
- 1python小程序表白_python表白小程序
- 2一文详解常见医学自然语言理解任务和算法_chip-ctc
- 3mcsm服务器管理系统,使用MCSManager搭建Minecraft服务器
- 4Python人生重开模拟器(高级版)_人生重开模拟器 如何开发
- 5python多进程爬虫与多线程爬虫模板_python超级高效的多线程模板
- 6xp配置网站服务器配置,WINDOWSXP服务器配置方法.pdf
- 72023年腾讯云轻量服务器评测:2核2G4M、4核8G12M、16核32G28M_2023年腾讯云轻量8核16g18m主机优惠价cpu性能测评
- 8【English】一、专治各种英语不服
- 9ingress-nginx 实现内部局域网的url转发配置_ingress转发内部接口
- 10chatgpt赋能python:Python中的[:,i]到底是什么?_python [:, i]
计算机功能简介:EC, NVMe, SCSI/ISCSI与块存储接口 RBD,NUMA
赞
踩
一 EC是指Embedded Controller
主要应用于移动计算机系统和嵌入式计算机系统中,为此类计算机提供系统管理功能。EC的主要功能是控制计算机主板上电时序、管理电池充电和放电,提供键盘矩阵接口、智能风扇接口、串口、GPIO、PS/2等常规IO功能,EC还可能有SPI接口,可以连接Flash ROM(主板BIOS)及其它SPI设备。在没有SIO(Super I/O)芯片的情况下,EC可以被定义成SIO。
下面是某EC芯片的内部功能框图。

该芯片主要分为以下三大部分:
主机域。包含:LPC、PNPCFG、RTCT逻辑设备,以及SMFI/SWUC/KBC/PMC逻辑设备的主机部分,EC2I的主机部分。
EC域。包含:EC8032、INTC、WUC KB扫描、GPIO、ECPM、SMB、PS/2、DAC、ADC、PWM、ETWD、EC2I、GCTRL、BRAM、EGPC、DBGR、CEC、SMFI/SWUC/KBC/PMC 的EC部分和EC2I的EC部分。
双映射模块。包含:CIR、BRAM、SSPI、PECI、UART1和UART2等。
技术细节请参阅相关文献或芯片Datasheet
下面是某主板的部分时序控制示意图。
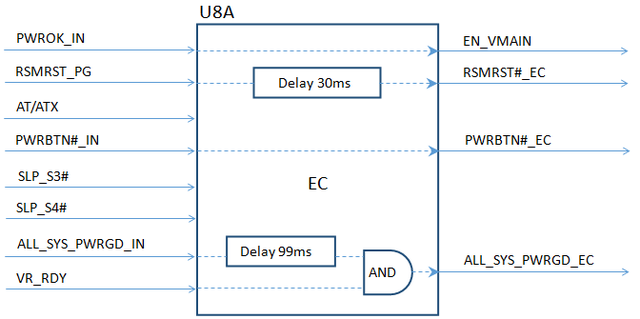
从上图可以看出,EC的好处是可以根据当前设计方案,适当调整关键信号的生效时间,让各组电路全部准备就绪后才开机。避免部分功能识不到或识别错误。特别是在工业应用领域,有许多老旧的功能设备速度太慢,利用EC延长计算机上电到开机的时间,给这些功能设备留出足够的等待时间,可以确保这些功能设备有足够的时间进行必要的初始化,确保该设备运转正常。
二 NVMe是一个逻辑设备接口规范
它是与AHCI类似的、基于设备逻辑接口的总线传输协议规范(相当于通讯协议中的应用层),用于访问通过PCI Express(PCIe)总线附加的非易失性存储器介质(例如采用闪存的固态硬盘驱动器),虽然理论上不一定要求 PCIe 总线协议。
NVMe的优点
NVMe标准是面向PCI-E SSD的,使用原生PCI-E通道与CPU直连可以免去SATA与SAS接口的外置控制器(PCH)与CPU通信所带来的延时。
NVMe加入了自动功耗状态切换和动态能耗管理功能,设备从Power State 0闲置50ms后可以切换到Power State 1,继续闲置的话,在500ms后又会进入功耗更低的Power State 2,切换时虽然会有短暂延迟,但SSD在闲置时可以把功耗控制在极低的水平,在功耗管理上NVMe标准的SSD会比现在主流的AHCI SSD拥有较大优势,这一点对移动设备来说尤其重要,可以显著增加笔记本和平板电脑的续航能力。
NVMe的发展历史
NVMe1.0标准与2011年3月推出,由NVMe规范组织成员公司(如Intel,戴尔,三星,镁光等共计100多家公司)合作开发。2012年10月推出了1.1的版本。在2014年11月推出1.2版本之后,时隔近3年,2017年5月,NVMe规范组织正式发布了最新版的NVMe1.3版规范标准。在最新的1.3中添加了如设备自检、引导分区、虚拟化、主机操控散热管理等新特性,理论上能够大大改进SSD的性能。
三【存储】SCSI、iSCSI协议详解及对比
SCSI是小型计算机系统接口(Small Computer System Interface)的简称,于1979首次提出,是为小型机研制的一种接口技术,现在已完全普及到了小型机,高低端服务器以及普通PC上。SCSI协议定义了一套不同设备(磁盘,磁带,处理器,光设备,网络设备等)利用该框架进行信息交互的模型和必要指令集。
SCSI指的是一个庞大协议体系,可以划分为SCSI-1、SCSI-2、SCSI-3,最新的为SCSI-3,也是目前应用最广泛的SCSI版本。
◼ SCSI-1:1979年提出,支持同步和异步SCSI外围设备;支持7台8位的外围设备,最大数据传输速度为5MB/s。
◼ SCSI-2:1992年提出,也称为Fast SCSI,数据传输率提高到20MB/s。
◼ SCSI-3:1995年提出,Ultra SCSI(Fast-20)。Ultra 2 SCSI(Fast-40)出现于1997年,最高传输速率可达80MB/s。1998年9月,Ultra 3 SCSI(Utra 160 SCSI)正式发布,最高数据传输率为160MB/s。Ultra 320 SCSI的最高数据传输率已经达到了320MB/s。
SCSI协议本质上同传输介质无关,SCSI可以在多种介质上实现,甚至是虚拟介质。例如基于光纤的FCP链路协议(FCP,Fibre Channel Protocol,是使用底层光纤通道连接的 SCSI接口 协议),基于SAS的链路协议(串行SCSI协议(SSP)用于传输SCSI命令),基于虚拟IP链路的iSCSI协议。通俗点说SCSI协议就是一个存储设备与服务器之间接口传递的一个规范。

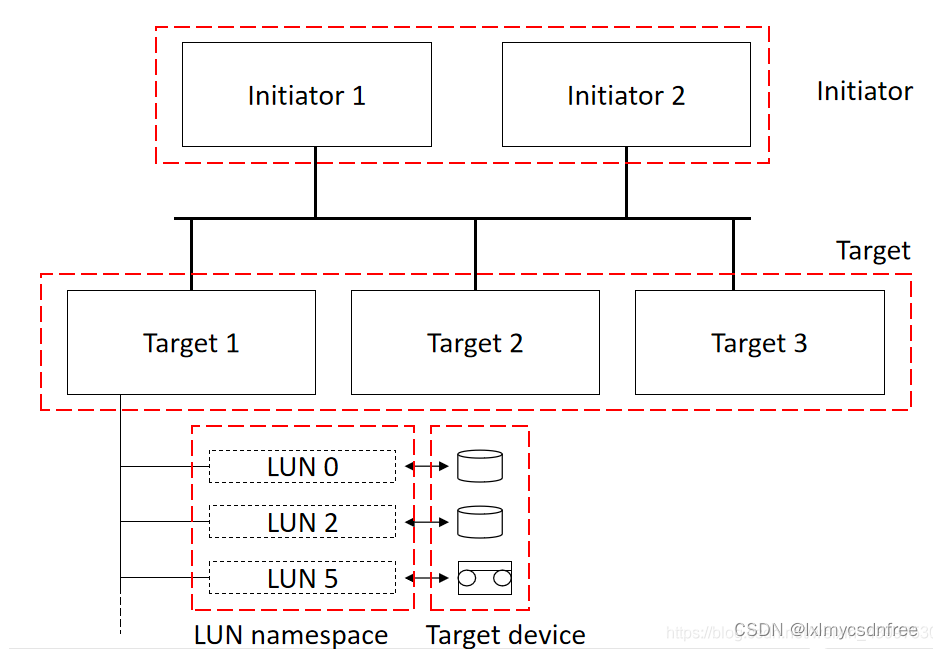
逻辑单元(LUN):LUN是SCSI目标器中所描述的名字空间资源,一个目标器可以包括多个LUN,而且每个LUN的属性可以有所区别,比如LUN#0可以是磁盘,LUN#1可以是其他设备。
启动器(Initiator):本质上,SCSI是一个C/S架构,其中客户端成为启动器,负责向SCSI目标器发送请求指令,一般主机系统都充当了启动器的角色。启动器通常在软件中实现,其功能类似于硬件 iSCSI HBA,以从远程存储服务器访问目标。使用基于软件的 iSCSI 发起程序需要连接到具有足够带宽的现有以太网网络以承载预期的存储流量。
目标器(Target):处理SCSI指令的服务端称为目标器,它接收来自主机的指令并解析处理,比如磁盘阵列的角色就是目标器。 SCSI的Initiator与Target共同构成了一个典型的C/S模型,每个指令都是“请求/应答”这样的模型来实现。为了提供对存储或输出设备的访问,目标配置有一个或多个逻辑单元号 (LUN)。在 iSCSI 中,LUN 显示为目标的按顺序编号的磁盘驱动器,尽管目标通常只有一个 LUN。启动器与目标执行 SCSI 协商以建立到 LUN 的连接。LUN 以模拟 SCSI 磁盘块设备的形式响应,它可以以原始形式使用,也可以使用客户端支持的文件系统进行格式化。iscsi 通过使用 ACL 提供 LUN 屏蔽。这确保了只有指定的客户端节点才能登录到特定的目标。在目标服务器上,可以在 TPG 级别设置 ACL 以保护 LUN 组,或为每个 LUN 单独设置。
◼ Initiator主要任务:发出SCSI请求。
◼ Target主要任务:回答SCSI请求,通过LUN提供业务,并通过任务管理器提供任务管理功能。
iSCSI
iSCSI是由Cisco和 IBM两家发起的,2003年2月由IETF(互联网工程任务组)认证通过,是一项比较成熟的技术。它将SCSI命令封装在TCP/IP包里,并使用一个iSCSI帧头。它基于IP协议栈,假设以不可靠的网络为基础,依靠TCP恢复丢失的数据包。iSCSI继承了两大最传统技术:SCSI和TCP/IP协议。这为iSCSI的发展奠定了坚实的基础。基于iSCSI的存储系统只需要不多的投资便可实现SAN存储功能,甚至直接利用现有的TCP/IP网络。相对于以往的网络存储技术,它解决了开放性、容量、传输速度、兼容性、安全性等问题,其优越的性能使其备受始关注与青睐。
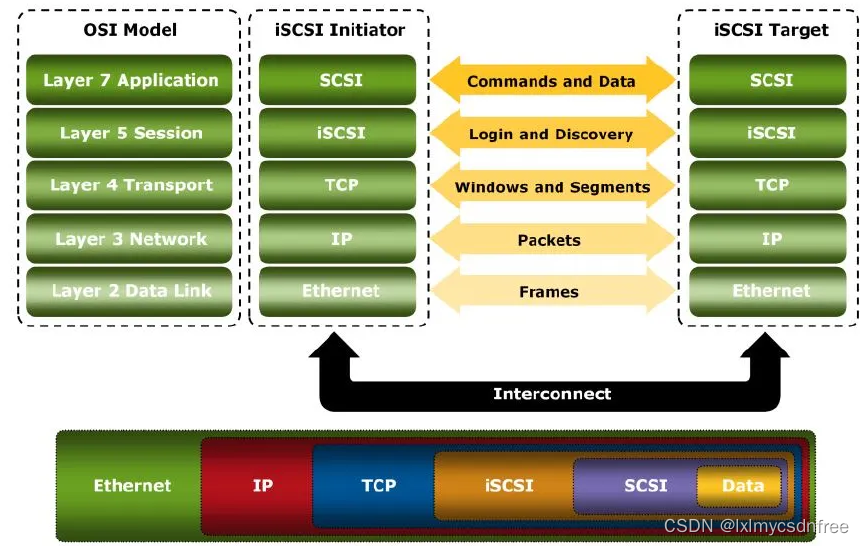
如上图所示,iSCSI (Internet SCSI)把SCSI命令和块状数据封装在TCP中在IP网络中传输。iSCSI作为SCSI的传输层协议,基本出发点是利用成熟的IP网络技术来实现和延伸SAN。 iSCSI协议是SCSI远程过程调用模型到TCP/IP协议的映射。SCSI协议层负责生成CDB,并将其送到iSCSI协议层,然后由 iSCSI协议层进一步封装成PDU,经IP网络进行传送。
iSCSI工作流程
◼ iSCSI系统由SCSI适配器发送一个SCSI命令。
◼ 命令封装到TCP/IP包中并送入到以太网络。
◼ 接收方从TCP/IP包中抽取SCSI命令并执行相关操作。
◼ 把返回的SCSI命令和数据封装到TCP/IP包中,将它们发回到发送方。
◼ 系统提取出数据或命令,并把它们传回SCSI子系统。
具体来讲,发起端(Initiator):
◼ SCSI层负责生成CDB(命令描述符块),将CDB传给iSCSI。
◼ iSCSI层负责生成iSCSI PDU(协议数据单元),并通过IP网络将PDU发给target。
目标器(Target):
◼ iSCSI层收到PDU,将CDB传给SCSI层。
◼ SCSI层负责解释CDB的意义,必要时发送响应。
总结 SCSI与ISCSI区别:
◼ iSCSI,即internet SCSI,是IETF制订的一项标准,用于将SCSI数据块映射成以太网数据包。从根本上说,iSCSI协议是一种跨过IP网络来传输潜伏时间短的 SCSI数据块的方法;简单的说, iSCSI可以实现在IP网络上运行SCSI协议,使其能够在诸如高速千兆以太网上进行路由选择。
◼ SCSI 的意义是小型计算机系统接口(Small Computer System Interface);今天的SCSI已划分为SCSI-1和SCSI-2,以及最新的SCSI-3三个类型。不过,目前最为流行的版本还要算是SCSI-2
iSCSI + Service API = RBD(Reliable Block Device)
四 什么是NUMA,我们为什么要了解NUMA
NUMA到底指的是什么?我们怎么可以感受到它的存在?以及NUMA的存在对于我们编程会有什么影响?今天我们一起来看一下。
NUMA(Non-Uniform Memory Access),即非一致性内存访问,是一种关于多个CPU如何访问内存的架构模型,早期,在计算机系统中,CPU是这样访问内存的:
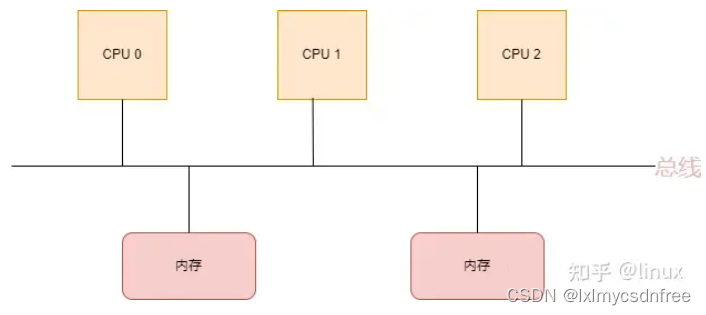

在这种架构中,所有的CPU都是通过一条总线来访问内存,我们把这种架构叫做SMP架构(Symmetric Multi-Processor),也就是对称多处理器结构。可以看出来,SMP架构有下面4个特点:
- CPU和CPU以及CPU和内存都是通过一条总线连接起来
- CPU都是平等的,没有主从关系
- 所有的硬件资源都是共享的,即每个CPU都能访问到任何内存、外设等
- 内存是统一结构和统一寻址的(UMA, Uniform Memory Architecture)
SMP架构在CPU核不多的情况下,问题不明显,有实验证明,SMP服务器CPU利用率最好的情况是2至4个CPU:(如上图右边)
但是随着CPU多核技术的发展,一颗物理CPU中集成了越来越多的core,导致SMP架构的性能瓶颈越来越明显,因为所有的处理器都通过一条总线连接起来,因此随着处理器的增加,系统总线成为了系统瓶颈,另外,处理器和内存之间的通信延迟也较大。
为了解决SMP架构下不断增多的CPU Core导致的性能问题,NUMA架构应运而生,NUMA调整了CPU和内存的布局和访问关系,具体示意如下图:

在NUMA架构中,将CPU划分到多个NUMA Node中,每个Node有自己独立的内存空间和PCIE总线系统。各个CPU间通过QPI总线进行互通。
CPU访问不同类型节点内存的速度是不相同的,访问本地节点的速度最快,访问远端节点的速度最慢,即访问速度与节点的距离有关,距离越远访,问速度越慢,所以叫做非一致性内存访问,这个访问内存的距离我们称作Node Distance。
虽然NUMA很好的解决了SMP架构下CPU大量扩展带来的性能问题,但是其自身也存在着不足,当Node节点本地内存不足时,需要跨节点访问内存,节点间的访问速度慢,从而也会带来性能的下降。所以我们在编写应用程序时,要充分利用NUMA系统的这个特点,尽量的减少不同CPU模块之间的交互,避免远程访问资源,如果应用程序能有方法固定在一个CPU模块里,那么应用的性能将会有很大的提升。
在Linux系统上,可以查看到NUMA架构下CPU和内存的分布情况,不过在这之前,我们先得理清几个概念:
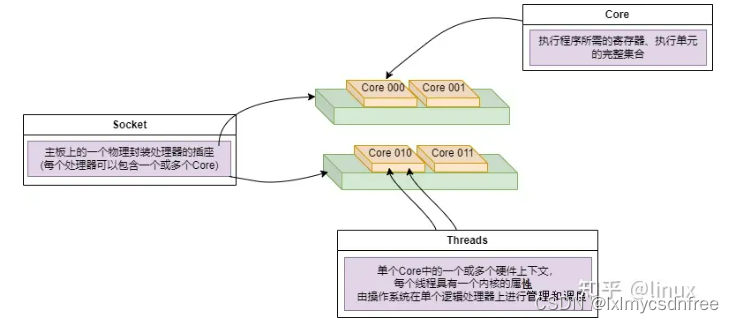
- Socket:表示一颗物理 CPU 的封装(物理 CPU 插槽),简称插槽。为了避免将逻辑处理器和物理处理器混淆,Intel 将物理处理器称为插槽,Socket表示可以看得到的真实的CPU核 。
- Core:物理 CPU 封装内的独立的一组程序执行的硬件单元,比如寄存器,计算单元等,Core表示的是在同一个物理核内逻辑层面的核。同一个物理CPU的多个Core,有自己独立的L1和L2 Cache,共享L3 Cache。
- Thread:使用超线程技术虚拟出来的逻辑 Core,需要 CPU 支持。为了便于区分,逻辑 Core 一般被写作 Processor。在具有 Intel 超线程技术的处理器上,每个内核可以具有两个逻辑处理器,这两个逻辑处理器共享大多数内核资源(如内存缓存和功能单元)。此类逻辑处理器通常称为 Thread 。超线程可以在一个逻辑核等待指令执行的间隔(等待从cache或内存中获取下一条指令),把时间片分配到另一个逻辑核。高速在这两个逻辑核之间切换,让应用程序感知不到这个间隔,误认为自己是独占了一个核。对于每个逻辑线程,拥有完整独立的寄存器集合和本地中断逻辑,共享执行单元和一二三级Cache,超线程技术可以带来20%~30%的性能提升。
- Node:即NUMA Node,包含有若干个 CPU Core 的组。
Socket、Core和Threads之间的关系示意如下:
在Linux系统中,可以用lscpu查看NUMA和CPU的对应关系:
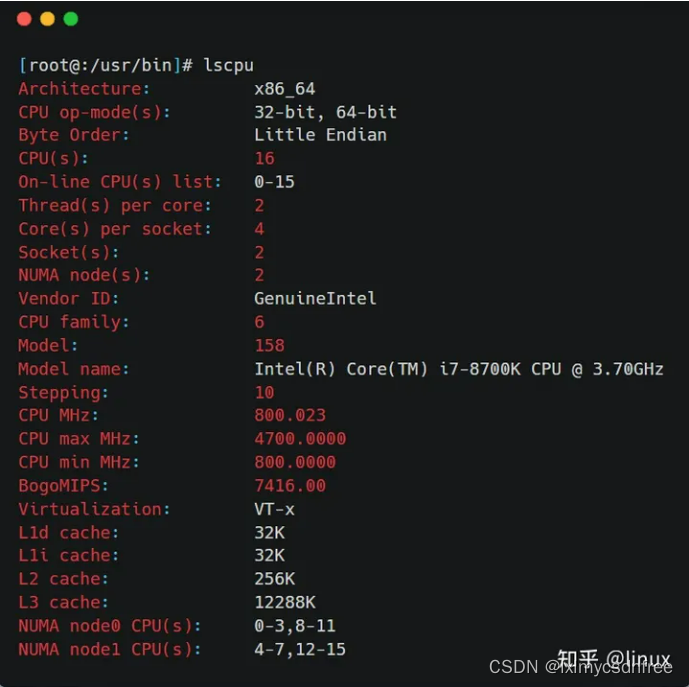
从上图可以看到,这台服务器有两个NUMA node,有两个Socket,每个Socket也就是一个物理CPU,有14个逻辑Core,每个逻辑Core有两个线程(服务器开启了超线程),所以总共的CPU个数(以超线程计数)为:2*14*2 = 56个。
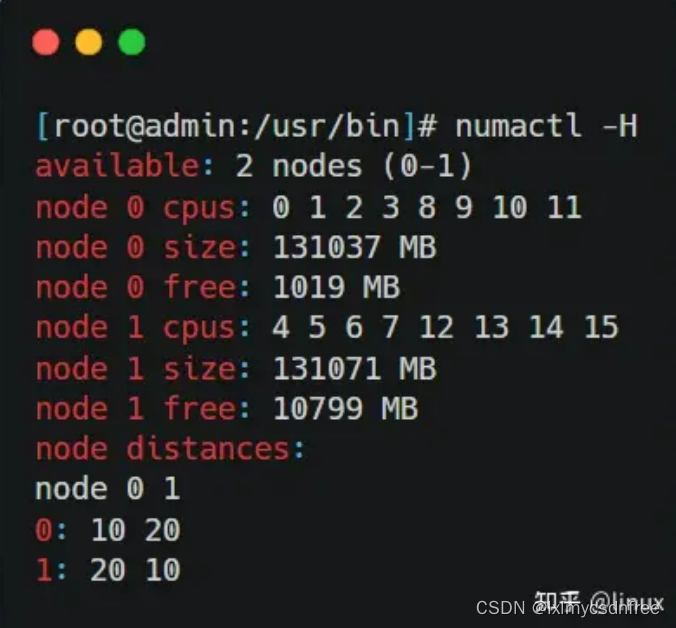
使用numactl -H命令可以看到NUMA下的内存分布:(上图右)
所以这台服务器上CPU和内存在NUMA下的分布如下:
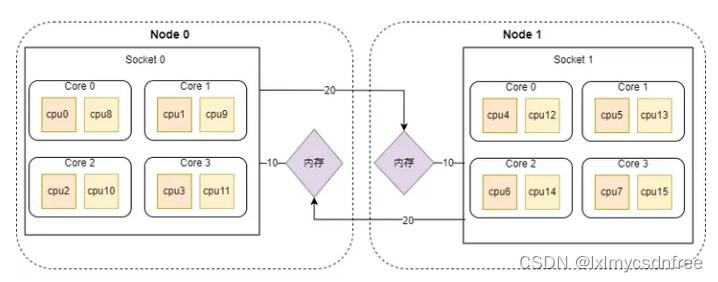
NUMA架构下的CPU,先从逻辑Core开始编号,如果开启了超线程,就从Core总数的后面继续编号,例如上图中从cpu8开始之后的都是开启超线程之后的CPU线程。
另外,在实际编程中,我们还可以通过numastat命令查看NUMA系统下内存的访问命中率:
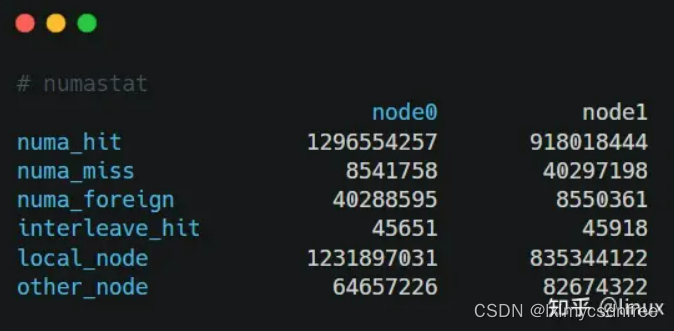
- numa_hit:成功分配给此节点的页面数量。
- numa_miss:由于预期节点上的内存较低,在此节点上分配的页面数量。每个 numa_miss 事件在另一个节点上都有对应的 numa_foreign 事件。
- numa_foreign:最初用于分配给另一节点的页面数量。每个 numa_foreign 事件在另一节点上都有对应的 numa_miss 事件。
- interleave_hit:成功分配给此节点的交集策略页面数量。
- local_node:此节点上的进程在这个节点上成功分配的页面数量。
- other_node:通过另一节点上的进程在这个节点上分配的页面数量。
如果miss值和foreign值越高,就要考虑线程绑定以及内存分配使用的问题。
需要注意的是,NUMA Node和socket并不一定是一对一的关系,在AMD的CPU中,可能更多见于NUMA Node比socket个数多(一般AMD的CPU的NUMA可以在BIOS中进行配置),而Intel的CPU中,NUMA Node可能比socket的个数还少。
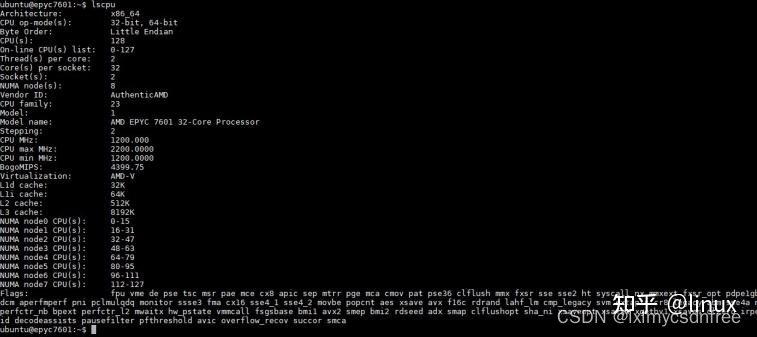
例如在下面这台服务器上,使用的是AMD的EPYC 7001,NUMA有8个,但是Socket只有两个:
NUMA架构下的编程
NUMA架构显著的特点就是CPU访问本地内存快,访问远程内存慢。所以我们在NUMA架构下编写程序,要扬长避短,多核多线程编程中,我们要尽可能的利用CPU Core的亲和性,将线程绑定到对应的CPU上,并且该线程从该CPU对应的本地内存上去申请内存,这样才能最大限度发挥NUMA架构的优势,达到比较好的处理性能。
简单来说,就是本地的处理器、本地的内存来处理本地的设备上产生的数据。如果有一个PCI设备(比如网卡)在Node0上,就用Node0上的核来处理该设备,处理该设备用到的数据结构和数据缓冲区都从Node0上分配。
在DPDK中,有一个rte_socket_id()函数,可以获取当前线程所在的NUMA Node,在使用DPDK提供申请内存的接口中,一般都需要传入参数NUMA id,也是基于提高NUMA架构下的报文转发性能考虑。
- 我:(1)maven包:
赞
踩

