int(date[2:])
- if int(seme)!=2:
- data2[index][(month-9)%12][day-1]+=1;
- else:
- data2[index][month-2][day-1]+=1;
- if name not in BookInfo.keys():
- data[index][42+offset-1]+=1
- else:
- i=0
- while i<len(BookClass)-1:
- if BookClass[i]==BookInfo[name]:
- break;
- i=i+1
- data[index][i+offset-1]+=1
- line=file_borrow.readline()
- i=0
- '''
- 计算月 日 放进 data
- '''
- zeros8=np.zeros(8,int).tolist();
- while i<len(data):
- data[i]+=zeros8
- i=i+1
- i=0
- while i<len(data):
- if i%3==1:
- n=n_2
- else:
- n=n_1
- num=sum(data[i][offset-1:])#某个人某学期总借书量
- mmean=num/n;
- dmean=num/(n*31);
- m=np.zeros(n,int).tolist();
- d=np.zeros(n*31,int).tolist();
- j=0#第j个月
- l=0#该学期第l天
- while j<n:
- m[j]=int(sum(data2[i][j]))
- k=0#第j月中的k天
- while k<31:
- d[l]=int(data2[i][j][k])
- l=l+1
- k=k+1
- j=j+1
- mmax=max(m);
- dmax=max(d);
- mmin=min(m);
- dmin=min(d);
- mvar=np.var(m);
- dvar=np.var(d);
- data[i][72:]=mmean,mvar,mmax,mmin,dmean,dvar,dmax,dmin;
- i=i+1
-
- data = data[:273]
- # 整理data
- test_predata_x = []
- for i in range(91):
- tmp = [data[i * 3][2], data[i * 3 + 1][2]] + [data[i * 3][1]] + data[i * 3][3:] + data[i * 3 + 1][3:] + \
- data[i * 3 + 2][3:]
-
- test_predata_x.append(tmp)
-
- # 整理输出结果
- test_y = []
- with open('sample_submission.csv', 'r') as f:
- lines = f.readlines()
- for line in lines[1:]:
- line.replace('\n', '')
- test_y.append(int(line.split(',')[1]))
-
-
- ''' 学期、学号、排名、门禁、书籍信息 '''
- #pickle.dump(data, open('data_pre.pkl', 'wb'))
-
- return test_predata_x, test_y
pre_treat.py:
- # -*- coding: utf-8 -*-
- """
- Created on Mon May 7 13:28:12 2018
- @author: Type真是太帅了
- """
- import numpy as np
- import pickle
-
- def pre_train():
- file_rank=open('成绩.txt','r')
- file_library=open('图书馆门禁.txt','r')
- file_borrow=open('借书.txt','r')
- file_consume=open('消费.txt','r')
- #file_type=open('图书类别.txt','r')
-
- '''
- 学期 学号 图书馆门禁次数 食堂总消费 交通总消费 宿舍总消费 超市总消费 书类别 排名
- '''
- data=[]
- '''
- 读入成绩
- '''
- line = file_rank.readline()
- line = file_rank.readline()#直接读取第二行数据
- while line:
- temp=[]
- pre=0
- while pre<len(line)-2: #对于每行line的每个字符 将其转化为数字形式并存储于数组中 最后\n两个字符不读
- if line[pre]!='\t':
- end=pre+1
- while end<len(line)-1:
- if line[end]=='\t':
- temp=temp+[int(line[pre:end])]
- pre=end+1
- break
- else:
- end=end+1
- else:
- pre=pre+1
- end=pre+1
- data=data+[temp]
- line = file_rank.readline()
- '''
- 以学号为主key 学期为负key进行排序
- '''
- data=sorted(data,key=lambda x:(x[1],x[0]))
-
- '''
- 读入图书馆门禁次数(学期计)
- '''
-
- '''
- 新增 月平均 月方差 月最大 月最小
- 日平均 日方差 日最大 日最小
- 06-22 小时点次数
- 共 25 维
- 0 1 2 3 4567 891011 12-28 29-71
- 学期 学号 排名 总数 月 日 06-22 1-43
- '''
- line = file_library.readline()
- line = file_library.readline()#直接读取第二行数据
- zero26=np.zeros(26,int).tolist();
- i=0
- while i<len(data):
- data[i]=data[i]+zero26;
- i=i+1
-
- data3=np.zeros(shape=(len(data),6,31)).tolist();#统计每天的次数 每个月取31天
- '''1/3学期 data3[index][0-4]表示 9-1月 9~0 10~1 11~2 12~3 1~4
- 2学期 data3[index][0-5]表示 2-7月
- '''
- n_1=5;#1 3 学期 5个月
- n_2=6;# 2 学期 6个月
- while line:
- readtime=0#记录读取次数 第一次读学期 第二次为学号
- (seme,sid,date,time,ent)=line.split('\t')
- seme=int(seme);
- sid=int(sid);
- index=(sid-1)*3+seme-1;#第seme的第sid号学生在data中的下标号
- data[index][3]+=1;#学期签到总数
- offset=6;#小时签到次数对应data列的偏移量
- #统计小时签到次数
- hour=int(time[0:2]);
- data[index][hour+offset]+=1;
- month=int(date[0:2]);
-
- day=int(date[2:])
- if seme!=2:
- data3[index][(month-9)%12][day-1]+=1;
- else:
- data3[index][month-2][day-1]+=1;
- line = file_library.readline()
-
- '''
- 根据data2和data3求均值 最大 最小 方差 并写入到data里
- '''
- i=0
- while i<len(data):
- if i%3==1:#是否为第二学期
- n=n_2;
- else:
- n=n_1;
- mmean=data[i][3]/n;
- dmean=data[i][3]/(n*31);
- m=np.zeros(n,int).tolist();#该人每个人的总数
- d=np.zeros(n*31,int).tolist()#该人每天的总数
- j=0#第j个月
- l=0#该学期第l天
- while j<n:
- m[j]=int(sum(data3[i][j]))
- k=0#第j月中的k天
- while k<31:
- d[l]=int(data3[i][j][k])
- l=l+1
- k=k+1
- j=j+1
- mmax=max(m);
- dmax=max(d);
- mmin=min(m);
- dmin=min(d);
- mvar=np.var(m);
- dvar=np.var(d);
- data[i][4:12]=mmean,mvar,mmax,mmin,dmean,dvar,dmax,dmin;
- i=i+1
- '''
- 借书
- '''
- """
- 读取书籍信息
- """
-
- BookInfo = dict()
- BookClass = ['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','TB','TD','TE','TF','TG','TH','TJ','TK','TL','TM','TN','TP','TQ','TS','TT','TU','TV','U','V','X','Y', 'Z','OO']
- '''
- pickle.dump(BookInfo,open('BookInfo.pkl','wb'))
- '''
- '''
- with open('图书类别.txt', encoding = 'utf-8') as f:
- f.readline();
- for line in f:
- line = line.replace('\n', '')
- (BookNumber, bookclass) = line.split('\t');
- if not BookNumber.isdigit():
- continue
-
- BookInfo[BookNumber] = bookclass
- '''
- '''
- 新增内容:
- 72 74 74 75 76 77 78 79
- 月总借书 日总借书
- 均值 方差 最大 最小
- ☞统计各种类书之和
- '''
- data2=np.zeros(shape=(len(data),6,31)).tolist();#统计每个学期每个人 某月的第某天借了几本书
-
- BookInfo=pickle.load(open('BookInfo.pkl','rb'))
- zero43=np.zeros(43,int).tolist()
- i=0
- offset=30 #书类别偏移
- while i<len(data):
- data[i]+=zero43
- i=i+1
- line=file_borrow.readline()
- line=file_borrow.readline()
-
- while line:
- (seme,sid,name,date,ent)=line.split('\t')
- index=(int(sid)-1)*3+int(seme)-1
- month=int(date[:2])
- day=int(date[2:])
- if int(seme)!=2:
- data2[index][(month-9)%12][day-1]+=1;
- else:
- data2[index][month-2][day-1]+=1;
- if name not in BookInfo.keys():
- data[index][42+offset-1]+=1
- else:
- i=0
- while i<len(BookClass)-1:
- if BookClass[i]==BookInfo[name]:
- break;
- i=i+1
- data[index][i+offset-1]+=1
- line=file_borrow.readline()
- i=0
- '''
- 计算月 日 放进 data
- '''
- zeros8=np.zeros(8,int).tolist();
- while i<len(data):
- data[i]+=zeros8
- i=i+1
- i=0
- while i<len(data):
- if i%3==1:
- n=n_2
- else:
- n=n_1
- num=sum(data[i][offset-1:])#某个人某学期总借书量
- mmean=num/n;
- dmean=num/(n*31);
- m=np.zeros(n,int).tolist();
- d=np.zeros(n*31,int).tolist();
- j=0#第j个月
- l=0#该学期第l天
- while j<n:
- m[j]=int(sum(data2[i][j]))
- k=0#第j月中的k天
- while k<31:
- d[l]=int(data2[i][j][k])
- l=l+1
- k=k+1
- j=j+1
- mmax=max(m);
- dmax=max(d);
- mmin=min(m);
- dmin=min(d);
- mvar=np.var(m);
- dvar=np.var(d);
- data[i][72:]=mmean,mvar,mmax,mmin,dmean,dvar,dmax,dmin;
- i=i+1
-
- # 整理data
- train_predata_x = []
- train_y = []
- for i in range(538):
- tmp = [data[i * 3][2], data[i * 3 + 1][2]] + [data[i * 3][1]] + data[i * 3][3:] + data[i * 3 + 1][3:] + \
- data[i * 3 + 2][3:]
-
- train_predata_x.append(tmp)
- train_y.append(data[i * 3 + 2][2])
- # =============================================================================
- # if item[0] == 3:
- # train_y.append(item[2])
- # if item[1] == pre_stu_id:
- # stu_info.extend(item[2:])
- # else:
- # data_zhengli.append(stu_info)
- # stu_info = item[1:]
- # pre_stu_id = item[1]
- # =============================================================================
-
-
-
- ''' 学期、学号、排名、门禁、书籍信息 '''
- #pickle.dump(data, open('data_pre.pkl', 'wb'))
- #pickle.dump(train_predata_x, open('train_predata_x.pkl', 'wb'))
-
- return train_predata_x, train_y
-
-
-
-
结果:
改进前(没有使用月平均最大最小方差等信息)


优化后:(317维)


