
- 1重要!关系你我 | 人工智能引发的就业危机
- 2BOSS 直聘:日增10亿数据的历史库,如何通过OceanBase节省70%存储成本?
- 3TreeSelect可搜索_treeselect 筛选
- 4案例20:Java物流管理系统设计与实现开题报告_java快递运输管理论文开题报告应该怎么写
- 5http协议
- 6保姆级讲解Python爬虫+爬取淘宝数据案例_爬取淘宝商品数据
- 7免费分享一套微信小程序外卖跑腿点餐(订餐)系统(uni-app+SpringBoot后端+Vue管理端技术实现) ,帅呆了~~_跑腿或点餐的uniapp前端模版
- 8如何制作知识付费课程?_知乎如何设置付费视频
- 9Win11控制面板快捷键 Win11打开控制面板的多种方法
- 10JavaScript:实现将 base64 字符串转换为字节数组算法(附完整源码)_js 把base转字节集
实测AIGC工作流,Stable Diffusion + Mubert 实现图片与音乐的转换生成
赞
踩
社区分享了不少文本生成图像的AIGC(AI生成内容)应用的突破,图像类的生成已经是“红海”了。
我们需要寻找“蓝海”,近期出现了其他内容的突破吗?

Mixlab

小杜
社区五月份介绍了 Pollinations.ai ,平台集成了文本、图像、音频、视频等多种模态的模型,近期平台功能也进行了迭代升级,但在模型内容质量上还是参差不齐。
最近热度最高的开源模型是 Stable Diffusion,其极为优秀的开源生态也催生了许多模型的整合创新。Stable Diffusion + Mubert 就实现了高质量的图像到音乐的生成。尤其是图片转音乐,不是那种抽象电子风,而是真正具备了应用级配乐的水准!(请看下文)
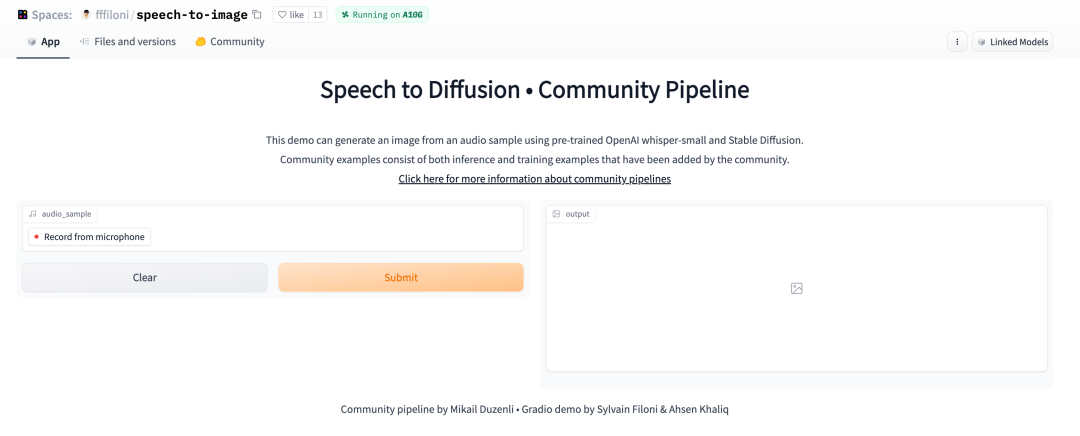
speech-to-image
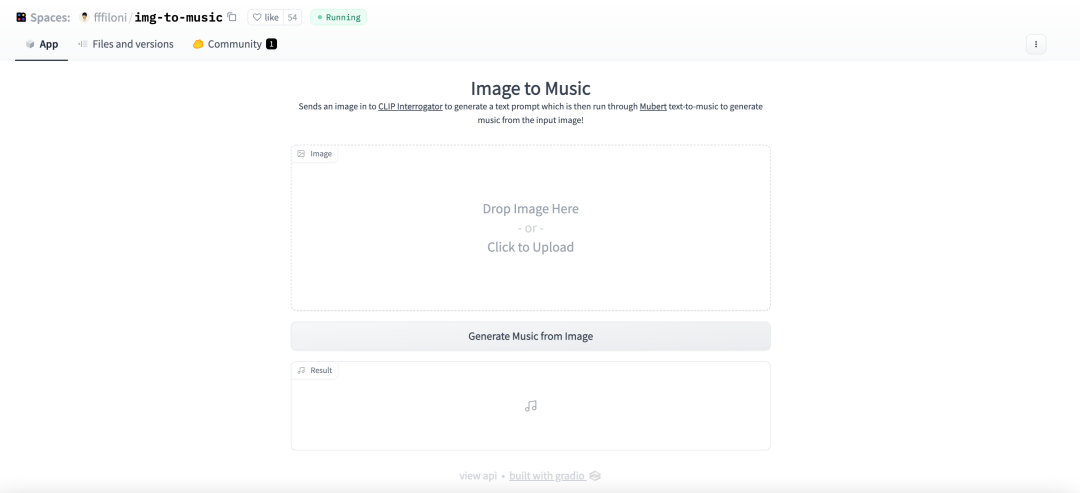
img-to-music

小杜
speech-to-image demo 使用预先训练的 OpenAI whisper-small 与 Stable Diffusion 从音频样本生成图像。img-to-music 则是发送图像到剪辑询问器 CLIP Interrogator 生成文本提示,然后通过 Mubert 识别文本输出音乐,实现输入图像到生成音乐的过程。
带我们看看测试效果?

Mixlab

小杜
speech-to-image ,我测试了三类声音到图像的生成
# 人声哼唱(小编的瞎哼)
# 流行音乐 (Golden Hour 前奏+一丢丢人声)
# 环境自然音(小编嘈杂的居住环境)
#01 人声哼唱

#02 流行音乐

#03 环境音

......

小杜
出乎意料的惊喜!对于我们人类,与为文字配插画相比,为音乐配
图似乎是件更为困难的事。音乐的抽象特征与AI生成的特质意外的契合。
AI给第一个哼唱生成了一幅略显俏皮的圣诞老人形象,似乎有点在嘲讽我哼唱得五音不全hh。第二个流行歌曲,AI应该是识别出了歌曲的关键词 “Love” ,虽说没太拼对,但有种为爱情冲昏了头脑的感觉。第三个环境音嘈杂而没有感情色彩,AI也生成了一幅比较契合的黑白色调的拼贴画。
反过来,图像生成音乐是啥效果?

Mixlab

小杜
那可更惊喜了!我找的音频素材可没AI生成的惊艳~同样也测试了三类图片生成的音乐-
# 音频生成的图像
# Stable Diffusion 文本生成的图像
# 艺术画作
#01 音频生成的图像

#02 文本生成的图像

#03 名画千里江山图局部

......

小杜
真是一个比一个惊喜!第一张图是测试 Golden Hour 音频转图像生成的图,反过来生成了有点迷幻电子风的音乐。第二张是用SD生成的概念汽车场景,AI较为精准地 “理解了” 画面内容,生成了科幻枪战的配乐。第三个则是震惊到我了,AI尽然为我挑选的千里江山图生成了有乐章结构的中国风音乐!
Stable Diffusion 的开源生态已经不局限于图像了。在文本-音乐生成模型 Mubert 实现图像-音乐的工作流中,文本是在哪一步生成的呢?

Mixlab

小杜
img-to-music 使用了 CLIP Interrogator 来生成图像的文字,再通过 Mubert 实现文本转音乐。
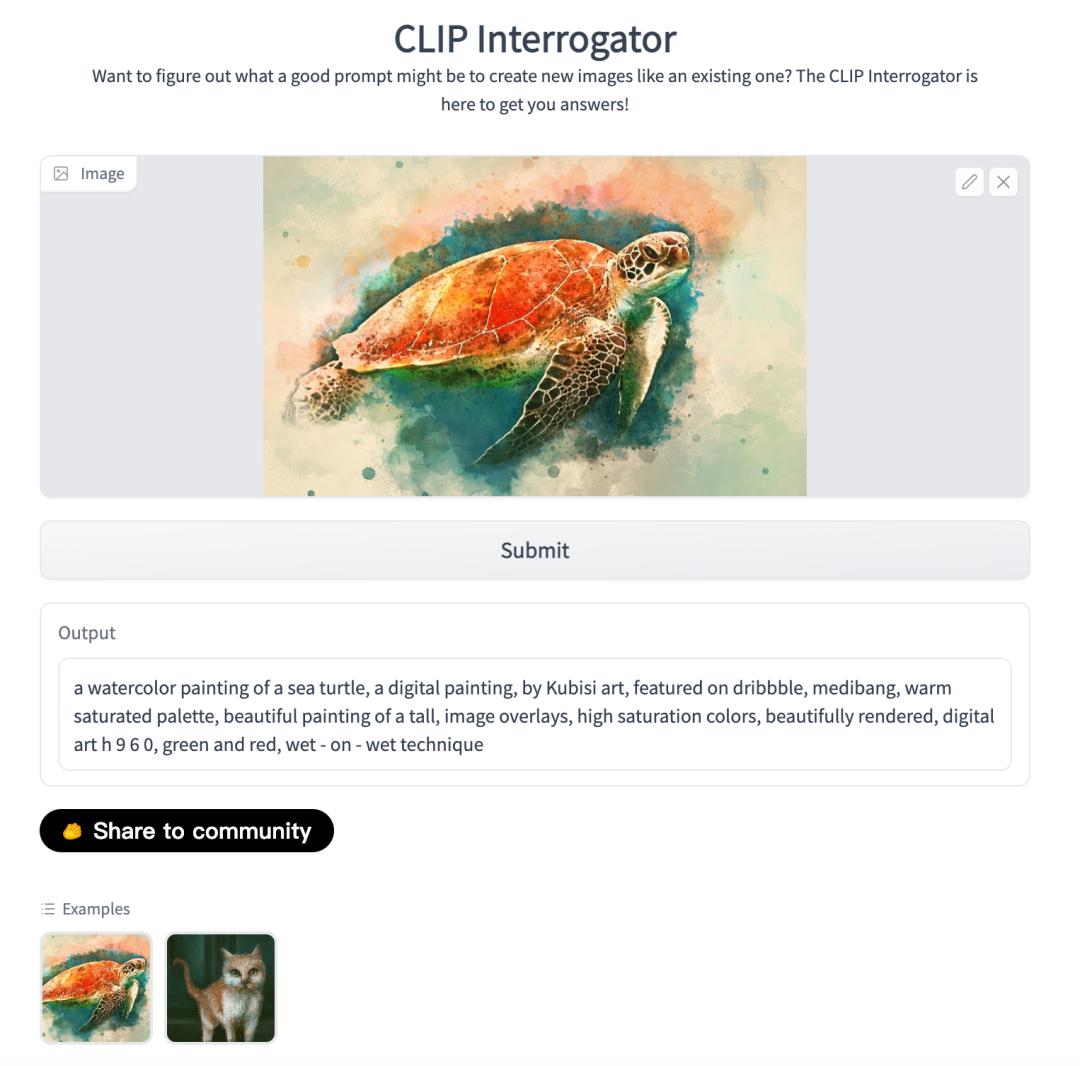
图像转文本模型demo
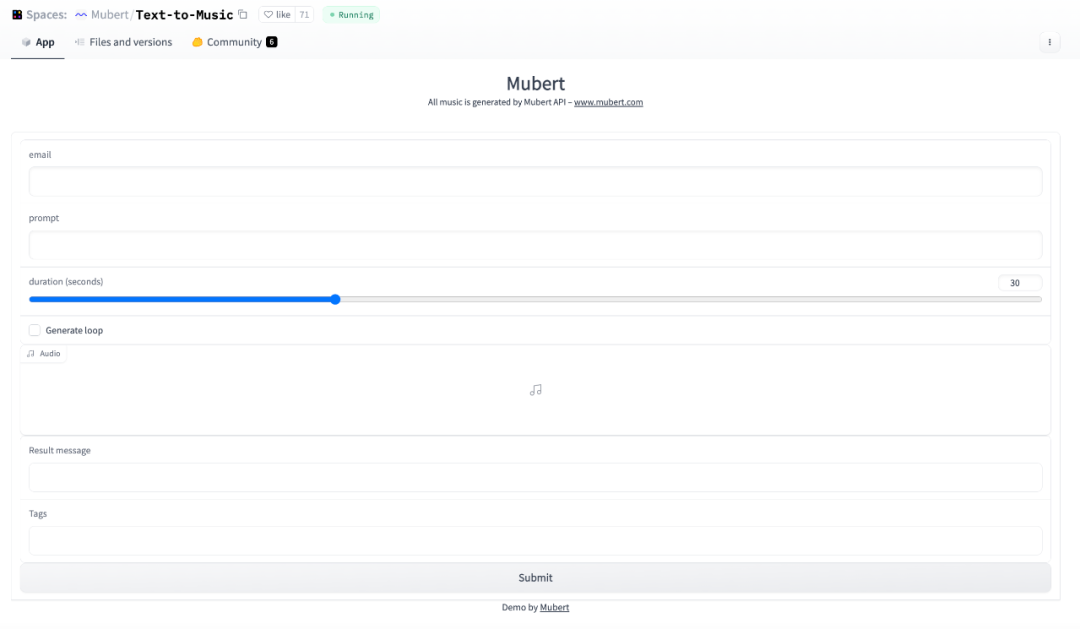
文本转音频demo

小杜
img-to-music 作者 @fffiloni 也展示了他产出的一些输出探索,非常奇妙~
图像转音频 demo

小杜
以 img-to-music 为线索,我找出了 Stable Diffusion 较完善的扩展应用模型集成,大家感兴趣也可以自主尝试基于SD模型的应用扩展创新哦~
speech-to-image demo:
huggingface.co/spaces/fffiloni/speech-to-image
Image to Music demo:
huggingface.co/spaces/fffiloni/img-to-music
CLIP Interrogator:
huggingface.co/spaces/pharma/CLIP-Interrogator
Mubert demo:
huggingface.co/spaces/Mubert/Text-to-Music
Mubert 项目地址:
github.com/MubertAI/Mubert-Text-to-Music
SD 扩展模型应用集成:
github.com/huggingface/diffusers/tree/main/examples/community#speech-to-image

小杜
更多有关AIGC最新突破的知识信息,欢迎查阅社群知识库哦~
【双11优惠】元宇宙知识库只需139元
下一期我们再卷卷视频?来点动态内容,AIGC 啥都玩一遍hhh

Mixlab

opus
欢迎留言讨论,参与 AIGC 话题的共创共建~

添加请备注AIGC & 元宇宙

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

