
- 1c# 进程间同步实现 进程之间通讯的几种方法 _c#与vc6.0进程之间数据传送
- 2web前端顶岗实习总结报告_web前端实习报告
- 3树莓派:基于opencv+Python的颜色形状识别(红色、蓝色的圆形、矩形、三角形)_识别红蓝色的三角形和正方形
- 4springboot+druid+dynamic-datasource+mysql数据库密码加密_dynamicdatasourceproperties.decrypt error
- 5【AI学习】对微调(Fine-tuning)的理解_sft阶段注入知识
- 6Typora+Node.js+PicGo+Gitee 设置图片自动上传_js模拟人工自动上传图片
- 7c++重载运算符使用const的原因_c++重载比较运算符后面为什么要加const
- 8Python开发游戏自动化后台脚本——实例分享_python编写游戏自动化脚本
- 9大模型之路3:趟到了Llama-Factory,大神们请指点_llama factory
- 10Spring Cloud Stream + RabbitMQ 消息消费组与消息分区_springboot rabbitmq分区
生成模型最新进展丨2024智源大会精彩回顾
赞
踩
过去一年,生成模型发展迅速,尤其是视频的生成模型,在图像和语言的建模框架上都出现了许多新的变化。生成式建模是人工智能的基础范式之一,是迈向通用人工智能的重要一环。随着生成式建模方法的快速发展和模型规模的急速增长,以自回归模型、扩散概率模型为代表的生成式人工智能(如GPT系列、Sora、Stable Diffusion等)在文本、图像、视频、跨模态等重要领域取得了一系列突破性进展。
本次智源大会「生成模型」论坛由中国人民大学副教授李崇轩和清华大学副教授陈键飞担任论坛主席,邀请到了中国人民大学卢志武教授,分享视频生成的最新进展;字节跳动GenAl研究员江毅,汇报视觉自回归的框架VAR;微软亚洲研究院视觉计算组研究员古纾旸博士分享对现有生成模型的思考;最后是上海交通大学邓志杰教授分享了如何对大语言模型微调加速推理。
以下是核心内容整理 ↓ (回放链接:https://event.baai.ac.cn/live/797)
视频生成前沿进展

报告嘉宾:卢志武 | 中国人民大学教授
主要内容:视频生成任务困难的原因:视频可以看是多帧的图像生成,生成内容的一致性难以保证,在生成长视频时画面抖动通常变得更为明显;视频生成消耗的资源特别高;可控生成方面,有很多额外的因素需要考虑。视频生成的范式有两种,一种是基于DIT的架构,还有一种是纯SD的架构,这里介绍的工作主要基于DIT的架构。

团队的工作结合扩散模型和transformer技术来实现视频生成。将transformer技术应用于基于扩散的视频生成,提出统一的时空掩码建模机制。模型的一些细节和sora类似,也做了压缩和简化,但transformer模块和sora有两点差异。一是VDT采用的是在时空维度上分别进行注意力机制处理的方法。二是VDT只考虑图像生成视频,没有考虑文本,因为文本数据量需要的数据量更大。实际应用中增加了一些人脸控制方法,保证生成时人脸不要动,在垂域应用-写真视频生成上取得了一些很好的结果。在相同条件下是和pika、runway、pixwerse模型做过对比,可以看到效果是更优化的。

未来的视频生成发展趋势主要有三个方面:第一,视频生成加速方面,可以通过推理加速方法解决;第二个发展趋势就是更长的视频不能只以来模型本身生成,可以考虑增加一些后续处理步骤;第三个趋势是普通团队也能做的方向,视频的可控生成,这个方向消耗的算力没有那么大,很多老师和科研团队都有可能做这个方向。

Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction

报告嘉宾:江 毅 | 字节跳动GenAl研究员
主要内容:语言模型分析遵循自上而下,自左到右的顺序,而视觉感知图像时,对目标的理解是整体到局部的过程。这次报告的内容是如何能够借助计算机视觉的特有性质,同时借鉴LLM的Tokenization,scaling law等优点,提出了针对视觉生成的视觉自回归框架。
借鉴视觉整体到局部生成的思路,框架主要由两个部分组成:一个是image tokenizotion,主要是把图像表示离散化,从而通过最大似然估计去优化;另外包含一个GPT-style的自回归模型来生成高清的图像。具体来说有两个步骤,第一步是有对图像进行多尺度的离散token map,分辨率从小到大;第二步转化成连续的feature map,再统一插值到rk对应最大分辨率,去重建对应的图像。
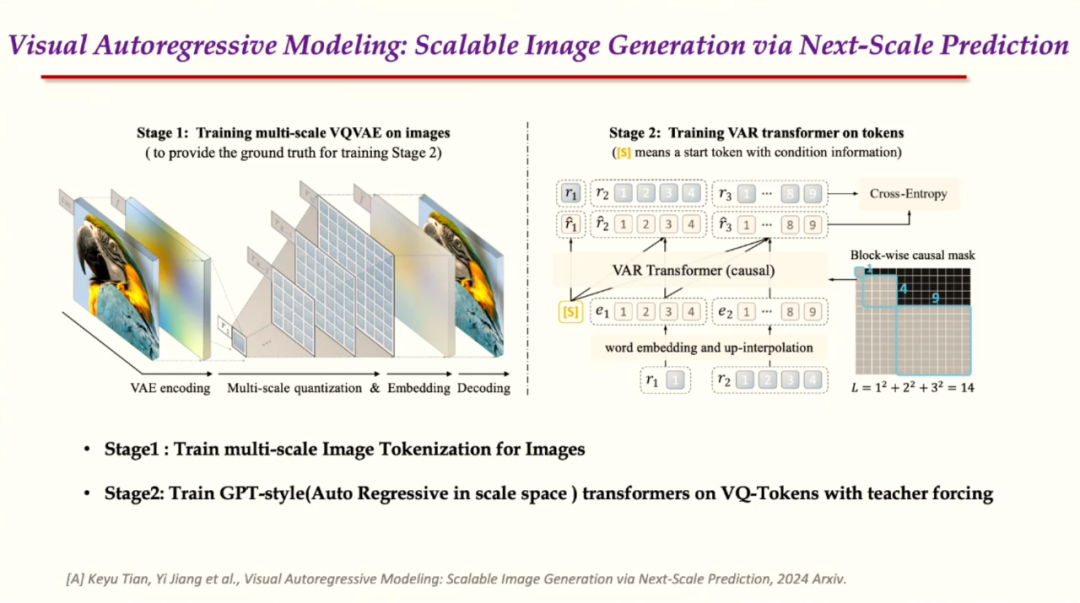
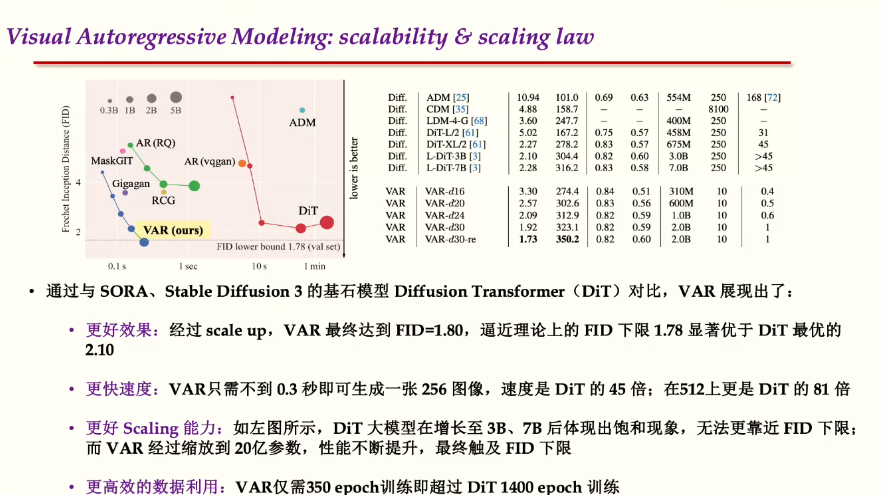
自回归模型的生成,第一步得到1×1的token map,从而并行生成一个2×2的token map。测试阶段得到一些生成图像,与Diffusion transformer(DIT)做对比,VAR表现出了逼近理论上的FID下限1.78,结果显著优于DIT的效果2.1,训练仅需350个轮次。
VAR模型包括300M-2B的Model,表现出了更强的scaling law能力。

通过对VAR模型的scaling law与zero shot generalization的实证验证,VAR具有更好的性能,更合理的生成速度,更完备的scaling law,解决了生成的泛化问题。VAR学习会比Diffusion更加高效。VAR可以直观的解释从小尺度到大尺度,模型更利于融合进LLM。
最后介绍一下未来可能会做的工作,会包括Text—to—image的相关内容。另外,从现在的视觉生成到多模态智能的发展趋势来看,视觉生成模型这一领域,未来多模态模型或者统一的模型走向离散的是必然的趋势。长视频是下一步可能要做的方向,长视频token序列会很长,生成更长的视频更适合通过VAR方式来完成。
视觉生成中的若干问题

报告嘉宾:古纾旸 | 微软亚洲研究院视觉计算组研究员
主要内容:个人认为视觉信号拆解是目前视觉生成领域几乎最重要的问题。
生成模型的一个重要步骤是拟合数据分布。然而数据分布往往非常复杂,难以直接拟合。因此需要将复杂数据分布拟合的任务拆分成多个简单数据分布拟合的任务。

在语言领域,将一个复杂的数据拆分成根据前面的token预测后面的token,拆分出的任务之间是没有冲突的。类比这种处理方式,将图像分成了一个个块,再对条件分布进行拟合,比如DALLE,Parti等,这类拆解方式在不同任务下学习的特征是不一样的,因此共享模型参数会导致冲突。相似的,从图像的深度维度进行拆分也会导致类似的冲突。
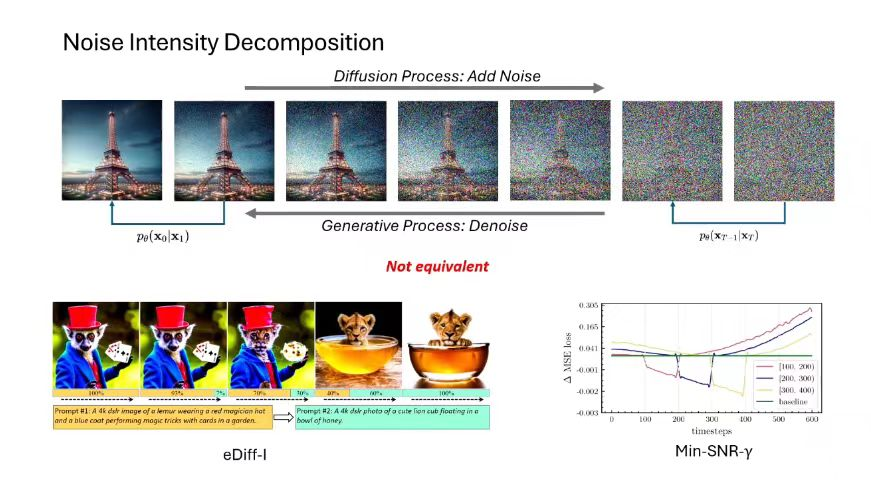
现在最流行的拆分方式是根据噪声强度做信号拆分,比如Diffusion,这种拆分结果也并不保证子任务之间完全不冲突。如果时间步不同或者噪声强度不同,模型学习到的信息是不一样的。此外,还可以让信号拆分方式变成可学习的,代表性工作有VDM和DSB等,然而这类工作在实际中也有各自的问题。
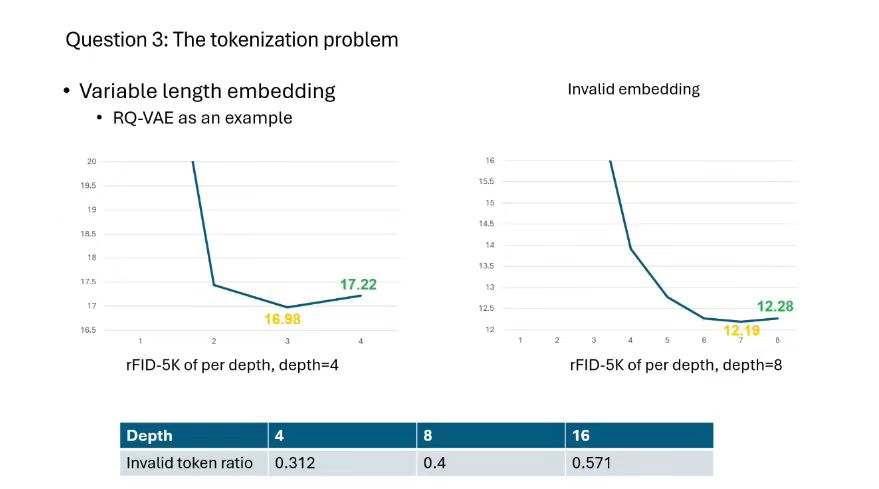
生成模型中的数据生成大部分分成两步来做,第一部分是信号压缩,使数据分布变得简单;第二部分在压缩后的信号上进行建模。如果采用变长的tokenization,随着网络的深度增加,出现的invalid embedding情况概率越来越高。
有关扩散模型是否是最大似然模型的问题,从training,inference 和evaluation的角度来看, Diffusion model 的最大似然均不能得到最好的结果。这是由于其拆分并不具有等价性,不同时间步的难度和重要性不同。这可以引申到一些其它有意思的话题,比如视觉信号的scaling law。
大模型的高效并行推理方法

报告嘉宾:邓志杰 | 上海交通大学清源研究院助理教授
主要内容:大模型的推理低效问题来源于两个方面:其一,随着scaling law的发展,模型本身越来越大;其二,语言模型自回归、扩散模型逐步去噪,都依赖顺序的、漫长的推理过程,其进一步放大模型自身的低效性,导致高部署成本以及比较差的用户体验。
本报告的工作主要分三个方面:其一围绕大语言模型,在算法上设计并行推理机制;其二研究大扩散模型的低步数推理方法;最后从模型架构、缓存优化等角度提供加速策略。

针对语言模型生成越往后越慢,带来高开销的问题,一个典型的技术是使用KV cache,用空间换时间。此外,投机解码可以把解码阶段的计算量降下来,显著提高生成过程的速度。投机解码利用小模型生成信息密度比较低的token,释放大模型的解码压力。
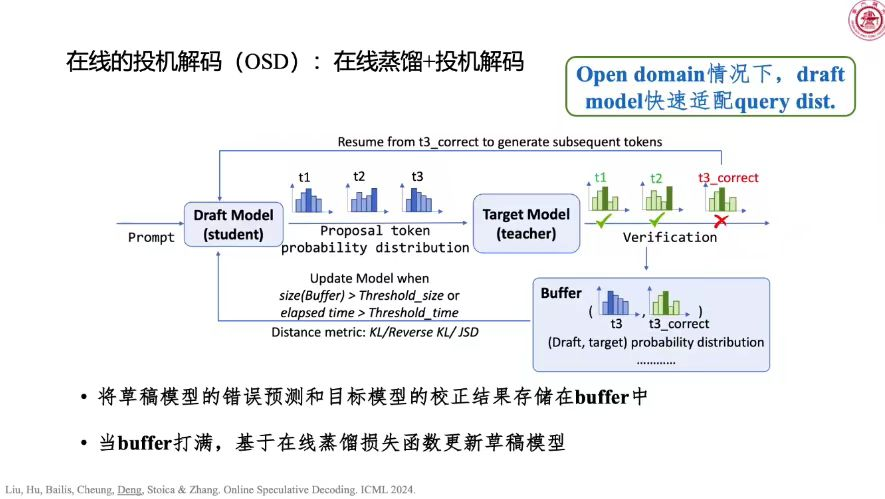
一致性大语言模型(Consistency LLMs)通过蒸馏并行不动点求解过程的轨迹,习得一次往后预测多个token的能力,带来至多3.6倍的推理加速。

利用扩散概率模型等价常微分方程形式,可以设计高效的离散化求解器,典型代表是DPM—solver,效果非常好。从模型蒸馏的角度出发也可以实现低步数推理。可以构建多步隐空间一致性蒸馏方法,对扩散ODE轨迹切段分别处理。得到一个统一的一致性模型,兼容不同采样步数。

提高模型表达能力的一个典型机制是专家混合,其稀疏激活专家,保证模型能力的同时降低计算开销,代表方法是Mixtral—8×7B。深度混合(MoD)将token routing拓展为expert routing,保障负载平衡。在专家混合里加一组空专家(null experts),同时加大稀疏激活数,可以使得不同的token自适应选择不同数目的真专家,增加建模灵活度。
对于未来的一些方向,个人认为在高效推理方面仍可以做很多技术上的研究,比如模型架构,模型的学习和训练方法,以及采样算法等方面的工作。个人认为重要的两个场景是多模态和视频生成。
圆桌论坛

Q1.陈键飞:目前至少存在两种范式,扩散和自回归,后续范式可能会有怎么样的转变,请各位结合自己的领域谈一下看法。
卢志武:个人觉得生成的部分如果只有一个transformer,无法实现统一的多模态大模型,现阶段比较困难,这是我的经验,不是结论。
江毅:个人的看法是在算力相对没有那么多,或者是模型没有那么大的条件下,扩散模型能够快速达到不错的效果。随着算力的增加,我相信VAR路线,包括tokenization是通过视频和图像联合建模,在高维空间表现的更好一些。
邓志杰:语言建模现在是以transformer为主流,学习的机制还是自回归更多。不过,可以关注到如BFNs等工作慢慢地开始做离散数据的扩散建模,链接多个模态。为了解决transformer高复杂度的问题,现在也出现了Memba、RWKV等挑战者,对transformer自身的修补、改进也持续不断。
李崇轩:最早思考这个问题是从纯数学的角度,发现很难有明确结果,之前有很多人说压缩即智能,但是很多生成模型都做最大似然估计,也都可以理解为压缩。因此,我觉得还是要从工程角度思考这个问题。我们也做过一些transformer和Diffusion结合的工作,在文到图的实践效果也不错,但是进一步scale up并没有更理想的结果。当然,我们不只有自回归或者Diffusion模型的变量,还有语言和图像本身模态的变量。
因此,我们最近有一些尝试,除了连续化的diffusion,也做了一些离散化的mask diffusion,现在有一些进展,在GPT-2大小上,结果没有比自回归差太多,这个角度可能还有很多可以研究的空间。但是,在更大的规模上也有可能得到负面的结果,可能发现语言模型上diffusion也不能scaling up,那就是自回归会统一所有模态,但我也不是很确定。
古纾旸:什么范式不重要,怎么做信号拆分很重要。当把语言拆分成一个一个token自回归就适合;当把图像拆分成噪声更小一点的模块,就应该用Diffusion。这个问题不是那么重要的问题,重要的问题是真的想清楚怎么拆分,自然而然会有更合适的范式出现。
陈键飞:个人认为古老师的看法确实是包含了视觉层次化的考虑,所以或许这是一个指引下一步的方向。
Q2. 陈键飞:语言模型在scaling up时,对能力的提升是有刻画的,比如说增加了推理的能力、做数学题的能力。但是对于视觉模型,大模型比小模型强在哪里,如何进一步刻画模型能力的提升,有什么是scaling解决不了的?
古纾旸:scaling law是基于范式存在的,这里只讨论diffusion model。有一些通用标准可以用来衡量语言模型的能力,因此语言模型有scaling law。而针对Diffusion model,关键是解决evaluation metric的问题。
李崇轩:从生成任务来讲,理想上有一个非常好的生成模型,同时达到最好的视觉效果和感知。从概率角度讲,每一个模型,都是一致的,也就是无穷数据、最大模型下可以恢复数据分布。因此,在极端情况下,所有的生成模型都有scaling law,但是我们关心的是现有算力、数据规模下不同模型的scaling law的变化率是否比较好。这个regimen下,不同模型的scaling law和metric,数据量,模型大小应该是有非常复杂的关系。
邓志杰:两位老师分享的有几个点,我特别同意,从metric,模态的角度是这样。现在比较关心的是文到视频场景里面,应该在哪些方面倾注比较大的资源,到底是标记数据还是提升显卡来训练模型,我也在思考。
江毅:个人认为所有的生成和理解任务都是围绕人的,所有任务都是人定义出来的,包括生成和理解,语义是最重要的,还是通过人来的。语音模型的语义才是未来,所以我的看法是语义是最关键的,就现在而言,围绕我们这些人所谓的概念和视频中的场景,包括文字渲染,这些都是最关键的,语义才是最重要的。
卢志武:个人经验觉得语言和视觉,这两个场景差别其实特别大,比如说大模型,套用在多模态,会发现效果是很差的。
李崇轩:个人认为幻觉可能就是伴随概率与生俱来的,可能是存在一个什么条件的输入,一定会有不好的情况出现。Scaling up可能会缓解幻觉,也可能会存在,严肃的场合下很难去应用。
观众提问
观众A: 刚才提到幻觉效应,利用思维链,提高结构化的推理路径引导模型产生事实性的输出,有没有该方向的应用?
邓志杰:借助辅助性的外部工具,很多幻觉都是可以消除掉的。
李崇轩:个人认为思维链相当于输入不同的条件,然后用对应的条件模型来回答,虽然都是使用同一个模型,但是条件的改变,结果会有区别,合适的prompt会激发合适的语料能力。在某些特定任务上,使用特定的prompt应该会有好的表现,可能也缺乏一些更深的理解。
观众B:如何使用大语言模型模仿我的思维,协助我,写出一篇很生动的思想政治教育授课稿?
陈键飞:个人认为这个应用属于长上下文的问题,根据使用者的背景,生成更加符合使用者特点的稿件,我总结这个特点可能是长上下文的问题。
观众C:从应用场景来提问题,比如说生成带有文字的图案,请问各位老师,达到这样的效果,是已经有现有的技术了,还是从什么途径找到这样的一个模型?
古纾旸:DALLE-3模型效果很不错,stable diffusion3提升也很多。现在我们有一些同事做过不错的探索,技术路线是在基础模型上做post-training,得到专有化模型,做的结果还可以。
观众C:开源预训练模型能力达不到是吗?
古纾旸:有一些是可以的,比如stable diffusion3,中文数据量相对少一些。
观众C:现在对于图案生成的位置,也不是太敏感,比如说生成左下角生成一只小狗,现有模型无法实现,这个有没有解决的途径?
古纾旸:这些基础模型是因为数据量的欠缺无法完成,针对这些问题,个人认为最简单实用的就是训练自己的专有模型。


