
- 1第一个ARM程序
- 2面经 | 我是如何通过校招拿到京东的Offer的。_京东校招面试流程
- 3实际项目中,运用Retrofit和OkHttp调用其他项目接口
- 4Linux下常用编译调试命令——gcc/g++与gdb工具的使用_gcc编译命令 ddebug
- 5【C++】红黑树的应用(封装map和set)_c++ map和红黑树
- 6TypeScript实战:下棋游戏_typescript实现掼蛋
- 7常见的七个排序算法:冒泡,直接插入,希尔,选择,堆,归并,快速排序。
- 8pip升级报错,或者pip install pywin32报错_pip 安装pywin32报错
- 9pikachu靶场-8 越权漏洞_pikachu垂直越权
- 10深度剖析记忆化搜索(非dp)_洛谷p1020 记忆化搜索
NVIDIA NeMo - 训练本地化多语种 LLM_nemo llm代码学习
赞
踩
本文转载自:使用 NVIDIA NeMo 训练本地化多语种 LLM (2024年 5月 17日 By Nicole Luo and Amit Bleiweiss
第 1 部分 https://developer.nvidia.com/zh-cn/blog/training-localized-multilingual-llms-with-nvidia-nemo-part-1/
第 2 部分 https://developer.nvidia.com/zh-cn/blog/training-localized-multilingual-llms-with-nvidia-nemo-part-2/

文章目录
一、概述
在当今的全球化世界中,AI 系统理解和沟通不同语言的能力变得越来越重要。
大型语言模型 (LLMs) 彻底改变了自然语言处理领域,使 AI 能够生成类似人类的文本、回答问题和执行各种语言任务。
然而,大多数主流 LLM 都在主要由英语组成的数据语料库上进行训练,从而限制了它们对其他语言和文化语境的适用性。
这就是 多语种 LLM 的价值所在:缩小语言差距,并释放 AI 的潜力,使其惠及更广泛的受众。
特别是,由于训练数据有限以及东南亚 (SEA) 语言的独特语言特性,当前最先进的 LLM 经常难以与这些语言进行交流。
这导致与英语等高资源语言相比,性能较低。
虽然一些 LLM 在一定程度上可以处理某些 SEA 语言,但仍然存在不一致、幻觉和安全问题。
与此同时,人们对在东南亚开发本地化的多语种 LLM 有着浓厚的兴趣和决心。
一个值得注意的例子是,新加坡启动了一项 7000 万新元的计划,以开发国家多模态大型语言模型计划 (NMLP)。
这项为期两年的国家层面计划旨在打造东南亚首个区域 LLM,专注于了解该地区独特的语言和文化细微差别。
随着东南亚地区对 AI 解决方案的需求不断增长,开发本地化的多语种 LLM 成为战略需要。
在其他地区也可以看到类似的趋势,目前先进的 LLM 不足以支持复杂的区域语言。
这些模型可以帮助企业和组织更好地服务客户、实现流程自动化,并创建更具吸引力的内容,与该地区的多元化人口产生共鸣。
NVIDIA NeMo 是一个端到端平台,旨在随时随地开发自定义生成式 AI。
它包括用于训练的工具、检索增强生成(RAG)、护栏和工具包、数据管护工具以及预训练模型,为企业提供了一种简单、经济高效且快速的方法来采用生成式 AI。
在本系列中,我们将探索使用 Omniverse Create 向基础语言模型(LLM)添加新语言支持的最佳实践。
本教程将指导您完成 NeMo 的关键步骤,包括分词器训练和合并、模型架构修改和模型持续预训练等。
在本文中,我们使用泰文维基百科数据对 GPT-1.3 B 模型进行持续预训练。
我们在第 1 部分中着重介绍了训练和合并多语种分词器,然后讨论了在 NeMo 模型中采用自定义分词器的方法,并将在 第 2 部分 中继续探讨。
通过遵循这些指南,您可以为多语种 AI 的发展做出贡献,并让更广泛的全球受众受益于 LLM。
二、本地化多语种 LLM 训练概述
多语种 LLM 面临的一个重大挑战是,理解目标语言的预训练基础 LLM 不足。
要构建多语种 LLM,您有以下几种选择:
- 使用多语种数据集从头开始预训练 LLM。
- 使用目标语言的数据集对英语基础模型进行持续预训练。
在低资源语言的情况下,后一种选择更可行。
根据定义,低资源语言的可用训练数据有限。
通过利用从最初训练模型所基于的高资源语言进行迁移学习,持续预训练可以有效地使模型适应新语言,即使数据量相对较少。
从头开始预训练需要使用低资源语言处理更大量的数据,才能达到相同的性能水平。
在尝试使用低资源数据进行持续预训练时,我们面临的一个挑战是次优分词器。
大多数基础模型都采用字节对编码 (BPE) 分词器。
原始分词器无法充分涵盖低资源语言的独特字符、子词和形态。
如果没有足够富有表现力的分词器,模型将难以高效地表示低资源语言,从而导致性能欠佳。
有必要构建自定义分词器,使模型能够在持续预训练期间更有效地处理和学习低资源语言数据。
为解决这些问题,我们建议通过以下工作流程为 LLM 添加新的语言支持。
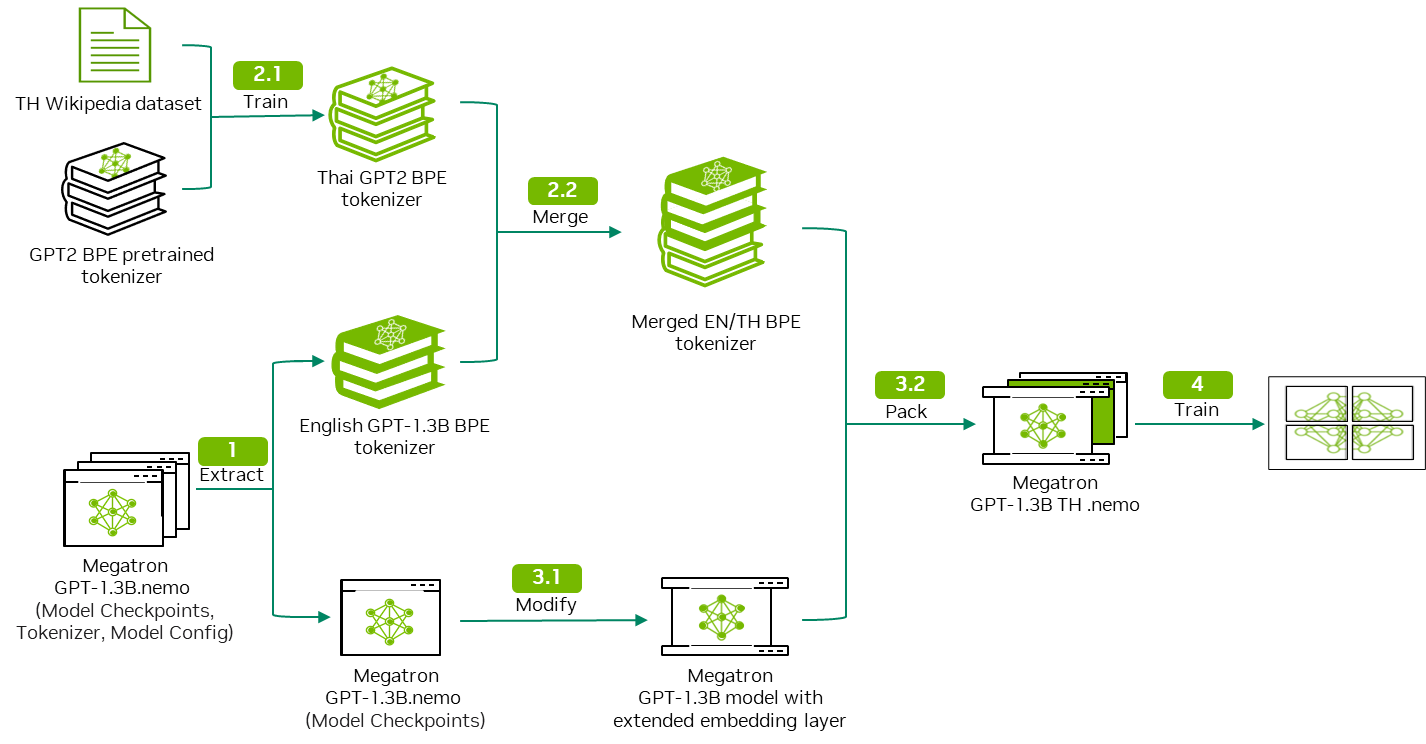 图 1.训练本地化多语种 LLM 的工作流程
图 1.训练本地化多语种 LLM 的工作流程
此工作流程将泰文维基百科数据用作以下步骤中的输入示例:
- 下载并解压缩 GPT 模型以获取模型权重和模型分词器。
- 自定义分词器训练并合并以输出双语分词器。
- 修改 GPT 模型架构以适应双语言分词器。
- 使用泰文维基百科数据执行持续预训练。
该工作流程具有通用性,可以应用于不同的语言数据集。
本博文详细介绍了步骤 1 和 2。
欲了解步骤 3 和 4 的详细信息,请参阅 第 2 部分。
三、教程预备知识
如需持续预训练 GPT-1.3 B 模型,我们建议使用以下硬件设置:
- 配备至少 30 GB GPU 显存的 NVIDIA GPU
- CUDA 和 NVIDIA 驱动:带驱动 535.154.05 的 CUDA 12.2
- Ubuntu 22.04
- NVIDIA Container Toolkit 版本 1.14.6:安装指南
- 我们使用了 NeMo 框架容器 24.01.01 版本。
我们通过 NGC 目录 提供对 GPU 加速软件的访问,旨在通过性能优化的容器、预训练的 AI 模型以及可在本地、云端或边缘部署的行业特定 SDK,以加速端到端工作流程。
第一步,从 NGC 目录中下载 NeMo 框架容器,并在容器镜像中运行 JupyterLab:
docker pull nvcr.io/nvidia/nemo:24.01.01.framework
docker run -it --gpus all -v : --workdir -p 8888:8888/ nvcr.io/nvidia/nemo:24.01.01.framework bash -c "jupyter lab"
四、数据收集和清理
在本教程中,我们使用 NVIDIA NeMo Curator 的 GitHub 存储库,用于下载和整理高质量的泰文维基百科数据。
NVIDIA NeMo Curator 由一系列可扩展的数据挖掘模块组成,旨在整理用于训练 LLM 的 NLP 数据。
NeMo Curator 中的模块使 NLP 研究人员能够从大量未整理的网络语料库中大规模挖掘高质量文本。
对于管线,请按照以下步骤操作:
- 使用不同的语言筛选非泰语内容。
- 重新格式化文档以校正任何 Unicode。
- 执行文档级精确重复数据删除和模糊重复数据删除,以删除重复的数据点。
- 执行文档级启发式过滤,以删除低质量文档。
通过使用 NVIDIA NeMo Curator 中演示的相同流程,可以复制其他语言的策展过程。
五、模型下载和提取
在这篇博文中,我们使用 nemo-megatron-gpt-1.3B 模型,该模型基于英语单语数据集 Pile 数据集。
您可以直接从 HuggingFace 下载模型,或者运行以下命令下载模型:
!wget -P './model/nemo_gpt_megatron_1pt3b_fb16/' https://huggingface.co/nvidia/nemo-megatron-gpt-1.3B/resolve/main/nemo_gpt1.3B_fp16.nemo
验证下载文件的 MD5 校验和,以确保其完整性:
!md5sum nemo_gpt1.3B_fp16.nemo
您应获得以下内容作为输出:
38f7afe7af0551c9c5838dcea4224f8a nemo_gpt1.3B_fp16.nemo
下载模型后,解压模型中的文件:vocab.json 和 merge.txt:
!tar -xvf ./model/nemo_gpt_megatron_1pt3b_fb16/nemo_gpt1.3B_fp16.nemo -C ./m
执行该命令后,将生成以下输出。
现在,您可以访问 vocab.json 和 merge.txt 文件,这些文件稍后将用于 tokenizer 的合并。
./
./50284f68eefe440e850c4fb42c4d13e7_merges.txt
./c4aec99015da48ba8cbcba41b48feb2c_vocab.json
./model_config.yaml
./model_weights.ckpt
六、分词器训练
要训练能够将其他语言和英语标记化的分词器,您可以采用以下两种方法之一:
- **多语种数据集:**使用包含英语的多语言数据集,从头开始训练分词器,其优点在于您可以获得多语言数据集的真实分布。
- **单语言数据集:**首先训练单语分词器,然后将其与原始英语分词器合并。
这样做的优点是,可以保留英语分词的原始分词映射,并重复使用基础模型的嵌入层,从而缩短分词器训练的时间。
本教程使用单语言数据集方法来保留预训练 GPT Megatron 模型的嵌入层。
此方法的详细步骤包括:
- **收集分词器训练数据:**从预训练数据集中进行子采样,以获取 tokenizer 训练所需的数据。
在本教程中,我们随机采样了 30% 的训练数据用于该目的。 - **训练自定义 GPT2 分词器:**使用预训练的 HuggingFace 模型作为起点,我们可以使用您自己的数据语料库来训练自定义的 TH GPT2 分词器。
- **合并两个分词器:**手动合并
merges.txt和vocab.json两个文件,以创建一个单一的分词器。
在本教程中,请使用泰语作为目标语言。
导入必要的库
开始之前,请先导入以下库:
import os
from transformers import GPT2Tokenizer, AutoTokenizer
import random import json
准备训练语料库
定义一个名为 convert_jsonl_to_txt 的函数,以从训练文档数据中采样,并将其写入 .txt 格式的输出文件中。
在本教程中,我们使用 'text' 作为访问训练文档数据的 JSON 密钥,根据需要可以更改该密钥。
def convert_jsonl_to_txt(input_file, output_file, percentage, key='text'):
with open(input_file, 'r', encoding='utf-8') as in_file, open(output_file, 'a', encoding='utf-8') as out_file:
for line in in_file:
if random.random() < percentage:
data = json.loads(line)
out_file.write(f"{data[key].strip()}\n")
现在,您可以读取输入文件并形成分词器训练语料库:
for file in os.listdir('./training_data'):
if 'jsonl' not in file:
continue
input_file = os.path.join('./training_data',file)
convert_jsonl_to_txt(input_file,'training_corpus.txt', 0.3)
with open('training_corpus.txt', 'r') as file:
training_corpus = file.readlines()
当训练语料库过大,无法加载到一个目标中时,可以采用迭代器方法加载训练语料库。
另外,如果您想了解更多相关信息,请参阅 根据旧的分词器训练新的分词器。
训练单语分词器
首先加载预训练的 GPT2 分词器,然后调用 tokenizer.train_new_from_iterator 方法,以训练新分词器。
Vocab_size 是 tokenizer.train_new_from_iterator 的一个参数,它决定词汇表中唯一令牌的最大数量。
值越大,可实现更精细的令牌化,但会增加模型的复杂性;而值越小,则可实现更粗粒度的令牌化,且唯一令牌越少,模型越简单。
old_tokenizer = AutoTokenizer.from_pretrained("gpt2")
new_tokenizer = old_tokenizer.train_new_from_iterator(training_corpus, vocab_size=8000)
new_tokenizer.save_pretrained('./new_monolingual_tokenizer/')
现在,您已完成训练新的单语分词器,请检查新分词器在目标语言上的有效性。
使用预训练的 GPT2 分词器和 TH 分词器分别将泰语句子和英语句子分词:
- 泰语句子:“เมืองหลวงของประเทศไทยคือกรุงเทพฯ” 是指“泰国的首都是曼谷”。
- 英语句子:“The capital of Thailand is Bangkok.”
Thai_text='เมืองหลวงของประเทศไทยคือกรุงเทพฯ'
print(f"Sentence:{Thai_text}")
print("Output of TH tokenizer: ",new_tokenizer.tokenize(Thai_text,return_tensors='pt'))
print("Output of pretrained tokenizer: ", old_tokenizer.tokenize(Thai_text,return_tensors='pt'))
Eng_text="The capital of Thailand is Bangkok."
print(f"Sentence:{Eng_text}")
print("Output of TH tokenizer: ",new_tokenizer.tokenize(Eng_text,return_tensors='pt'))
print("Output of pretrained tokenizer: ", old_tokenizer.tokenize(Eng_text,return_tensors='pt'))
您应该会得到以下几行作为输出:
Sentence:เมืองหลวงของประเทศไทยคือกรุงเทพฯ
Output of TH tokenizer: ['à¹Ģม', 'ื', 'à¸Ńà¸ĩหลวà¸ĩ', 'à¸Ĥà¸Ńà¸ĩà¸Ľà¸£à¸°à¹Ģà¸Ĺศà¹Ħà¸Ĺย', 'à¸Ħ', 'ื', 'à¸Ńà¸ģร', 'ุ', 'à¸ĩà¹Ģà¸Ĺà¸ŀฯ']
Output of pretrained tokenizer: ['à¹', 'Ģ', 'à¸', '¡', 'à¸', '·', 'à¸', 'Ń', 'à¸', 'ĩ', 'à¸', '«', 'à¸', '¥', 'à¸', '§', 'à¸', 'ĩ', 'à¸', 'Ĥ', 'à¸', 'Ń', 'à¸', 'ĩ', 'à¸', 'Ľ', 'à¸', '£', 'à¸', '°', 'à¹', 'Ģ', 'à¸', 'Ĺ', 'à¸', '¨', 'à¹', 'Ħ', 'à¸', 'Ĺ', 'à¸', '¢', 'à¸', 'Ħ', 'à¸', '·', 'à¸', 'Ń', 'à¸', 'ģ', 'à¸', '£', 'à¸', '¸', 'à¸', 'ĩ', 'à¹', 'Ģ', 'à¸', 'Ĺ', 'à¸', 'ŀ', 'à¸', '¯']
Sentence:The capital of Thailand is Bangkok.
Output of TH tokenizer: ['The', 'Ġc', 'ap', 'ital', 'Ġof', 'ĠThailand', 'Ġis', 'ĠB', 'ang', 'k', 'ok', '.']
Output of pretrained tokenizer: ['The', 'Ġcapital', 'Ġof', 'ĠThailand', 'Ġis', 'ĠBangkok', '.']
从输出中可以看到,与泰语句子的英语标记器和英语句子的英语标记器相比,TH 标记器生成的标记列表更短。
原因是,许多泰文字符,尤其是那些表示元音和色调标记的字符,在英语分词器中很可能被视为词外音(OOV)。
分词器可以将这些字符拆分为单个字节,或将其替换为UNK token,从而增加 token 数量。
七、分词器合并
要合并两个分词器,您必须处理vocab.json和merges.txt文件。
以下是合并这两个文件的方法。
对于 vocab.json 文件中:
- 维护预训练的分词器的
vocab.json文件中的 ID 令牌映射。 - 通过自定义的单语言分词器迭代处理
vocab.json文件,以便在遇到新令牌时进行更新。 - 将其添加到原始文件
vocab.json中,该文件带有累加令牌 ID。
关于merges.txt文件:
- 预训练的分词器的
merges.txt文件保持不变。 - 通过使用自定义的单语言分词器来迭代
merges.txt文件。 - 当遇到新的合并规则时,请将其添加到原始规则文件
merges.txt中。
规则是,在合并时,不允许重新排列或修改vocab.json文件或merges.txt文件的原始顺序。
对于vocab.json,您必须保持原始 ID 令牌映射相同,才能重用预训练嵌入层。
如果在将新合并的标记器加载到预训练模型并尝试获取令牌的嵌入时,映射受到干扰,模型可能会输出其他令牌的预训练嵌入,例如将‘dog’的 token ID 更改为‘cat’,从而导致‘dog’在合并过程中发生更改。
例如,在merges.txt文件中,合并规则的顺序对于让 BPE 标记器在标记化新文本时以最佳状态运行至关重要。
标记化器将按顺序应用这些规则,从第一个规则开始,一直向下列表,直到无法应用进一步的规则。
因此,合并规则的顺序更改将严重影响标记化器的性能,并导致次优标记化。
这是一个示例。
假设您有一个令牌列表['N', 'VI', 'D', 'IA'],以及两套不同的合并规则:
Set A:
N VI
D IA
NVI DIA
Set B:
D IA
NVI DIA
N VI
在对令牌列表应用集 A 时,分词器按给定顺序遵循合并规则:
['N', 'VI', 'D', 'IA'] -> ['NVI', 'D', 'IA'](应用规则 1。)['NVI', 'D', 'IA'] -> ['NVI', 'DIA'](应用规则 2。)['NVI', 'DIA'] -> ['NVIDIA'](应用规则 3)
标记化的最终输出结果为['NVIDIA'],这是我们所期望的结果。
但是,将集合 B 应用于同一令牌列表时,分词器会遇到以下问题:
['N', 'VI', 'D', 'IA'] -> ['N', 'VI', 'DIA'](应用规则 1)。['N', 'VI', 'DIA'](从下一个合并规则中的第一个令牌开始,无法应用更多规则,因为'NVI'未找到。)
在这种情况下,分词器无法合并 'N'和 'VI' ,因为合并规则 'N VI' 出现在 'NVI DIA' 中。
因此,分词器会生成次优输出: ['N', 'VI', 'DIA'] ,而不是['NVIDIA']。
更改规则的顺序会改变分词器的行为,并可能降低其性能。
运行以下代码以进行分词器合并:
output_dir = './path_to_merged_tokenizer'
# Make the directory if necessary
if not os.path.exists(output_dir ):
os.makedirs(output_dir)
#Read vocab files
old_vocab = json.load(open(os.path.join('./path_to_pretrained_tokenizer', 'vocab.json')))
new_vocab = json.load(open(os.path.join('./path_to_cusotmized_tokenizer', 'vocab.json')))
next_id = old_vocab[max(old_vocab, key=lambda x: int(old_vocab[x]))] + 1
# Add words from new tokenizer
for word in new_vocab.keys():
if word not in old_vocab.keys():
old_vocab[word] = next_id
next_id += 1
# Save vocab
with open(os.path.join(output_dir , 'vocab.json'), 'w') as fp:
json.dump(old_vocab, fp, ensure_ascii=False)
old_merge_path = os.path.join('./path_to_pretrained_tokenizer', 'merges.txt')
new_merge_path = os.path.join('./path_to_cusotmized_tokenizer', 'merges.txt')
#Read merge files
with open(old_merge_path, 'r') as file:
old_merge = file.readlines()
with open(new_merge_path, 'r') as file:
new_merge = file.readlines()[1:]
#Add new merge rules, the order of merge rule has to be maintained
old_merge_set = set(old_merge)
combined_merge = old_merge + [merge_rule for merge_rule in new_merge if merge_rule not in old_merge_set]
# Save merge.txt
with open(os.path.join(output_dir , 'merges.txt'), 'w') as file:
for line in combined_merge:
file.write(line)
现在,您可以加载并测试组合的 tokenizer,并将其 tokenization 输出与预训练的 tokenizer 和自定义的单语言 tokenizer 进行比较。
您应该能够观察到组合的 tokenizer 在将目标语言和英语标记化方面效果良好。
八、第一部分小结
此时,您已成功自定义能够将英语和目标语言标记化的 BPE 标记器。
在 下一篇文章 中,我们将修改预训练模型的嵌入层,以便采用自定义分词器,并开始将修改后的模型与自定义分词器一起使用,以便在 NeMo 中进行持续预训练。
要开始训练多语种分词器,请首先下载并设置开源语言数据集,以整理用于训练的低资源语言数据集。
NeMo 策展人 已在 GitHub 上发布。
另外,您还可以通过 NeMo 微服务抢先体验 请求访问 NVIDIA NeMo Curator,以加速和简化数据管护流程。
上面我们讨论了如何训练单语分词器,并将其与预训练 LLM 的分词器合并,以形成多语言分词器。
下面,我们将向您展示如何将自定义分词器集成到预训练 LLM,以及如何在 NVIDIA NeMo 中实现这一目标。
图 1.训练本地化多语种 LLM 的工作流程
九、准备工作
开始之前,请先导入以下库:
import torch
from nemo.collections.nlp.models.language_modeling.megatron_gpt_model import MegatronGPTModel
from nemo.collections.nlp.parts.megatron_trainer_builder import MegatronTrainerBuilder
from omegaconf import OmegaConf
十、模型修改
合并后,组合分词器的词汇量大于 GPT-megatron-1.3 B 模型预训练分词器的词汇量。
这意味着您必须扩展 GPT – megatron – 1.3 B 模型的嵌入层,以适应组合分词器 (图 2)。
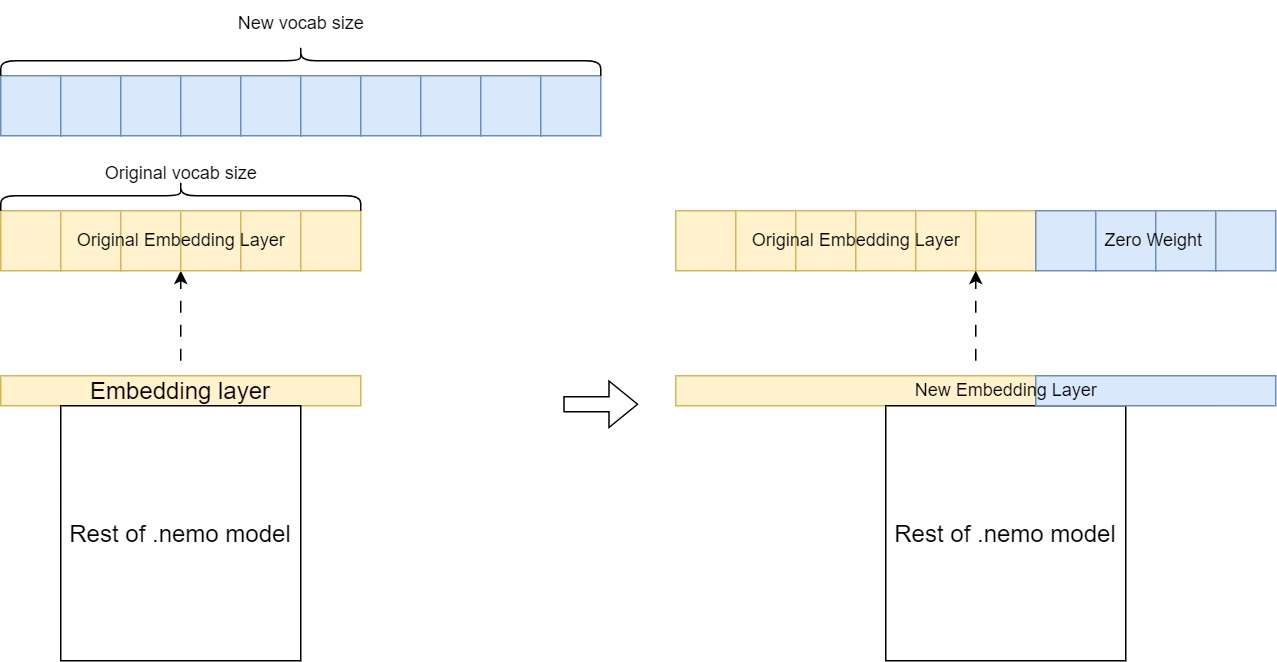 图 2.扩展新分词器的模型嵌入层
图 2.扩展新分词器的模型嵌入层
关键步骤包括以下内容:
- 使用所需增加的词汇量创建新的嵌入层。
- 通过从原始嵌入层复制现有权重来初始化它。
- 将新词表条目设置为零权重。
然后,此扩展嵌入层会替换预训练模型中的原始层,使其能够以新语言处理其他标记,同时保留在初始预训练过程中学习的知识。
加载并提取嵌入层
运行以下代码以加载 GPT-megatron-1.3 B.nemo 模型:
#Initialization
trainer_config = OmegaConf.load('/opt/NeMo/examples/nlp/language_modeling/conf/megatron_gpt_config.yaml')
trainer_config.trainer.accelerator='gpu' if torch.cuda.is_available() else 'cpu'
trainer = MegatronTrainerBuilder(trainer_config).create_trainer()
#load gpt-megatron-1.3b.nemo and its config
nemo_model = MegatronGPTModel.restore_from('./path_to_1.3B_nemo_model',trainer=trainer)
nemo_config = OmegaConf.load('./path_to_1.3B_nemo_model_config.yaml')
加载模型后,您可以从模型中提取嵌入层的权重,即 state_dict 参数。
该嵌入层用于生成新的嵌入层。
#Extract original embedding layer
embed_weight = nemo_model.state_dict()[f'model.language_model.embedding.word_embeddings.weight']
print(f"Shape of original embedding layer: {embed_weight.shape}")
生成新的嵌入层
现在,您必须计算新嵌入层和原始嵌入层之间的维度差异。
根据此差异创建张量,并将其连接到原始嵌入层,以形成新的嵌入层。
差值基于以下内容计算得出:
- 组合分词器词汇量
- 原始嵌入层长度
- 一个参数:
model_config.yaml和model.make_vocab_size_divisible_by
以下是差值的方程:

- 组合分词器词汇量 =

- 原始 NeMo 嵌入层长度 =

- model.make_vocab_size_divisible_by =

机制是,为了更大限度地提高计算效率,您需要将嵌入层填充到可被 8 的倍数整除的数字上。
给定 tokenizer 词汇量,模型预计会有一个带填充的嵌入层。
如果您从头开始训练,此过程应该是自动的,但在这种情况下,您必须手动填充新的嵌入层。
tokenizer = AutoTokenizer.from_pretrained('./path_to_new_merged_tokenizer')
if len(tokenizer)% nemo_config.make_vocab_size_divisible_by != 0:
tokenizer_diff = (int(len(tokenizer)/nemo_config.make_vocab_size_divisible_by)+1) * nemo_config.make_vocab_size_divisible_by - embed_weight.shape[0]
else:
tokenizer_diff = tokenizer.vocab_size - embed_weight.shape[0]
现在,您可以生成额外的张量作为新标记的初始权重。
然后,此张量连接到之前提取的原始嵌入层,以形成新的嵌入层。
hidden_size = embed_weight.shape[1]
random_embed = torch.zeros((tokenizer_diff, hidden_size)).to('cuda')
new_embed_weight = torch.cat((embed_weight, random_embed), dim=0)
修改并输出新模型
在此步骤中,您将修改模型配置中与 tokenizer 相关的设置,以与新词表保持一致。
回想一下,新嵌入的形状不同于原始嵌入层。
如果直接替换原始模型中的嵌入层,您将遇到层大小不匹配错误。
加载包含更新的 tokenizer 配置的空模型实例,并将预训练模型的值分配给其 state_dict,同时添加新的嵌入层。
最后,以 .nemo 格式保存此修改后的模型,以便对扩展的词汇表进行持续预训练。
state_dict = nemo_model.state_dict()
state_dict[f'model.language_model.embedding.word_embeddings.weight'] = new_embed_weight
NEW_TOKENIZER_PATH = './path_to_new_merged_tokenizer'
nemo_config['tokenizer']['vocab_file'] = f"{NEW_TOKENIZER_PATH}/vocab.json"
nemo_config['tokenizer']['merge_file'] = f"{NEW_TOKENIZER_PATH}/merges.txt"
nemo_config['vocab_file'] = f"{NEW_TOKENIZER_PATH}/vocab.json"
nemo_config['merges_file'] = f"{NEW_TOKENIZER_PATH}/merges.txt"
new_nemo_model = MegatronGPTModel(nemo_config,trainer)
new_nemo_model.load_state_dict(state_dict)
new_nemo_model.save_to('./path_to_modified_nemo_model')
运行以下代码,检查新模型在英语提示下是否表现良好:
python /opt/NeMo/examples/nlp/language_modeling/megatron_gpt_eval.py \ gpt_model_file='./path_to_modified_nemo_model' \
prompts='ENTER YOUR PROMPT' \
inference.greedy=True \
inference.add_BOS=True \
trainer.devices=1 \
trainer.num_nodes=1 \
tensor_model_parallel_size=-1 \
pipeline_model_parallel_size=-1
十一、数据预处理
为了确保数据的一致性,请重复运行数据预处理脚本以处理训练、验证和测试数据集。
有关更多信息,请参阅 第 3 步:将数据拆分为训练、验证和测试。
替换 --json_key 参数,用于指定数据集中文档文本的键值:
python /opt/NeMo/scripts/nlp_language_modeling/preprocess_data_for_megatron.py \ --input='./path_to_train/val/test_dataset' \
--json-keys=text \
--tokenizer-library=megatron \
--vocab './path_to_merged_tokenizer_vocab_file'\
--dataset-impl mmap \
--tokenizer-type GPT2BPETokenizer \
--merge-file './path_to_merged_tokenizer_merge_file' \
--append-eod \
--output-prefix='./path_to_output_preprocessed_dataset'
十二、持续预训练
与您的模型相比,用于持续预训练的默认配置文件可能具有不同的模型配置。
运行以下代码以覆盖这些配置。
并相应地更新 tokenizer 和 data prefix 参数。
ori_conf = OmegaConf.load('./path_to_original_GPT-1.3B_model/model_config.yaml')
conf = OmegaConf.load('/opt/NeMo/examples/nlp/language_modeling/conf/megatron_gpt_config.yaml')
for key in ori_conf.keys():
conf['model'][key] = ori_conf[key]
# Set global_batch_size based on micro_batch_size
conf['model']["global_batch_size"] = conf['model']["micro_batch_size"] * conf.get('data_model_parallel_size',1) * conf.get('gradient_accumulation_steps',1)
# Reset data_prefix (dataset path)
conf['model']['data']['data_prefix'] = '???'
# Reset tokenizer config
NEW_TOKENIZER_PATH = "./path_to_new_merged_tokenizer"
conf['model']['tokenizer']['vocab_file'] = f"{NEW_TOKENIZER_PATH}/vocab.json"
conf['model']['tokenizer']['merge_file'] = f"{NEW_TOKENIZER_PATH}/merges.txt"
conf['model']['vocab_file'] = f"{NEW_TOKENIZER_PATH}/vocab.json"
conf['model']['merges_file'] = f"{NEW_TOKENIZER_PATH}/merges.txt"
OmegaConf.save(config=conf,f='/opt/NeMo/examples/nlp/language_modeling/conf/megatron_gpt_config.yaml')
运行以下代码以开始持续预训练。
应根据您的特定硬件和设置修改以下参数:
nproc_per_node:每个节点上的 GPU 数量。model.data.data_prefix:训练、验证和测试数据集的路径,请参阅代码示例以了解相关格式。exp_manager.name:输出文件夹名称,该名称将用于保存中间检查点,在./nemo_experiments/文件夹中。trainer.devices:每个节点的 GPU 设备数量。trainer.num_nodes:表示模型训练的节点数。trainer.val_check_interval:在训练过程中执行验证检查的频率(以步数为单位)。trainer.max_steps:指定训练过程的最大步长。model.tensor_model_parallel_size:对于 13B 模型,请继续使用1。
对于更大的模型,请使用更大的尺寸。model.pipeline_model_parallel_size:对于 13B 模型,建议保持为1。
对于更大的模型,建议使用更大的尺寸。model.micro_batch_size:根据 GPU 的视频随机存取存储器(vRAM)大小进行调整。model.global_batch_size:其值取决于micro_batch_size。
欲了解更多信息,请参阅 批处理(Batching)。
DATA = '{train:[1.0,training_data_indexed/train_text_document], validation:[training_data_indexed/val_text_document], test:[training_data_indexed/test_text_document]}'
!torchrun --nproc_per_node=1 \ /opt/NeMo/examples/nlp/language_modeling/megatron_gpt_continue_training.py \
"model.data.data_prefix={DATA}"\
name=megatron_gpt_ \
exp_manager.name=megatron_gpt_1 \
restore_from_path='./path_to_modified_nemo_model' \
trainer.devices=1 \
trainer.num_nodes=1 \
trainer.precision=16 \
trainer.val_check_interval=300 \
trainer.max_steps=1200 \
model.megatron_amp_O2=False \
model.tensor_model_parallel_size=1 \
model.pipeline_model_parallel_size=1 \
model.micro_batch_size=1 \
model.global_batch_size=1 \
++model.use_flash_attention=False \
++model.seq_len_interpolation_factor=null
十三、模型推理
在训练期间,生成的中间文件将存储在./nemo_experiments 文件夹中。
在这里,您应该可以找到所需的模型 Checkpoint 文件和 hparams.yaml 文件。
使用以下代码使用 Checkpoint 文件进行推理:
python /opt/NeMo/examples/nlp/language_modeling/megatron_gpt_eval.py \
'checkpoint_dir="./path_to_checkpoint_folder"' \
'checkpoint_name="name of checkpoint file in .ckpt format"' \
'hparams_file="./path_to_hparams_file"' \
prompts='ENTER YOUR PROMPT' \
inference.greedy=True \
inference.add_BOS=True \
trainer.devices=1 \
trainer.num_nodes=1 \
tensor_model_parallel_size=-1 \
pipeline_model_parallel_size=-1
表 1 比较了原始 GPT-megatron-1.3 B 模型和使用泰文维基百科数据训练的 GPT-megatron-1.3 B 模型生成的句子输出。
在本文中,我们截断了一些重复输出标记。
| 提示 | GPT-megatron-1.3 B.nemo 的输出 | 输出经过训练的 GPT-megatron-1.3 B-TH.nemo |
|---|---|---|
| 泰国的省会城市是 | 泰国的省会城市为曼谷。 | |
| 泰国的省会城市为曼谷。 | ||
| n nHistory n n 泰国的省会城市原名 Chiang Mai,意思是“太阳之城”。 | ||
| 泰国的省会城市原名 Chiang Mai,意思是“太阳之城”。 | ||
表 1.句子输出对比
训练后,模型提高了对泰语的理解,尽管其英语性能降低。
这是由于使用单语数据集持续预训练导致模型遗忘。
为避免这种情况,我们建议使用包含英语和目标语言的语料库进行训练。
十四、结束语
通过遵循此工作流程,您可以有效地扩展基础 LLM 的语言支持,使其能够理解并生成多种语言的内容。
此方法使用在初始预训练期间学习的现有知识和表征,同时使模型能够通过持续学习适应和获得新的语言技能。
此过程的成功确实取决于用于分词器训练和持续预训练的目标语言数据的质量和数量。
为了确保最佳性能,尤其是减轻灾难性的遗忘,仔细的训练课程和训练策略也是必要的。
要开始使用,请下载 NeMo 框架容器 或下载并设置 NVIDIA/NeMo 开源库 在 GitHub 上。
您可以在低资源语言上使用自己的精选数据集,并按照本文中的步骤在基础语言模型(LLM)上添加所需的新语言支持。
作为 NeMo 微服务抢先体验,您还可以请求访问 NVIDIA NeMo 策展人 和 NVIDIA NeMo 定制器 微服务。
这些微服务共同简化了大语言模型(LLM)的数据管护和自定义,使您能够更快地将解决方案推向市场。
2024-05-28(二)

