
- 1酷开科技以酷开系统为媒介,打造欢乐生活场景
- 2微信小程序使用scroll-view自定义下拉刷新_uni-app scroll-view 真机模式开启自定义刷新 会出现下方多出一部分空白
- 3Over 100 Data Science Interview Questions 北美数据科学面试题和参考答案_北美分析师面试问题及答案
- 4Java全栈体系路线(总结不易,持续更新中)_java全栈知识体系
- 5VS Code 用作嵌入式开发编辑器_vscode嵌入式开发
- 6fork函数详解与进程替换(exec)_fork函数 和进程替换函数
- 7Docker系列之相关概念_被动挂载
- 8如何在Mac 终端升级ruby版本_mac ruby更新
- 9TCP 发送机制_每次发送1024字节
- 10通过node-red实现mqtt通讯_node-red mqtt
使用基于LLM的CrewAI代理执行数据科学任务 尝试使用代理执行数据科学活动_crewai部署环境
赞
踩
使用基于LLM的CrewAI代理执行数据科学任务
尝试使用代理执行数据科学活动

由DALL-E 3生成的图像
基于LLM的代理或LLM代理是一种能够执行具有将LLM与规划和记忆等组件相结合的架构的LLM应用程序的复杂任务的代理结构。简单来说,LLM代理是一个工具,其中LLM是大脑,用于协调决策以实现目标。
其中一个易于使用的基于LLM的代理框架是CrewAI。通过使用代理并启动任务,我们可以自动执行复杂的分析来解决问题。对于需要进行复杂分析以开发模型的数据科学家来说,这是一个有趣的前景。
我想尝试一下CrewAI是否能够执行数据科学任务。那么,让我们开始吧。
CrewAI的使用
我们需要做的第一件事是安装CrewAI。您可以通过在命令行中执行以下代码来完成。
pip install crewai
- 1
然后,让我们尝试使用CrewAI代理来处理我们的工作。我还会一路上解释示例中的组件。此外,我将使用以下电信流失Kaggle数据集作为示例。
首先,我们需要设置环境以接受OpenAI API密钥。CrewAI代理可以使用各种LLM,但为了简单起见,我们将使用默认的GPT模型。为此,我们将使用以下代码。
import os
from crewai import Agent, Task, Crew, Process
os.environ["OPENAI_API_KEY"] = "YOUR OPENAI API KEY"
- 1
- 2
- 3
- 4
设置好环境后,让我们看看我们有哪些数据集。
import pandas as pd
df = pd.read_csv('/content/telecom_churn.csv')
- 1
- 2

作者提供的图像
数据集中有各种列,其中“Churn”列是目标列。这是一个试图对客户是否流失进行分类的数据集。然而,我希望尽量减少GPT的标记使用,因为GPT可以接受的标记数量是有限的。
对于这个实验,我将取100个样本行和仅三列来测试CrewAI。
df[['Churn', 'AccountWeeks', 'ContractRenewal']].sample(100).reset_index(drop = True).to_csv('100_samples_telecom_churn.csv', index = False)
- 1
我将文件保存为CSV文件,以便CrewAI代理稍后可以读取它们。数据准备好后,让我们尝试一下这些工具。
我们要启动的第一个工具是用于读取CSV文件的工具。
from langchain_community.document_loaders.csv_loader import CSVLoader
from langchain.agents import Tool
loader = CSVLoader(file_path="/content/100_samples_telecom_churn.csv")
load_tool = Tool(
name="数据加载工具",
func=loader.load,
description="从源中加载CSV数据",
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
上面的代码将使用LangChain的CSVLoader来读取CSV文件。CrewAI代理无法直接执行Python代码,因此它们需要外部工具来促进这个过程。在上面的代码中,我们传递了存储流失数据的文件路径,并将它们传递给Tool对象。
处理完成后,让我们尝试一下CrewAI代理框架。为此,我们需要为实验设置代理。在第一次测试中,我们将尝试代理是否能够读取数据并对其进行分析;然后将结果开发为博客文章。
从流失数据集创建博客文章
在下面的代码中,我将启动代理。
# 定义具有角色和目标的代理 analyst = Agent( role='高级数据分析师', goal='加载数据集并从数据中提供见解', backstory="""您在一家电信公司工作。 您的专长是从可用数据中识别趋势和分析。 您擅长剖析复杂数据并提供可操作的见解。""", verbose=True, allow_delegation=False ) writer = Agent( role='数据内容策划师', goal='从数据中制作引人入胜的内容', backstory="""您是一位著名的数据作家,以 您对数据集的深入见解和引人入胜的文章而闻名。 您将复杂的概念转化为引人入胜的叙述。""", verbose=True, allow_delegation=False, )

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
上面的代码显示了我们初始化了两个不同的代理:一个分析师和一个作家。通过代理,我们可以定义他们的角色,目标和背景故事。每个参数都提供了我们的代理在给定任务时如何行动。
接下来,我们将初始化代理执行任务。在此示例中,我们将使用简单的顺序任务,其中每个代理执行一个不同的任务。
# 为我们的代理创建任务 task1 = Task( description="""使用提供的工具从CSV数据集中进行全面分析。 您只需要运行工具,而无需提供任何输入,因为工具已经嵌入了源数据路径。 确定与流失相关的任何分析。 您的最终答案必须是完整的分析报告""", agent=analyst, tools = [load_tool] ) task2 = Task( description="""根据提供的见解,开发一个引人入胜的博客 文章,以突出您的发现。 您的文章应该对普通人来说具有信息性,不要让它听起来像是AI。 您的最终答案必须是至少3段的完整博客文章。""", agent=writer )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
在上述任务中,我们描述了第一个任务,即特定代理使用可用的工具加载数据集并分析数据。第二个任务是根据从第一个任务中获得的见解提供博客文章。
准备好代理和任务后,我们将启动Crew以运行整个过程。
crew = Crew(
agents=[analyst, writer],
tasks=[task1, task2],
verbose=2,
)
result = crew.kickoff()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
由于我们设置了详细模式以允许详细记录过程,我们可以看到正在发生的过程。在下面的图像中,我向您展示了分析师正在使用工具读取CSV数据集并从数据中提供见解。
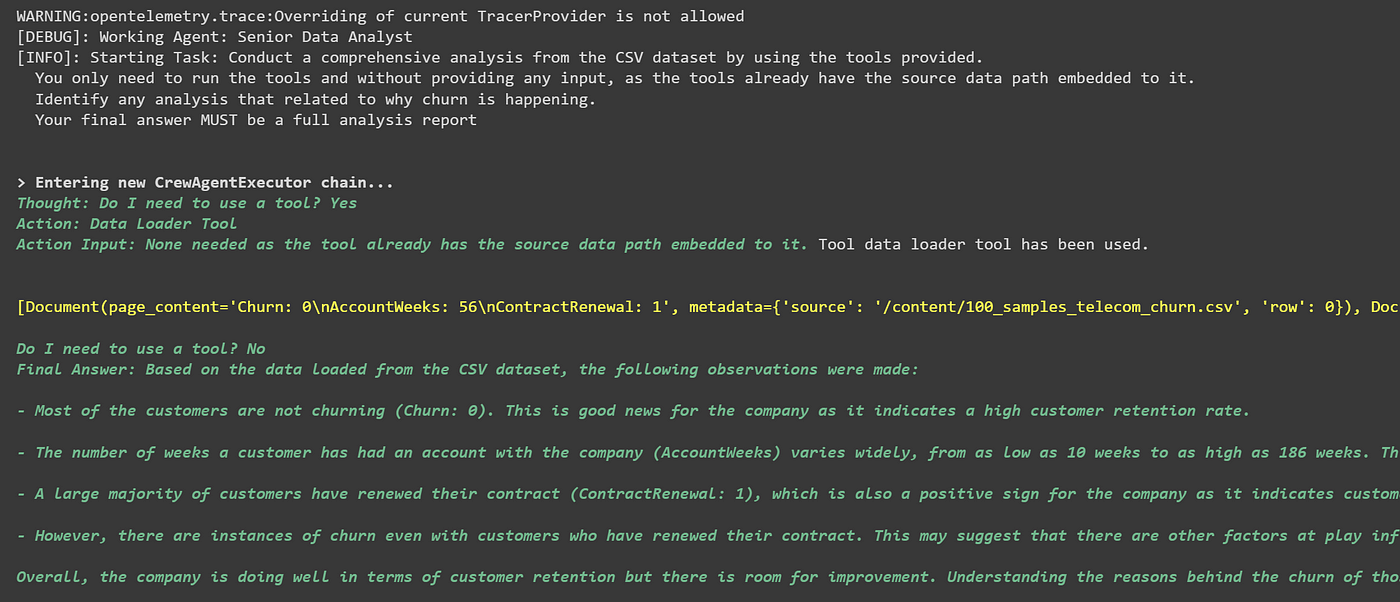
作者提供的图像
在下一部分中,我们可以看到作家开始根据给定的见解撰写博客文章。
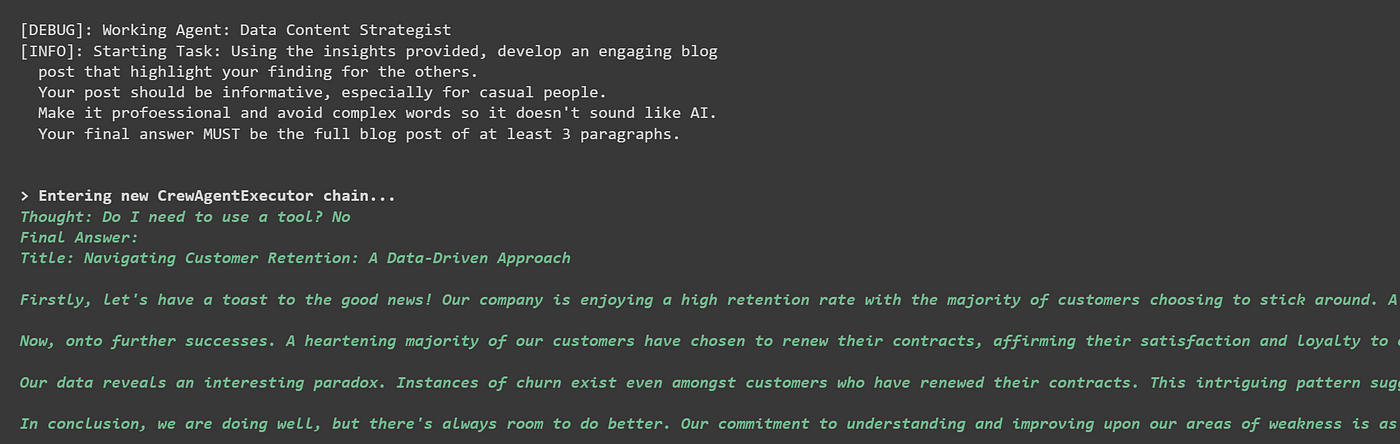
作者提供的图像
CrewAI能够读取数据集并成功执行任务。让我们尝试其他实验。在下一部分中,我们将尝试代理分析数据、开发机器学习模型并部署模型。
开发和部署机器学习模型
对于数据科学任务,我们需要创建与之前的代理行为不同的新代理。为此,我们可以使用以下代码。
# 定义具有角色和目标的代理 analyst = Agent( role='高级数据分析师', goal='加载数据集并从数据中提供见解', backstory="""您在一家电信公司工作。 您的专长是从可用数据中识别趋势和分析。 您擅长剖析复杂数据并提供可操作的见解。""", verbose=True, allow_delegation=False, tools=[load_tool] ) data_scientist = Agent( role='高级数据科学家', goal='根据预定目标开发最佳的机器学习模型', backstory="""您是一位著名的数据科学家,以 您在Python中高度创新的机器学习模型而闻名。 您将数据转化为机器学习模型可以接受的形式,并基于此开发机器学习模型。""", verbose=True, allow_delegation=False, ) machine_learning_engineer = Agent( role='高级机器学习工程师', goal='创建最佳的代码来部署机器学习模型', backstory="""您是一位经验丰富的机器学习工程师,拥有大量部署机器学习模型的经验。 您将尽力根据提供的代码部署模型。""", verbose=True, allow_delegation=False, )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
在上面的代码中,我们添加了两个不同的代理,即数据科学家和机器学习工程师。数据科学家将开发模型,而机器学习工程师将部署模型。
接下来是创建任务。
task1 = Task( description="""使用提供的工具从CSV数据集中进行全面分析。 您只需要运行工具,而无需提供任何'tool_input',因为工具已经嵌入了源数据路径。 确定与流失相关的任何分析。 您的最终答案必须是带有可视化的完整分析报告""", agent=analyst ) task2 = Task( description="""根据提供的见解,开发一个机器学习模型来预测流失。 该模型应遵循机器学习的最佳实践,特别是从预处理到验证。 您的最终答案必须是完整的Python代码,只有Python代码,没有其他内容。 """, agent=data_scientist, expected_output = "用于预测流失的机器学习模型的完整Python代码" ) task3 = Task( description="""从您获得的代码中,开发一个Python代码来在生产应用程序中部署机器学习模型。 模型部署应遵循最佳实践。 模型对象应为输出。 从简单开始,如果需要的话再进行迭代。 您的最终答案必须是从机器学习开发到模型部署的完整Python代码,只有Python代码,没有其他内容。 """, agent=machine_learning_engineer, expected_output = "用于部署机器学习模型的Python代码", context = [task2] ) 对于这个任务,我没有为代理程序提供执行Python代码的工具,所以我要求代理程序将结果作为完整的Python代码提供。此外,任务3需要任务2的输出,因此我们通过`context`参数传递了`task2`。 一切准备就绪后,我们将在下面的代码中设置流程。 ```python crew = Crew( agents=[analyst, data_scientist, machine_learning_engineer ], tasks=[task1, task2, task3], verbose=2, ) result = crew.kickoff()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
与之前的代理程序类似,数据科学家将提供完整的Python代码来开发分类模型。
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report, confusion_matrix, accuracy_score # 加载数据 df = pd.read_csv('data.csv') # 预处理 # 将'Churn'列转换为二进制 df['Churn'] = df['Churn'].apply(lambda x: 1 if x == 'Yes' else 0) # 将数据分为'X'特征和'y'目标标签集 X = df[['AccountWeeks', 'ContractRenewal']] y = df['Churn'] # 将数据分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 通过去除均值并缩放到单位方差来标准化特征 sc = StandardScaler() X_train = sc.fit_transform(X_train) X_test = sc.transform(X_test) # 建模 # 使用逻辑回归作为简单的流失预测模型 model = LogisticRegression() model.fit(X_train, y_train) # 预测 y_pred = model.predict(X_test) # 评估 print('分类报告:\n',classification_report(y_test, y_pred)) print('混淆矩阵:\n',confusion_matrix(y_test, y_pred)) print('准确率:',accuracy_score(y_test, y_pred))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
[DEBUG]: [高级数据科学家] 任务输出:
# 导入库 import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report, confusion_matrix, accuracy_score # 加载数据 df = pd.read_csv('data.csv') # 预处理 # 将'Churn'列转换为二进制 df['Churn'] = df['Churn'].apply(lambda x: 1 if x == 'Yes' else 0) # 将数据分为'X'特征和'y'目标标签集 X = df[['AccountWeeks', 'ContractRenewal']] y = df['Churn'] # 将数据分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 通过去除均值并缩放到单位方差来标准化特征 sc = StandardScaler() X_train = sc.fit_transform(X_train) X_test = sc.transform(X_test) # 建模 # 使用逻辑回归作为简单的流失预测模型 model = LogisticRegression() model.fit(X_train, y_train) # 预测 y_pred = model.predict(X_test) # 评估 print('分类报告:\n',classification_report(y_test, y_pred)) print('混淆矩阵:\n',confusion_matrix(y_test, y_pred)) print('准确率:',accuracy_score(y_test, y_pred))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
此外,还有部署模型的方法。
# 导入库 import pandas as pd import pickle from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report, confusion_matrix, accuracy_score from flask import Flask, request, jsonify # 加载数据 df = pd.read_csv('data.csv') # 预处理 # 将'Churn'列转换为二进制 df['Churn'] = df['Churn'].apply(lambda x: 1 if x == 'Yes' else 0) # 将数据分为'X'特征和'y'目标标签集 X = df[['AccountWeeks', 'ContractRenewal']] y = df['Churn'] # 将数据分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 通过去除均值并缩放到单位方差来标准化特征 sc = StandardScaler() X_train = sc.fit_transform(X_train) X_test = sc.transform(X_test) # 建模 # 使用逻辑回归作为简单的流失预测模型 model = LogisticRegression() model.fit(X_train, y_train) # 将模型保存到磁盘 filename = 'finalized_model.sav' pickle.dump(model, open(filename, 'wb')) # 将缩放器保存到磁盘 scaler_filename = 'scaler.sav' pickle.dump(sc, open(scaler_filename, 'wb')) # 从磁盘加载模型 loaded_model = pickle.load(open(filename, 'rb')) loaded_scaler = pickle.load(open(scaler_filename, 'rb')) # 使用Flask来提供模型 app = Flask(__name__) @app.route('/predict', methods=['POST']) def predict(): data = request.get_json(force=True) data_scaled = loaded_scaler.transform([data['input']]) prediction = loaded_model.predict(data_scaled) return jsonify(prediction=int(prediction[0])) if __name__ == '__main__': app.run(port=5000, debug=True) """ 这段代码将训练好的模型和缩放器保存到磁盘。 然后,它加载模型并使用Flask Web框架提供模型。 `/predict`端点接受带有输入数据的POST请求, 使用保存的缩放器对输入数据进行缩放, 使用加载的模型进行预测, 并将预测结果作为JSON响应返回。 """
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
正如你所看到的,代码非常简单,缺乏任何数据科学实验。也许如果我们添加更多工具或更好的提示,代理程序可以做到这一点。然而,至少我们可以看到代理程序可以执行数据科学活动。
结论
CrewAI是一个基于LLM的框架,用于执行基于代理程序的复杂任务。在本文中,我向您展示了CrewAI能够执行数据科学任务,但可能还不够优化。
我会继续进行进一步的实验,但目前我们可以看到CrewAI如何执行数据科学任务。我可能会写一篇后续文章来详细介绍,敬请关注。

