
- 1【算法/序列】等差数列&&子序列&&算术序列&&最长对称子串
- 2中霖教育怎么样?二建继续教育几年一次?
- 3【springboot&neo4j】版本差异对比_neo4j-ogm-core版本
- 4生成模型最新进展丨2024智源大会精彩回顾
- 5基于微信小程序的校园服务平台+ssm后端源码和论文_小程序后端服务平台
- 6python接入文心一言api实现ai聊天_qianfan.chatcompletion
- 72024华中杯C题光纤传感器平面曲线重建原创论文分享_基于光纤传感器的平面曲线重建算法建模模型假设
- 8酒泉职业技术学院毕业设计课题目录参考
- 92024年,软件测试未来可期?_2024年软件测试就业形势
- 10【NLP】第4章 从头开始预训练 RoBERTa 模型_roberta模型
健康医疗大模型,开源了!_扁鹊大模型
赞
踩
扁鹊(BianQue)

基于主动健康的主动性、预防性、精确性、个性化、共建共享、自律性六大特征,华南理工大学未来技术学院-广东省数字孪生人重点实验室开源了中文领域生活空间主动健康大模型基座ProactiveHealthGPT。
我们期望,生活空间主动健康大模型基座ProactiveHealthGPT 可以帮助学术界加速大模型在慢性病、心理咨询等主动健康领域的研究与应用。本项目为 生活空间健康大模型扁鹊(BianQue) 。
扁鹊健康大数据BianQueCorpus
我们经过调研发现,在健康领域,用户通常不会在一轮交互当中清晰地描述自己的问题,而当前常见的开源医疗问答模型(例如:ChatDoctor、本草(HuaTuo,原名华驼 )、DoctorGLM、MedicalGPT-zh)侧重于解决单轮用户描述的问题,而忽略了“用户描述可能存在不足”的情况。哪怕是当前大火的ChatGPT也会存在类似的问题:如果用户不强制通过文本描述让ChatGPT采用一问一答的形式,ChatGPT也偏向于针对用户的描述,迅速给出它认为合适的建议和方案。然而,实际的医生与用户交谈往往会存在“医生根据用户当前的描述进行持续多轮的询问”。并且医生在最后根据用户提供的信息综合给出建议,如下图所示。我们把医生不断问询的过程定义为 询问链(CoQ, Chain of Questioning) ,当模型处于询问链阶段,其下一个问题通常由对话上下文历史决定。

我们结合当前开源的中文医疗问答数据集(MedDialog-CN、IMCS-V2、CHIP-MDCFNPC、MedDG、cMedQA2、Chinese-medical-dialogue-data),分析其中的单轮/多轮特性以及医生问询特性,结合实验室长期自建的生活空间健康对话大数据,构建了千万级别规模的扁鹊健康大数据BianQueCorpus。对话数据通过“病人:xxx\n医生:xxx\n病人:xxx\n医生:”的形式统一为一种指令格式,如下图所示。

input: "病人:六岁宝宝拉大便都是一个礼拜或者10天才一次正常吗,要去医院检查什么项目\\n医生:您好\\n病人:六岁宝宝拉大便都是一个礼拜或者10天才一次正常吗,要去医院检查什么项目\\n医生:宝宝之前大便什么样呢?多久一次呢\\n病人:一般都是一个礼拜,最近这几个月都是10多天\\n医生:大便干吗?\\n病人:每次10多天拉的很多\\n医生:"
target: "成形还是不成形呢?孩子吃饭怎么样呢?"
- 1
- 2
训练数据当中混合了大量target文本为医生问询的内容而非直接的建议,这将有助于提升AI模型的问询能力。
使用方法
- 克隆本项目
cd ~
git clone https://github.com/scutcyr/BianQue.git
- 1
- 2
- 安装依赖 需要注意的是torch的版本需要根据你的服务器实际的cuda版本选择,详情参考pytorch安装指南
cd BianQue
conda env create \-n proactivehealthgpt\_py38 \--file proactivehealthgpt\_py38.yml
conda activate proactivehealthgpt\_py38
pip install cpm\_kernels
pip install torch\==1.13.1+cu116 torchvision\==0.14.1+cu116 torchaudio\==0.13.1 \--extra-index-url https://download.pytorch.org/whl/cu116
- 1
- 2
- 3
- 4
- 5
- 6
- 【补充】Windows下的用户推荐参考如下流程配置环境
cd BianQue
conda create \-n proactivehealthgpt\_py38 python\=3.8
conda activate proactivehealthgpt\_py38
pip install torch\==1.13.1+cu116 torchvision\==0.14.1+cu116 torchaudio\==0.13.1 \--extra-index-url https://download.pytorch.org/whl/cu116
pip install \-r requirements.txt
pip install rouge\_chinese nltk jieba datasets
\# 以下安装为了运行demo
pip install streamlit
pip install streamlit\_chat
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
【补充】Windows下配置CUDA-11.6:下载并且安装CUDA-11.6、下载cudnn-8.4.0,解压并且复制其中的文件到CUDA-11.6对应的路径,参考:win11下利用conda进行pytorch安装-cuda11.6-泛用安装思路
-
在Python当中调用BianQue-2.0模型:
import torch from transformers import AutoModel, AutoTokenizer \# GPU设置 device = torch.device("cuda" if torch.cuda.is\_available() else "cpu") \# 加载模型与tokenizer model\_name\_or\_path = 'scutcyr/BianQue-2' model = AutoModel.from\_pretrained(model\_name\_or\_path, trust\_remote\_code=True).half() model.to(device) tokenizer = AutoTokenizer.from\_pretrained(model\_name\_or\_path, trust\_remote\_code=True) \# 单轮对话调用模型的chat函数 user\_input = "我的宝宝发烧了,怎么办?" input\_text = "病人:" + user\_input + "\\n医生:" response, history = model.chat(tokenizer, query=input\_text, history=None, max\_length=2048, num\_beams=1, do\_sample=True, top\_p=0.75, temperature=0.95, logits\_processor=None) \# 多轮对话调用模型的chat函数 \# 注意:本项目使用"\\n病人:"和"\\n医生:"划分不同轮次的对话历史 \# 注意:user\_history比bot\_history的长度多1 user\_history = \['你好', '我最近失眠了'\] bot\_history = \['我是利用人工智能技术,结合大数据训练得到的智能医疗问答模型扁鹊,你可以向我提问。'\] \# 拼接对话历史 context = "\\n".join(\[f"病人:{user\_history\[i\]}\\n医生:{bot\_history\[i\]}" for i in range(len(bot\_history))\]) input\_text = context + "\\n病人:" + user\_history\[-1\] + "\\n医生:" response, history = model.chat(tokenizer, query=input\_text, history=None, max\_length=2048, num\_beams=1, do\_sample=True, top\_p=0.75, temperature=0.95, logits\_processor=None)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 启动服务
本项目提供了bianque_v2_app.py作为BianQue-2.0模型的使用示例,通过以下命令即可开启服务,然后,通过http://<your_ip>:9005访问。
streamlit run bianque\_v2\_app.py \--server.port 9005
- 1
特别地,在bianque_v2_app.py当中, 可以修改以下代码更换指定的显卡:
os.environ\['CUDA\_VISIBLE\_DEVICES'\] = '1'
- 1
对于Windows单显卡用户,需要修改为:os.environ['CUDA_VISIBLE_DEVICES'] = '0',否则会报错!
可以通过更改以下代码指定模型路径为本地路径:
model\_name\_or\_path = "scutcyr/BianQue-2"
- 1
我们还提供了bianque_v1_app.py作为BianQue-1.0模型的使用示例,以及bianque_v1_v2_app.py作为BianQue-1.0模型和BianQue-2.0模型的联合使用示例。
扁鹊-2.0
基于扁鹊健康大数据BianQueCorpus,我们选择了 ChatGLM-6B 作为初始化模型,经过全量参数的指令微调训练得到了新一代BianQue【BianQue-2.0】。与扁鹊-1.0模型不同的是,扁鹊-2.0扩充了药品说明书指令、医学百科知识指令以及ChatGPT蒸馏指令等数据,强化了模型的建议与知识查询能力。以下为两个测试样例。
- 样例1:宝宝特别喜欢打嗝,是什么原因啊,该怎么预防啊

- 样例2:我外婆近来身体越来越差了,带她去医院检查,医生说她得了肾静脉血栓,我们全家都很担心,医生开了很多注射用低分子量肝素钙,我想问它的药理毒理?

扁鹊-2.0与扁鹊-1.0联合使用,兼顾多轮问询与出色的健康建议能力
通过以下命令实现联合使用扁鹊-2.0与扁鹊-1.0构建主动健康服务:
streamlit run bianque\_v1\_v2\_app.py \--server.port 9005
- 1
以下为应用例子:前面若干轮为经过扁鹊-1.0模型进行问询的过程,最后一轮回复为经过扁鹊-2.0模型的回答。
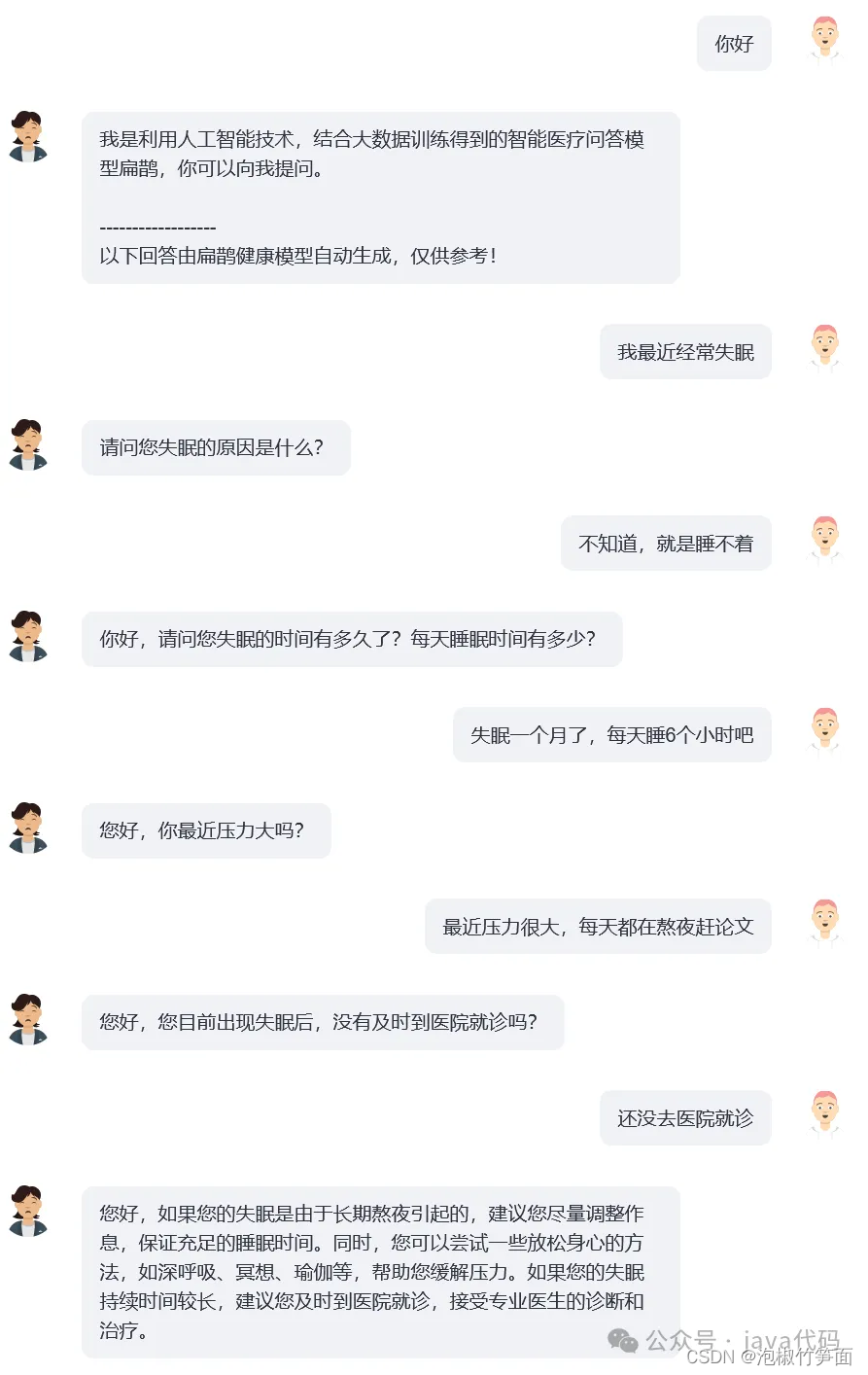
扁鹊-1.0
扁鹊-1.0(BianQue-1.0) 是一个经过指令与多轮问询对话联合微调的医疗对话大模型。我们经过调研发现,在医疗领域,往往医生需要通过多轮问询才能进行决策,这并不是单纯的“指令-回复”模式。用户在咨询医生时,往往不会在最初就把完整的情况告知医生,因此医生需要不断进行询问,最后才能进行诊断并给出合理的建议。基于此,我们构建了 扁鹊-1.0(BianQue-1.0) ,拟在 强化AI系统的问询能力 ,从而达到模拟医生问诊的过程。我们把这种能力定义为“望闻问切”当中的“问”。综合考虑当前中文语言模型架构、参数量以及所需要的算力,我们采用了ClueAI/ChatYuan-large-v2作为基准模型,在8张 NVIDIA RTX 4090显卡上微调了1个epoch得到扁鹊-1.0(BianQue-1.0),用于训练的中文医疗问答指令与多轮问询对话混合数据集包含了超过900万条样本,这花费了大约16天的时间完成一个epoch的训练。我们将计划围绕扁鹊模型的“望闻问切”能力,结合医学专家知识、多模态技术、多生理信号计算等,进行多个版本的模型迭代研究。
模型“问”能力示例
“望闻问切”四诊法由扁鹊发明。“四诊法”(望、闻、问、切),是中医诊病的基本方法。其中,“问”的能力可以被建模到语言模型当中。我们把AI模型的“问”能力定义为:
“问”能力:AI模型能够根据病人输入的信息,结合医学知识来进行恰当的问询,并且结合进一步的问询得到的病人的信息,给出“合适的诊断或建议”。“问”的过程通常是一个多轮对话过程。
以下是2个简单的例子:
-
例子1
用户:我最近感觉全身疲惫
扁鹊-1.0:是劳累了,还是熬夜了?
用户:这周都在熬夜赶论文
扁鹊-1.0:嗯,熬夜容易引起各种不适,如头晕、乏力、失眠、多梦等,多休息,可以口服谷维素、维生素B1和安神补脑液,避免熬夜。 -
例子2
用户:我最近经常失眠
扁鹊-1.0:失眠多久了?
用户:两周了
扁鹊-1.0:睡眠怎么样?
用户:上床几小时才睡得着
扁鹊-1.0:可以口服一些药物
用户:有具体推荐吗
扁鹊-1.0:需要先检查一下
用户:那我需要做什么检查?
扁鹊-1.0:心电图
使用方法
直接使用扁鹊-1.0模型
import os from transformers import T5Tokenizer, T5ForConditionalGeneration, AutoTokenizer import torch device = torch.device("cuda" if torch.cuda.is\_available() else "cpu") tokenizer = T5Tokenizer.from\_pretrained("scutcyr/BianQue-1.0") model = T5ForConditionalGeneration.from\_pretrained("scutcyr/BianQue-1.0") model = model.to(device) def preprocess(text): text = text.replace("\\n", "\\\\n").replace("\\t", "\\\\t") return text def postprocess(text): return text.replace("\\\\n", "\\n").replace("\\\\t", "\\t") def answer(user\_history, bot\_history, sample=True, top\_p=1, temperature=0.7): '''sample:是否抽样。生成任务,可以设置为True; top\_p:0-1之间,生成的内容越多样 max\_new\_tokens=512 lost...''' if len(bot\_history)>0: context = "\\n".join(\[f"病人:{user\_history\[i\]}\\n医生:{bot\_history\[i\]}" for i in range(len(bot\_history))\]) input\_text = context + "\\n病人:" + user\_history\[-1\] + "\\n医生:" else: input\_text = "病人:" + user\_history\[-1\] + "\\n医生:" return "我是利用人工智能技术,结合大数据训练得到的智能医疗问答模型扁鹊,你可以向我提问。" input\_text = preprocess(input\_text) print(input\_text) encoding = tokenizer(text=input\_text, truncation=True, padding=True, max\_length=768, return\_tensors="pt").to(device) if not sample: out = model.generate(\*\*encoding, return\_dict\_in\_generate=True, output\_scores=False, max\_new\_tokens=512, num\_beams=1, length\_penalty=0.6) else: out = model.generate(\*\*encoding, return\_dict\_in\_generate=True, output\_scores=False, max\_new\_tokens=512, do\_sample=True, top\_p=top\_p, temperature=temperature, no\_repeat\_ngram\_size=3) out\_text = tokenizer.batch\_decode(out\["sequences"\], skip\_special\_tokens=True) print('医生: '+postprocess(out\_text\[0\])) return postprocess(out\_text\[0\]) answer\_text = answer(user\_history=\["你好!", "我最近经常失眠", "两周了", "上床几小时才睡得着"\], bot\_history=\["我是利用人工智能技术,结合大数据训练得到的智能医疗问答模型扁鹊,你可以向我提问。", "失眠多久了?", "睡眠怎么样?"\])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
使用个人数据在扁鹊-1.0模型基础上进一步微调模型
- 环境创建
以下为在RTX 4090显卡,CUDA-11.6驱动配置下的环境配置
conda env create \-n bianque\_py38 \--file py38\_conda\_env.yml
conda activate bianque\_py38
pip install torch\==1.13.1+cu116 torchvision\==0.14.1+cu116 torchaudio\==0.13.1 \--extra-index-url https://download.pytorch.org/whl/cu116
- 1
- 2
- 3
-
数据集构建
参考.data/cMedialog_example.csv格式,构建你的数据集 -
基于扁鹊-1.0模型微调你的模型
修改./scripts/run_train_model_bianque.sh,通过绝对路径指定PREPROCESS_DATA,并且调整其他变量,然后运行:
cd scripts
bash run\_train\_model\_bianque.sh
- 1
- 2
声明
扁鹊-1.0(BianQue-1.0) 当前仅经过1个epoch的训练,尽管模型具备了一定的医疗问询能力,但其仍然存在以下局限:
-
训练数据来源于开源数据集以及互联网,尽管我们采用了严格的数据清洗流程,数据集当中仍然不可避免地存在大量噪声,这会使得部分回复产生错误;
-
医生“问询”是一项复杂的能力,这是非医生群体所不具备的,当前的模型对于模拟“医生问询”过程是通过大量样本学习得到的,因此在问询过程当中,有可能出现一些奇异的提问风格。换一句话来说,当前版本的模型强化了“问”的能力,但是“望”、“闻”、“切”的能力仍待进一步研究!
**扁鹊-2.0(BianQue-2.0)**使用了ChatGLM-6B 模型的权重,需要遵循其MODEL_LICENSE。
源代码下载地址:
https://gitee.com/stjdydayou/BianQue.git
那么,如何学习大模型 AGI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
-END-
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/人工智能uu/article/detail/875057
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

