
- 1安卓系统--翻译手机rom语言 添加多国语言 编译apk 反编译ODEX 工具步骤解析_安卓系统增加语言包的方法
- 2基于Springboot框架黑龙江哈尔滨某大学二手物品交易系统设计与实现 研究背景和意义、国内外现状
- 3VsCode上运行Flutter项目_vscode运行flutter项目模拟器打开只有一个手机看不到页面
- 4urlconnection 获取响应头_java – 如何从HttpURLConnection中读取完整的响应?
- 5Vue3---组件全局注册_vue3注册全局组件
- 6NAPI机制分析_napi_struct
- 7I.MX6Q(TQIMX6Q/TQE9)学习笔记——内核启动与文件系统挂载_leds-gpio: probe of leds failed with error -16
- 8c++——进程与线程的区别_c++ 线程和进程的区别
- 9java相关软件(ieda,jdk8)及配置(环境变量)
- 10PG 数据库锁表问题_pg数据库查询锁表
云上业务一键性能调优,应用程序性能诊断工具 Btune 上线
赞
踩

- 01 -
终于等来了预算,这就把服务迁移到最新的 CPU 平台上去,这样前端的同事立马就能感受我们带来的速度提升了。可是…… 这些性能指标怎么回事?不仅没有全面提升,有些反而下降了。不应该这样啊,这可怎么办?
花费了几个月时间终于搞定了业务模块的重构,立刻部署升级让业务焕然一新。可是……长尾延迟居然还增加了一倍,说好的业务效果提升呢,到底是哪里出了问题?
上面的这些问题,对于开发运维工程师来说一定不陌生,经常被这类出乎意料的状况打个措手不及。但是,性能优化是一项高技术门槛的工作,这通常需要运维人员有丰富的系统知识和经验,对业务反复进行分析、定位、测试、验证。遇到麻烦的 case,有时候可能需要花费数周时间。如果团队中缺乏这类运维人员,那就只能盯着性能指标下降却没有有效的方法,最后影响了业务上线效果。
在将业务迁移至不同计算平台,或者进行新业务上线的过程中,为了能够完全发挥计算平台的能力,及时找出性能瓶颈,对系统进行全面优化,百度智能云推出了「应用程序性能诊断工具 Btune」。
就像电脑管家可以快速对 PC 进行性能优化,Btune 能够对云上业务进行一键性能调优,短时间内完成性能瓶颈的定位并提供优化建议,使得初级运维人员可以胜任高技术门槛的性能调优工作。
源自百度智能云多年在各种服务器 CPU(Intel、AMD、ARM) 和多类业务(推荐、搜索、广告、大数据、数据库、视频编解码等)上的性能调优经验,Btune 支持多维度应用性能分析,可以自动生成优化建议提高应用性能,并提供可视化分析数据展示。
- 02 -
Btune 内置了百度自研的瓶颈分析树模块,通过自顶向下的方式,从 CPU、内存、磁盘、网络、并发等 5 个维度对业务应用进行性能剖析和瓶颈定位,并从应用、runtime、系统、硬件等多个层次对每个瓶颈给出可操作的优化建议。
借助 Btune 的专业能力,用户不仅能知道性能问题的根因,还能获得问题优化的方法。只需在 Btune 的前端界面进行一键操作,几分钟后就可以得到一份完整的性能瓶颈和优化建议报告。
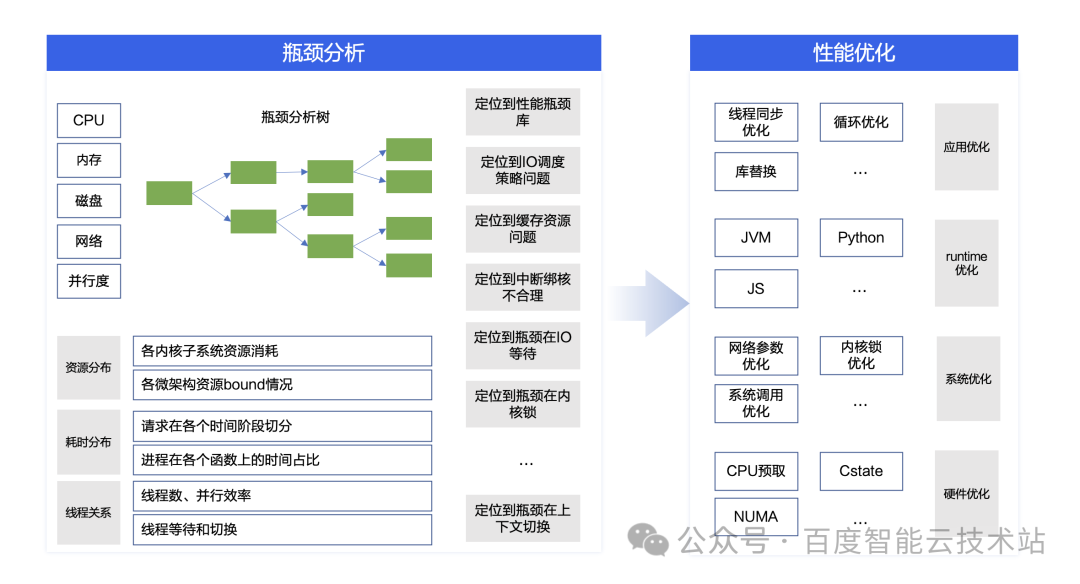
在 Btune 提供的性能瓶颈和优化建议报告中包含两部分:分析摘要和分析详情。其中,「分析摘要」清晰地展示了业务性能瓶颈点和相应的优化建议,可以满足绝大部分的场景的需求。「分析详情」提供了更详细的性能分析数据,从系统配置、系统性能、进程线程模型、函数指令热点等多个维度呈现负载的资源分布、耗时分布、线程关系等运行特性,满足用户更细粒度性能优化。
- 03 -
接下来,我们通过一个测试用例介绍如何使用 「应用程序性能诊断工具 Btune」。(此测试用例仅用于展示 Btune 基本功能和使用方法,实际生产环境业务负载比较复杂,但 Btune 使用方法和分析原理相同。)
在这个例子中,首先我们编写一个测试程序作为分析对象。在这个程序中主要是调用 glibc 库的 memset 和 memcpy 函数对内存进行操作。然后通过 numactl 命令模拟程序跨 NUMA 访问内存的情况。我们通过 Btune 对这个程序进行分析给出性能瓶颈和优化建议。在 Btune 输出的报告中,给出了两类建议:
-
在计算方面,给出了内存操作热点函数和对应的热点库升级建议。
-
在内存方面,给出了跨 NUMA 访存优化建议。
最后我们根据 Btune 给出的建议对程序进行优化,可以看到优化后程序性能提高了 36.8%,优化效果显著。
测试程序代码如下,程序会无限循环执行简单的内存拷贝操作,可通过编译命令:gcc -o test test.c 和启动命令:nohup numactl -N 0 -m 1 ./test & 来运行此程序。
#include "stdio.h" #include "stdlib.h" #include "string.h" #define ARRAY_SIZE 1000000000 void main() { int i=0; int *a = malloc(sizeof(int)*ARRAY_SIZE); int *b = malloc(sizeof(int)*ARRAY_SIZE); while(1) { memset(a, 0, sizeof(int)*ARRAY_SIZE); memset(b, 0, sizeof(int)*ARRAY_SIZE); memcpy(b, a, sizeof(int)*ARRAY_SIZE); }; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
具体操作步骤如下:
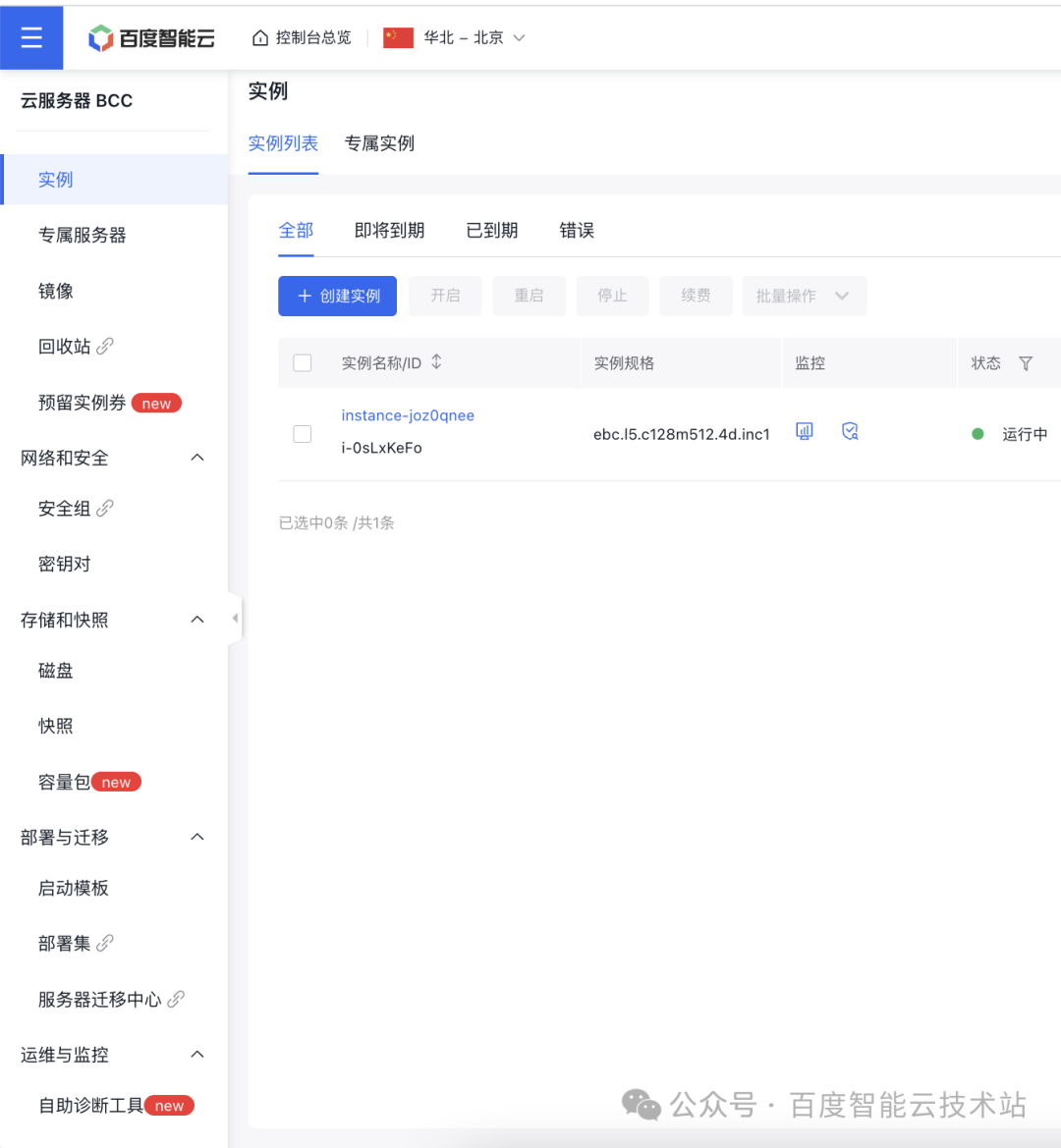
1. 登录云服务器控制台
创建一个云服务器实例,登陆实例并拷贝、启动测试程序 test。然后在百度智能云控制台侧边栏选择云服务器并选择「运维与监控」下面的「自助诊断工具」进入性能分析界面。
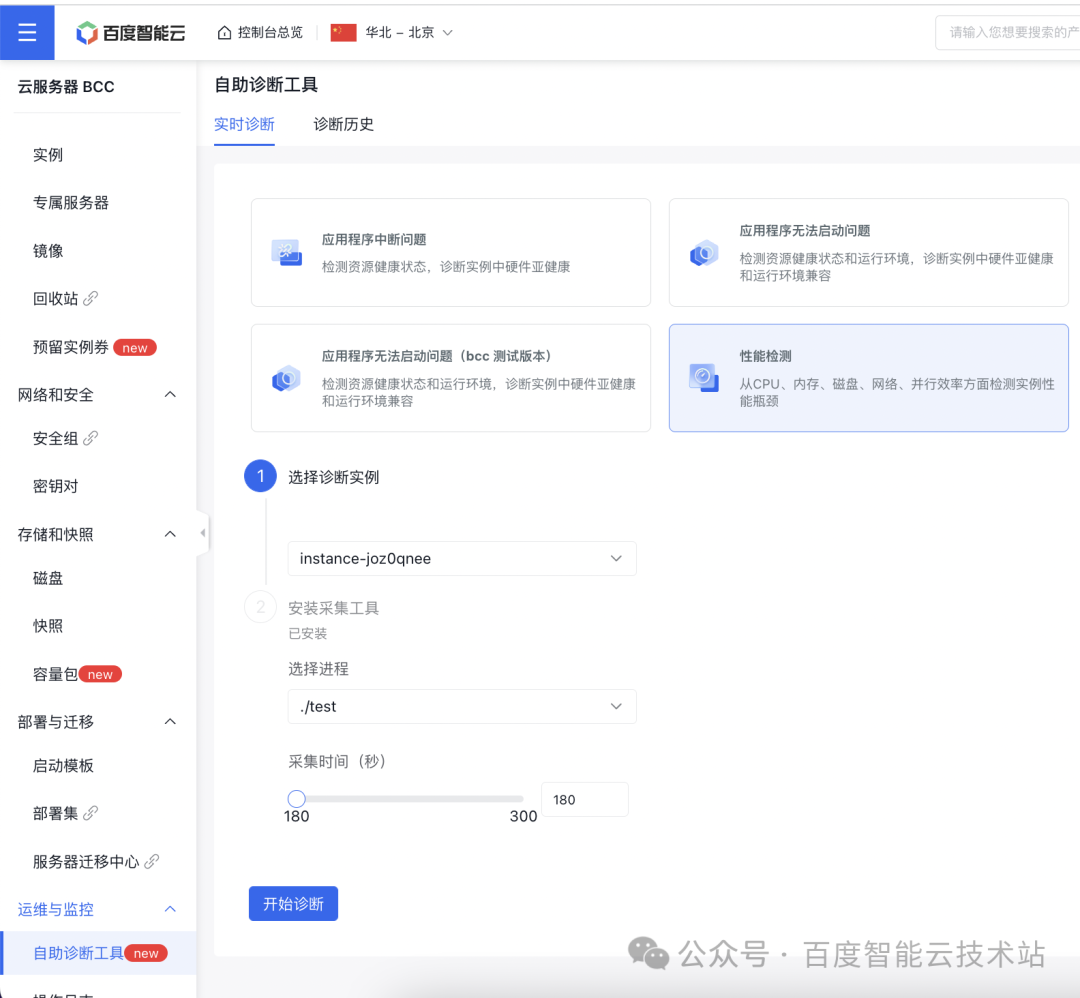
2. 启动性能检测
在自助诊断工具页面选择「性能检测」选项,然后选择刚才创建的云服务器实例作为诊断实例,以及选择 test 进程作为诊断进程,Btune 需要一定周期的采集时间分析该进展。参数配置完可开始检测。
3. 查看分析摘要报告
几分钟后,诊断完毕。Btune 输出分析摘要报告:
(1)待优化项
列出了程序的几个瓶颈点,并给出了优化建议。在此例中,有 3 条优化建议:前 2 条给出了热点函数 memset 和 memcpy 的热点占比,并推荐升级 glibc2.33 进行优化(当前 CentOS 7.9 默认 glibc 是 2.17,版本较低,性能差)。第 3 条给出了当前程序跨 NUMA 内存使用率是 100%,建议减少跨 NUMA 访问。
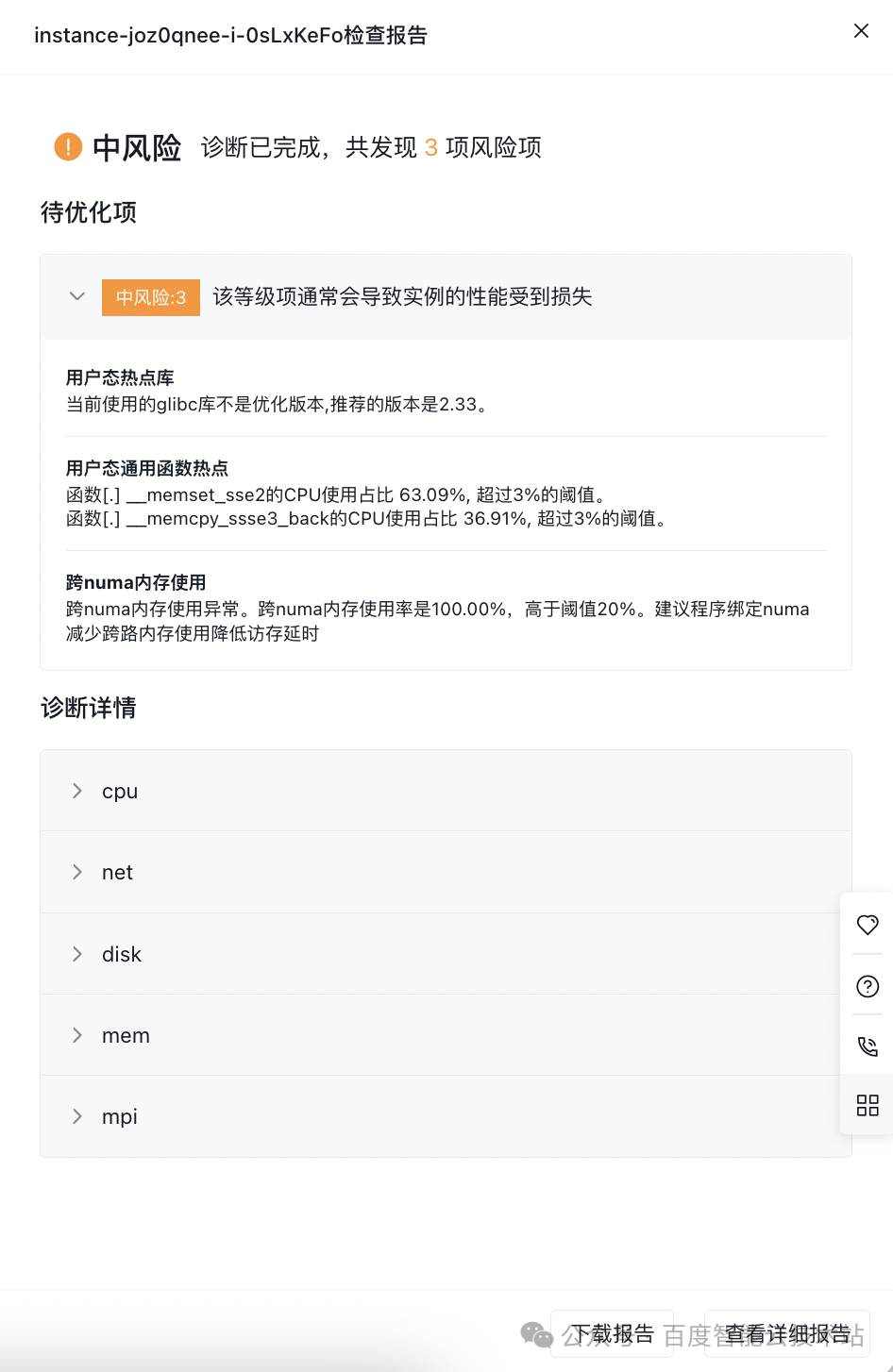
(2)诊断详情
诊断详情可查看 CPU、内存、网络、磁盘、并发等 5 个维度的监控数据。我们以 CPU、内存和并发 3 个诊断项说明如下:
- CPU 诊断项:内核的网络、存储和调度正常,主要风险是 glibc 热点函数和库版本。

- 内存诊断项:无内存泄漏,采用匿名大页,整机内存使用量较少,主要风险是跨 NUMA 使用内存。
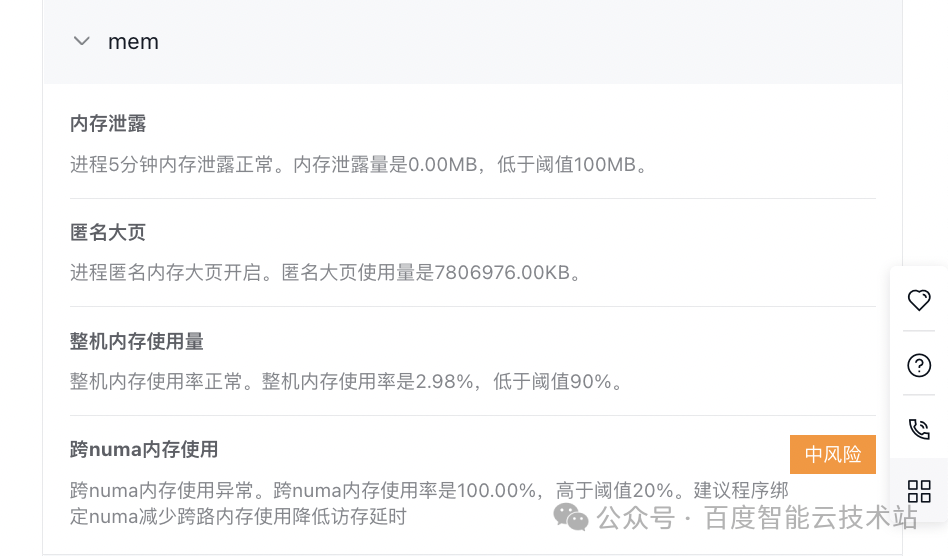
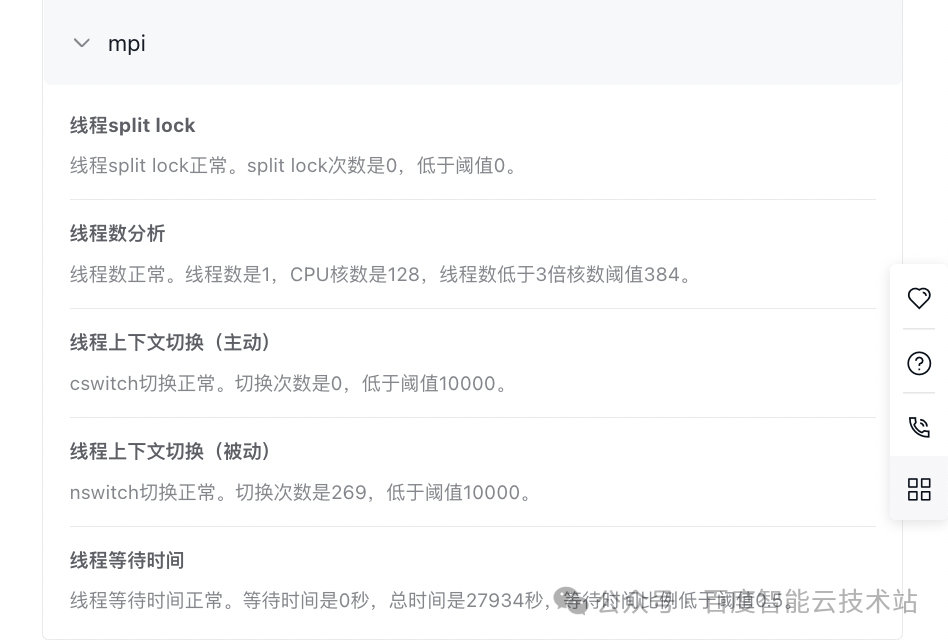
- 并发诊断项(mpi):线程数是 1,由于内存默认对齐所以没有出现 split lock 情况,线程上下文切换和线程等待时间均正常,无风险。
4. 查看分析详情报告
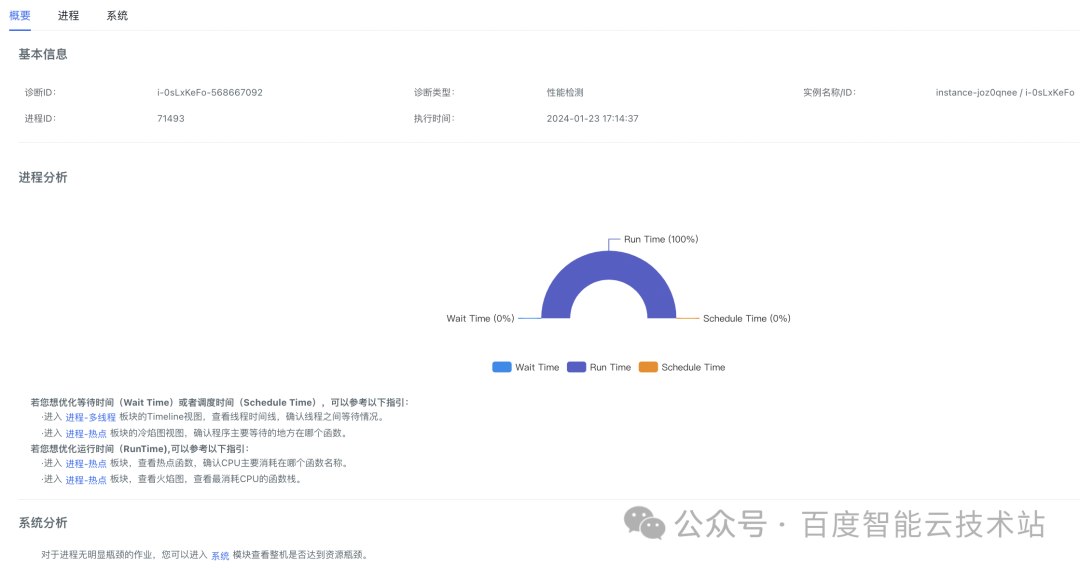
点击检测报告右下角的「查看详细报告」,可以查看详细的性能性能分析数据。
详细报告界面分为三部分:概要、进程和系统。「概要」从程序运行时间维度给出了初步分析;「进程」给出了进程粒度的分析数据(CPU、内存、磁盘、网络、热点、多线程并发);「系统」给出了整机粒度的分析数据(CPU、内存、磁盘、网络)。
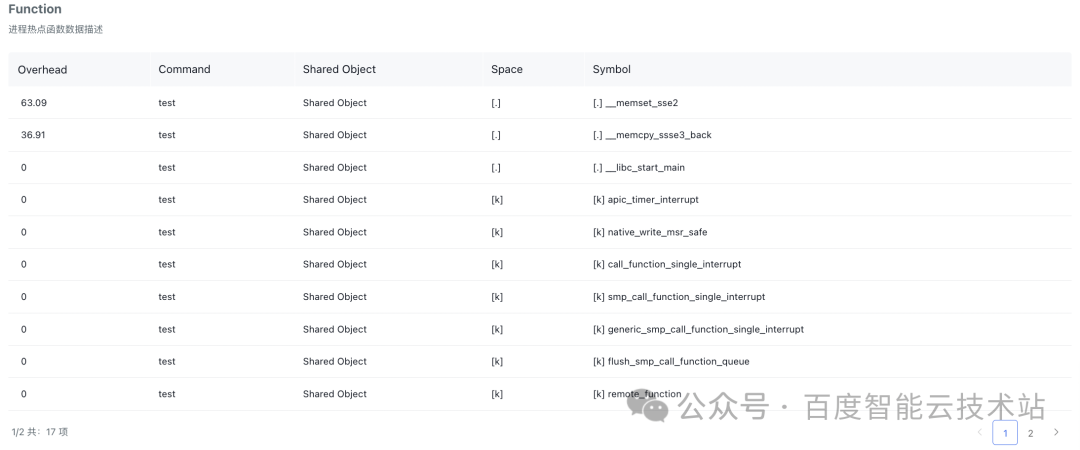
此案例中,通过进程「热点」可以查看热点函数 list,跨路的热点函数 list,火焰图,跨路火焰图等,具体如下:
- 热点函数:此例中主要热点是内存操作函数__memset_sse2 和__memcpy_sse3_back,分别占比 63.09% 和 36.91%。
- 跨 NUMA 热点函数:此例中主要跨路热点函数是__memcpy_sse3_back,占比 100%。

- 火焰图:此例中,glibc 中的__memset_sse2 和__memcpy_sse3_back 占比最大。
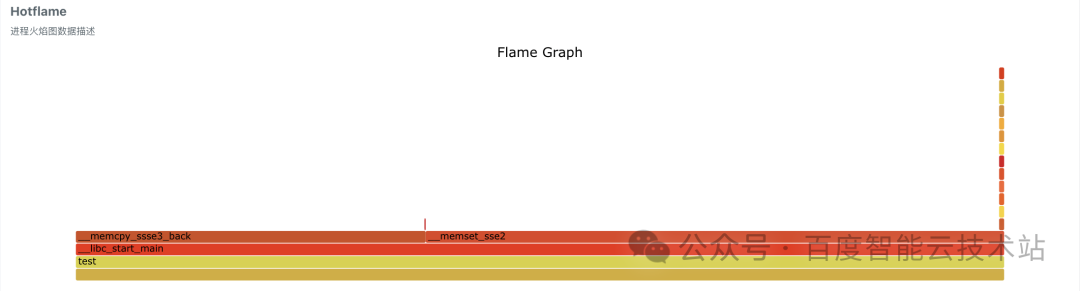
- 跨 NUMA 火焰图:此例中,glibc 中的__memcpy_sse3_back 占比最大。

5. 程序优化效果
根据 Btune 给出的优化建议,我们需要做两项优化措施:一个是升级 glibc 到 2.33,一个是减少跨 NUMA 访存。
为了方便对比优化前后性能差异,我们统计核心代码段的耗时,修改程序如下:
clock_gettime(CLOCK_REALTIME, &start);
memset(a, 0, sizeof(int)*ARRAY_SIZE);
memset(b, 0, sizeof(int)*ARRAY_SIZE);
memcpy(b, a, sizeof(int)*ARRAY_SIZE);
clock_gettime(CLOCK_REALTIME, &end);
elapsed = (end.tv_sec - start.tv_sec) + (end.tv_nsec - start.tv_nsec) / 1e9;
printf("Elapsed time: %f seconds\n", elapsed);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
首先,优化前的默认程序执行单次耗时 2.576349 秒。
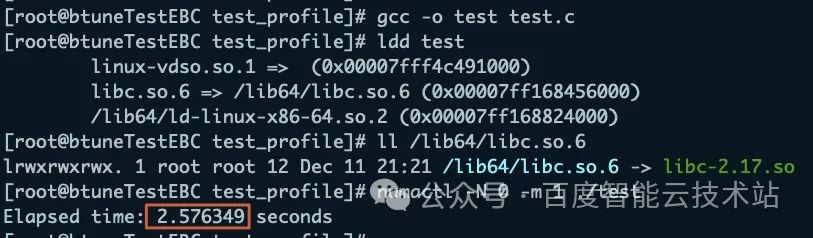
然后,执行 Btune 的建议优化项其一,关闭跨 NUMA 启动并保持 2.17 版本 glibc,此时程序耗时 1.821380 秒,优化 29.3%。
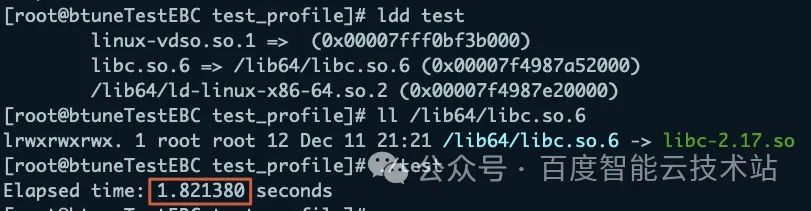
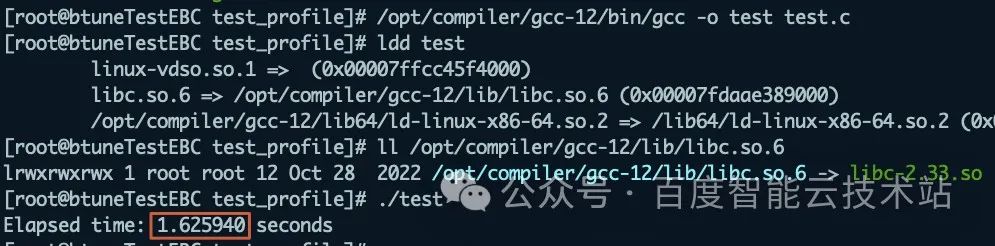
最后,执行 Btune 的全部优化建议,升级到 2.33 版本 glibc,并关闭跨 NUMA 启动,耗时 1.625940 秒,共优化 36.8%。
- - - - - - - - - - END - - - - - - - - - -
推荐阅读

