
- 1照片动起来的软件哪个好用?照片秒变动态大片
- 2医疗AI产业链如何颠覆传统?AI大模型携手医疗巨头,打造未来医疗生态圈!_联邦学习 医疗问诊模型
- 3skewx 字体模糊_1+x证书Web前端开发初级理论考试样题2019
- 4ssl证书获取与tomcat和nginx设置https_nginx 映射tomcat ssl部署
- 5多lib架构android,2020-08-19 RN / Android多Lib资源依赖合并方案
- 6姿态估计openpose算法笔记_heatmaps openpose
- 7深入研究simulink建模与仿真之小数转换为整数的舍入模式(圆整模式、取整模式)_simulink取整
- 8云开发npm安装wx-server-sdk没有创建一个package-lock.json_npm 全局安装没有package-lock.json
- 9mac pro M1(ARM)安装:window虚拟机(三)_m1安装windows虚拟机
- 10ORACLE更新序列最大值为表的最大值_oracle修改序列的最大值sql语句
AIGC从入门到入坑01(初学者适用版)_aigc百问百答适合新手入门
赞
踩
AIGC从入门到入坑系列文章
前言
Today,人工智能技术快速发展和广泛应用已经引起大众的兴趣和关注了。特别是作为人工智能重要分支的深度学习,展现出独有的统治力,引领了一场科技革命。作为一名刚毕业的本科生,本身对人工智能感兴趣的我也选择加入这场浪潮中,开坑系列博客,同时作为自己的学习笔记,希望自己能吃透AIGC和AI大模型,探寻一条到AGI的朝圣之路。
首先说明一下AIGC、AI大模型和AGI三个名词的解释,正所谓知其然,才知其所以然。
- AIGC:全名“AI Generated Content”,称为“生成式AI”。由AI自动创作生成的内容,例如AI文本续写,文字转图像的AI图、AI数字化主持人等,都属于AIGC的范畴。
- AI大模型:全名“AI Large Models”,是指具有大量参数和复杂结构的人工智能模型,AI大模型训练需要巨大的计算资源和复杂的分布式系统支持。
- AGI:全名"Artificial General Intelligence",AGI 指的是通用人工智能,也称为强人工智能。AGI旨在实现像人类一样的通用智能,能够在各种不同领域进行学习和推理,并具备类似人类的认知能力。
让我们先吃透AIGC吧~
以下是本篇文章正文内容
学习路径
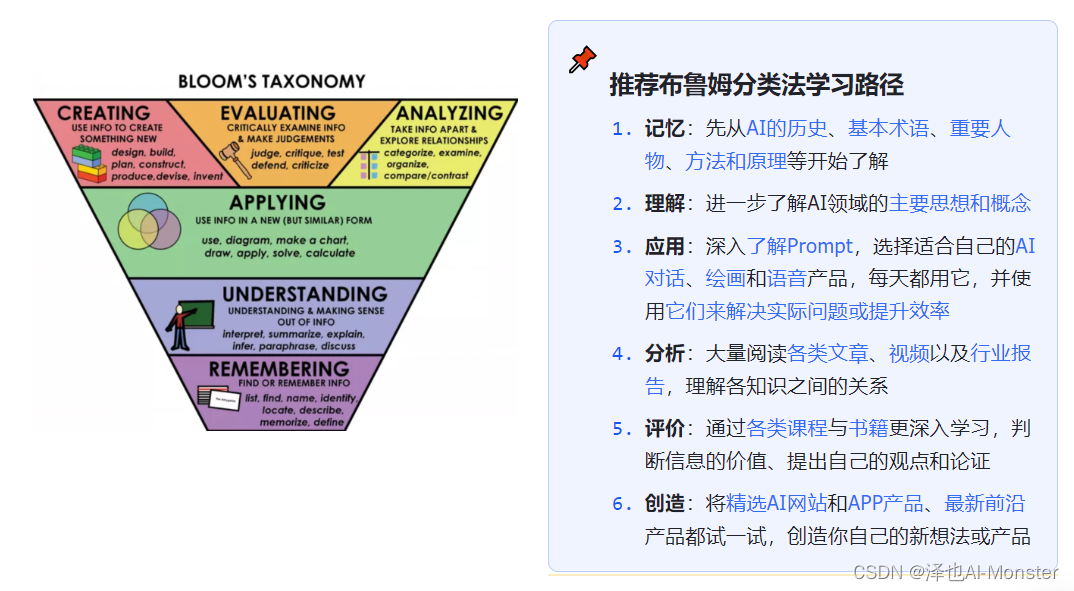
AI时间线
人工智能简史
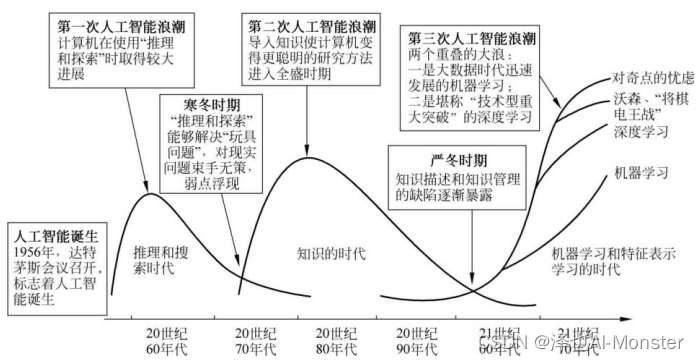
提到计算机,人工智能就不得不提到计算机科学之父、人工智能之父----Alan Mathison Turing艾伦·麦席森·图灵,他是计算机逻辑的奠基者,提出了“图灵机”和“图灵测试”等重要概念。为纪念他在计算机领域的卓越贡献,美国计算机协会于1966年设立图灵奖,此奖项被誉为计算机科学界的诺贝尔奖。
1950年图灵提出了图灵测试,他主张用这个测试来判断计算机是否具有“智能”。所谓图灵测试就是隔墙相问,不知道与你对话的是人还是机器。
推荐好文:人工智能风云录之图灵开天香农辟地

1956年的夏天,在美国达特茅斯Dartmouth College 的一次会议上, AI 被定义为计算机科学的一个研究领域, Marvin Minsky (明斯基) ,John McCarthy (麦卡锡) ,Claude Shannon (香农) ,还有Nathaniel Rochester (罗切斯特)组织了这次会议,他们后来被称为AI的奠基人。

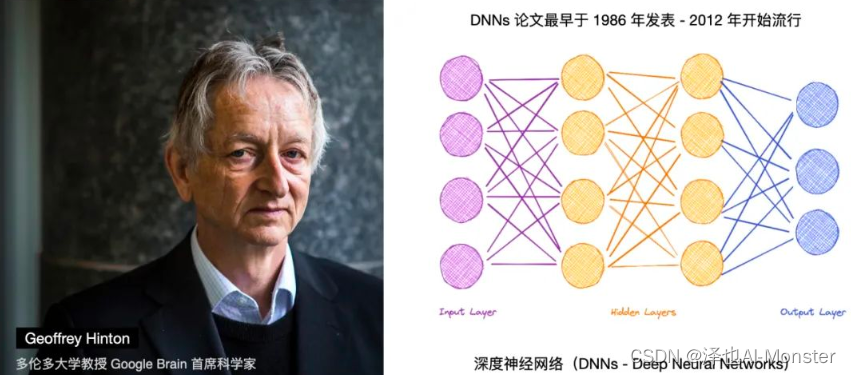
2012年,深度学习兴起,深度学习(Deep Learning)是机器学习(Machine Learning)的子集,它使用多层神经网络和反向传播(Backpropagation)技术来训练神经网络。该领域是几乎是由Geoffrey Hinton开创的,早在1986年, Hinton与他的同事一起发表了关于深度神经网络(DNNs-Deep Neural Networks)的开创性论文,这篇文章引入了反向传播的概念,这是一种调整权重的算法。
2016年:DeepMind(14年被谷歌5.25亿美元收购)的AlphaGo在2016年战胜了围棋世界冠军李世石。这是一个历史性的时刻,它标志着人工智能在围棋这个历史悠久且复杂度极高的游戏中超越了人类,对人类对于机器智能和未来可能性的理解产生了深远影响。

2022年:OpenAI发布了ChatGPT语言模型,这个模型基于GPT-3框架,其能力在于生成和理解自然语言,甚至能与人类进行深度交谈。ChatGPT的问世是人工智能在自然语言处理领域的一大里程碑,它开启了人工,智能的新纪元。通过深度学习和大规模数据训练, ChatGPT能理解复杂的人类语言,并生成具有连贯性和创造性的回应。
推荐好文:ChatGPT 中,G、P、T 分别是什么意思?

AI绘画简史
2014年:对抗生成网络GAN诞生,AI学术界提出了一个非常重要的深度学习模型,这就是大名鼎鼎的对抗生成网络GAN(Generative Adversarial Network, GAN)
推荐好文:生成对抗式网络GAN(一) —— 基于传统数学和能量的角度

2015年11月: 《Deep Unsupervised Learning usingNonequilibrium Thermodynamics》论文发表扩散模型的开山之作,奠定了扩散模型的理论基础和基本框架
进阶好文:什么是扩散模型?
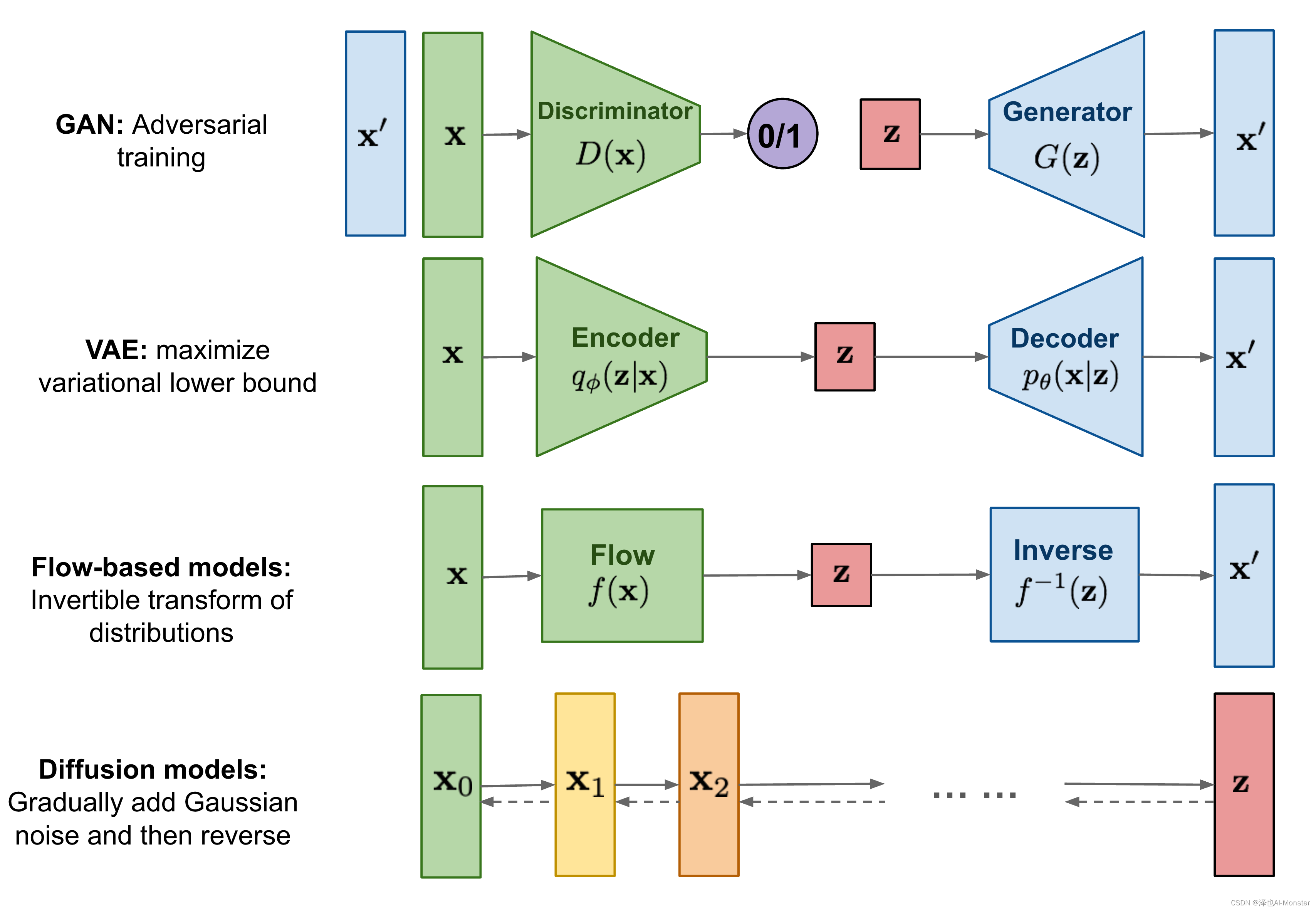
2020年6月:如今生成扩散模型的大火,始于2020年加州伯克利大学提出了DDPM (Denoising Diffusion Probabilistic Model)模型,虽然也用了“扩散模型”这个名字,但事实上除了采样过程的形式有一定的相似之外,DDPM与传统基于朗之万方程采样的扩散模型可以说完全不一样,这完全是一个新的起点、新的篇章。
2021年: OpenAI开源了新的深度学习模型CLIP (Contrastive Language-Image Pre-Training),当时最先进的图像分类人工智能。CLIP训练AI同时做了两个事情,一个是自然语言理解,一个是计算机视觉分析,是不是有了多模态的味道了哈哈哈。它被设计成一个有特定用途的能力强大的工具,那就是做通用的图像分类, CLIP可以决定图像和文字提示的对应程度,比如把猫的图像和猫这个词完全匹配起来。

2021年6月:微软发布LoRA论文(Low-Rank Adaptation of LargeLanguage Models),直译为大语言模型的低阶适应,这是微软的研究人员为了解决大语言模型微调而开发的一项技术。比如,GPT-3有1750亿参数,为了让它能干特定领域的活儿,需要做微调,但是如果直接对GPT-3做微调,成本太高太麻烦了。LoRA的做法是,冻结预训练好的模型权重参数,然后在每个Transformer 块里注入可训练的层,由于不需要对模型的权重参数重新计算梯度,所以,大大减少了需要训练的计算量。有能力还是建议看看这篇论文,以后学大模型也需要。

2022年7月:MidJourney V3上线,Midjourney自发布以来迭代速度非常快。2022年3月V1 发布时仍参考了很多的开源模型;4月、7月和11月分别发布了V2、V3和V4,迭代出了自己的模型优势。当前最新的已经是V6了,总之,每次迭代都是产品功能的飞跃。它可以说是AIGC现象级应用,一年实现1000万用户和1亿美元营收。

2022年8月: Stable Diffusion上线,并开源Stable Diffusion,以开源底层代码的形式在HuggingFace/Github 公开发布。“将AIGC交到数十亿人手中,实现技术民主化",用户可以在其代码的基础上运行或修改,制作自己的应用程序,向终端用户提供服务。作为稀缺的开源模型,同时有着良好的性能,公测后就受到了广泛的关注和好评,积累了大量用户。

2023年6月: Drag Diffusion论文发布。在此之前,精确和可控的图像编辑是一项具有挑战性的任务,已经引起了极大的关注。DragGAN实现了一个基于点的交互式图像编辑框架,并以像素级的精度实现了令人印象深刻的编辑结果。然而,由于该方法是基于生成对抗网络(GAN) ,其通用性受到预先训练好的GAN模型能力的上限限制。在Drag Diffusion这项工作中,将编辑框架扩展到扩散模型。通过利用大规模预训练的扩散模型,我们大大改善了基于点的交互式编辑在现实世界场景中的适用性。虽然大多数现有的基于扩散的图像编辑方法是在文本嵌入的基础上工作的,但Drag Diffusion优化了扩散潜势,以实现精确的空间控制。

AI名词解释
我就主观的精选一些AI前沿的英文名词,便于自己学习理解。
AI(人工智能):Artificial Intelligence,它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是新一轮科技革命和产业变革的重要驱动力量。
Agent(智能体) :等同于一个设置了一些目标或任务,可以迭代运行的大型语言模型。这与大型语言模型(LLM)在像ChatGPT这样的工具中“通常”的使用方式不同。在ChatGPT中,你提出一个问题并获得一个答案作为回应。而Agent拥有复杂的工作流程,模型本质上可以自我对话,而无需人类驱动每一部分的交互。
Alignment(对齐):人工智能对齐是指引导人工智能系统的行为,使其符合设计者的利益和预期目标。一个已对齐的人工智能的行为会向着预期方向发展;而未对齐的人工智能的行为虽然也具备特定目标,但此目标并非设计者所预期。
Attention(注意力):注意力机制是上世纪九十年代,一些科学家在研究人类视觉时,发现的一种信号处理机制。人工智能领域的从业者把这种机制引入到一些模型里,并取得了成功。在神经网络的上下文中,注意力机制有助于模型在生成输出时专注于输入的相关部分,用来自动学习和计算输入数据对输出数据的贡献大小。
COT(思维链提示):Chain-of-thought是一种允许大型语言模型(LLM)在给出最终答案之前通过一系列中间步骤解决问题的技术。思路链提示通过模仿思路的推理步骤诱导模型回答多步骤问题,从而提高推理能力。它允许大型语言模型克服一些需要逻辑思维和多个步骤来解决的推理任务的困难,例如算术或常识推理问题。
Double Descent(双降):机器学习中的一种现象,其中模型性能随着复杂性的增加而提高,然后变差,然后再次提高。就是说随着模型参数变多,Test Error是先下降,再上升,然后第二次下降。
深度学习中,模型大了好还是小了好呢? - Summer Clover的回答
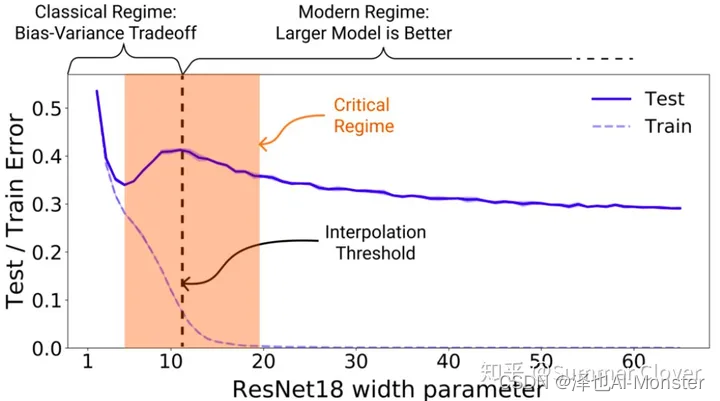
Embedding(嵌入):通俗解释就是"猜词"。比如一个游戏中,你的目标是描述一个词,而你的朋友们要根据你的描述猜出这个词。你不能直接说出这个词,而是要用其他相关的词来描述它。例如,你可以用"外绿内红"、“又大又甜”、“夏天"来描述,让他们猜“西瓜”。这种将一个词转化为其他相关词的过程,就像计算机科学中的"Embedding”,这是一种将对象(如词语、用户或商品)映射到数值向量的技术。这些向量捕捉了对象之间的相似性和关系,就像你在"猜词"游戏中使用相关词描述一个词一样。Embedding的核心属性是把高维的,可能是非结构化的数据,转化为低维的,结构化的向量。这样做的目的是让机器可以理解和处理这些数据,从而进行有效的学习和预测。
Emergence(涌现):这是一种现象,当孤立的每个能力被以某种方式突然组织起来的时候,却爆发出很强大的能力。换句话说就是,许多小实体相互作用后产生了大实体, 而这个大实体展现了组成它的小实体所不具有的特性。涌现在整合层次和复杂系统理论中起着核心作用。例如,生物学中的生命现象是化学的一个涌现,量变引起质变。
Fine-Tuning(微调):微调是迁移学习的一种常用技术。目标模型复制了源模型上除掉了输出层外的所有模型设计及其参数,并基于目标数据集微调这些参数。微调在自然语言处理(NLP)中很常见,尤其是在语言建模领域。像OpenAI的GPT这样的大型语言模型可以在下游NLP任务上进行微调,以产生比预训练模型通常可以达到的更好的结果。
Generalization ability(泛化能力):在机器学习中,一个模型的泛化能力是指其在新的、未见过的数据上的表现能力。
Hallucinate(幻觉):在人工智能的背景下,幻觉是指模型生成的内容不是基于实际数据或与现实明显不同的现象。
Instruction Tuning(指令调优):机器学习中的一种技术,其中模型根据数据集中给出的特定指令进行微调。
Knowledge Distillation(数据蒸馏):数据蒸馏旨在将给定的一个原始的大数据集浓缩并生成一个小型数据集,使得在这一小数据集上训练出的模型,和在原数据集上训练得到的模型表现相似.数据蒸馏技术在深度学习领域中被广泛应用,特别是在模型压缩和模型部署方面。它可以帮助将复杂的模型转化为更轻量级的模型,并能够促进模型的迁移学习和模型集成,提高模型的鲁棒性和泛化能力。
LLM大语言模型(Large Language Model):大语言模型是由具有许多参数(通常为数十亿或更多权重)的神经网络组成的语言模型,使用自监督学习或半监督学习对大量未标记文本进行训练。
Multimodal(模态):在人工智能中,这是指可以理解和生成多种类型数据(如文本和图像)信息的模型。
Parameters(参数):在机器学习中,参数是模型用于进行预测的内部变量。它们是在训练过程中从训练数据中学习的。例如,在神经网络中,权重和偏差是参数。
Prompt Engineering(提示工程):它是人工智能中的一个概念,特别是自然语言处理(NLP)。 在提示工程中,任务的描述会被嵌入到输入中。提示工程的典型工作方式是将一个或多个任务转换为基于提示的数据集,并通过所谓的"基于提示的学习(prompt-based learning) "来训练语言模型。
RLHF(基于人类反馈的强化学习):Reinforcement Learning from Human Feedback在机器学习中,人类反馈强化学习(RLHF)或人类偏好强化学习 是一种直接根据人类反馈训练"奖励模型"并将该模型用作奖励函数以使用强化学习优化代理策略的技术。
Reinforcement Learning(强化学习):它是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。强化学习是除了监督学习和非监督学习之外的第三种基本的机器学习方法。
Vector Database(向量数据库):向量数据库(Om-iBASE)是基于智能算法提取需存储内容的特征,转变成具有大小定义、特征描述、空间位置的多维数值进行向量化存储的数据库,使内容不仅可被存储,同时可被智能检索与分析。
小白从0-1必看5篇资料
01.人工智能时代已经开始 | 盖茨笔记
预计用时7分钟
这篇是去年盖茨对于OpenAI所做给予了很高的评价,大佬们都纷纷下场了,我们庶民百姓也要跟上脚步啊,未来不是AI淘汰我们,而是会使用AI的人来淘汰我们。

02.AI狂飙的时代,人还有价值吗?
预计用时1个小时
个人觉得很有必要读,同时可以做笔记,因为嘉宾很有水平,认知很高,并且对于主持人人的问题都很好的回答了。主要包括:ChatGPT的革命性,就业市场的冲击方式,人的存在危机,人的价值体系转移,价值体系转移的进程,普通人应该怎么办。


03.【渐构】万字科普GPT4为何会颠覆现有工作流;为何你要关注微软Copilot、文心一言等大模型
预计用时50分钟
介绍了ChatGBT的底层原理、训练方式、未来影响和应对方法,up讲的通俗易懂,而且逻辑很清晰,剖析的很perfect,同时还强调了其不是搜索引擎和聊天机器人的区别,以及其对社会的影响和未来的竞争力。

04. 独家 | 解析Tansformer模型—理解GPT-3, BERT和T5背后的模型(附链接)
预计用时10分钟

05.OpenAI:GPT最佳实践(大白话编译解读版)
预计用时40分钟
这是一个偏向使用实践性的文章,希望大家在使用过相关产品(会科学的就用ChatGPT,Claude,不会的用文心,智谱,讯飞星火这种都可)才学习,这样效果更佳,感触更深。OpenAI 发布了《GPT 最佳实践》官方文档,介绍与 ChatGPT 交互的技巧和用例。但文档以通俗易懂的英语写成,但缺乏中文版本,因此未来力场团队进行了重新编译并补充了更容易理解的用例。六个核心提示策略包括:清晰指令、添加细节、角色扮演、使用分隔符号、提供步骤和举例说明。

初学者进阶必读8篇资料
OpenAI大牛Andrej Karpathy(OpenAI创始团队成员,原特斯拉AI部门负责人)刚在BUILD2023大会上做了这个主题演讲 “State of GPT”,详细讲述了如何从一个基础模型训练成ChatGPT的过程。通俗易懂,内容精彩至极!
原地址:https://build.microsoft.com/en-US/sessions/db3f4859-cd30-4445-a0cd-553c3304f8e2
B站upWeb3天空之城精翻:https://www.bilibili.com/video/BV1ts4y1T7UH/
总结
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。

