
- 1深度学习利用RCNN识别不定长计算题验证码(pytorch版,LSTM + CTCLoss)_深度学习识别不定长数组
- 2奔三女程序员不禁三思,“中年危机,移动app应用开发
- 3理解numpy mean(axis=?)_x.mean(axis=0)
- 4element-ui树形控件el-tree详解
- 5正则表达式 验证YYYY-MM-DD HH:mm:ss,包含闰年验证(包含世纪年和普通闰年)_正则表达式验证yyyy-mm-dd hh:mm:ss
- 6Unity 2018.3.8 f1 个人版的Standard Assets在哪里下载?
- 7【华为OD机试真题 JS语言】197、农场施肥、不爱施肥的小布 | 机试真题+思路参考+代码分析
- 8C# =>实用详解_c# =>
- 9Confluence与Jira整合之统一用户管理_confluence启用外部用户管理
- 102020-08-31 2020常用面试题_dialog所在activity stop
线性回归知识点_线性回归知识点整理总结
赞
踩
线性回归是什么
是一种预测模型,利用各个特征的数值去预测目标值。线性回归的主要思想是给每一个特征分配一个权值,最终的预测结果是每个特征值与权值的乘机之和再加上偏置。所以训练的目标是找到各个特征的最佳权值和偏置,使得误差最小。线性回归的假设前提是噪声符合正态分布。线性回归也可以做分类,但是效果不好。
线性回归的五大假设
https://blog.csdn.net/Noob_daniel/article/details/76087829
1.特征和标签呈线性关系。
2.误差之间相互独立
3.自变量相互独立
4.误差项的方差应为常数
5.误差呈正态分布
线性回归要求因变量符合正态分布?
是的。线性回归的假设前提是特征与预测值呈线性关系,误差项符合高斯-马尔科夫条件(零均值,零方差,不相关),这时候线性回归是无偏估计。噪声符合正态分布,那么因变量也符合分布。在进行线性回归之前,要求因变量近似符合正态分布,否则线性回归效果不佳(有偏估计)。
如何判断数据是否符合正态分布?将数据转化成符合正态分布的方法。
看一下这个非正态转化成正态:https://zhuanlan.zhihu.com/p/49467973?utm_source=wechat_session
看峰度和偏度。若偏度大于3倍标准差,则需要进行处理。 偏度大于3倍标准差,可以进行log变换。 2-3倍,可以进行根号处理。
损失函数是啥: 最小均方误差,MSE 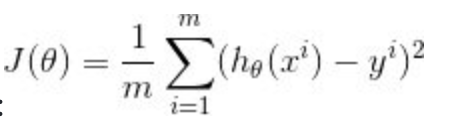
为什么使用这个损失函数?
线性回归损失函数为什么要用平方形式?【】
为什么使用最小均方误差【最大化似然公式L(θ)相当于最小化,最终变成最小二乘问题】
使得所有样本到直线上的欧式距离之和最小。这个想法和分类问题是正好相反的,分类问题是找到一个分界面离所有样本尽可能远

线性回归求解方法
(1)公式法,损失对w和b进行求导,倒数为0,然后求解w和b。(需要时满秩矩阵,样本数量要大于特征数量)
(2)优化方法,初始化w和b,然后使用优化方法不断进行优化求解。通常使用梯度下降法。
简要介绍一下线性回归处理步骤,怎么确定因变量与自变量间线性关系,什么情况下可停止迭代,怎么避免过拟合情况?
一般来说缺失值处理、类别变量数值化,异常值处理,连续特征离散化(数据分桶)等等,当两次迭代所带来的增益小于事先给定的阈值时,或者达到事先设定的最大迭代次数,则停止迭代过程,过拟合没法避免只能说是尽量降低过拟合的影响,通过l1、l2正则化、减少特征的数量、增大样本的数量等等。
最小二乘/梯度下降手推
当x矩阵是列满秩的时候,可以用最小二乘法,但是求矩阵的逆比较慢
梯度下降法,以最大似然估计的结果对权值求梯度,sigmoid函数也是如此

lasso 回归【L1loss】与ridge 岭回归【L2 loss】
解决普通线性回归过拟合问题。解决方程求解法中的非满秩矩阵无法求解问题。约束参数
LASSO: 特征过多,稀疏线性关系,目的为了在一堆特征里面找出主要的特征
RIDGE:样本数少,或者样本重复程度高
你可以引用ISLR的作者Hastie和Tibshirani的话,他们断言在对少量变量有中等或大尺度的影响的时候用lasso回归。在对多个变量只有小或中等尺度影响的时候,使用Ridge回归。
从概念上讲,我们可以说,Lasso回归(L1)同时做变量选择和参数收缩,而ridge回归只做参数收缩,并最终在模型中包含所有的系数。在有相关变量时,ridge回归可能是首选。此外,ridge回归在用最小二乘估计有更高的偏差的情况下效果最好。因此,选择合适的模型取决于我们的模型的目标。

线性回归不好的原因
1.普通线性回归易过拟合,使用LASSO或者RIDGE回归试试.
2.数据不符合线性回归的假设。
3.特征工程要不再搞搞?
选择题 下列关于线性回归说法错误的是(D)
A.在现有模型上,加入新的变量,所得到的R^2的值总会增加
B.线性回归的前提假设之一是残差必须服从独立正态分布
C.残差的方差无偏估计是SSE/(n-p)
D.自变量和残差不一定保持相互独立
为什么进行线性回归前需要对特征进行离散化处理。
1.离散化操作很easy,特征离散化之后易于模型的快速迭代。
2.稀疏矩阵计算快,省内存。
3.鲁棒性强。单个特征数值过大或者过小对结果的影响会被降低。
4.可以产生交叉特征(相当于非线性了)
5.模型的稳定性加强了。
6.简化了模型,相当于降低了过拟合的风险
回归常用的指标
1)均方误差MSE:是反映估计值与被估计量之间差异程度的一种度量。
2)RMSE均方根误差:观测值与真值偏差的平方和与观测次数m比值的平方根,用来衡量观测值同真值之间的偏差。
3)SSE和方误差
4)MAE:直接计算模型输出与真实值之间的平均绝对误差
5)MAPE:不仅考虑预测值与真实值误差,还考虑了误差与真实值之间的比例。
6)平均平方百分比误差
7)决定系数
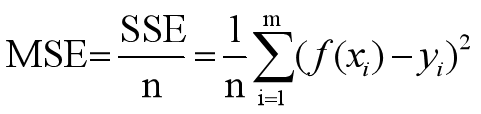
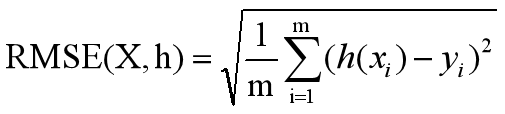
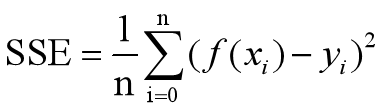
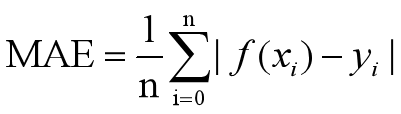
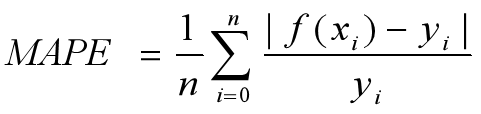
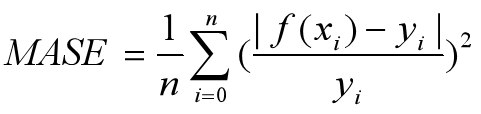

使用方法
sklearn.linear_model.linerregression算法
数学上:
Y= WTX+b


